

BERT、GPT、Flan-T5 などの言語モデルから、SAM や安定拡散などの画像モデルに至るまで、Transformer は急速な勢いで世界を席巻していますが、人々は「Transformer は唯一のものなのか」と尋ねずにはいられません。選択?
スタンフォード大学とニューヨーク州立大学バッファロー校の研究者チームは、この質問に対して否定的な答えを提供するだけでなく、新しい代替テクノロジーである Monarch Mixer も提案しています。最近、チームは関連する論文といくつかのチェックポイント モデルおよびトレーニング コードを arXiv 上で公開しました。ちなみにこの論文はNeurIPS 2023に選出され、口頭発表の資格を獲得しました。

ペーパーリンク:https://arxiv.org/abs/2310.12109
on GitHubコードアドレスは: https://github.com/HazyResearch/m2
このメソッドは、Transformer 内の高コストの注意と MLP を削除し、表現力豊かな Monarch マトリックスに置き換えます。言語や画像の実験において、より低コストでより優れたパフォーマンスを達成できるようになります。
スタンフォード大学が Transformer に代わる技術を提案したのはこれが初めてではありません。今年 6 月には、同校の別のチームも Backpack と呼ばれるテクノロジーを提案しました。Heart of Machine の記事「Stanford Training Transformer Alternative Model: 170 Million Parameters, Debiased, Controllable and Highly Interpretable」を参照してください。もちろん、これらのテクノロジーが真の成功を収めるためには、研究コミュニティによってさらにテストされ、アプリケーション開発者の手によって実用的で有用な製品に変えられる必要があります。
見てみましょうこの文書では、Monarch Mixer の概要といくつかの実験結果について説明します。
自然言語処理とコンピューター ビジョンの分野では、機械学習モデルはすでにより長いシーケンスとより高い次元を処理できるようになりました。 、これにより、より長いコンテキストとより高い品質がサポートされます。ただし、既存のアーキテクチャの時間と空間の複雑さは、シーケンスの長さおよび/またはモデルの次元で二次的な増加パターンを示し、コンテキストの長さが制限され、スケーリング コストが増加します。たとえば、Transformer のアテンションと MLP は、シーケンスの長さとモデルの次元に応じて二次的にスケールします。
