
 テクノロジー周辺機器
AI
長いテキストは 4k ウィンドウの長さで読むことができます。Chen Danqi と彼の弟子たちは Meta と協力して、大きなモデルのメモリを強化する新しい方法を開始しました。
テクノロジー周辺機器
AI
長いテキストは 4k ウィンドウの長さで読むことができます。Chen Danqi と彼の弟子たちは Meta と協力して、大きなモデルのメモリを強化する新しい方法を開始しました。
長いテキストは 4k ウィンドウの長さで読むことができます。Chen Danqi と彼の弟子たちは Meta と協力して、大きなモデルのメモリを強化する新しい方法を開始しました。

ウィンドウの長さが 4K しかない大きなモデルでも、テキストの大部分を読み取ることができます。
プリンストン大学の中国人博士学生による最新の成果は、大型モデルのウィンドウ長の制限を「突破」することに成功しました。
さまざまな質問に答えることができるだけでなく、実装プロセス全体 は、追加のトレーニング を必要とせず、プロンプトによって完全に完了できます。

研究チームは、モデル自体のウィンドウ長制限を突破できる MemWalker と呼ばれるツリー メモリ戦略を作成しました。
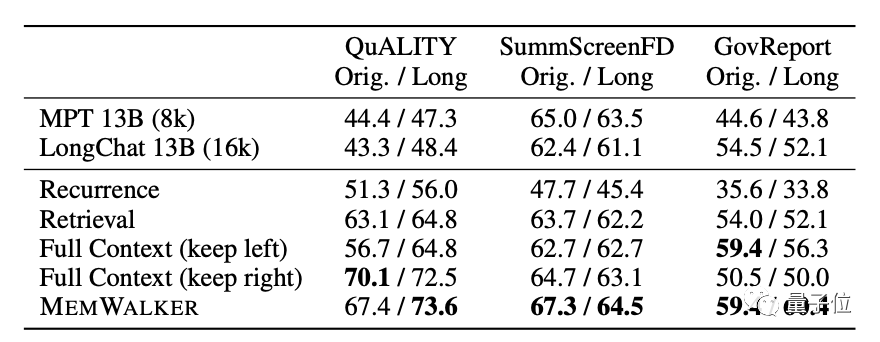
テスト中、モデルによって読み取られた最長のテキストには 12,000 個のトークンが含まれており、結果は LongChat と比較して大幅に改善されました。
同様の TreeIndex と比較すると、MemWalker は単に一般化するのではなく、あらゆる質問を推論して答えることができます。
MemWalker の研究開発では「分割統治」の考え方が活用されており、一部のネチズンは次のようにコメントしています:
大型モデルの思考プロセスをより人間らしくするたびに

