

復旦大学とファーウェイ・ノアが反復的な高品質ビデオ生成を実現するVidRDフレームワークを提案

復旦大学とファーウェイのノアの方舟研究所の研究者は、画像拡散モデル (LDM) - VidRD (再利用と拡散) に基づいて高品質ビデオを生成するための反復ソリューションを提案しました。このソリューションは、生成されるビデオの品質とシーケンスの長さにおいて画期的な進歩を遂げ、高品質で制御可能な長いシーケンスのビデオ生成を実現することを目的としています。これは、生成されたビデオ フレーム間のジッター問題を効果的に軽減し、研究と実用的な価値が高く、現在注目を集めている AIGC コミュニティに貢献します。
潜在拡散モデル (LDM) は、ノイズ除去オートエンコーダーに基づく生成モデルであり、ランダムに初期化されたデータから徐々にノイズを除去することで高品質のデータを生成できます。ただし、モデルのトレーニングと推論の両方における計算とメモリの制限により、通常、単一の LDM は非常に限られた数のビデオ フレームしか生成できません。既存の研究では、別の予測モデルを使用してより多くのビデオ フレームを生成しようとしていますが、これにより追加のトレーニング コストが発生し、フレーム レベルのジッターが発生します。
この論文では、画像合成における潜在拡散モデル (LDM) の目覚ましい成功に触発されて、VidRD と呼ばれる「再利用と拡散」と呼ばれるフレームワークが提案されています。このフレームワークは、LDM によってすでに生成された少数のビデオ フレームの後にさらに多くのビデオ フレームを生成できるため、より長く、高品質で多様なビデオ コンテンツを繰り返し生成できます。 VidRD は、効率的なトレーニングのために事前トレーニング済みの画像 LDM モデルを読み込み、ノイズ除去のために時間情報を追加した U-Net ネットワークを使用します。

- 論文タイトル: 再利用と拡散: テキストからビデオへの生成のための反復的ノイズ除去
- 論文アドレス: https://arxiv.org/abs/2309.03549
- プロジェクト ホームページ: https://anonymous0x233.github.io/ ReuseAndDiffuse /
この記事の主な貢献は次のとおりです:
- よりスムーズなビデオを生成するために、この記事はLDM モデルは、タイミングを意識した反復的な「テキストからビデオへの」生成方法を提案しています。この方法では、既に生成されたビデオ フレームから潜在空間特徴を再利用し、毎回前の拡散プロセスに従うことにより、より多くのビデオ フレームを繰り返し生成できます。
- この記事では、高品質の「テキストビデオ」データ セットを生成するための一連のデータ処理方法を設計します。既存のアクション認識データセットに対して、この論文ではマルチモーダル大規模言語モデルを使用してビデオにテキストの説明を与えます。画像データの場合、このペーパーではランダムなスケーリングと変換方法を使用して、より多くのビデオ トレーニング サンプルを生成します。
- UCF-101 データセット上で、この記事では FVD と IS の 2 つの評価指標と可視化結果を検証しました。定量的および定性的結果は次のことを示しています。 、VidRD モデルはすべてより良い結果を達成しました。