この問題に対応して、スタンフォード大学とニューヨーク州立大学バッファロー校の研究チームは、複雑さが配列の長さとモデルに応じて変化する高性能アーキテクチャを発見したと主張しています。成長は二次二次的です。
彼らの研究は、MLP ミキサーと ConvMixer からインスピレーションを受けています。これら 2 つの研究では次のことが観察されました: 多くの機械学習モデルは、軸としてシーケンスとモデルの次元に沿って情報を混合し、多くの場合、単一の演算子を使用して両方の軸を操作します。
パフォーマンスを求めています。二次関数とハードウェア効率の高いハイブリッド演算子の実装は困難です。たとえば、MLP ミキサーの MLP と ConvMixer の畳み込みは両方とも表現力豊かですが、どちらも入力次元に応じて二次的にスケールします。最近の研究では、準 2 次シーケンスのハイブリッド手法が提案されています。これらの手法では、より長い畳み込みまたは状態空間モデルが使用され、すべて FFT が使用されます。ただし、これらのモデルの FLOP 利用率は非常に低く、モデルの次元は非常に低いです。まだ第二の拡張です。同時に、スパースデンス MLP レイヤーでは品質を損なうことなく有望な進歩が見られますが、一部のモデルはハードウェア使用率が低いため、実際にはデンスモデルよりも遅くなる可能性があります。
これらのインスピレーションに基づいて、研究チームは、表現力豊かな二次二次構造行列を使用する Monarch Mixer (M2) を提案しました。 #Monarch 行列は一般化された高速フーリエ変換 (FFT) 構造行列であり、アダマール変換、トプリッツ行列、AFDF 行列、畳み込みなどのさまざまな線形変換が含まれていることが研究によって示されています。これらの行列は、ブロック対角行列の積によってパラメータ化できます。これらのパラメータはモナーク因子と呼ばれ、置換インターリーブに関連しています。
これらは二次二次的に計算されます: 因子の数が設定されている場合から p まで、入力長が N のとき、計算量は
となるため、p = log N のとき、計算量は O (N log N) に位置します p = 2 の場合。 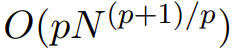 M2 は、Monarch マトリックスを使用して、シーケンス軸とモデル次元軸に沿って情報をブレンドします。このアプローチは実装が簡単であるだけでなく、ハードウェア効率も優れています。GEMM (一般化行列乗算アルゴリズム) をサポートする最新のハードウェアを使用して、ブロックされた対角モナーク係数を効率的に計算できます。