#それでは、ツリー メモリ戦略とは具体的に何で、限られたウィンドウ長で長いテキストをどのように読み取るのでしょうか?
1 つのウィンドウでは不十分です。もう少し開いてください。
モデルでは、MemWalker は基本モデルとして Stable Beluga 2 を使用します。これは、コマンド チューニングを通じて Llama 2-70B によって取得されます。
このモデルを選択する前に、開発者はオリジナルの Llama 2 とそのパフォーマンスを比較し、最終的に選択を決定しました。
MemWalker という名前のように、その動作プロセスは記憶の流れのようなものです。
具体的には、メモリツリー構築とナビゲーション検索の2段階に大別されます。
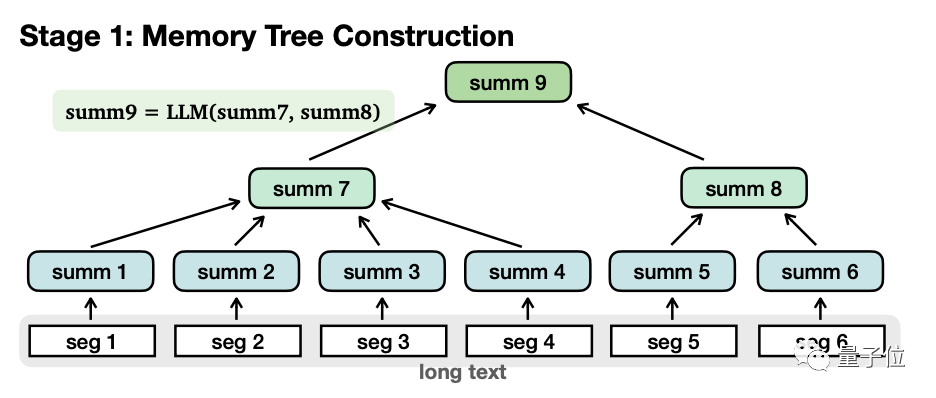
メモリ ツリーを構築するとき、長いテキストは複数の小さなセグメント (seg1-6) に分割され、大きなモデルは次のことを行います。各セグメントを個別に処理します。サマリーから、「リーフ ノード 」(リーフ ノード、合計 1-6) を取得します。
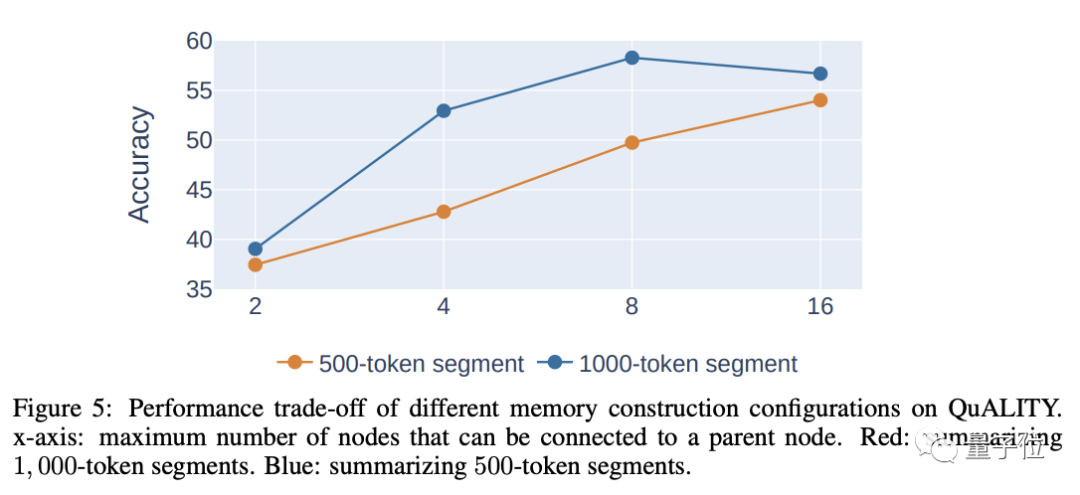
セグメント化する場合、各セグメントが長いほどレベルが少なくなり、その後の検索に有利ですが、長すぎると精度の低下につながるため、総合的に考慮してください。各セグメントの長さを決定するために必要です。
著者は、各段落の適切な長さは 500 ~ 2000 トークンであると考えており、実験で使用したものは 1000 トークンです。
次に、モデルはこれらのリーフ ノードの内容を再帰的に要約して、「非リーフ ノード」## を形成します。 #(非リーフノード、合計7-8)。
この 2 つのもう 1 つの違いは、リーフ ノードには元の情報 が含まれるのに対し、非リーフ ノードには 要約された二次情報 しか含まれないことです。
機能的には、非リーフ ノードは、答えがあるリーフ ノードをナビゲートして特定するために使用され、リーフ ノードは、答えについて推論するために使用されます。 非リーフ ノードは複数のレベルを持つことができ、モデルは「ルート ノード」が取得されて完全なツリー構造が形成されるまで徐々に要約されます。 メモリ ツリーが確立されたら、ナビゲーション検索段階に入り、答えを生成できます。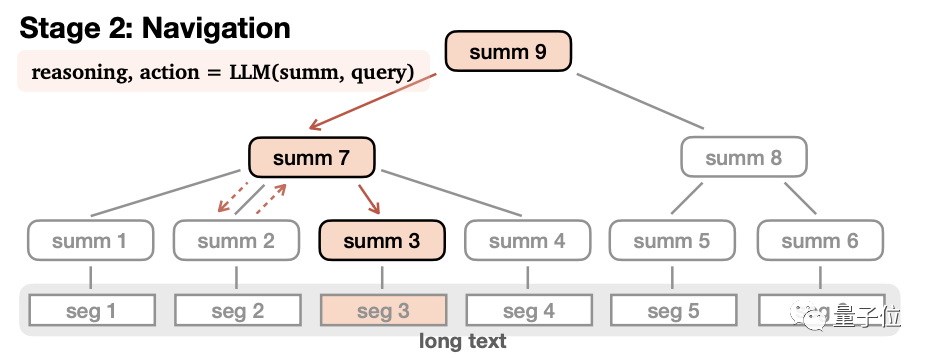
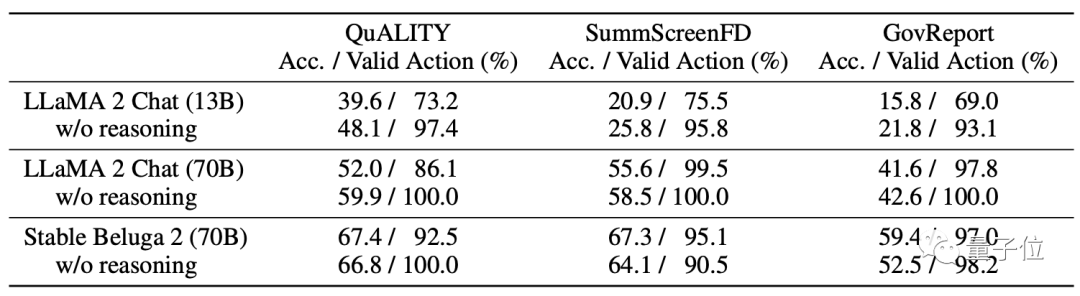
レベルの子ノードの内容を 1 つずつ読み取り、このノードが次のように推論します。入力するか、戻ります。 このノードに入ることを決定したら、葉ノードが読み取られるまでプロセスを再度繰り返します。葉ノードの内容が適切な場合は回答が生成され、そうでない場合は回答が返されます。
答えの完全性を保証するために、このプロセスの終了条件は、適切なリーフ ノードが見つかることではなく、モデルが完全な答えが得られたと信じること、または最大ステップ数であることです。が達成された。
ナビゲーション プロセス中に、モデルが間違ったパスに入ったことを検出した場合、元に戻ることもできます。
さらに、MemWalker は精度を向上させるために ワーキング メモリ メカニズム も導入しています。
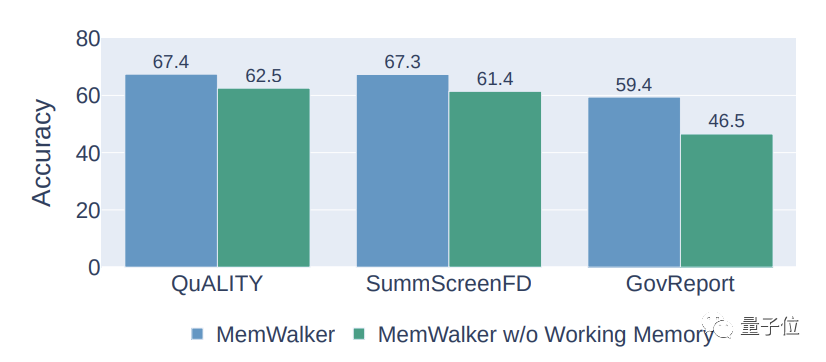
#このメカニズムは、訪問したノードのコンテンツを現在のコンテンツのコンテキストに追加します。
モデルが新しいノードに入ると、現在のノードの内容がメモリに追加されます。
このメカニズムにより、モデルは各ステップで訪問したノードのコンテンツを利用して、重要な情報の損失を回避できます。
実験結果は、作業記憶メカニズムにより MemWalker の精度を約 10% 向上できることを示しています。
さらに、上記のプロセスはプロンプトに頼るだけで完了でき、追加のトレーニングは必要ありません。

