

PyTorch Geometric (PyG) は、グラフ ニューラル ネットワーク モデルを構築し、さまざまなグラフ畳み込みを実験するための主要なツールです。この記事ではリンク予測を通して紹介していきます。

リンク予測は、「どの 2 つのノードを相互にリンクすべきか?」という質問に答えます。「変換分割」を実行して、モデリング用のデータを準備します。バッチ処理用に専用のグラフデータローダーを用意します。 Torch Geometric でモデルを構築し、PyTorch Lightning を使用してモデルをトレーニングし、モデルのパフォーマンスを確認します。
Cora ML 引用データセットを使用します。データセットには、Torch Geometric を通じてアクセスできます。
data = tg.datasets.CitationFull(root="data", name="Cora_ML")
デフォルトでは、Torch Geometric データセットは複数のグラフを返すことができます。単一のグラフがどのようなものかを見てみましょう
data[0] > Data(x=[2995, 2879], edge_index=[2, 16316], y=[2995])
ここで、X はノードの特性です。 edge_index は 2 x (n エッジ) 行列です (最初の次元 = 2、行 0 - ソース ノード/「送信者」、行 1 - ターゲット ノード/「受信者」として解釈されます)。
まず、データセット内のリンクを分割します。グラフ リンクの 20% を検証セットとして使用し、10% をテスト セットとして使用します。このようなネガティブ リンクはバッチ データ ローダーによってオンザフライで作成されるため、ネガティブ サンプルはここではトレーニング データセットに追加されません。
一般に、ネガティブ サンプリングでは「偽の」サンプル (この場合はノード間のリンク) が作成されるため、モデルは本物のリンクと偽のリンクを区別する方法を学習します。ネガティブ サンプリングはサンプリングの理論と数学に基づいており、いくつかの優れた統計的特性を備えています。
最初に、リンク分割オブジェクトを作成しましょう。
link_splitter = tg.transforms.RandomLinkSplit(num_val=0.2, num_test=0.1, add_negative_train_samples=False,disjoint_train_ratio=0.8)
disjoint_train_ratio は、「監視」フェーズでトレーニング情報として使用されるエッジの数を調整します。残りのエッジはメッセージ パッシング (ネットワーク内の情報転送フェーズ) に使用されます。
グラフ ニューラル ネットワークでエッジをセグメント化するには、誘導セグメンテーションと伝導セグメンテーションという少なくとも 2 つの方法があります。この変換方法は、GNN がグラフ構造から構造パターンを学習する必要があることを前提としています。帰納的設定では、ノード/エッジ ラベルを学習に使用できます。この論文の最後には、これらの概念を詳細に説明し、追加の形式化を提供する 2 つの論文があります: ([1]、[3])。
train_g, val_g, test_g = link_splitter(data[0]) > Data(x=[2995, 2879], edge_index=[2, 2285], y=[2995], edge_label=[9137], edge_label_index=[2, 9137])
この操作の後、いくつかの新しい属性が得られます:
edge_label: エッジが true/false であるかどうかを示します。これが私たちが予測したいことです。
edge_label_index は、ノード リンクを格納するために使用される 2 x NUM EDGES マトリックスです。
サンプルの分布を見てみましょう
th.unique(train_g.edge_label, return_counts=True) > (tensor([1.]), tensor([9137])) th.unique(val_g.edge_label, return_counts=True) > (tensor([0., 1.]), tensor([3263, 3263])) th.unique(val_g.edge_label, return_counts=True) > (tensor([0., 1.]), tensor([3263, 3263]))
トレーニング データには負のエッジはありません (トレーニング中に作成します)。val/テスト セットについては、すでに次の比率になっています。 50:50 いくつかの「偽」リンクがあります。
これで、GNN を使用してモデルを構築し、
クラス GNN(nn.Module):
def __init__(self, dim_in: int, conv_sizes: Tuple[int, ...], act_f: nn.Module = th.relu, dropout: float = 0.1,*args, **kwargs):super().__init__()self.dim_in = dim_inself.dim_out = conv_sizes[-1]self.dropout = dropoutself.act_f = act_flast_in = dim_inlayers = [] # Here we build subsequent graph convolutions.for conv_sz in conv_sizes:# Single graph convolution layerconv = tgnn.SAGEConv(in_channels=last_in, out_channels=conv_sz, *args, **kwargs)last_in = conv_szlayers.append(conv)self.layers = nn.ModuleList(layers) def forward(self, x: th.Tensor, edge_index: th.Tensor) -> th.Tensor:h = x# For every graph convolution in the network...for conv in self.layers:# ... perform node embedding via message passingh = conv(h, edge_index)h = self.act_f(h)if self.dropout:h = nn.functional.dropout(h, p=self.dropout, training=self.training)return h