M2 は、Monarch マトリックスを使用して、シーケンス軸とモデル次元軸に沿って情報をブレンドします。このアプローチは実装が簡単であるだけでなく、ハードウェア効率も優れています。GEMM (一般化行列乗算アルゴリズム) をサポートする最新のハードウェアを使用して、ブロックされた対角モナーク係数を効率的に計算できます。
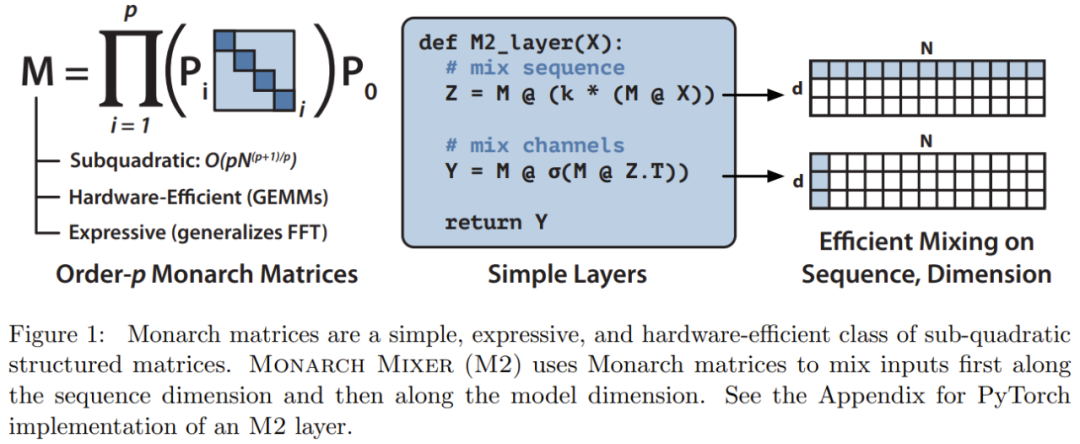
研究チームは、PyTorch を使用してコードを記述し、行列の乗算、転置、変形、および要素ごとの積のみに依存して、40 行未満で M2 層を実装しました (「図 1 の中央の疑似コード)。入力サイズが 64k の場合、これらのコードは A100 GPU で 25.6% の FLOP 使用率を達成します。 RTX 4090 などの新しいアーキテクチャでは、同じサイズの入力に対して、単純な CUDA 実装で 41.4% の FLOP 使用率を達成できます
関連Monarch Mixer の数学的説明と理論的分析の詳細については、元の論文を参照してください。
研究チームは、Monarch Mixer と Transformer の 2 つのモデルを比較し、主に 3 つの主要なタスクにおける Transformer の占有状況に焦点を当てました。勉強しました。 3 つのタスクは次のとおりです: BERT スタイルの非因果マスク言語モデリング タスク、ViT スタイルの画像分類タスク、および GPT スタイルの因果言語モデリング タスク
各タスクでは、前提として、実験結果は、新たに提案した手法が、attentionとMLPを使用せずにTransformerと同等のレベルを達成できることを示しています。彼らはまた、BERT 設定における強力な Transformer ベースライン モデルと比較した新しい手法の高速化についても評価しました。
非因果的言語モデリングには書き換えが必要です
非因果的言語モデリング用にタスクを書き直す必要があるため、チームは M2 ベースのアーキテクチャである M2-BERT を構築しました。 M2-BERT は BERT スタイルの言語モデルを直接置き換えることができ、BERT は Transformer アーキテクチャの主要なアプリケーションです。 M2-BERT のトレーニングには、C4 のマスクされた言語モデリングが使用され、トークナイザーは bert-base-uncased です。
M2-BERT は Transformer バックボーンに基づいていますが、図 3
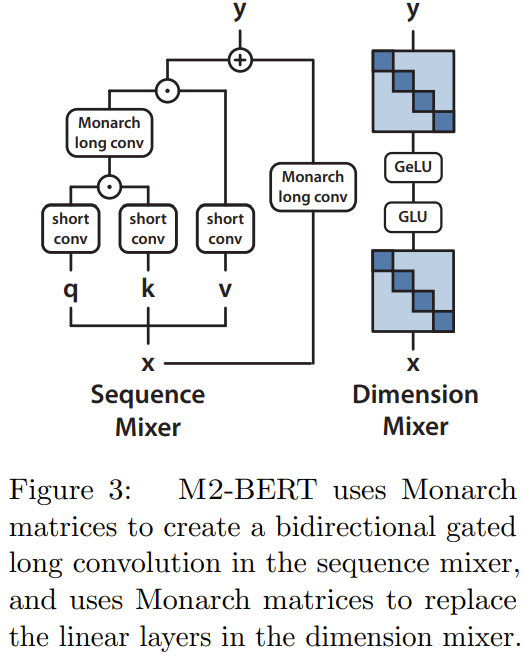 に示すように、M2 層がアテンション層と MLP を置き換えます。
に示すように、M2 層がアテンション層と MLP を置き換えます。
