

NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?

1 はじめに
Neural Radiation Fields (NeRF) は、深層学習とコンピューター ビジョンの分野におけるかなり新しいパラダイムです。この技術は、ECCV 2020 の論文「NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis」(最優秀論文賞を受賞) で紹介され、それ以来爆発的に人気が高まり、現在までに 800 件近く引用されています [1]。このアプローチは、機械学習による 3D データの従来の処理方法に大きな変化をもたらします。
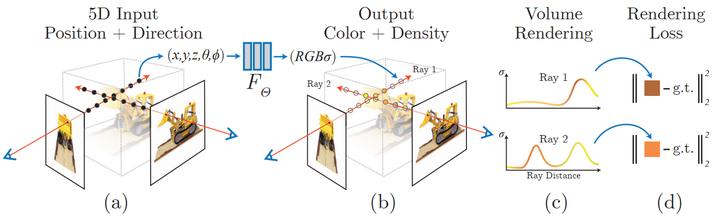
神経放射線フィールド シーン表現と微分可能なレンダリング プロセス:
カメラ光線に沿って 5D 座標 (位置と視線方向) をサンプリングすることで画像を合成します。位置は MLP に入力されて色と体積密度が生成され、これらの値は体積レンダリング技術を使用して画像に合成されます。このレンダリング関数は微分可能であるため、合成値と実際に観察された値の間の残差を最小限に抑えることでシーンを最適化できます。イメージで表現します。
2 NeRF とは何ですか?
NeRF は、画像と正確なポーズに条件付けされた、画像が与えられた 3D シーンの新しいビューを生成する生成モデルです。このプロセスはよく呼び出されます。 「新しいビュー構成」。それだけでなく、シーンの 3D 形状と外観を連続関数として明確に定義し、立方体を行進させることで 3D メッシュを生成できます。画像データから直接学習しますが、畳み込み層も変換層も使用しません。
長年にわたり、3D ボクセルから点群、符号付き距離関数に至るまで、機械学習アプリケーションで 3D データを表現する多くの方法が存在してきました。共通の最大の欠点は、写真測量や LIDAR などのツールを使用して 3D データを生成するか、3D モデルを手作りするなど、事前に 3D モデルを想定する必要があることです。ただし、反射率の高い物体、「格子状」の物体、透明な物体など、多くの種類の物体は大規模にスキャンできません。 3D 再構成方法では、再構成エラーが発生することが多く、モデルの精度に影響を与えるステップ効果やドリフトが発生する可能性があります。
対照的に、NeRF は光線フィールドの概念に基づいています。ライト フィールドは、3D ボリューム全体で光の透過がどのように発生するかを記述する関数です。これは、空間内の各 x = (x, y, z) 座標および各方向 d で光線が移動する方向を記述し、θ および ξ の角度または単位ベクトルとして記述されます。これらは一緒になって、3D シーンの光の透過を記述する 5D 特徴空間を形成します。この表現に触発されて、NeRF は、この空間から色 c = (R, G, B) と密度 (密度) σ で構成される 4D 空間にマッピングする関数を近似しようとします。これは、この 5D 座標空間と考えることができます。光線が終了する可能性(オクルージョンなど)。したがって、標準 NeRF は F: (x, d) -> (c, σ) の形式の関数です。
元の NeRF 論文では、既知の姿勢を持つ一連の画像でトレーニングされた多層パーセプトロンを使用して、この関数をパラメーター化しました。これは、一般化シーン再構築と呼ばれる一連の手法の 1 つであり、画像のコレクションから 3D シーンを直接記述することを目的としています。このアプローチには、非常に優れた特性がいくつかあります。
- データから直接学習
- シーンの連続表現により、葉やメッシュなどの非常に薄く複雑な構造が可能になります
- 鏡面性や粗さなどの暗黙的な物理的プロパティ
- シーン内の照明の暗黙的なレンダリング
それ以来、一連の改善に関する論文が登場しました。たとえば、レンズの数を減らし、単一のレンズを使用するなどです。 - レンズ学習 [2、3]、動的シーンのサポート [4、5]、ライト フィールドのフィーチャ フィールドへの一般化 [6]、ネットワーク上の未校正の画像コレクションからの学習 [7]、LIDAR データとの組み合わせ [8]、大規模なシーン表現 [9]、ニューラル ネットワークを使用しない学習 [10] など。
3 NeRF アーキテクチャ
全体として、トレーニング済みの NeRF モデルと既知のポーズと画像の寸法を持つカメラを考慮して、次のプロセスを通じてシーンを構築します。
- 各ピクセルについて、カメラの光学中心からシーンを通して光線を発射し、(x, d) 位置で一連のサンプルを収集します。
- 各サンプルの点とビュー方向 (x, d) を使用します。 d) 出力 (c, σ) 値 (rgbσ) を生成するための入力として使用します。
- 古典的なボリューム レンダリング技術を使用して画像を構築します。
発光フィールド (多くの文書では、次のように翻訳されています) 「radiation Field」(ただし、翻訳者は「Light Shooting Field」の方が直感的だと考えています)機能は、組み合わせると、以前のビデオで見られた視覚効果を作成できるいくつかのコンポーネントの 1 つにすぎません。全体として、この記事には次の部分が含まれています。
- 位置エンコーディング
- ライト フィールド関数近似器 (MLP)
- 微分可能ボディ レンダラー (微分可能ボリューム レンダラー)
- 層化サンプリング階層的ボリューム サンプリング
説明を最大限に明確にするために、この記事では各コンポーネントの主要な要素をコードの表示としてできるだけ簡潔にリストします。 bmild の元の実装と、yenchenlin および krrish94 の PyTorch 実装が参照されています。
3.1 位置エンコーダ
2017 年に導入されたトランス モデル [11] と同様に、NeRF も入力として位置エンコーダの恩恵を受けます。高周波関数を使用して連続入力を高次元空間にマッピングし、モデルがデータの高周波変化を学習できるようにし、よりクリーンなモデルを作成します。この方法により、低周波数関数に対するニューラル ネットワークのバイアスが回避され、NeRF がより明確な詳細を表現できるようになります。著者は ICML 2019 に関する論文を参照しています [12]。
transformerd の位置エンコーディングに精通している場合、関連する NeRF の実装は、同じサインとコサインの式が交互に繰り返される非常に標準的なものであることがわかります。位置エンコーダの実装:
