

GPT-3.5 を選択しますか、それとも Llama 2 などのオープンソース モデルを微調整しますか?総合的に比較した結果、答えは次のようになります。

GPT-3.5 の微調整には非常に費用がかかることはよく知られています。このペーパーでは、実験を使用して、手動で微調整したモデルが数分の 1 のコストで GPT-3.5 のパフォーマンスに近づくことができるかどうかを検証します。興味深いことに、この記事はまさにそれを行っています。
SQL タスクと関数表現タスクの結果を比較すると、この記事では次のことがわかりました:
- GPT-3.5 は 2 つのデータ セット ( Spider データ セットと Viggo 関数表現データ セットのサブセットは、Lora によって微調整された Code Llama 34B よりもわずかに優れたパフォーマンスを示します。
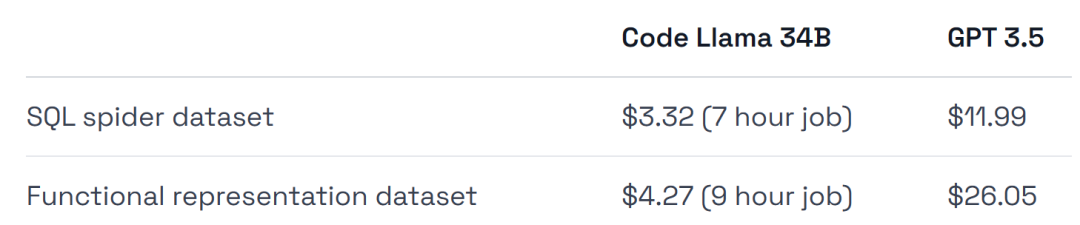
- GPT-3.5 は、トレーニングと導入に 4 ~ 6 倍の費用がかかります。
この実験の結論の 1 つは、GPT-3.5 の微調整が最初の検証作業には適しているが、その後は Llama 2 のようなモデルが最適である可能性があるということです。要約すると:
- #微調整が特定のタスク/データセットを解決する正しい方法であることを確認したい場合、または完全に管理された環境が必要な場合は、次に GPT-3.5 を微調整します。
- コストを節約したい場合、データセットから最大限のパフォーマンスを引き出したい場合、インフラストラクチャのトレーニングと展開をより柔軟に行いたい場合、または一部のデータを非公開にしたい場合は、オープンなデータセットを微調整してください。 Llama 2 のようなソース モデル。
次に、この記事がどのように実装されるかを見てみましょう。
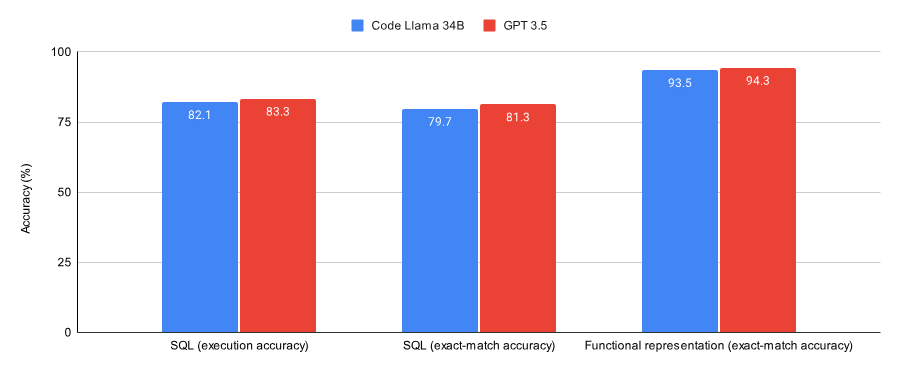
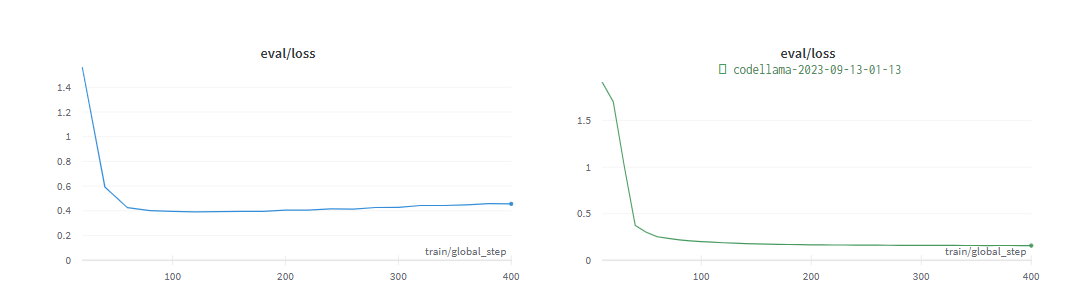
次の図は、SQL タスクと関数表現タスクで収束するようにトレーニングされたコード Llama 34B と GPT-3.5 のパフォーマンスを示しています。結果は、GPT-3.5 が両方のタスクでより高い精度を達成していることを示しています。
ハードウェア使用量に関しては、実験では A40 GPU を使用しました。コストは 1 時間あたり約 0.475 ドルです。
さらに、実験では、Spider のサブセットである、微調整に非常に適した 2 つのデータセットを選択しました。データセットと Viggo 関数表現データセット。
GPT-3.5 モデルと公平に比較するために、実験では Llama で最小限のハイパーパラメーター微調整を実行しました。
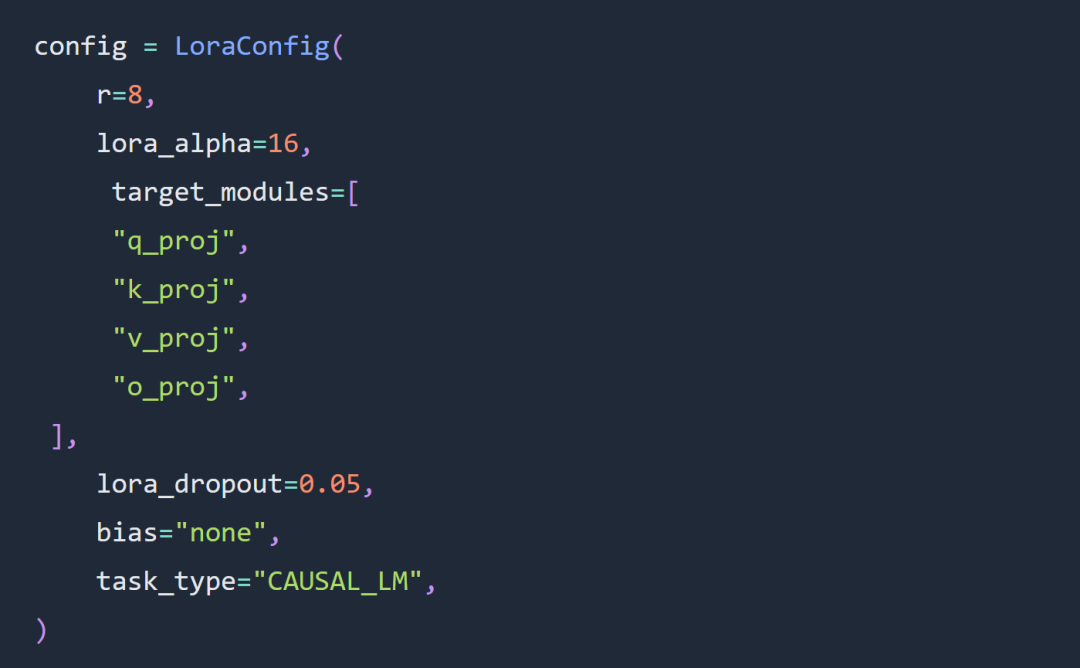
この記事の実験における 2 つの重要な選択肢は、フルパラメータ微調整の代わりに Code Llama 34B と Lora 微調整を使用することです。
