

著者: Ye Xiaofei
リンク: https://www.zhihu.com/question/269707221/answer/2281374258
Iメルセデス ベンツが北米で発売されたとき、さまざまな構造とパラメーターをテストするための期間がありました。1 週間で 100 以上の異なるモデルをトレーニングできました。この目的のために、会社の先輩たちの実践と私自身の考えと要約を組み合わせて、一連の効率的なコード実験管理方法を開発し、プロジェクトの実装を首尾よく支援しましたので、ここで共有します。
多くのオープン ソース リポジトリが、入力 argparse を使用して多くのトレーニングおよびモデル関連のパラメーターを送信することを好むことはわかっていますが、これは実際には非常に非効率です。トレーニングのたびに大量のパラメータを手動で入力するのは面倒な一方で、デフォルト値を直接変更してからコードにアクセスして変更すると、非常に時間がかかります。ここでは、有名な 3D 点群の場合と同様に、Yaml ファイルを直接使用してすべてのモデルとトレーニング関連のパラメーターを制御し、Yaml の名前をモデル名とタイムスタンプにリンクすることをお勧めします 検出ライブラリ OpenPCDet 以下のリンクのように作成しました。
github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yaml上記のリンクから yaml ファイルの一部を切り取りました。図に示すように、この構成ファイルには、点群の前処理方法、分類の種類、バックボーンのさまざまなパラメータ、オプティマイザと損失の選択が含まれます (図には示されていません。詳細については、上のリンクを参照してください)。完全な情報)。言い換えると、基本的に、モデルに影響を与える可能性のあるすべての要素がこのファイルに含まれています。コードでは、単純な yaml.load() を使用するだけでこれらの要素が読み込まれます。辞書。さらに重要なのは、 この構成ファイルはチェックポイントと同じフォルダーに保存できるため、ブレークポイントのトレーニング、微調整、または直接テストに直接使用できます。また、テストにも使用できます。一致させるのに非常に便利です。結果と対応するパラメータ。

これにより、コードでのトレーニング中にどのモデルまたはサブモデルを使用するかを決定する必要がなくなりますが、yaml で直接定義できます。
Tensorboard と tqdm の使い方私は基本的にこの 2 つのライブラリを毎回使用します。 Tensorboard はトレーニングの損失曲線の変化を非常によく追跡できるため、モデルがまだ収束していて過学習しているかどうかを簡単に判断できます。画像関連の作業を行っている場合は、視覚化の結果をそれに追加することもできます。多くの場合、基本的にモデルの動作を知るには、テンソルボードの収束ステータスを見るだけで十分です。テストと微調整に個別に時間を費やす必要がありますか? Tqdm を使用すると、トレーニングの進行状況を直感的に追跡できるため、トレーニングの進行状況を簡単に追跡できます。 .Github を最大限に活用する複数の人々との共同開発に取り組んでいる場合でも、単独のプロジェクトに取り組んでいる場合でも、Github を使用することを強くお勧めします (会社は bitbucket を使用する場合があります)。多かれ少なかれ)コードを記録します。詳細については、私の回答を参照してください: 大学院生として、どのような科学研究ツールが役立つと思いますか?https://www.zhihu.com/question/484596211/answer/2163122684
リンク: https://www.zhihu.com/question/269707221/answer/470576066
一方で、何千ものバージョンをテストした後では、どのモデルにどのパラメータがあるか分からなくなると思います。良い習慣は非常に効果的です。さらに、古いバージョンの構成ファイルの呼び出しを容易にするために、新しく追加されたパラメータにデフォルト値を提供するようにしてください。
