

MiniGPT-4 は MiniGPT-v2 にアップグレードされました。マルチモーダル タスクは GPT-4 なしでも完了できます。

数か月前、KAUST (サウジアラビアのキング・アブドラ科学技術大学) の数人の研究者が、MiniGPT-4 # と呼ばれる手法を提案しました。 ## プロジェクト。GPT-4 と同様の画像理解機能と対話機能を提供します。
たとえば、MiniGPT-4 は、下の写真のシーンに答えることができます。「その写真は、凍った湖の上で成長しているサボテンを描写しています。サボテンの周りには巨大な氷の結晶があり、そこには「遠くに氷の結晶が見えます。雪を頂いた山々が…」では、このような光景は現実の世界で起こり得るのでしょうか? MiniGPT-4 が出した答えは、この画像は現実世界では一般的ではない、そしてその理由です。

ほんの数か月が経ちましたが、最近、KAUST チームと Meta の研究者は、MiniGPT-4 を MiniGPT-v2 バージョンにアップグレードしたことを発表しました。 。

論文のアドレス: https://arxiv.org/pdf/2310.09478.pdf
論文ホームページ: https://minigpt-v2.github.io/
#デモ: https://minigpt-v2.github.io/
具体的には、MiniGPT-v2 は、さまざまな視覚言語タスクをより適切に処理するための統合インターフェイスとして機能します。同時に、この記事では、モデルをトレーニングするときに、さまざまなタスクに一意の識別記号を使用することをお勧めします。これらの識別記号は、モデルが各タスクの指示を簡単に区別し、各タスク モデルの学習効率を向上させるのに役立ちます。
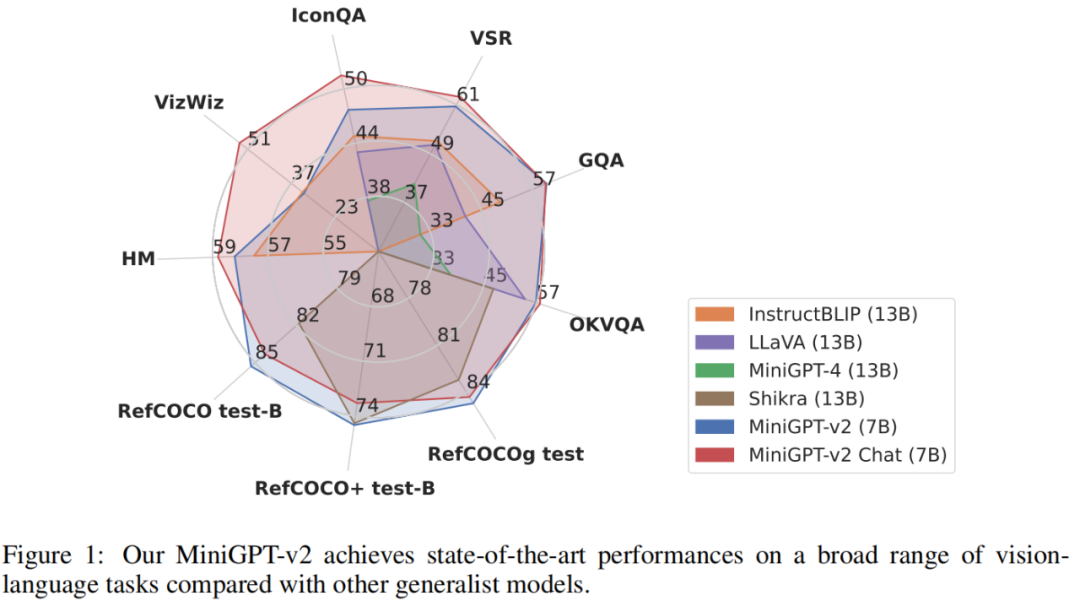
MiniGPT-v2 モデルのパフォーマンスを評価するために、研究者たちはさまざまな視覚言語タスクについて広範な実験を実施しました。結果は、MiniGPT-4、InstructBLIP、LLaVA、Shikra などの以前のビジョン言語汎用モデルと比較して、MiniGPT-v2 がさまざまなベンチマークで SOTA または同等のパフォーマンスを達成していることを示しています。たとえば、VSR ベンチマークでは、MiniGPT-v2 は MiniGPT-4 を 21.3%、InstructBLIP を 11.3%、LLaVA を 11.7% 上回っています。
以下では、特定の例を使用して MiniGPT-v2 識別シンボルの役割を説明します。
たとえば、[グラウンディング] 認識シンボルを追加することで、モデルは空間位置認識を備えた画像記述を簡単に生成できます。