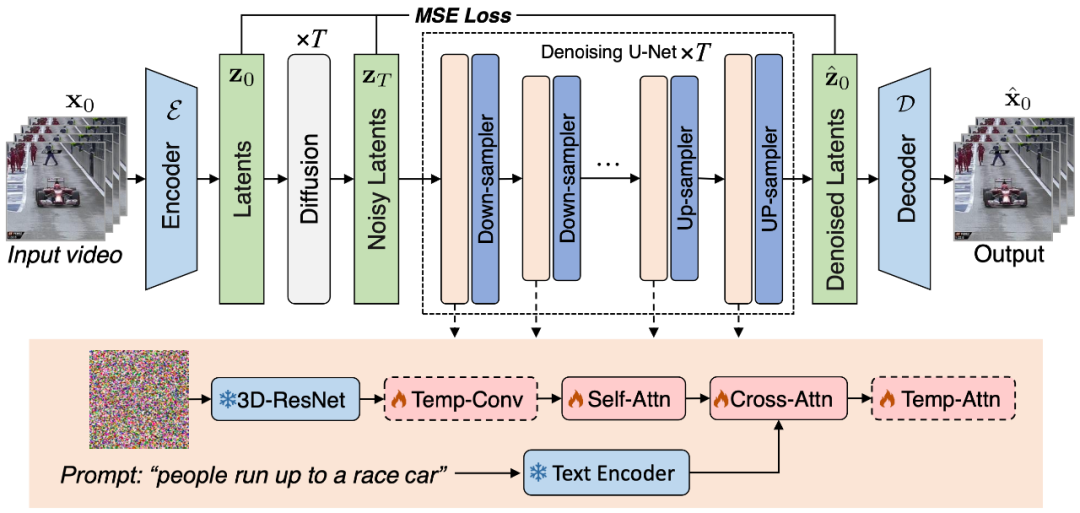
この記事では、高品質ビデオ合成のための LDM トレーニングの開始点として、事前トレーニング済みの画像 LDM を使用することが効率的で賢明な選択であると考えています。同時に、この見解は[1、2]などの研究成果によってさらに裏付けられています。これに関連して、この記事で慎重に設計されたモデルは、事前にトレーニングされた安定拡散モデルに基づいて構築されており、その優れた特性を十分に学習し、継承しています。これらには、正確な潜在表現のための変分オートエンコーダー (VAE) と強力なノイズ除去ネットワーク U-Net が含まれます。図 1 は、モデルの全体的なアーキテクチャを明確かつ直感的に示しています。
この記事のモデル設計で注目すべき特徴は、事前トレーニングされたモデルの重みを最大限に活用していることです。具体的には、VAE のコンポーネントや U-Net のアップサンプリング層とダウンサンプリング層を含むほとんどのネットワーク層は、安定した拡散モデルの事前トレーニングされた重みを使用して初期化されます。この戦略により、モデルのトレーニング プロセスが大幅に高速化されるだけでなく、モデルが最初から良好な安定性と信頼性を示すことが保証されます。私たちのモデルは、元の潜在的な特徴を再利用し、以前の拡散プロセスを模倣することにより、少数のフレームを含む最初のビデオ クリップから追加のフレームを繰り返し生成できます。さらに、ピクセル空間と潜在空間の間の変換に使用されるオートエンコーダーでは、タイミング関連のネットワーク層をデコーダーに挿入し、これらの層を微調整して時間的一貫性を向上させます。
ビデオ フレーム間の連続性を確保するために、この記事では 3D Temp-conv レイヤーと Temp-attn レイヤーをモデルに追加します。 Temp-conv 層は 3D ResNet に従い、3D 畳み込み演算を実装して空間的および時間的相関を捕捉し、ビデオ シーケンス集約のダイナミクスと連続性を理解します。 Temp-Attn 構造は Self-attention に似ており、ビデオ シーケンス内のフレーム間の関係を分析して理解するために使用され、モデルがフレーム間の実行情報を正確に同期できるようになります。これらのパラメーターはトレーニング中にランダムに初期化され、モデルに時間構造の理解とエンコードを提供するように設計されています。さらに、モデル構造に適応するために、データ入力もそれに応じて適応および調整されています。 #図 2. この記事で提案する高品質の「テキストビデオ」トレーニング データセット構築方法 VidRD モデルをトレーニングするために、この記事では、図 2 に示すように、大規模な「テキスト-ビデオ」トレーニング データセットを構築する方法を提案します。この方法は、「テキスト-画像」データと「 text-video」には説明データがありません。さらに、高品質のビデオ生成を実現するために、この記事ではトレーニング データのウォーターマークを削除することも試みます。 現在の市場では高品質のビデオ記述データセットが比較的不足していますが、多数のビデオ分類データセットが存在します。