#実験では、Lora ハイパーパラメータの微調整に関するルールにかなりの範囲で従い、Lora アダプターは次のように構成されました:
##SQL プロンプトの例は次のとおりです。
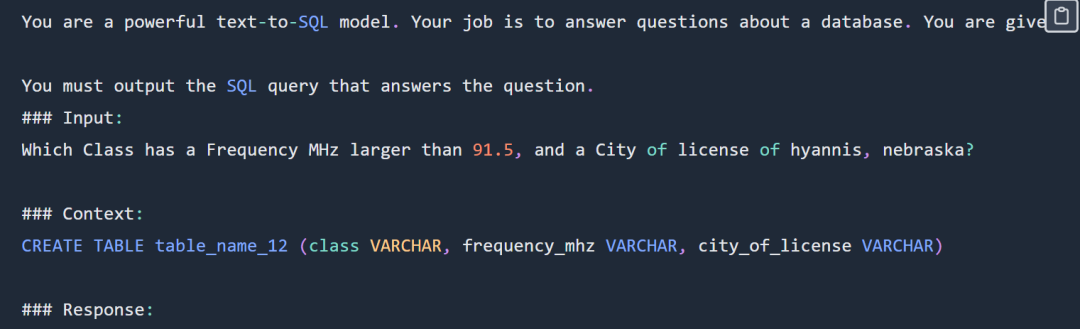
SQL プロンプトは次のとおりです。部分的に表示されています。完全なプロンプトを入力してください。 元のブログを表示します。
実験では完全な Spider データ セットを使用しませんでした。具体的な形式は次のとおりです。
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
実験では、sql-create-context データセットと Spider データセットの交差を使用することを選択しました。モデルに提供されるコンテキストは、次のような SQL 作成コマンドです:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
SQL タスクのコードとデータ アドレス: https://github.com/samlhuillier/spider-sql -finetune
関数表現プロンプトの例は次のようになります:
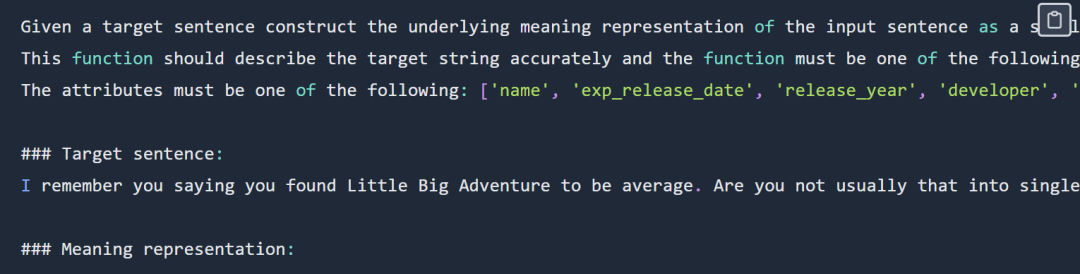
function 表現プロンプトは部分的に表示されています。完全なプロンプトについては、元のブログを確認してください。##出力は次のとおりです:
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])
 関数表現タスク コードとデータ アドレス: https://github.com/ samlhuillier/viggo-finetune
関数表現タスク コードとデータ アドレス: https://github.com/ samlhuillier/viggo-finetune
詳細については、元のブログをご覧ください。
以上がGPT-3.5 を選択しますか、それとも Llama 2 などのオープンソース モデルを微調整しますか?総合的に比較した結果、答えは次のようになります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7334
7334
 9
1627
14
1352
46
1264
25
1209
29
9
1627
14
1352
46
1264
25
1209
29

 文字列を介してオブジェクトを動的に作成し、Pythonでメソッドを呼び出す方法は?
Apr 01, 2025 pm 11:18 PM
文字列を介してオブジェクトを動的に作成し、Pythonでメソッドを呼び出す方法は?
Apr 01, 2025 pm 11:18 PM
Pythonでは、文字列を介してオブジェクトを動的に作成し、そのメソッドを呼び出す方法は?これは一般的なプログラミング要件です。特に構成または実行する必要がある場合は...
