

Tsinghua Zhu Wenwu のチーム: AutoGL-light、オープンソースのグラフ用の世界初の軽量自動機械学習ライブラリ

2020 年の AutoGL のリリース以来、清華大学の Zhu Wenwu 教授のチームは、特にグラフ トランスフォーマー、グラフ アウトの観点から、自動グラフ機械学習の解釈可能性と一般化可能性において新たな進歩を遂げてきました。分布一般化 (OOD)、グラフ自己教師あり学習などの研究において、グラフ ニューラル アーキテクチャの検索および評価ベンチマークが公開され、中国の新世代オープン ソースである初の軽量インテリジェンス ライブラリ (AutoGL-light) が GitLink でリリースされました。イノベーションサービスプラットフォーム。
インテリジェンス データベースのレビュー
グラフは、データ間の関係を説明する一般的な抽象概念であり、さまざまな研究分野に広く存在しており、多くの重要な要素があります。ソーシャル ネットワーク分析、レコメンデーション システム、交通量予測などのインターネット アプリケーション、新薬発見、新材料調製などの科学アプリケーション (AI for Science) などのアプリケーションは、さまざまな分野をカバーしています。グラフ機械学習は近年広く注目を集めています。異なるグラフ データは構造、性質、タスクが大きく異なるため、手動で設計された既存のグラフ機械学習モデルには、さまざまなシナリオや環境の変化に一般化する機能がありません。 AutoML on Graphs は、グラフ機械学習開発の最前線です。与えられたデータとタスクに対して最適なグラフ機械学習モデルを自動的に設計することを目的としています。研究と応用の両方で非常に価値があります。
グラフの自動機械学習の問題に対応して、清華大学の朱文武教授のチームは 2017 年に計画を開始し、2020 年に世界初のグラフの自動機械学習である AutoGL をリリースしました。機械学習のプラットフォームとツールキット。
プロジェクト アドレス: https://github.com/THUMNLab/AutoGL
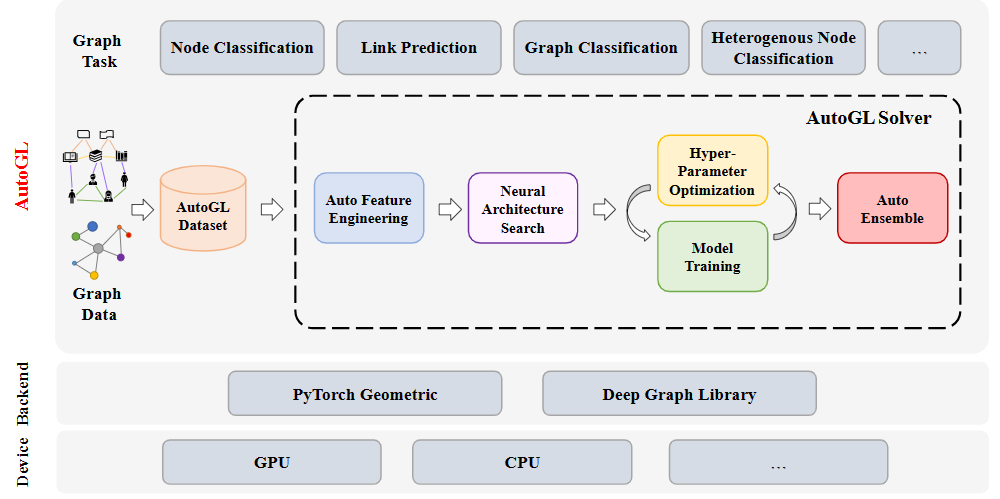
スマート ライブラリGitHub で 1000 を超えるスターを獲得し、20 以上の国と地域から数万の訪問を集め、GitLink で公開されました。スマート ライブラリには、主流のグラフ自動機械学習方法をカバーする、グラフ自動機械学習プロセスの完全なセットが含まれています。 Zhitu は、グラフ自動機械学習ソリューション AutoGL Solver を通じて、グラフ上の自動機械学習を 5 つのコア部分に分割します。グラフ自動特徴量エンジニアリング、グラフ ニューラル アーキテクチャ検索 (NAS)、グラフ ハイパーパラメータ最適化 (HPO)、グラフ モデル トレーニング、および自動グラフモデルの統合。スマート ライブラリは、ノード分類、異種グラフ ノード分類、リンク予測、グラフ分類など、さまざまな種類のグラフ タスクをすでにサポートしています。
グラフ自動機械学習研究の新たな進歩
グラフ自動機械学習の解釈可能性と一般化可能性が現在のところ欠如していることを考慮して、インテリジェント インテリジェンスグラフ チームは、グラフ自動機械学習の研究において一連の新たな進歩を遂げました。
1. グラフの分布外汎化 (OOD) アーキテクチャの検索
グラフのニューラル アーキテクチャの検索はできません。プロセスグラフ データ分布変化の問題を解決するために, 分離自己教師あり学習に基づくグラフニューラルアーキテクチャ探索手法を提案する. グラフサンプルごとに適切なグラフニューラルネットワークアーキテクチャをカスタマイズすることで, グラフニューラルアーキテクチャ探索手法の適応性を高めるデータ分散シフトの処理が効果的に強化されます。この成果は、機械学習に関するトップ国際会議である ICML 2022 で発表されました。

