

GPT-4 を使用すると、ロボットはペンを回したり、クルミを皿に盛り付けたりする方法を学習しました。

学習という点では、GPT-4 は素晴らしい生徒です。大量の人間データを消化した結果、さまざまな知識を習得しており、チャット中に数学者のテレンス・タオにインスピレーションを与えることもできます。
同時に、優れた教師としても活躍し、本の知識を教えるだけでなく、ロボットにペンの回し方も教えてくれます。

Eureka と呼ばれるこのロボットは、Nvidia、ペンシルバニア大学カリフォルニア工科大学、テキサス大学オースティン校の研究の成果です。この研究は、大規模言語モデルと強化学習に関する研究を組み合わせたものです。GPT-4 は報酬関数の改良に使用され、強化学習はロボット コントローラーのトレーニングに使用されます。
GPT-4 でコードを作成できるため、Eureka は優れた報酬関数設計機能を備えており、独自に生成された報酬は、タスクの 83% において人間の専門家の報酬よりも優れています。この能力により、ロボットは、ペンを回す、引き出しやキャビネットを開ける、ボールを投げたりキャッチしたり、ドリブルしたり、ハサミを操作したりするなど、以前は簡単に完了できなかった多くのタスクを完了できるようになります。ただし、当面はすべて仮想環境で行われます。



#さらに、Eureka は新しいタイプの in-context も実装しています。 RLHF は、人間のオペレーターからの自然言語フィードバックを組み込んで、報酬関数をガイドし、調整することができます。ロボットエンジニアに強力な補助機能を提供し、エンジニアが複雑な動作動作を設計できるように支援します。 NVIDIA の上級 AI 科学者であり、論文の著者の 1 人であるジム ファン氏は、この研究を「物理シミュレータ API 空間におけるボイジャー (米国が開発、建造した外側銀河探査機)」に例えました。

この研究は完全にオープンソースであることを言及する価値があります。オープンソースのアドレスは次のとおりです:

- 紙のリンク: https://arxiv.org/pdf/2310.12931.pdf
- ## プロジェクトリンク: https://eureka-research.github.io/
- コードリンク: https://github.com/eureka-research/ Eureka
大規模言語モデル (LLM) は、ロボット タスクの高レベルのセマンティック プランニングに優れています ( Google SayCan、RT-2 ロボットなど)が、ペンを回すなどの複雑で低レベルの操作タスクを学習するためにそれらを使用できるかどうかは未解決の問題です。既存の試みでは、タスク プロンプトを作成するか、単純なスキルのみを学習するために広範な分野の専門知識が必要であり、人間レベルの柔軟性には遠く及ばない。

