

中国チームが制作した超人気のミニ GPT-4 のビジュアル機能は飛躍的に向上し、GitHub で 20,000 個のスターを獲得

GPT-4V はターゲット検出用ですか?ネチズンによる実際のテスト: まだ準備ができていません。
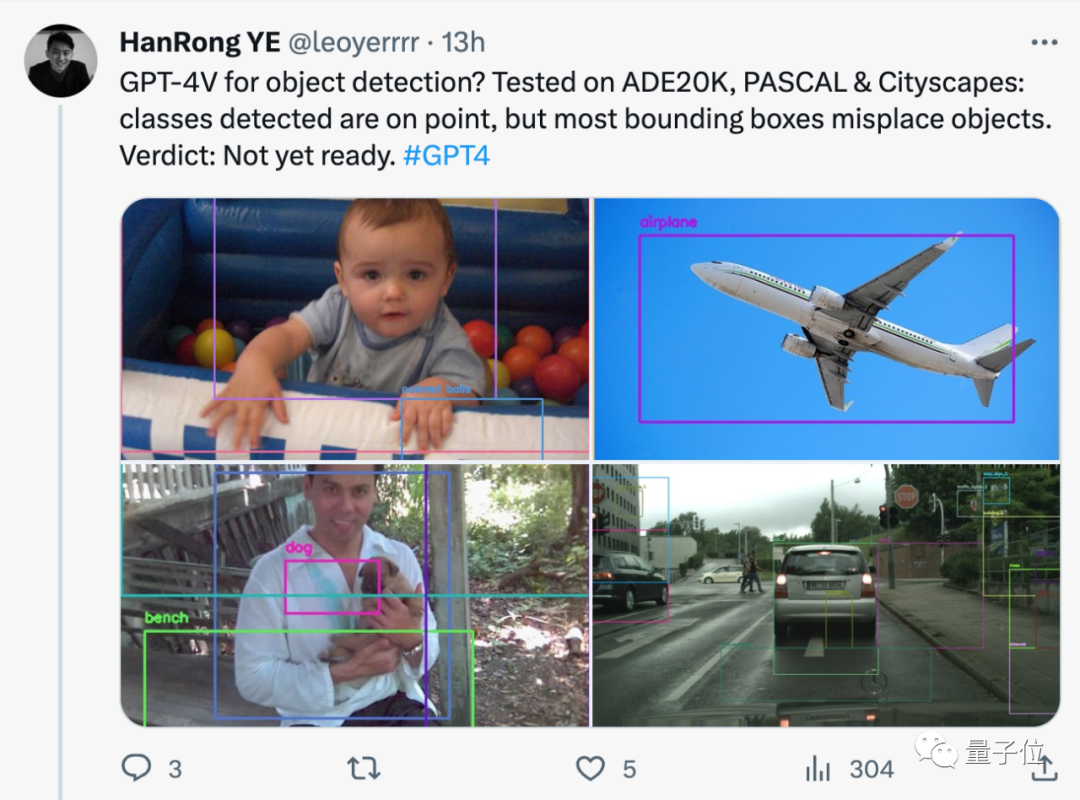
#検出されたカテゴリには問題はありませんが、ほとんどの境界ボックスが間違って配置されています。
大丈夫、誰かが行動してくれるでしょう!