論文アドレス: https://proceedings.mlr.press/v162/qin22b/qin22b.pdf
2. 大規模なグラフ アーキテクチャの検索
既存のグラフ ニューラル アーキテクチャの検索では大規模なグラフを処理できないという問題を解決するには、アーキテクチャ サブグラフを使用します。サンプリングメカニズムのスーパーネットワークトレーニング方法は、重要度サンプリングとピア学習アルゴリズムを通じてサンプリングプロセスの一貫性ボトルネックを突破し、グラフニューラルアーキテクチャ検索の効率を大幅に向上させ、初めて単一マシンを達成します。 1億スケールの実グラフデータを処理できます。この成果は、機械学習に関するトップ国際会議である ICML 2022 で発表されました。

#論文アドレス: https://proceedings.mlr.press/v162/guan22d.html
3. グラフニューラルアーキテクチャ検索評価ベンチマーク
グラフ ニューラル アーキテクチャ検索の統一された評価基準の欠如と、評価プロセスで消費される膨大なコンピューティング リソースを考慮して、Zhitu チームはグラフ ニューラル アーキテクチャ検索ベンチマーク NAS-Bench-Graph を調査し、提案しました。これは、最初のグラフ ニューラル アーキテクチャ検索ベンチマークです。ニューラル アーキテクチャ検索用の表形式のベンチマークです。このベンチマークは、さまざまなグラフ ニューラル アーキテクチャ検索方法を効率的、公平かつ再現性よく比較でき、グラフ データ アーキテクチャ検索のベンチマークが存在しないギャップを埋めることができます。 NAS-Bench-Graph は、さまざまなサイズとタイプの 9 つの一般的に使用されるノード分類グラフ データを使用して、26,206 の異なるグラフ ニューラル ネットワーク アーキテクチャを含む検索空間を設計し、再現性と公正な比較を確保しながら、完全にトレーニングされたモデル効果を提供します。コンピューティングリソースが大幅に削減されます。この成果は、機械学習に関するトップ国際会議である NeurIPS 2022 で発表されました。

# プロジェクトアドレス: https://github.com/THUMNLab/NAS-Bench-Graph
#4. 自動グラフ トランスフォーマー
現在の手動で設計されたグラフ トランスフォーマー アーキテクチャでは最高の予測パフォーマンスを達成することが難しいという問題を考慮して、自動グラフ トランスフォーマーアーキテクチャ検索フレームワークを提案します. 統合されたグラフ Transformer 検索スペースと構造を意識したパフォーマンス評価戦略により、最適なグラフ Transformer の設計には時間がかかり、最適なアーキテクチャを取得するのが難しいという問題が解決されます. この研究は、トップの ICLR 2023 で公開されました機械学習に関する国際会議。

##5. 堅牢なグラフ ニューラル アーキテクチャ検索
現在のグラフ ニューラル アーキテクチャ検索では敵対的攻撃に対処できないという問題に向けて、堅牢なグラフ ニューラル アーキテクチャ検索手法を提案します。検索 堅牢なグラフ演算子が空間に追加され、検索プロセス中に堅牢性評価指標が提案され、敵対的な攻撃に耐えるグラフ ニューラル アーキテクチャ検索の能力が強化されます。この成果は、パターン認識に関するトップ国際会議である CVPR 2023 で発表されました。
 #論文アドレス: https://openaccess.thecvf.com/content/CVPR2023/papers/Xie_Adversarily_Robust_Neural_Architecture_Search_for_Graph_Neural_Networks_CVPR_2023_paper.pdf
#論文アドレス: https://openaccess.thecvf.com/content/CVPR2023/papers/Xie_Adversarily_Robust_Neural_Architecture_Search_for_Graph_Neural_Networks_CVPR_2023_paper.pdf
6. 自己教師ありグラフ ニューラル アーキテクチャ検索
既存のグラフ ニューラル アーキテクチャ検索は、アーキテクチャのトレーニングと検索の指標としてラベルに大きく依存しています。ラベルが不足しているシナリオでのグラフに対する自動機械学習の適用。この問題に対応して、Zhitu チームは自己教師ありグラフ ニューラル アーキテクチャの検索方法を提案し、グラフ データ形成を駆動するグラフ要素と最適なニューラル アーキテクチャの間の潜在的な関係を発見し、新しい分離された自己教師ありグラフ ニューラル アーキテクチャを採用しました。探索モデルは、ラベルなしのグラフデータに対して最適なアーキテクチャを効率的に探索することを実現します。この成果は、機械学習に関するトップカンファレンスである NeurIPS 2023 に採択されました。