[検出] 認識シンボルを追加することにより、モデルは入力テキスト内のオブジェクトを直接抽出し、画像内のオブジェクトの空間位置を見つけることができます。

画像内のオブジェクトをフレーム化します。[identify] を追加すると、モデルはオブジェクトの名前を直接識別できます。参照] オブジェクトの説明を使用すると、モデルはオブジェクトの対応する空間位置を見つけるのに直接役立ちます。
 また、タスクを追加せずにマッチング、対話用の画像:
また、タスクを追加せずにマッチング、対話用の画像:

# モデルの空間認識も強化され、登場するモデルに直接質問することができます写真の左、中、右:

メソッドの紹介


ビジュアル バックボーン: MiniGPT-v2 はバックボーン モデルとして EVA を使用し、トレーニング中にビジュアル バックボーンはフリーズします。モデルは 448x448 の画像解像度でトレーニングされ、より高い画像解像度にスケールするために位置エンコードが挿入されます。
線形投影層: この記事の目的は、凍結されたビジュアル バックボーンからすべてのビジュアル トークンを言語モデル空間に投影することです。ただし、より高解像度の画像 (例: 448x448) の場合、すべての画像トークンを投影すると非常に長いシーケンス入力 (例: 1024 トークン) が発生し、トレーニングと推論の効率が大幅に低下します。したがって、この論文では、エンベディング空間内の 4 つの隣接するビジュアル トークンを単純に連結し、それらを大規模な言語モデルの同じ特徴空間内の 1 つのエンベディングに一緒に投影することで、ビジュアル入力トークンの数を 4 分の 1 に削減します。
大規模言語モデル: MiniGPT-v2 は、言語モデルのバックボーンとしてオープン ソースの LLaMA2-chat (7B) を使用します。この研究では、言語モデルはさまざまな視覚言語入力のための統一されたインターフェイスとして考慮されます。この記事では、LLaMA-2 言語トークンを直接使用して、さまざまな視覚言語タスクを実行します。空間的位置の生成を必要とする基本的な視覚タスクの場合、この論文では、空間的位置を表す境界ボックスのテキスト表現を生成する言語モデルを直接必要とします。
#マルチタスク指示トレーニング
##この記事では、タスク認識の記号指示を使用してタスク認識をトレーニングします。モデルは3段階に分かれています。トレーニングの各段階で使用されるデータセットを表 2 に示します。
フェーズ 1: 事前トレーニング。この論文では、より多様な知識を取得するために、弱くラベル付けされたデータセットに高いサンプリング レートを与えます。
フェーズ 2: マルチタスク トレーニング。各タスクで MiniGPT-v2 のパフォーマンスを向上させるために、現在の段階では、モデルをトレーニングするためのきめの細かいデータセットの使用のみに焦点を当てています。研究者らは、GRIT-20MやLAIONなどの弱い教師付きデータセットをステージ1から除外し、各タスクの頻度に応じてデータサンプリング率を更新しました。この戦略により、モデルは高品質に位置合わせされた画像とテキストのデータを優先することができ、その結果、さまざまなタスクにわたって優れたパフォーマンスが得られます。
フェーズ 3: マルチモーダル命令のチューニング。その後、このペーパーでは、よりマルチモーダルな命令データセットを使用してモデルを微調整し、チャットボットとしての会話機能を強化することに焦点を当てます。
最後に、公式は読者がテストできるデモも提供しています。たとえば、下の画像の左側で、写真をアップロードし、[検出]を選択して、次のように入力します。 「赤い風船」と入力すると、モデルは写真内の赤い風船を識別できます。
#興味のある読者は、紙のホームページで詳細を確認してください。



以上がMiniGPT-4 は MiniGPT-v2 にアップグレードされました。マルチモーダル タスクは GPT-4 なしでも完了できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7552
7552
 15
1382
52
83
11
22
95
15
1382
52
83
11
22
95

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CENTOSでのZookeeperパフォーマンスチューニングは、ハードウェア構成、オペレーティングシステムの最適化、構成パラメーターの調整、監視、メンテナンスなど、複数の側面から開始できます。特定のチューニング方法を次に示します。SSDはハードウェア構成に推奨されます。ZookeeperのデータはDISKに書き込まれます。十分なメモリ:頻繁なディスクの読み取りと書き込みを避けるために、Zookeeperに十分なメモリリソースを割り当てます。マルチコアCPU:マルチコアCPUを使用して、Zookeeperが並行して処理できるようにします。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