画像表示能力で GPT-4 を数か月上回った Mini GPT-4 がアップグレードされました ——MiniGPT-v2。
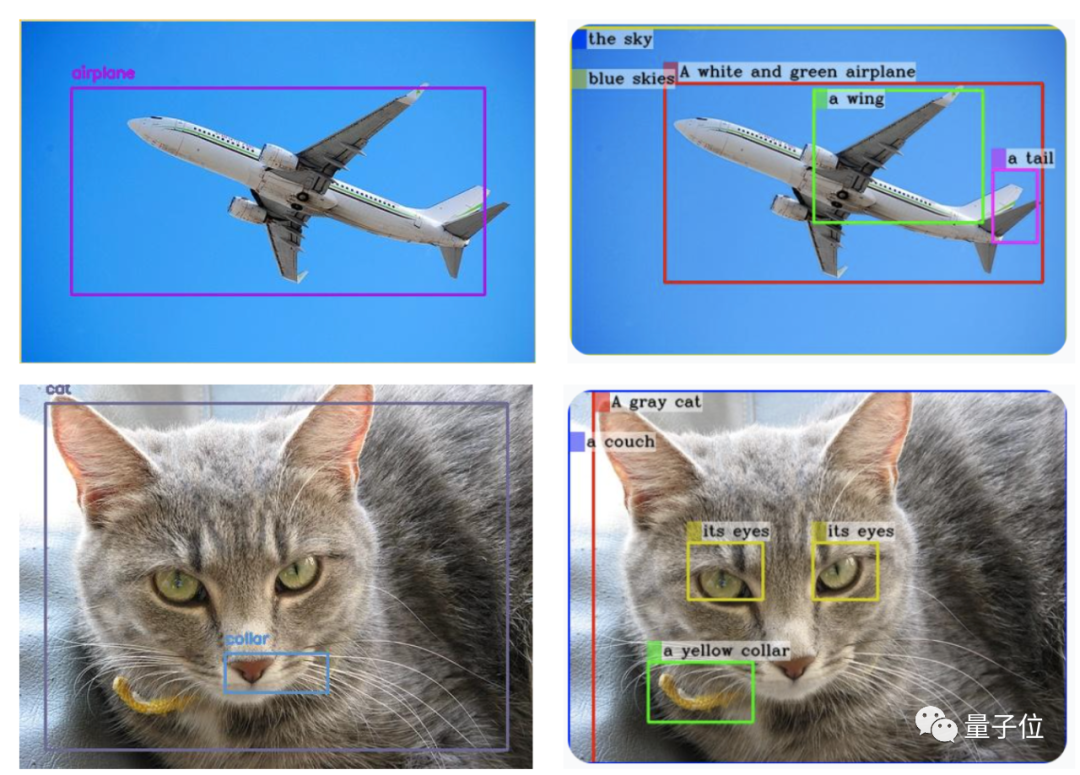
△ (GPT-4V は左側に生成され、MiniGPT-v2 は右側に生成されます)
これは単純なコマンドです: [グラウンディング] の詳細はこの画像で説明します が達成された結果です。
それだけでなく、さまざまな視覚的なタスクも簡単に処理できます。
オブジェクトを丸で囲み、プロンプト単語の前に [identify] を追加して、モデルがオブジェクトの名前を直接識別できるようにします。

もちろん、何も追加せずに尋ねることもできます~
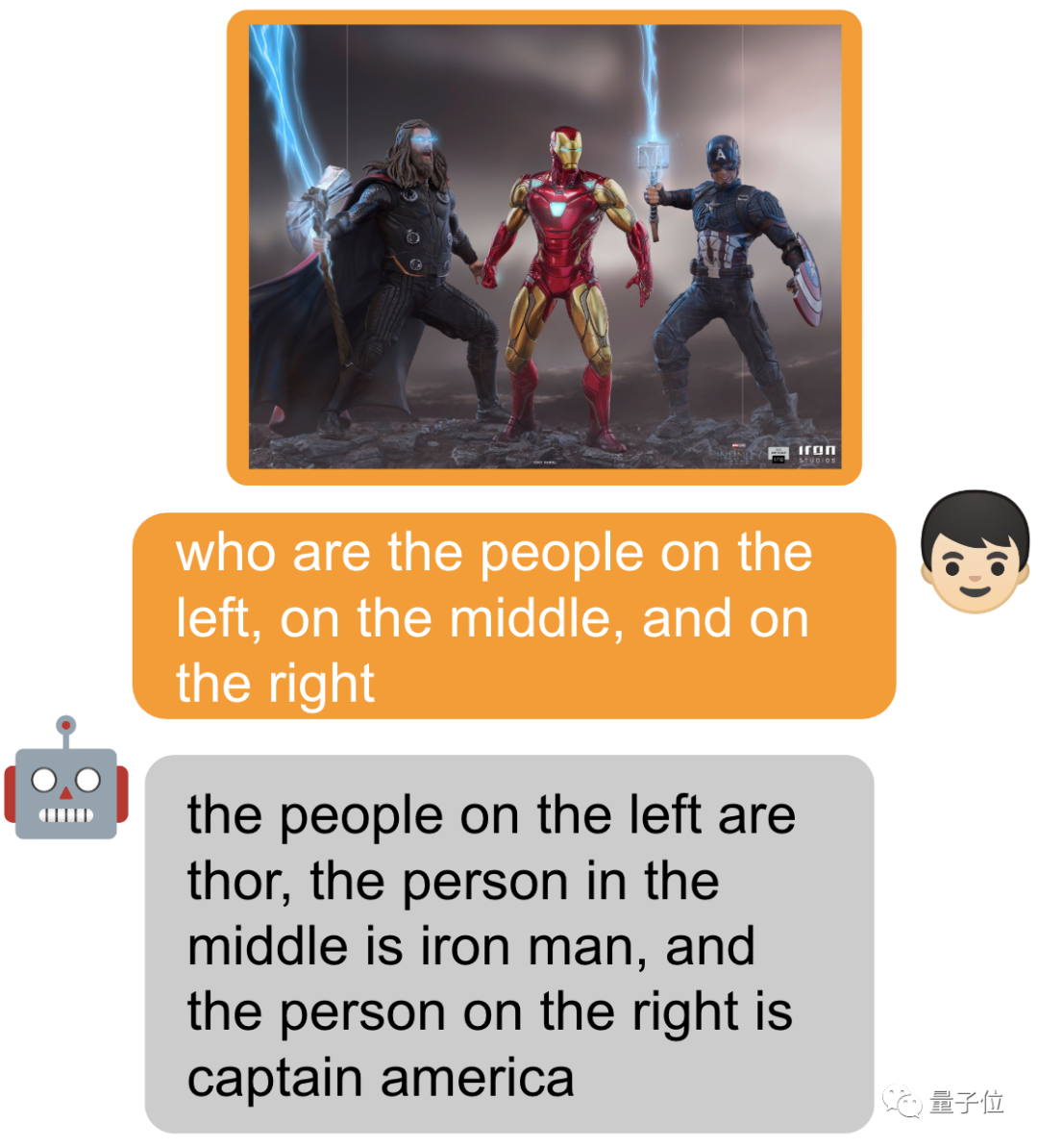
MiniGPT-v2 は MiniGPT によって作成されます- 4 オリジナルチーム (KAUST キング・アブドラ科学技術大学) と Meta の 5 人の研究者によって開発されました。

前回の MiniGPT-4 は、登場時に大きな注目を集め、一時はサーバーがパンクする事態となりましたが、現在、GitHub プロジェクトのスター数は 22,000 を超えています。