一方、強化学習 (RL) は、柔軟性やその他の多くの側面 (OpenAI のルービック キューブを遊ぶロボットハンドなど) において目覚ましい成果を上げていますが、人間による設計が必要です。報酬関数を慎重に構築して、望ましい行動の学習信号を正確に体系化して提供します。現実世界の強化学習タスクの多くは、学習に使用するのが難しいまばらな報酬しか提供しないため、実際には、漸進的な学習信号を提供するために報酬の整形が必要です。報酬関数はその重要性にもかかわらず、設計が難しいことで知られています。最近の調査によると、調査対象となった強化学習の研究者と実践者の 92% が、報酬を設計する際に手動で試行錯誤を行ったと回答し、89% が、設計した報酬は最適ではなく、意図しない結果を招いたと回答しました。
報酬設計が非常に重要であることを考えると、最先端のコーディング LLM (GPT-4 など) を使用して一般的な報酬プログラミング アルゴリズムを開発することは可能でしょうか?と尋ねずにはいられません。これらの LLM は、コード作成、ゼロショット生成、およびコンテキスト内学習において優れたパフォーマンスを発揮し、プログラミング エージェントのパフォーマンスを大幅に向上させました。理想的には、このような報酬設計アルゴリズムは、人間レベルの報酬生成機能を備え、幅広いタスクに拡張可能で、人間の監督なしで退屈な試行錯誤プロセスを自動化すると同時に、安全性を確保するために人間の監督と互換性がある必要があります。 。 本稿では、LLMによる報酬設計アルゴリズムEUREKA(正式名称はEvolution-driven Universal REward Kit for Agent)を提案します。このアルゴリズムは次の成果を達成しました: #1. 報酬設計のパフォーマンスは、10 種類のロボット形式 (四足ロボット、クワッドローターなど) を含む 29 の異なるオープンソース RL 環境で人間のレベルに達しました。ロボット、二足歩行ロボット、マニピュレーター、およびいくつかの器用な手については、図 1 を参照してください。タスク固有のプロンプトや報酬テンプレートを使用しない場合、EUREKA の自律的に生成された報酬は、タスクのエキスパート報酬の 83% で人間を上回り、平均で 52% の正規化された改善を達成しました。 2. 手動の報酬エンジニアリングでは以前は達成できなかった器用さを解決する 運用タスク. ペン回しの問題を例に挙げます。 5本の指でペンを素早く回転させるには、あらかじめ設定された回転設定に従ってペンを素早く回転させ、できるだけ多くのサイクルを回転させる必要があります。学習と組み合わせたコースとEUREKAを組み合わせることで、研究者は擬似擬人化モデル上でペンの高速回転の操作を初めて実証しました。 「シャドウ ハンド」 (図 1 の下部を参照) 3. ヒューマン フィードバックに基づく強化学習 (RLHF) は、より効率的なデータを生成できる新しい勾配なしのコンテキスト学習方法を提供します。論文では、EUREKA が既存の人間の報酬関数から利益を生成し、改善できることを示しています。同様に、研究者らは、人間のテキストによるフィードバックを使用して報酬の設計を支援する EUREKA の能力も実証しました。 LLM を使用して報酬設計を支援した以前の L2R の研究とは異なり、EUREKA には特定のタスク プロンプト、報酬テンプレート、および少数の例がありません。実験では、自由形式の表現力を生成および改善できる能力のおかげで、EUREKA は L2R よりも大幅に優れたパフォーマンスを発揮しました 強力な報酬プログラム。 EUREKA の汎用性は、3 つの主要なアルゴリズム設計の選択肢から恩恵を受けています: コンテキストとしての環境、進化的検索、および報酬の反映。 まず、環境のソース コードをコンテキストとして取得することで、EUREKA はバックボーン エンコーディング LLM のゼロ サンプルから実行可能な報酬関数を生成できます ( GPT-4) その後、EUREKA は、LLM コンテキスト ウィンドウ内で報酬候補のバッチを繰り返し提案し、最も有望な報酬を調整することで、報酬の品質を大幅に向上させます。このコンテキスト内の改善は、ポリシーに基づく報酬である報酬の反映を通じて達成されます。トレーニング統計 高品質のテキストの概要により、自動的かつターゲットを絞った報酬編集が可能 図 3 は、EUREKA のゼロサンプル報酬の例と、最適化プロセス中に蓄積されたさまざまな改善を示しています。 EUREKA が報酬検索を最大限の可能性まで拡張できるようにするために、EUREKA は IsaacGym で GPU 高速化分散強化学習を使用して中間報酬を評価します。これにより、ポリシー学習速度が最大 3 桁向上し、EUREKA は広く適用可能なアルゴリズムとなっています。計算量が増えると当然膨らみます。 #写真 2 に示すとおり。研究者らは、LLM ベースの報酬設計に関するさらなる研究を促進するために、すべてのプロンプト、環境、生成された報酬関数をオープンソース化することに取り組んでいます。 EUREKA は 3 つのアルゴリズム コンポーネントで構成されています: 1) 環境をコンテキストとして使用し、実行可能な報酬のゼロショット生成をサポートします; 2) 進化的検索、反復的に報酬候補を提案および洗練します; 3 )反省に報酬を与え、きめ細かい報酬の改善をサポートします。
コンテキストとしての環境 この記事では、元の環境コードをコンテキストとして直接提供することをお勧めします。 EUREKA は最小限の命令だけで、サンプルをゼロにしてさまざまな環境で報酬を生成できます。 EUREKA 出力の例を図 3 に示します。 EUREKA は、提供された環境コード内の既存の観察変数 (指先の位置など) を巧みに組み合わせて、有効な報酬コードを生成します。環境固有のヒント エンジニアリングや報酬テンプレートはすべて必要ありません。 ただし、生成された報酬は最初の試行で常に実行可能であるとは限りません。また、実行可能であっても最適ではない可能性があります。これにより、単一サンプルの報酬生成の準最適性を効果的に克服するにはどうすればよいかという疑問が生じます。 #進化的探索 次に、この論文では、進化的探索がどのように行われるかを紹介します。前述の次善の解決策などの問題を解決します。これらは、各反復で EUREKA が LLM のいくつかの独立した出力をサンプリングするような方法で洗練されます (アルゴリズム 1 の 5 行目)。各反復 (世代) は独立して同一に分散されるため、サンプル数が増加するにつれて、反復内のすべての報酬関数でエラーが発生する確率は指数関数的に減少します。 ##ボーナス反映 この報酬反映プロセスの構築は非常に簡単ですが、報酬最適化アルゴリズムの依存関係により、この構築方法は非常に重要です。つまり、報酬関数が効率的であるかどうかは、RL アルゴリズムの特定の選択によって影響を受け、同じオプティマイザーの下でも、ハイパーパラメーターが異なると、同じ報酬が大きく異なる動作をする可能性があります。 RL アルゴリズムが個々の報酬コンポーネントを最適化する方法を詳しく説明することで、報酬リフレクションにより、EUREKA はよりターゲットを絞った報酬編集を作成し、固定 RL アルゴリズムとより適切に相乗する報酬関数を合成できるようになります。
実験環境には 10 個の異なるロボットと 29 個のタスクが含まれており、これらの 29 個のタスクは IsaacGym シミュレーターによって実装されています。実験は、IsaacGym (アイザック) の 9 つのオリジナル環境を使用して行われ、四足歩行、二足歩行、クアッドコプター、マニピュレーター、器用なロボットの手など、さまざまなロボット形態をカバーしました。これに加えて、このペーパーでは、Dexterity ベンチマークからの 20 のタスクを含めることで、評価の深さを確保しています。
#ロボットの器用な手がペンを継続的に回転できるようにするには、動作プログラムにできるだけ多くのサイクルが必要です。この論文では、(1) ペンをランダムなターゲット構成にリダイレクトするために使用される報酬関数を生成するように Eureka に指示し、(2) Eureka の報酬を使用してこの事前トレーニングされたポリシーを微調整して、目的のペン シーケンスの回転を達成することで、このタスクに対処します。構成。 。図に示すように、エウレカ スピナーは戦略にすぐに適応し、連続して多くのサイクルを回転させることに成功しました。対照的に、事前トレーニングされたポリシーも最初から学習されたポリシーも、ローテーションの単一エポックを完了することはできません。 #この論文では、人間の報酬関数の初期化から始めることが Eureka にとって有利かどうかも調査します。示されているように、エウレカは人間の報酬の質に関係なく、人間の報酬から改善し、恩恵を受けます。 Eureka は、人間のフィードバックを組み合わせて報酬を変更できる RLHF も実装しています。これにより、エージェントがより安全でより人間に優しいタスクを完了するように徐々に誘導されます。行動。この例では、Eureka が、以前の自動報酬反映を置き換える人間のフィードバックを使用して、人型ロボットに直立走行を教える方法を示しています。 人型ロボットはエウレカを通じて走行歩行を学習します。 詳細については、元の論文を参照してください。 