既存のターゲットをターゲットにするグラフ ニューラル ネットワーク アーキテクチャの検索では、タスクごとのアーキテクチャ要件の違いを考慮することができません。Zhitu チームは、最初のマルチタスク グラフ ニューラル ネットワーク アーキテクチャの検索方法を提案しました。これは、異なるグラフ タスクに対して同時に最適なアーキテクチャを設計し、コース学習を使用します。それらの間の協力関係により、異なるグラフ タスクをカスタマイズするための最適なアーキテクチャが効果的に実現されます。この成果は、機械学習に関するトップカンファレンスである NeurIPS 2023 に採択されました。
 軽量インテリジェント マップ
軽量インテリジェント マップ
上記の研究の進捗状況に基づいて、インテリジェント マップ チームはオープンなマップを指定しました。 CCF のソース プラットフォーム GitLink は、世界初の軽量グラフ自動機械学習オープン ソース ライブラリである AutoGL-light をリリースしました。その全体的なアーキテクチャ図を図 1 に示します。軽量スマート グラフには、主に次の特徴があります。
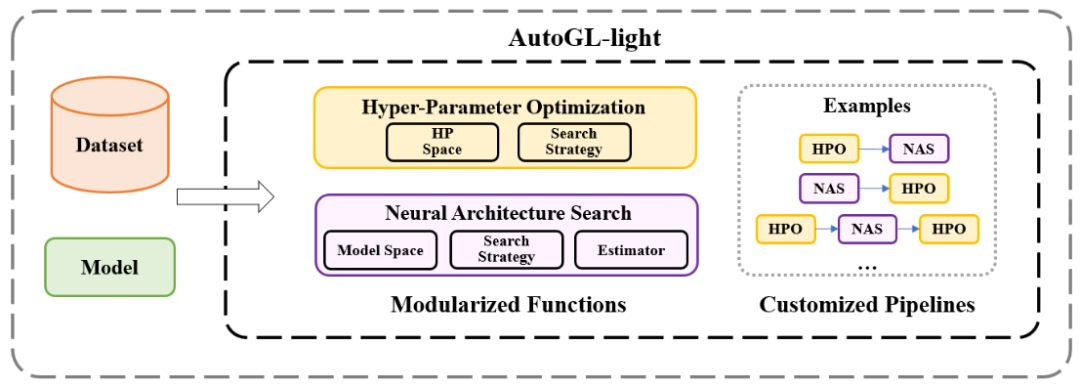 図 1. 軽量スマート グラフのフレームワーク図
図 1. 軽量スマート グラフのフレームワーク図
#
プロジェクトアドレス: https://gitlink.org.cn/THUMNLab/AutoGL-light
1. モジュールの分離
Lightweight Intelligent Graph は、より包括的なモジュール分離方法を通じて、さまざまなグラフの自動機械学習パイプラインのより便利なサポートを実現し、機械学習プロセスのどのステップでもモジュールを自由に追加してニーズを満たすことができます。ユーザーのカスタマイズされたニーズ。
2. 自己カスタマイズ機能
軽量インテリジェンス ライブラリは、ユーザーがカスタマイズしたグラフ ハイパーパラメータ最適化 (HPO) とグラフ ニューラル アーキテクチャ検索 (NAS)。グラフ ハイパーパラメータ最適化モジュールでは、Lightweight Intelligent Graph がさまざまなハイパーパラメータ最適化アルゴリズムと検索スペースを提供し、基本クラスを継承することでユーザーが独自の検索スペースを作成できるようにします。グラフ ニューラル アーキテクチャ検索モジュールでは、軽量スマート グラフが典型的かつ最先端の検索アルゴリズムを実装しており、ユーザーは自分のニーズに応じて検索スペース、検索戦略、評価戦略のモジュール設計を簡単に組み合わせてカスタマイズできます。
3. 幅広い応用分野
軽量インテリジェント グラフの応用は、従来のグラフ マシンに限定されません。学習タスクに加えて、さらに幅広い応用分野に拡張されました。現在、軽量スマート マップは、分子マップや単一細胞オミクス データなどの科学向け AI アプリケーションをすでにサポートしています。将来的には、Lightweight Intelligent Graph は、さまざまな分野のグラフ データに対する最先端のグラフ自動機械学習ソリューションを提供したいと考えています。
4. GitLink プログラミング サマー キャンプ
Lightweight Smart Map の機会を利用して、Smart Map チームは、 GitLink プログラミング サマー キャンプ (GLCC) への参加は、CCF 中国コンピュータ連盟の指導の下、CCF オープンソース開発委員会 (CCF ODC) が主催する、全国の大学生を対象とした夏季プログラミング活動です。 Zhitu チームの 2 つのプロジェクト、「GraphNAS アルゴリズムの再現」と「グラフ自動学習科学分野での応用事例」には、国内 10 以上の大学の学部生と大学院生が参加申し込みをしました。
サマーキャンプ中、Zhitu チームは参加学生と積極的にコミュニケーションを図り、作業の進捗は予想を上回りました。その中で、GraphNAS アルゴリズム複製プロジェクトは、前述のグラフ分布外の一般化アーキテクチャ検索 (ICML'22)、大規模グラフ アーキテクチャ検索 (ICML'22)、および自動グラフ Transformer (ICLR'23) を軽量で実装することに成功しました。インテリジェント グラフ。) を使用して、軽量のシンク ライブラリの柔軟性と独立したカスタマイズ機能を効果的に検証します。