このアップグレードにより、一部のネチズンはすでにそれを使い始めています~
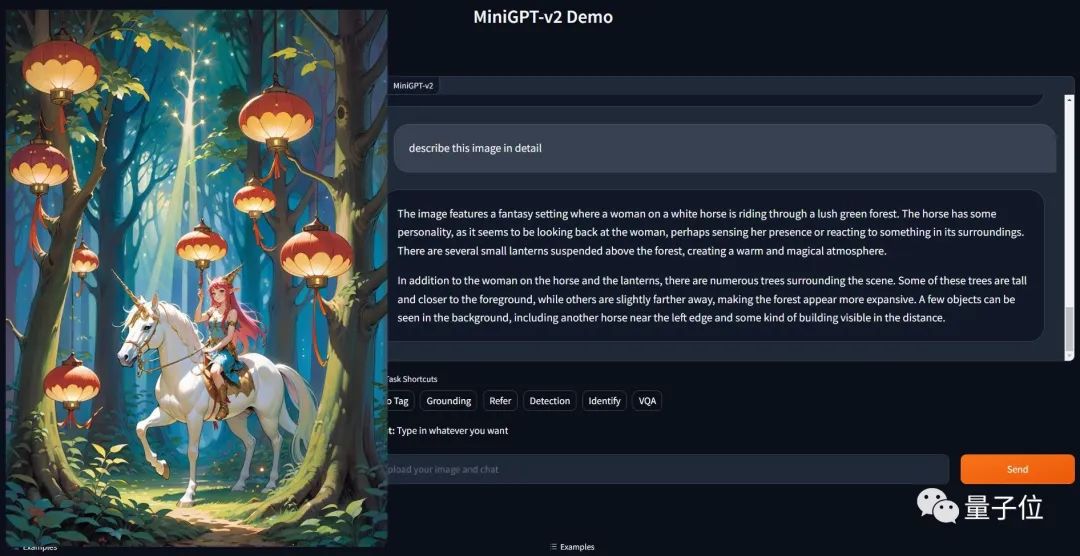
複数のビジュアルタスクのための共通インターフェース
さまざまなテキスト アプリケーションの共通インターフェイスとして、大規模なモデルはすでに一般的になっています。これに触発されて、研究チームは、画像の説明や視覚的な質問応答など、さまざまな視覚的タスクに使用できる統一インターフェイスを構築したいと考えています。

「単一モデルの条件下で、シンプルなマルチモーダル命令を使用してさまざまなタスクを効率的に完了するにはどうすればよいか?」は、チームが解決する必要がある難しい問題となっています。
簡単に言うと、MiniGPT-v2 は、ビジュアル バックボーン、線形層、大規模言語モデルの 3 つの部分で構成されています。
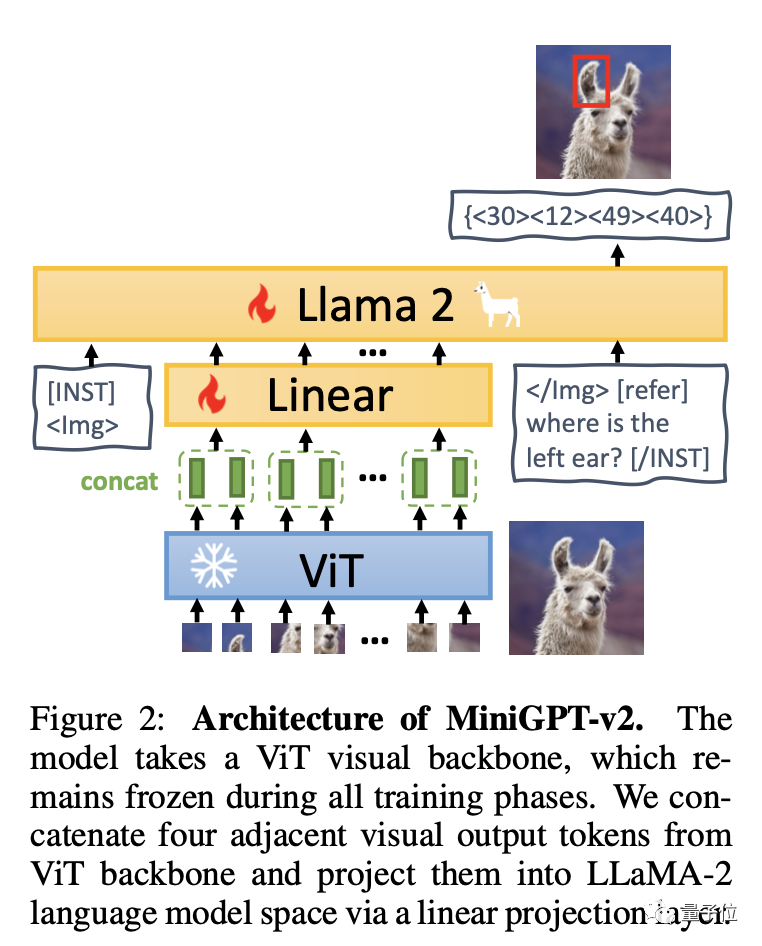
モデルは ViT ビジュアル バックボーンに基づいており、すべてのトレーニング段階で変更されません。 4 つの隣接するビジュアル出力トークンが ViT から誘導され、線形層を介して LLaMA-2 言語モデル空間に投影されます。