同じプロジェクト内では、再利用性が優れていることは非常に良いプログラミング習慣ですが、急速に発展している DL コーディングでは、プロジェクトがタスク駆動であると仮定すると、これは場合によっては障害になる可能性があるため、再利用可能な機能をいくつか抽出し、さまざまなモデルをモデル構造に関連するさまざまなファイルに分離するようにしてください。ただし、将来の更新でより便利になります。そうしないと、一見美しいデザインでも数か月後には役に立たなくなってしまいます。
恥ずかしい状況になることもよくあります。いくつかのバージョンが更新されており、新しいバージョンでは切望されている機能がいくつかありますが、残念ながら一部の API が変更されています。したがって、プロジェクト内でフレームワークのバージョンを安定させるように努めることができます。プロジェクトを開始する前に、さまざまなバージョンの長所と短所を検討してください。場合によっては、適切な学習が必要です。
さらに、さまざまな枠組みに対して寛容な心を持ちましょう。
著者: OpenMMLab
リンク: https://www.zhihu.com/question/269707221/answer/2480772257
出典: Zhihu
著作権は著者に属します。商業転載の場合は作者に許可を、非商業転載の場合は出典を明記してください。
こんにちは、質問者さん。前の回答では、実験データを管理するための Tensorboard、Weights&Biases、MLFlow、Neptune などのツールの使用について言及しています。ただし、実験管理ツール用に構築されるホイールが増えるにつれて、ツールを学習するコストがますます高くなっています。
MMCV はあなたの空想をすべて満たすことができ、構成ファイルを変更することでツールを切り替えることができます。
github.com/open-mmlab/mmcv
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
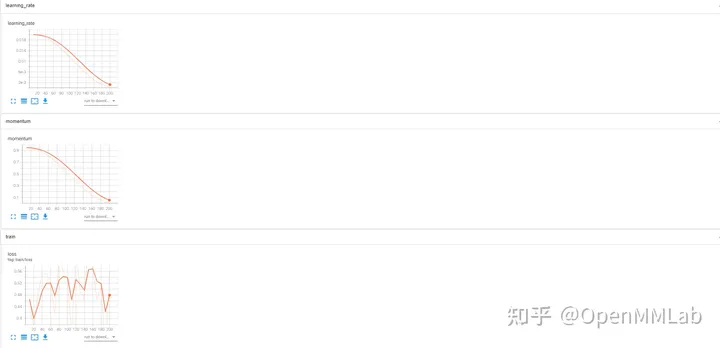
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
(事前に Python API で wandb にログインする必要があります)
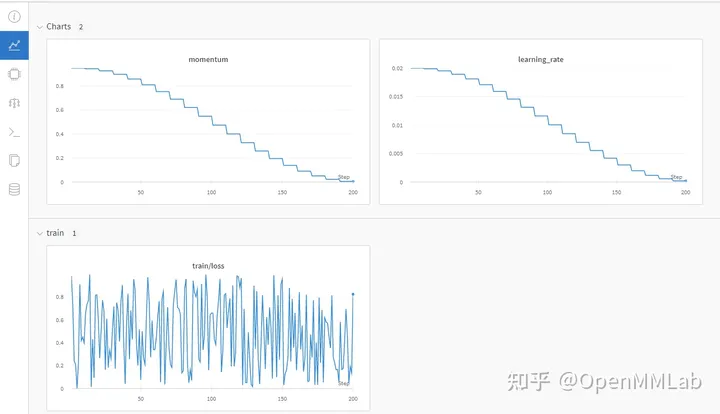
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
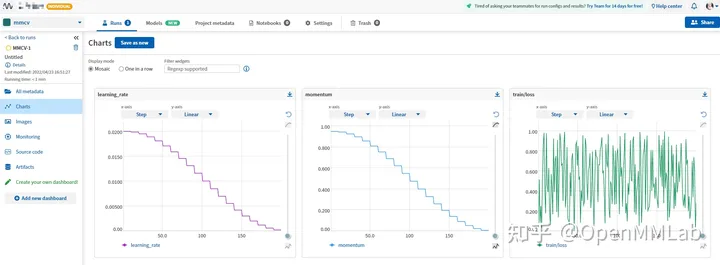
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
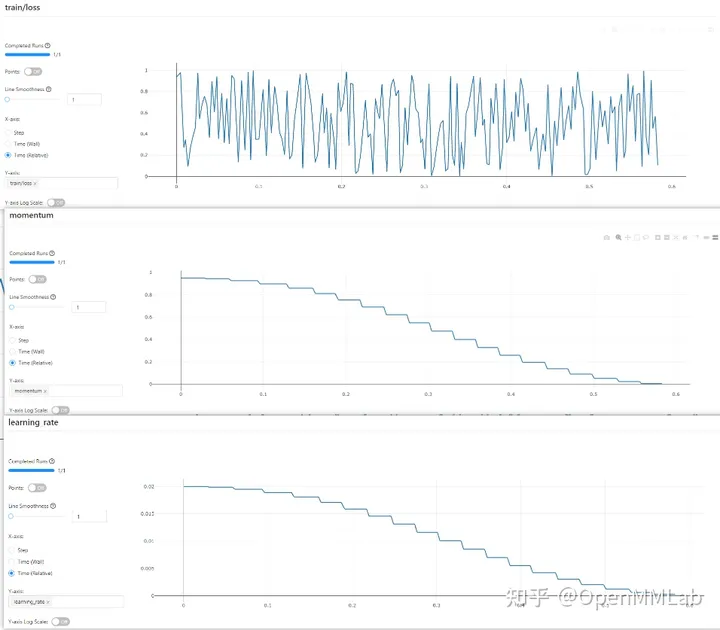
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
上記は、さまざまな実験用管理ツールの最も基本的な機能のみを使用していますが、構成ファイルをさらに変更して、より多くの姿勢のロックを解除することができます。
MMCV を所有することは、すべての実験用管理ツールを所有することと同じです。あなたが以前 TF 少年だった場合は、TensorBoard の古典的なノスタルジックなスタイルを選択できます。すべての実験データと実験環境を記録したい場合は、Wandb (Weights & Biases) または Neptume を試してください。デバイスがインターネットに接続されている場合は、mlflow を選択して実験データをローカルに保存することができ、最適なツールが常に存在します。
さらに、MMCV には独自のログ管理システム ( TextLoggerHook ) もあります。デバイス環境、データセット、モデルの初期化方法、損失、メトリック、トレーニング中に生成されるその他の情報など、トレーニング プロセス中に生成されるすべての情報がローカルの xxx.log ファイルに保存されます。ツールを使用せずに、以前の実験データを確認できます。
どの実験管理ツールを使用すればよいかまだ迷っていますか?さまざまなツールの学習コストがまだ心配ですか?急いで MMCV に乗り出し、わずか数行の設定ファイルでさまざまなツールを簡単に体験してください。
github.com/open-mmlab/mmcv
以上がディープラーニングの科学研究において、コードと実験を効率的に管理するにはどうすればよいでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