これらのデータセットには豊富なビデオ コンテンツが含まれており、各ビデオには分類ラベルが付いています。たとえば、Moments-In-Time、Kinetics-700、および VideoLT は、3 つの代表的な大規模ビデオ分類データ セットです。 Kinetics-700 は 700 の人間のアクション カテゴリをカバーし、600,000 を超えるビデオ クリップが含まれています。 Moments-In-Time には 339 のアクション カテゴリが含まれており、合計 100 万を超えるビデオ クリップが含まれています。一方、VideoLT には 1,004 のカテゴリと 250,000 の長い未編集のビデオが含まれています。 既存のビデオ データを最大限に活用するために、この記事では、これらのビデオにさらに詳細な注釈を自動的に付けることを試みます。この記事では、BLIP-2 や MiniGPT4 などのマルチモーダル大規模言語モデルを使用しています。ビデオ内のキー フレームをターゲットにし、元の分類ラベルを組み合わせることで、モデルの質問と回答を通じて注釈を生成するための多くのプロンプトを設計します。この方法は、ビデオ データの音声情報を強化するだけでなく、詳細な説明のない既存のビデオに、より包括的で詳細なビデオ説明をもたらします。これにより、より豊富なビデオ タグの生成が可能になり、VidRD モデルがより優れたトレーニング効果をもたらすことができます。 さらに、この記事では、既存の非常に豊富な画像データについて、トレーニング用に画像データをビデオ形式に変換する詳細な方法も設計しました。具体的な操作は、画像のさまざまな位置でさまざまな速度でパンとズームを行うことです。これにより、各画像に独自の動的な表示形式が与えられ、現実の静止物体をキャプチャするためにカメラを移動する効果がシミュレートされます。この方法により、既存の画像データをビデオトレーニングに有効活用することができます。
最後に、次のようになります。図 3 は、この記事で生成された結果と既存の手法である Make-A-Video [3] および Imagen Video [4] のそれぞれを視覚的に比較したもので、この記事のモデルのより優れた品質生成効果を示しています。 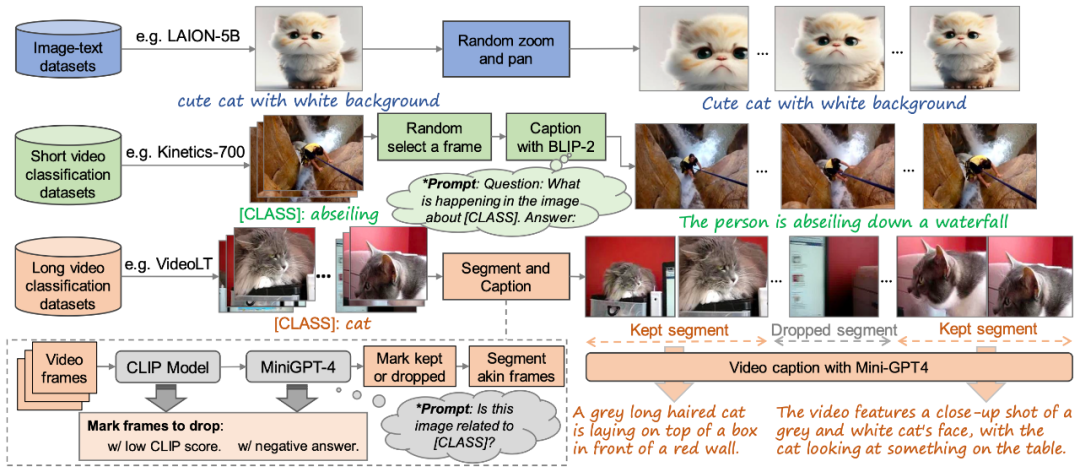
説明文は「空にオーロラが広がる雪国でのタイムラプス」、「キャンドルが燃えている」です。 .」、「夜の輝く街の上空を襲う壮大な竜巻。」、「美しい海の海岸にある白い砂浜の空撮。」さらに多くのビジュアライゼーションはプロジェクトのホームページでご覧いただけます。
 #図 3. 既存の方法との生成効果の視覚的比較
#図 3. 既存の方法との生成効果の視覚的比較
以上が復旦大学とファーウェイ・ノアが反復的な高品質ビデオ生成を実現するVidRDフレームワークを提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1652
1652
 14
1413
52
1304
25
1251
29
1224
24
14
1413
52
1304
25
1251
29
1224
24

 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