このモデルには価値があります。関心のある部分は、一連のグラフ畳み込みです (この場合は SAGEConv)。 SAGE 畳み込みの正式な定義は次のとおりです:
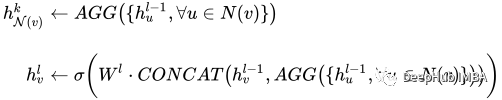 å¾ç
å¾ç
v は現在のノードとノード v の N(v) 近傍ノードです。このタイプの畳み込みの詳細については、GraphSAGE の元の論文を参照してください[1]
準備されたデータを使用してモデルが予測できるかどうかを確認してみましょう。ここでの PyG モデルへの入力は、ノード フィーチャ X の行列と、edge_index を定義するリンクです。
gnn = GNN(train_g.x.size()[1], conv_sizes=[512, 256, 128]) with th.no_grad():out = gnn(train_g.x, train_g.edge_index) out > tensor([[0.0000, 0.0000, 0.0051, ..., 0.0997, 0.0000, 0.0000],[0.0107, 0.0000, 0.0576, ..., 0.0651, 0.0000, 0.0000],[0.0000, 0.0000, 0.0102, ..., 0.0973, 0.0000, 0.0000],...,[0.0000, 0.0000, 0.0549, ..., 0.0671, 0.0000, 0.0000],[0.0000, 0.0000, 0.0166, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0034, ..., 0.1111, 0.0000, 0.0000]])
私たちのモデルの出力は、N ノード x 埋め込みサイズの次元を持つノード埋め込み行列です。
PyTorch Lightning は主にトレーニングに使用されますが、ここではリンクするかどうかを予測するための出力ヘッドとして GNN の出力の後に Linear レイヤーを追加します。
class LinkPredModel(pl.LightningModule):
def __init__(self,dim_in: int,conv_sizes: Tuple[int, ...], act_f: nn.Module = th.relu, dropout: float = 0.1,lr: float = 0.01,*args, **kwargs):super().__init__() # Our inner GNN modelself.gnn = GNN(dim_in, conv_sizes=conv_sizes, act_f=act_f, dropout=dropout) # Final prediction model on links.self.lin_pred = nn.Linear(self.gnn.dim_out, 1)self.lr = lr def forward(self, x: th.Tensor, edge_index: th.Tensor) -> th.Tensor:# Step 1: make node embeddings using GNN.h = self.gnn(x, edge_index) # Take source nodes embeddings- sendersh_src = h[edge_index[0, :]]# Take target node embeddings - receiversh_dst = h[edge_index[1, :]] # Calculate the product between themsrc_dst_mult = h_src * h_dst# Apply non-linearityout = self.lin_pred(src_dst_mult)return out def _step(self, batch: th.Tensor, phase: str='train') -> th.Tensor:yhat_edge = self(batch.x, batch.edge_label_index).squeeze()y = batch.edge_labelloss = nn.functional.binary_cross_entropy_with_logits(input=yhat_edge, target=y)f1 = tm.functional.f1_score(preds=yhat_edge, target=y, task='binary')prec = tm.functional.precision(preds=yhat_edge, target=y, task='binary')recall = tm.functional.recall(preds=yhat_edge, target=y, task='binary') # Watch for logging here - we need to provide batch_size, as (at the time of this implementation)# PL cannot understand the batch size.self.log(f"{phase}_f1", f1, batch_size=batch.edge_label_index.shape[1])self.log(f"{phase}_loss", loss, batch_size=batch.edge_label_index.shape[1])self.log(f"{phase}_precision", prec, batch_size=batch.edge_label_index.shape[1])self.log(f"{phase}_recall", recall, batch_size=batch.edge_label_index.shape[1])return loss def training_step(self, batch, batch_idx):return self._step(batch) def validation_step(self, batch, batch_idx):return self._step(batch, "val") def test_step(self, batch, batch_idx):return self._step(batch, "test") def predict_step(self, batch):x, edge_index = batchreturn self(x, edge_index) def configure_optimizers(self):return th.optim.Adam(self.parameters(), lr=self.lr)PyTorch Lightning の役割は、トレーニング ステップを簡素化することです。必要なのは、いくつかの関数を設定することだけです。次のコマンドを使用して、モデルをテストしますか?