シーケンス ミキサーでは、注意は残差畳み込みによる双方向ゲート畳み込みに置き換えられます (図 3 の左側を参照)。畳み込みを復元するために、チームは Monarch 行列を DFT および逆 DFT 行列に設定しました。彼らはまた、投影ステップの後に深さ方向の畳み込みを追加しました。
#次元ミキサーでは、MLP の 2 つの密行列が学習されたブロック対角行列に置き換えられます (Monarch 行列の次数は 1、b=4)
研究者は事前トレーニングを実施し、合計 4 つの M2-BERT モデルを取得しました。そのうち 2 つはサイズがそれぞれ 80M と 110M の M2-BERT ベース モデルで、他の 2 つはサイズがそれぞれ 80M と 110M の M2-BERT モデル、M2-BERT-large モデルはそれぞれ 260M と 341M です。これらのモデルは、それぞれ BERT-base および BERT-large と同等です
表 3 は BERT ベースと同等のモデルのパフォーマンスを示し、表 4 は BERT-large と同等のパフォーマンスを示しますモデルのパフォーマンス。
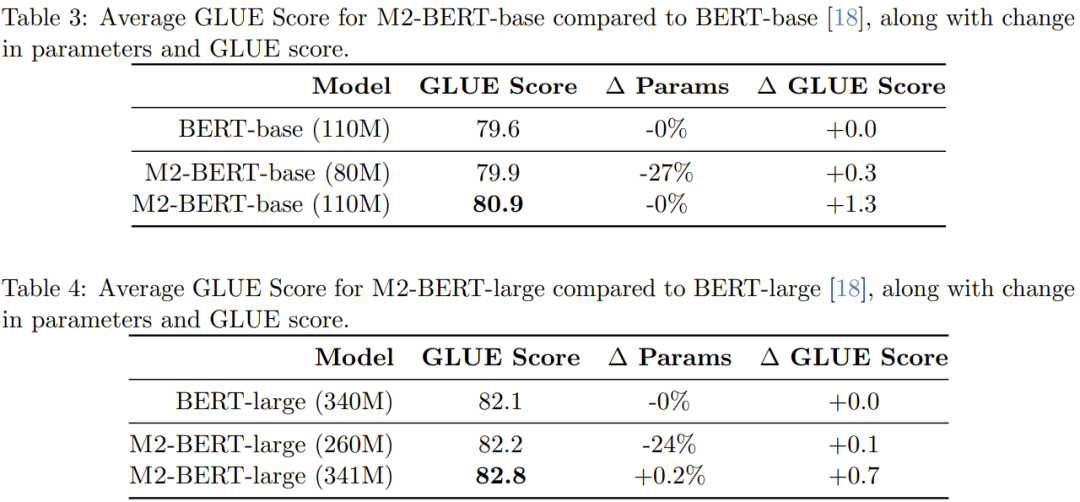
表からわかるように、GLUE ベンチマークでは、M2-BERT ベースのパフォーマンスは BERT ベースと同等ですが、パラメータが 27% 少ない; 2 つのパラメータの数が等しい場合、M2-BERT-base は BERT-base より 1.3 ポイント優れています。同様に、パラメータが 24% 少ない M2-BERT-large は BERT-large と同等のパフォーマンスを示しますが、パラメータ数が同じ場合は M2-BERT-large の方が 0.7 ポイント有利です。
表 5 は、BERT ベース モデルと同等のモデルの順方向スループットを示しています。 A100-40GB GPU でミリ秒あたりに処理されたトークンの数が報告されます。これは推論時間を反映している可能性があります
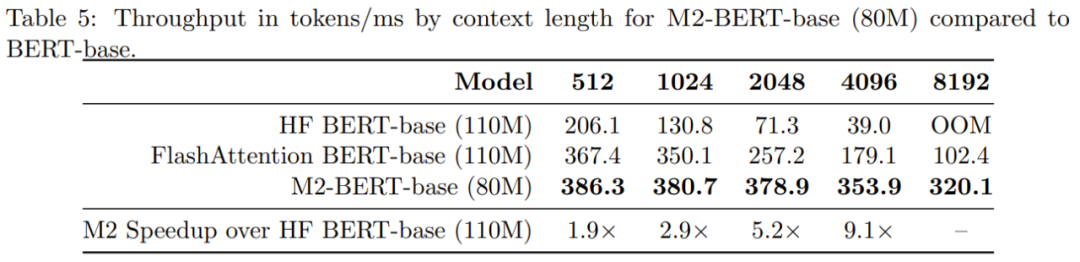
M2-BERT ベースのスループットは、高度に最適化された BERT モデルをも上回っていることがわかります。4K シーケンス長での標準的な HuggingFace 実装と比較して、M2-BERT ベースのスループットは 9.1 倍に達する可能性があります。
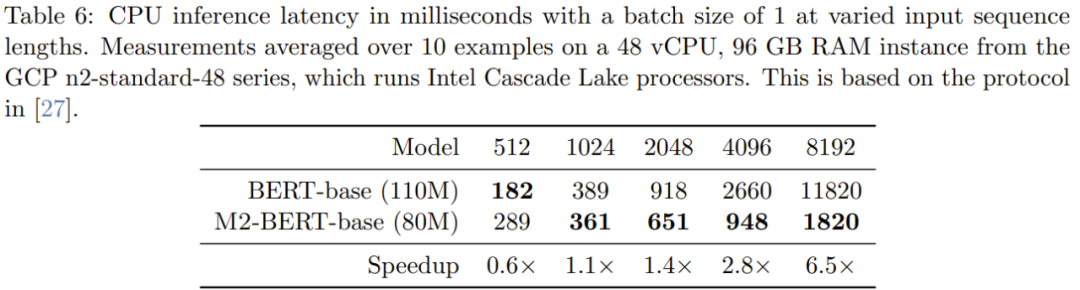
シーケンスが短い場合でも、データの局所性の影響が FLOP 削減に大きく影響し、フィルター生成 (BERT には存在しない) などの操作のコストが高くなります。系列長が 1K を超えると、M2-BERT ベースの高速化の利点が徐々に増加し、系列長が 8K に達すると、速度の利点は 6.5 倍に達します。