EUREKA は、特に報酬アルゴリズムを独自に作成できます。これを実現する方法を以下で見てみましょう。




実験部分では、報酬を生成する機能を含む、エウレカの総合的な評価を行います。機能 、新しいタスクを解決する能力、およびさまざまな人間の入力を統合する能力。
 #Eureka は超人レベルの報酬関数を生成できます。 29 のタスク全体で、Eureka によって与えられた報酬関数は、タスクの 83% で専門家によって作成された報酬よりも優れたパフォーマンスを示し、平均で 52% の改善が見られました。特に、Eureka は高次元の Dexterity ベンチマーク環境で大きな向上を実現します。
#Eureka は超人レベルの報酬関数を生成できます。 29 のタスク全体で、Eureka によって与えられた報酬関数は、タスクの 83% で専門家によって作成された報酬よりも優れたパフォーマンスを示し、平均で 52% の改善が見られました。特に、Eureka は高次元の Dexterity ベンチマーク環境で大きな向上を実現します。  Eureka は報酬検索を進化させることができるため、時間の経過とともに報酬が向上し続けます。大規模な報酬探索と詳細な報酬反映フィードバックを組み合わせることで、エウレカは徐々により良い報酬を生み出し、最終的には人間のレベルを超えます。
Eureka は報酬検索を進化させることができるため、時間の経過とともに報酬が向上し続けます。大規模な報酬探索と詳細な報酬反映フィードバックを組み合わせることで、エウレカは徐々により良い報酬を生み出し、最終的には人間のレベルを超えます。 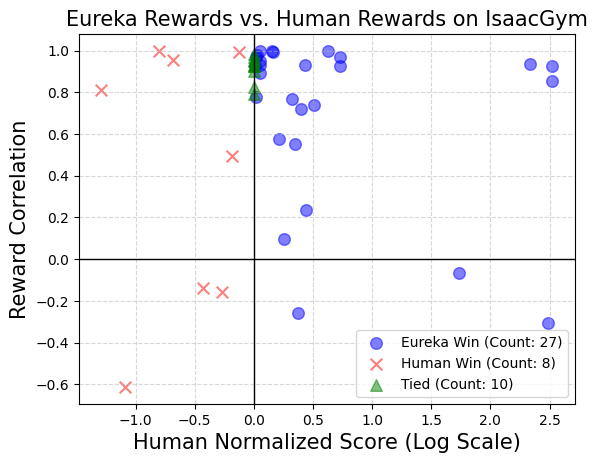 Eureka は新しい報酬も生成します。この論文は、すべての Isaac タスクにおける Eureka 報酬と人間の報酬の間の相関を計算することによって、Eureka 報酬の新規性を評価します。図に示すように、Eureka は主に弱相関の報酬関数を生成し、人間の報酬関数よりも優れた性能を発揮します。さらに、タスクが難しいほど、エウレカの報酬の関連性が低くなることが観察されています。場合によっては、エウレカの報酬は人間の報酬と負の相関があるにもかかわらず、それを大幅に上回っていました。
Eureka は新しい報酬も生成します。この論文は、すべての Isaac タスクにおける Eureka 報酬と人間の報酬の間の相関を計算することによって、Eureka 報酬の新規性を評価します。図に示すように、Eureka は主に弱相関の報酬関数を生成し、人間の報酬関数よりも優れた性能を発揮します。さらに、タスクが難しいほど、エウレカの報酬の関連性が低くなることが観察されています。場合によっては、エウレカの報酬は人間の報酬と負の相関があるにもかかわらず、それを大幅に上回っていました。 


以上がGPT-4 を使用すると、ロボットはペンを回したり、クルミを皿に盛り付けたりする方法を学習しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7455
7455
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