model = LinkPredModel(val_g.x.size()[1], conv_sizes=[512, 256, 128]) with th.no_grad():out = model.predict_step((val_g.x, val_g.edge_label_index))
トレーニング ステップでは、データ ローダーに特別な処理が必要です。
グラフ データには特別な処理、特にリンク予測が必要です。 PyG には、バッチを正しく生成する役割を担う特殊なデータ ローダー クラスがいくつかあります。次の入力を受け入れる tg.loader.LinkNeighborLoader を使用します:
一括ロードされるデータ (画像)。 num_neighbors 1 つの「ホップ」中にノードごとにロードされるネイバーの最大数。近傍数 1 - 2 - 3 -…-K を指定するリスト。特に非常に大きなグラフィックスに役立ちます。
edge_label_index どの属性が真/偽リンクを示しているか。
neg_sampling_ratio - 陰性サンプルと実際のサンプルの比率。
train_loader = tg.loader.LinkNeighborLoader(train_g,num_neighbors=[-1, 10, 5],batch_size=128,edge_label_index=train_g.edge_label_index, # "on the fly" negative sampling creation for batchneg_sampling_ratio=0.5 ) val_loader = tg.loader.LinkNeighborLoader(val_g,num_neighbors=[-1, 10, 5],batch_size=128,edge_label_index=val_g.edge_label_index,edge_label=val_g.edge_label, # negative samples for val set are done already as ground-truthneg_sampling_ratio=0.0 ) test_loader = tg.loader.LinkNeighborLoader(test_g,num_neighbors=[-1, 10, 5],batch_size=128,edge_label_index=test_g.edge_label_index,edge_label=test_g.edge_label, # negative samples for test set are done already as ground-truthneg_sampling_ratio=0.0 )
以下はトレーニング モデルです
model = LinkPredModel(val_g.x.size()[1], conv_sizes=[512, 256, 128]) trainer = pl.Trainer(max_epochs=20, log_every_n_steps=5) # Validate before training - we will see results of untrained model. trainer.validate(model, val_loader) # Train the model trainer.fit(model=model, train_dataloaders=train_loader, val_dataloaders=val_loader)
テスト データを確認し、分類レポートと ROC 曲線を表示します。
with th.no_grad():yhat_test_proba = th.sigmoid(model(test_g.x, test_g.edge_label_index)).squeeze()yhat_test_cls = yhat_test_proba >= 0.5 print(classification_report(y_true=test_g.edge_label, y_pred=yhat_test_cls))
結果はかなり良いようです:
precision recall f1-score support0.0 0.68 0.70 0.69 16311.0 0.69 0.66 0.68 1631accuracy 0.68 3262macro avg 0.68 0.68 0.68 3262
ROC曲线也不错
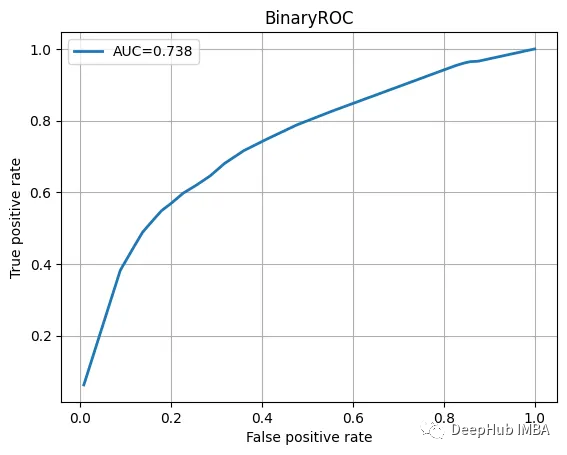
我们训练的模型并不特别复杂,也没有经过精心调整,但它完成了工作。当然这只是一个为了演示使用的小型数据集。
图神经网络尽管看起来很复杂,但是PyTorch Geometric为我们提供了一个很好的解决方案。我们可以直接使用其中内置的模型实现,这方便了我们使用和简化了入门的门槛。
本文代码:https://github.com/maddataanalyst/blogposts_code/blob/main/graph_nns_series/pyg_pyl_perfect_match/pytorch-geometric-lightning-perfect-match.ipynb
以上がPytorch Geometric を使用したリンク予測コードの例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