グラフ自動機械学習科学応用プロジェクトは、単一細胞 RNA 配列解析の代表的なアルゴリズム scGNN、代表的な MolCLR を含む、軽量のインテリジェント グラフ上にグラフベースの生物学的情報処理アルゴリズムを実装します。分子表現学習のアルゴリズムである AutoGNNUQ と分子構造予測の代表的なアルゴリズムである AutoGNNUQ は、AI for Science におけるグラフ自動機械学習技術の適用を促進します。 GitLink プログラミング サマー キャンプでは、Lightweight Intelligent Graph によってアルゴリズムとアプリケーション ケースが充実するだけでなく、参加する学生がオープンソース ソフトウェア開発やその他のスキルを実践し、グラフ自動機械学習の才能を育成し、我が国のオープン プログラミングの発展に貢献することもできます。根源的なエコロジー構造、自らの強み。
Zhitu チームは、清華大学コンピューター サイエンス学部の Zhu Wenwu 教授が率いるネットワークおよびメディア研究所の出身で、中心メンバーには、Wang Xin 助教授、Zhang Ziwei 博士研究員が含まれています。 、博士課程のLi Haoyang、Qin Yijian、Zhang Zeyang、修士課程のGuan Chaoyuと10人以上がいます。このプロジェクトは、中国国家自然科学財団と科学技術省から強力な支援を受けています。
以上がTsinghua Zhu Wenwu のチーム: AutoGL-light、オープンソースのグラフ用の世界初の軽量自動機械学習ライブラリの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 特定のシステムバージョンでMySQLが報告したエラーのソリューション
Apr 08, 2025 am 11:54 AM
特定のシステムバージョンでMySQLが報告したエラーのソリューション
Apr 08, 2025 am 11:54 AM
MySQLのインストールエラーのソリューションは次のとおりです。1。システム環境を慎重に確認して、MySQL依存関係ライブラリの要件が満たされていることを確認します。異なるオペレーティングシステムとバージョンの要件は異なります。 2.エラーメッセージを慎重に読み取り、依存関係のインストールやSUDOコマンドの使用など、プロンプト(ライブラリファイルの欠落やアクセス許可など)に従って対応する測定値を取得します。 3.必要に応じて、ソースコードをインストールし、コンパイルログを慎重に確認してみてください。これには、一定量のLinuxの知識と経験が必要です。最終的に問題を解決する鍵は、システム環境とエラー情報を慎重に確認し、公式の文書を参照することです。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 mysqlをインストールするときに依存関係が欠落の問題を解決する方法
Apr 08, 2025 pm 12:00 PM
mysqlをインストールするときに依存関係が欠落の問題を解決する方法
Apr 08, 2025 pm 12:00 PM
MySQLのインストール障害は、通常、依存関係の欠如によって引き起こされます。解決策:1。システムパッケージマネージャー(Linux APT、YUM、DNF、Windows VisualC Redistributableなど)を使用して、sudoaptinStalllibmysqlclient-devなどの欠落している依存関係ライブラリをインストールします。 2.エラー情報を慎重に確認し、複雑な依存関係を1つずつ解決します。 3.パッケージマネージャーのソースが正しく構成され、ネットワークにアクセスできることを確認します。 4. Windowsの場合は、必要なランタイムライブラリをダウンロードしてインストールします。公式文書を読んで検索エンジンを適切に使用する習慣を開発することは、問題を効果的に解決することができます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