# pyclass PositionalEncoder(nn.Module):# sine-cosine positional encoder for input points.def __init__( self,d_input: int,n_freqs: int,log_space: bool = False ):super().__init__()self.d_input = d_inputself.n_freqs = n_freqs # 是不是视线上的采样频率?self.log_space = log_spaceself.d_output = d_input * (1 + 2 * self.n_freqs)self.embed_fns = [lambda x: x] # 冒号前面的x表示函数参数,后面的表示匿名函数运算# Define frequencies in either linear or log scaleif self.log_space:freq_bands = 2.**torch.linspace(0., self.n_freqs - 1, self.n_freqs)else:freq_bands = torch.linspace(2.**0., 2.**(self.n_freqs - 1), self.n_freqs)# Alternate sin and cosfor freq in freq_bands:self.embed_fns.append(lambda x, freq=freq: torch.sin(x * freq))self.embed_fns.append(lambda x, freq=freq: torch.cos(x * freq))def forward(self, x) -> torch.Tensor:# Apply positional encoding to input.return torch.concat([fn(x) for fn in self.embed_fns], dim=-1)
思考: この位置エンコーディングは入力点をエンコードします。この入力点は視線上のサンプリング ポイントですか?それとも見る角度が違うのでしょうか? self.n_freqs は視線上のサンプリング周波数ですか?この理解から、視線上のサンプリング位置である必要があります。視線上のサンプリング位置がエンコードされていない場合、これらの位置を効果的に表現できず、RGBA をトレーニングできないためです。
3.2 放射輝度フィールド関数
原文では、ライト フィールド関数は NeRF モデルで表されています。NeRF モデルは、エンコードされた 3D ポイントと視線方向を使用する典型的な多層パーセプトロンです。 as は入力を受け取り、出力として RGBA 値を返します。この記事ではニューラル ネットワークを使用していますが、ここでは任意の関数近似器を使用できます。たとえば、Yu らのフォローアップ論文 Plenoxels では、球面調和関数を使用して、競争力のある結果を達成しながら桁違いに高速なトレーニングを実現しています [10]。
 写真
写真
NeRF モデルの深さは 8 層で、ほとんどの層のフィーチャー次元は 256 です。残りの接続はレイヤー 4 に配置されます。これらのレイヤーの後、RGB 値と σ 値が生成されます。 RGB 値は線形レイヤーでさらに処理され、視線方向と連結されてから別の線形レイヤーを通過し、最後に出力で σ と再結合されます。 NeRF モデルの PyTorch モジュール実装:
class NeRF(nn.Module):# Neural radiance fields module.def __init__( self,d_input: int = 3,n_layers: int = 8,d_filter: int = 256,skip: Tuple[int] = (4,), # (4,)只有一个元素4的元组 d_viewdirs: Optional[int] = None): super().__init__()self.d_input = d_input# 这里是3D XYZ,?self.skip = skip# 是要跳过什么?为啥要跳过?被遮挡?self.act = nn.functional.reluself.d_viewdirs = d_viewdirs# d_viewdirs 是2D方向?# Create model layers# [if_true 就执行的指令] if [if_true条件] else [if_false]# 是否skip的区别是,训练输入维度是否多3维,# if i in skip =if i in (4,),似乎是判断i是否等于4# self.d_input=3 :如果层id=4,网络输入要加3维,这是为什么?第4层有何特殊的?self.layers = nn.ModuleList([nn.Linear(self.d_input, d_filter)] +[nn.Linear(d_filter + self.d_input, d_filter) if i in skip else \ nn.Linear(d_filter, d_filter) for i in range(n_layers - 1)])# Bottleneck layersif self.d_viewdirs is not None:# If using viewdirs, split alpha and RGBself.alpha_out = nn.Linear(d_filter, 1)self.rgb_filters = nn.Linear(d_filter, d_filter)self.branch = nn.Linear(d_filter + self.d_viewdirs, d_filter // 2)self.output = nn.Linear(d_filter // 2, 3) # 为啥要取一半?else:# If no viewdirs, use simpler outputself.output = nn.Linear(d_filter, 4) # d_filter=256,输出是4维RGBAdef forward(self,x: torch.Tensor, # ?viewdirs: Optional[torch.Tensor] = None) -> torch.Tensor: # Forward pass with optional view direction.if self.d_viewdirs is None and viewdirs is not None:raise ValueError('Cannot input x_direction')# Apply forward pass up to bottleneckx_input = x# 这里的x是几维?