 GoまたはRustを使用してPythonスクリプトを呼び出して、真の並列実行を実現する方法は?
Apr 01, 2025 pm 11:39 PM
GoまたはRustを使用してPythonスクリプトを呼び出して、真の並列実行を実現する方法は?
Apr 01, 2025 pm 11:39 PM
GoまたはRustを使用してPythonスクリプトを呼び出して、真の並列実行を実現する方法は?最近、私はPythonを使用しています...
 Python Asyncio Telnet接続はすぐに切断されます:サーバー側のブロッキング問題を解決する方法は?
Apr 02, 2025 am 06:30 AM
Python Asyncio Telnet接続はすぐに切断されます:サーバー側のブロッキング問題を解決する方法は?
Apr 02, 2025 am 06:30 AM
Pythonasyncioについて...
 ChatGpt時代には、技術的なQ&Aコミュニティは課題にどのように対応できますか?
Apr 01, 2025 pm 11:51 PM
ChatGpt時代には、技術的なQ&Aコミュニティは課題にどのように対応できますか?
Apr 01, 2025 pm 11:51 PM
ChatGpt時代のテクニカルQ&Aコミュニティ:SegmentFaultの対応戦略StackOverFlow ...
 Scapy Crawlerを使用するときにパイプラインファイルを書き込めない理由は何ですか?
Apr 02, 2025 am 06:45 AM
Scapy Crawlerを使用するときにパイプラインファイルを書き込めない理由は何ですか?
Apr 02, 2025 am 06:45 AM
SCAPYクローラーを使用するときにパイプラインファイルを作成できない理由についての議論は、SCAPYクローラーを学習して永続的なデータストレージに使用するときに、パイプラインファイルに遭遇する可能性があります...
 Pythonマルチプロセスパイプ通信で「パイプ閉じた」エラーを優雅に処理する方法は?
Apr 01, 2025 pm 11:12 PM
Pythonマルチプロセスパイプ通信で「パイプ閉じた」エラーを優雅に処理する方法は?
Apr 01, 2025 pm 11:12 PM
Pythonマルチプロセスパイプエラー「パイプは閉じています」? PythonのMultiprocessing Moduleでパイプメソッドを使用して、親子プロセス通信を使用する場合、遭遇する可能性があります...
 Webページデータを取得するときに動的読み込みコンテンツが欠落の問題を解決する方法は?
Apr 01, 2025 pm 11:24 PM
Webページデータを取得するときに動的読み込みコンテンツが欠落の問題を解決する方法は?
Apr 01, 2025 pm 11:24 PM
リクエストライブラリを使用してWebページのデータをクロールするときに遭遇する問題とソリューション。リクエストライブラリを使用してWebページデータを取得すると、時々遭遇します...