画像分類
画像分野における新しい手法の利点が同じかどうかを検証するため言語分野の研究者と同様に、チームはまた、非因果モデリングの観点から実行された画像分類タスクにおける M2 のパフォーマンスも評価しました。
表 7 は、Monarch Mixer、ViT- を示しています。 b、ImageNet-1k 上の HyenaViT-b および ViT-b-Monarch (標準 ViT-b の MLP モジュールを Monarch マトリックスに置き換えたもの)。
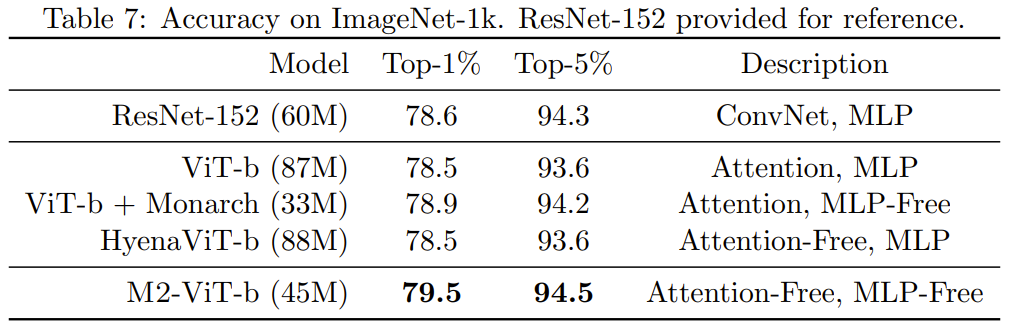
Monarch Mixer の利点は非常に明白です。元の ViT-b モデルを超えるのに必要なパラメーターの数は半分だけです。驚くべきことに、パラメータが少ない Monarch Mixer は、ImageNet タスク
因果言語モデリング# 用に特別に設計された ResNet-152 よりも優れたパフォーマンスを発揮することさえできました。
##GPT スタイルの因果言語モデリングは、Transformer の重要なアプリケーションです。チームは、M2-GPT
という因果言語モデリング用の M2 ベースのアーキテクチャを開発しました。シーケンス ミキサーの場合、M2-GPT は Hyena の畳み込みフィルターの組み合わせを使用します。 - H3 からの最新のアテンションフリー言語モデルと複数のパラメータ共有。彼らは、これらのアーキテクチャの FFT を因果関係パラメータ化に置き換え、MLP 層を完全に削除しました。結果として得られるアーキテクチャには、まったく注意が払われておらず、MLP もまったくありません。
彼らは、因果言語モデリングの標準データセットである PILE 上で M2-GPT を事前トレーニングしました。結果を表8に示す。
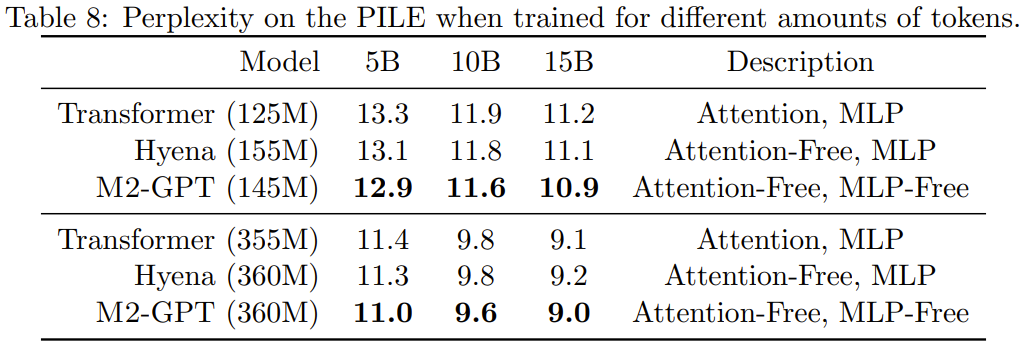
新しいアーキテクチャに基づくモデルには注意も MLP もまったくありませんが、事前トレーニングされたモデルでは依然として勝利していることがわかります。困惑指数: トランスフォーマーとハイエナを通して。これらの結果は、Transformer とは大きく異なるモデルでも、因果言語モデリングで優れたパフォーマンスを達成できる可能性があることを示唆しています。
詳細については元の論文を参照してください
以上がTransformer よりも、BERT と GPT without tention、MLP の方が実際には強力です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