チームは、大規模なモデルで各タスクの指示を簡単に区別し、各タスクの学習効率を向上させることができるように、トレーニング モデル内のさまざまなタスクに一意の識別子を使用することを推奨しています。
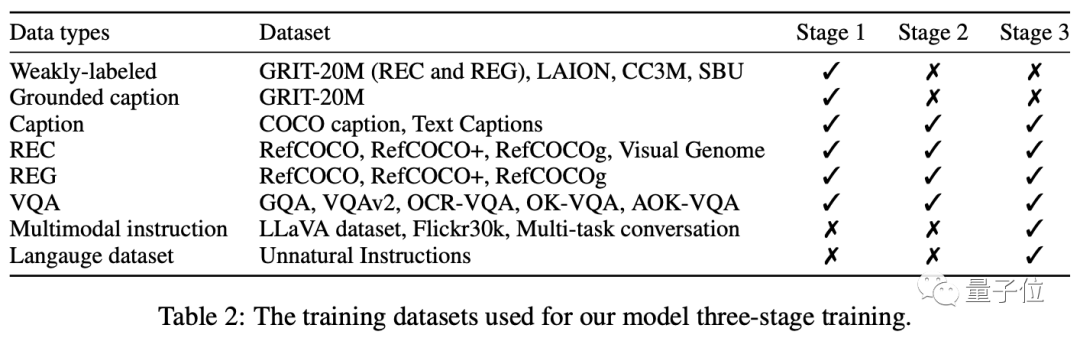
トレーニングは主に、事前トレーニング - マルチタスクトレーニング - マルチモード指導調整の 3 つの段階に分かれています。
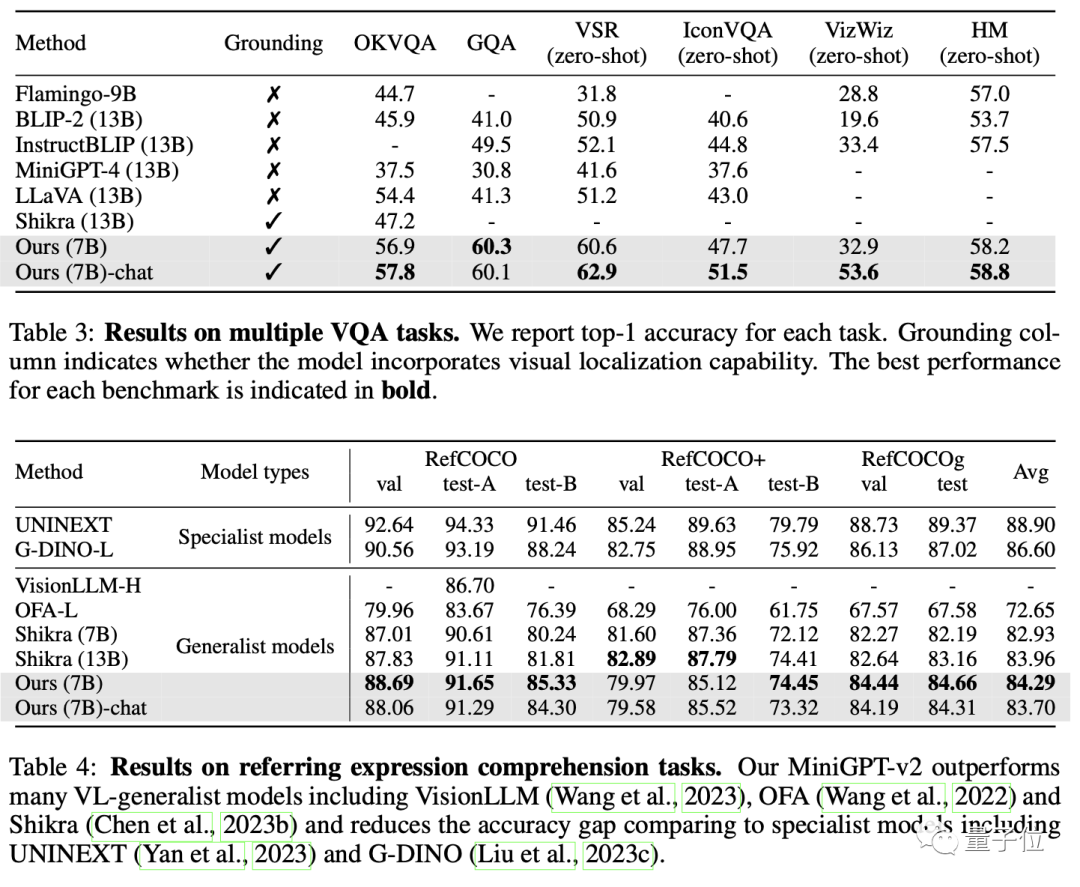
最終的に、MiniGPT-v2 は、多くの視覚的な質問応答や視覚的なグラウンディングのベンチマークにおいて、他の視覚言語の一般的なモデルよりも優れたパフォーマンスを示しました。
最終的に、このモデルは、ターゲット オブジェクトの説明、視覚的な位置特定、画像の説明、視覚的な質問応答、指定された入力からの直接画像解析など、さまざまな視覚的なタスクを完了できます。テキスト、オブジェクト。

興味のあるお友達は、下のデモ リンクをクリックして体験してください:
https://minigpt-v2.github.io/
https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2
紙のリンク: https://arxiv.org/abs/ 2310.09478
GitHub リンク: https://github.com/Vision-CAIR/MiniGPT-4
以上が中国チームが制作した超人気のミニ GPT-4 のビジュアル機能は飛躍的に向上し、GitHub で 20,000 個のスターを獲得の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7561
7561
 15
1384
52
84
11
28
98
15
1384
52
84
11
28
98

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
CENTOSシステムでGitLabログを表示するための完全なガイドこの記事では、メインログ、例外ログ、その他の関連ログなど、CentosシステムでさまざまなGitLabログを表示する方法をガイドします。ログファイルパスは、gitlabバージョンとインストール方法によって異なる場合があることに注意してください。次のパスが存在しない場合は、gitlabインストールディレクトリと構成ファイルを確認してください。 1.メインGitLabログの表示
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