从下面的分离RGB和A看,应该是4D# 下面通过8层MLP训练RGBAfor i, layer in enumerate(self.layers):# 8层,每一层进行运算x = self.act(layer(x)) if i in self.skip:x = torch.cat([x, x_input], dim=-1)# Apply bottleneckbottleneck 瓶颈是啥?是不是最费算力的模块?if self.d_viewdirs is not None:# 从网络输出分离A,RGB还需要经过更多训练alpha = self.alpha_out(x)# Pass through bottleneck to get RGBx = self.rgb_filters(x) x = torch.concat([x, viewdirs], dim=-1)x = self.act(self.branch(x)) # self.branch shape: (d_filter // 2)x = self.output(x) # self.output shape: (3)# Concatenate alphas to outputx = torch.concat([x, alpha], dim=-1)else:# Simple outputx = self.output(x)return x考察: この NERF クラスの入力と出力は何でしょうか?このクラスを通して何が起こるでしょうか? __init__ 関数のパラメータを見ると、主にニューラルネットワークの入力、レベル、次元を設定していることが分かり、視点位置と視線方向という5Dデータが入力され、出力はRGBAとなっています。質問ですが、出力RGBAはワンポイントですか?それとも一連の視線でしょうか?それがシリーズの場合、位置コーディングが各サンプリング ポイントの RGBA をどのように決定するのかを知りません。
サンプリング間隔の説明を見ていません。それが点である場合、その上のどの点ですか?視線はこれRGBAですか?目で見た視覚サンプリング点の集合の結果である点RGBAでしょうか? NERF クラスコードを見ると、主に視点位置と視線方向に基づいて多層フィードフォワード学習が行われ、5D 視点位置と視線方向を入力として 4D RGBA が出力されることがわかります。
3.3 Differentiable Volume Renderer(微分可能ボリューム レンダラー)
RGBA 出力ポイントは 3D 空間に配置されているため、それらを画像に合成するには、次のセクション 4 の方程式 1 ~ 3 を適用する必要があります。論文 体積積分について説明します。基本的に、各ピクセルの視線に沿ったすべてのサンプルの加重合計が実行され、そのピクセルの推定カラー値が取得されます。各 RGB サンプルは、その透明度のアルファ値によって重み付けされます。アルファ値が高いほど、サンプリングされた領域が不透明である可能性が高いことを示し、したがって、光線に沿った遠方のポイントが遮蔽される可能性が高くなります。累積積演算により、これらのさらなるポイントが確実に抑制されます。
元の NeRF モデルによるボリューム レンダリング出力:
def raw2outputs(raw: torch.Tensor,z_vals: torch.Tensor,rays_d: torch.Tensor,raw_noise_std: float = 0.0,white_bkgd: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:# 将原始的NeRF输出转为RGB和其他映射# Difference between consecutive elements of `z_vals`. [n_rays, n_samples]dists = z_vals[..., 1:] - z_vals[..., :-1]# ?这里减法的意义是啥?dists = torch.cat([dists, 1e10 * torch.ones_like(dists[..., :1])], dim=-1)# 将每个距离乘以其对应方向光线的范数,以转换为真实世界的距离(考虑非单位方向)dists = dists * torch.norm(rays_d[..., None, :], dim=-1)# 将噪声添加到模型对密度的预测中,用于在训练期间规范网络(防止漂浮物伪影)noise = 0.if raw_noise_std > 0.:noise = torch.randn(raw[..., 3].shape) * raw_noise_std# Predict density of each sample along each ray. Higher values imply# higher likelihood of being absorbed at this point. [n_rays, n_samples]alpha = 1.0 - torch.exp(-nn.functional.relu(raw[..., 3] + noise) * dists)# Compute weight for RGB of each sample along each ray. [n_rays, n_samples]# The higher the alpha, the lower subsequent weights are driven.weights = alpha * cumprod_exclusive(1. - alpha + 1e-10)# Compute weighted RGB map.rgb = torch.sigmoid(raw[..., :3])# [n_rays, n_samples, 3]rgb_map = torch.sum(weights[..., None] * rgb, dim=-2)# [n_rays, 3]# Estimated depth map is predicted distance.depth_map = torch.sum(weights * z_vals, dim=-1)# Disparity map is inverse depth.disp_map = 1. / torch.max(1e-10 * torch.ones_like(depth_map),depth_map / torch.sum(weights, -1))# Sum