理論的には、MemWalker は十分な計算能力がある限り、無限に長いテキストを読み取ることができます。
ただし、テキストの長さが増加するにつれて、メモリ ツリーを構築するときの 時間と空間の複雑さは指数関数的に増加します。
著者についてこの論文の筆頭著者は、プリンストン大学 NLP 研究室の中国人博士課程学生、ハワード チェンです。 清華ヤオクラスの卒業生、チェン・ダンチーはハワードの指導者であり、今年のACLに関する彼女の学術レポートも検索に関連したものでした。 この成果は、ハワードがメタでのインターンシップ中に完成させたもので、メタ AI 研究所の 3 人の学者、ラマカンス パスヌル、ジェイソン ウェストン、アスリ チェリキルマズもこのプロジェクトに参加しました。紙のアドレス: https://arxiv.org/abs/2310.05029
以上が長いテキストは 4k ウィンドウの長さで読むことができます。Chen Danqi と彼の弟子たちは Meta と協力して、大きなモデルのメモリを強化する新しい方法を開始しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7505
7505
 15
1378
52
78
11
19
55
15
1378
52
78
11
19
55

 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
この記事では、Debian SystemsでiPtablesまたはUFWを使用してファイアウォールルールを構成し、Syslogを使用してファイアウォールアクティビティを記録する方法について説明します。方法1:Iptablesiptablesの使用は、Debian Systemの強力なコマンドラインファイアウォールツールです。既存のルールを表示する:次のコマンドを使用して現在のiPtablesルールを表示します。Sudoiptables-L-N-vでは特定のIPアクセスを許可します。たとえば、IPアドレス192.168.1.100がポート80にアクセスできるようにします:sudoiptables-input-ptcp - dport80-s192.166
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