of weights along each ray. In [0, 1] up to numerical error.acc_map = torch.sum(weights, dim=-1)# To composite onto a white background, use the accumulated alpha map.if white_bkgd:rgb_map = rgb_map + (1. - acc_map[..., None])return rgb_map, depth_map, acc_map, weightsdef cumprod_exclusive(tensor: torch.Tensor) -> torch.Tensor:# (Courtesy of https://github.com/krrish94/nerf-pytorch)# Compute regular cumprod first.cumprod = torch.cumprod(tensor, -1)# "Roll" the elements along dimension 'dim' by 1 element.cumprod = torch.roll(cumprod, 1, -1)# Replace the first element by "1" as this is what tf.cumprod(..., exclusive=True) does.cumprod[..., 0] = 1.return cumprod
質問: ここでの主な機能は何ですか?何が入力されましたか?アウトプットとは何ですか?
3.4 層化サンプリング
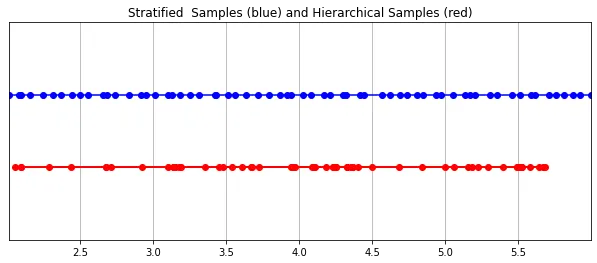
カメラが最終的に取得した RGB 値は、ピクセルを通過する視線に沿った光サンプルの蓄積です。古典的なボリューム レンダリング方法では、ピクセルに沿ってポイントを蓄積します。視線、次に点が統合され、各点で光線が粒子に当たらずに進む確率が推定されます。したがって、各ピクセルは、それを通過する光線に沿って点をサンプリングする必要があります。積分を最もよく近似するために、層化サンプリング法では空間を N 個のビンに均一に分割し、各ビンから均一にサンプルを抽出します。層化サンプリング法では、単純に等間隔でサンプルを抽出するのではなく、モデルが連続空間でサンプリングできるため、ネットワークが連続空間で学習できるように調整されます。
 画像
画像
PyTorch で実装された階層サンプリング:
def sample_stratified(rays_o: torch.Tensor,rays_d: torch.Tensor,near: float,far: float,n_samples: int,perturb: Optional[bool] = True,inverse_depth: bool = False) -> Tuple[torch.Tensor, torch.Tensor]:# Sample along ray from regularly-spaced bins.# Grab samples for space integration along rayt_vals = torch.linspace(0., 1., n_samples, device=rays_o.device)if not inverse_depth:# Sample linearly between `near` and `far`z_vals = near * (1.-t_vals) + far * (t_vals)else:# Sample linearly in inverse depth (disparity)z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))# Draw uniform samples from bins along rayif perturb:mids = .5 * (z_vals[1:] + z_vals[:-1])upper = torch.concat([mids, z_vals[-1:]], dim=-1)lower = torch.concat([z_vals[:1], mids], dim=-1)t_rand = torch.rand([n_samples], device=z_vals.device)z_vals = lower + (upper - lower) * t_randz_vals = z_vals.expand(list(rays_o.shape[:-1]) + [n_samples])# Apply scale from `rays_d` and offset from `rays_o` to samples# pts: (width, height, n_samples, 3)pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None]return pts, z_vals
3.5 階層ボリューム サンプリング
放射線場が表現されています2 つの多層パーセプトロンによって、1 つは粗いレベルで動作し、シーンの広範な構造特性をエンコードし、もう 1 つは細かいレベルで詳細を調整し、メッシュやブランチなどの薄くて詳細な構造を可能にします。さらに、受信するサンプルは異なり、粗いモデルはレイ全体にわたって広く、ほぼ規則的に配置されたサンプルを処理しますが、細かいモデルは強い事前分布を持つ領域に磨きをかけ、顕著な情報を取得します。
这种“珩磨”过程是通过层次体积采样流程完成的。3D空间实际上非常稀疏,存在遮挡,因此大多数点对渲染图像的贡献不大。因此,对具有对积分贡献可能性高的区域进行过采样(oversample)更有好处。他们将学习到的归一化权重应用于第一组样本,以在光线上创建PDF,然后再将inverse transform sampling应用于该PDF以收集第二组样本。该集合与第一集合相结合,并被馈送到精细网络以产生最终输出。
分层采样PyTorch实现:
def sample_hierarchical(rays_o: torch.Tensor,rays_d: torch.Tensor,z_vals: torch.Tensor,weights: torch.Tensor,n_samples: int,perturb: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:# Apply hierarchical sampling to the rays.# Draw samples from PDF using z_vals as bins and weights as probabilities.z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1])new_z_samples = sample_pdf(z_vals_mid, weights[..., 1:-1], n_samples, perturb=perturb)new_z_samples = new_z_samples.detach()# Resample points from ray based on PDF.z_vals_combined, _ = torch.sort(torch.cat([z_vals, new_z_samples], dim=-1), dim=-1)# [N_rays, N_samples + n_samples, 3]pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals_combined[..., :, None]return pts, z_vals_combined, new_z_samplesdef sample_pdf(bins: torch.Tensor, weights: torch.Tensor, n_samples: int, perturb: bool = False) -> torch.Tensor:# Apply inverse transform sampling to a weighted set of points.# Normalize weights to get PDF.# [n_rays, weights.shape[-1]]pdf = (weights + 1e-5) / torch.sum(weights + 1e-5, -1, keepdims=True) # Convert PDF to CDF.cdf = torch.cumsum(pdf, dim=-1) # [n_rays, weights.shape[-1]]# [n_rays, weights.shape[-1] + 1]cdf = torch.concat([torch.zeros_like(cdf[..., :1]), cdf], dim=-1) # Take sample positions to grab from CDF. Linear when perturb == 0.if not perturb:u = torch.linspace(0., 1., n_samples, device=cdf.device)u = u.expand(list(cdf.shape[:-1]) + [n_samples]) # [n_rays, n_samples]else:# [n_rays, n_samples]u = torch.rand(list(cdf.shape[:-1]) + [n_samples], device=cdf.device) # Find indices along CDF where values in u would be placed.u = u.contiguous() # Returns contiguous tensor with same values.inds = torch.searchsorted(cdf, u, right=True) # [n_rays, n_samples]# Clamp indices that are out of bounds.below = torch.clamp(inds - 1, min=0)above = torch.clamp(inds, max=cdf.shape[-1] - 1)inds_g = torch.stack([below, above], dim=-1) # [n_rays, n_samples, 2]# Sample from cdf and the corresponding bin centers.matched_shape = list(inds_g.shape[:-1]) + [cdf.shape[-1]]cdf_g = torch.gather(cdf.unsqueeze(-2).expand(matched_shape), dim=-1,index=inds_g)bins_g = torch.gather(bins.unsqueeze(-2).expand(matched_shape), dim=-1, index=inds_g)# Convert samples to ray length.denom = (cdf_g[..., 1] - cdf_g[..., 0])denom = torch.where(denom <h3 id="Training">4 Training</h3><p>论文中训练NeRF推荐的每网络8层、每层256维的架构在训练过程中会消耗大量内存。缓解这种情况的方法是将前传(forward pass)分成更小的部分,然后在这些部分上积累梯度。注意与minibatching的区别:梯度是在采样光线的单个小批次上累积的,这些光线可能已经被收集成块。如果没有论文中使用的NVIDIA V100类似性能的GPU,可能必须相应地调整块大小以避免OOM错误。Colab笔记本采用了更小的架构和更适中的分块尺寸。</p><p>我个人发现,由于局部极小值,即使选择了许多默认值,NeRF的训练也有些棘手。一些有帮助的技术包括早期训练迭代和早期重新启动期间的中心裁剪(center cropping)。随意尝试不同的超参数和技术,以进一步提高训练收敛性。</p><h4 id="初始化">初始化</h4><pre class="brush:php;toolbar:false">def init_models():# Initialize models, encoders, and optimizer for NeRF training.encoder = PositionalEncoder(d_input, n_freqs, log_space=log_space)encode = lambda x: encoder(x)# View direction encodersif use_viewdirs:encoder_viewdirs = PositionalEncoder(d_input, n_freqs_views,log_space=log_space)encode_viewdirs= lambda x: encoder_viewdirs(x)d_viewdirs = encoder_viewdirs.d_outputelse:encode_viewdirs = Noned_viewdirs = Nonemodel = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)model.to(device)model_params = list(model.parameters())if use_fine_model:fine_model = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)fine_model.to(device)model_params = model_params + list(fine_model.parameters())else:fine_model = Noneoptimizer= torch.optim.Adam(model_params, lr=lr)warmup_stopper = EarlyStopping(patience=50)return model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper
训练
def train():# Launch training session for NeRF.# Shuffle rays across all images.if not one_image_per_step:height, width = images.shape[1:3]all_rays = torch.stack([torch.stack(get_rays(height, width, focal, p), 0) for p in poses[:n_training]], 0)rays_rgb = torch.cat([all_rays, images[:, None]], 1)rays_rgb = torch.permute(rays_rgb, [0, 2, 3, 1, 4])rays_rgb = rays_rgb.reshape([-1, 3, 3])rays_rgb = rays_rgb.type(torch.float32)rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0train_psnrs = []val_psnrs = []iternums = []for i in trange(n_iters):model.train()if one_image_per_step:# Randomly pick an image as the target.target_img_idx = np.random.randint(images.shape[0])target_img = images[target_img_idx].to(device)if center_crop and i = rays_rgb.shape[0]:rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0target_img = target_img.reshape([-1, 3])# Run one iteration of TinyNeRF and get the rendered RGB image.outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)# Backprop!rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, target_img)loss.backward()optimizer.step()optimizer.zero_grad()psnr = -10. * torch.log10(loss)train_psnrs.append(psnr.item())# Evaluate testimg at given display rate.if i % display_rate == 0:model.eval()height, width = testimg.shape[:2]rays_o, rays_d = get_rays(height, width, focal, testpose)rays_o = rays_o.reshape([-1, 3])rays_d = rays_d.reshape([-1, 3])outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, testimg.reshape(-1, 3))val_psnr = -10. * torch.log10(loss)val_psnrs.append(val_psnr.item())iternums.append(i)# Check PSNR for issues and stop if any are found.if i == warmup_iters - 1:if val_psnr <h4 id="训练">训练</h4><pre class="brush:php;toolbar:false"># Run training session(s)for _ in range(n_restarts):model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper = init_models()success, train_psnrs, val_psnrs = train()if success and val_psnrs[-1] >= warmup_min_fitness:print('Training successful!')breakprint(f'Done!')5 Conclusion
辐射场标志着处理3D数据的方式发生了巨大变化。NeRF模型和更广泛的可微分渲染正在迅速弥合图像创建和体积场景创建之间的差距。虽然我们的组件可能看起来非常复杂,但受vanilla NeRF启发的无数其他方法证明,基本概念(连续函数逼近器+可微分渲染器)是构建各种解决方案的坚实基础,这些解决方案可用于几乎无限的情况。
原文:NeRF From Nothing: A Tutorial with PyTorch | Towards Data Science
原文链接:https://mp.weixin.qq.com/s/zxJAIpAmLgsIuTsPqQqOVg
以上がNeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7523
7523
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
