

Microsoft AR/VR の特許共有により、カメラ角度の違いによって生じるオクルージョンや視差の問題を解決

(Nweon 2023年11月3日) カメラ視点によるヘッドマウントディスプレイでは、目に位置が対応できないため、ユーザーが周囲の物体の位置関係を正しく認識することが難しい可能性があります。定められた空間。さらに、同じ定義された空間内の複数のユーザーは、定義された空間の外側のオブジェクトに対して異なる視点を持つ可能性があります。
そこでマイクロソフトは、「周囲環境の視点依存表示」というタイトルの特許出願で、特に自動車のようなモバイルプラットフォームにおいて、定義された空間を正確に表現する環境画像を提案しています。つまり、コンピューティング システムは、定義された空間を囲む環境の少なくとも一部の深度マップと強度データを構築します。次に、強度データは深度マップの位置と関連付けられます。
### さらに、コンピューティングシステムは、定義された空間内のユーザの姿勢に関する情報を取得し、ユーザの姿勢に基づいて、ユーザが見ている定義された空間の周囲環境の一部を決定することができる。コンピューティング システムはさらに、ユーザーの視点から環境の一部を表す画像データを取得します。次に、コンピューティング システムは、ユーザーの視野内の深度マップ位置での強度データに基づいて、表示用の画像を生成します。このようにして、1 つ以上のカメラによって取得された環境のビューをユーザーの視点に再投影することができ、カメラの視点の違いによるオクルージョンや視差の問題が発生することなく、環境の正しいビューを提供できます。
### 図1は、ユーザ102および104が定義された空間106内に位置する例示的な使用シナリオ100を示す。ユーザ102および104は、それぞれヘッドマウントデバイス112および114を装着する。 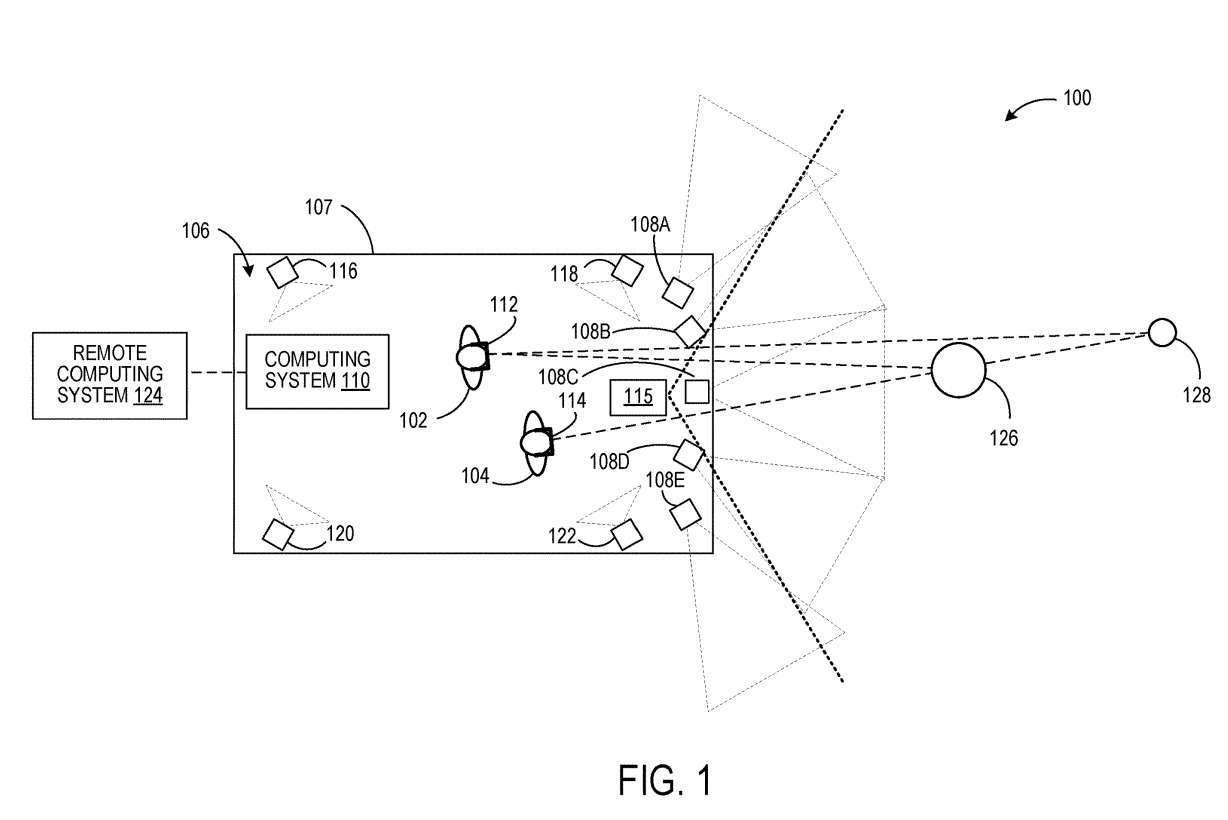 ### コンピューティングシステム110は、各ユーザ102、104の視点から定義された空間の周囲の環境を表す画像データを生成する。これを行うために、コンピューティングシステム110は、定義された空間106における各ユーザ102および104の姿勢に関する情報を取得する。
### コンピューティングシステム110は、各ユーザ102、104の視点から定義された空間の周囲の環境を表す画像データを生成する。これを行うために、コンピューティングシステム110は、定義された空間106における各ユーザ102および104の姿勢に関する情報を取得する。
図 1 では、4 つのそのようなイメージング デバイスが 116、118、120、および 122 として示されています。このような撮像装置の例としては、ステレオカメラ装置、深度センサーなどが挙げられる。
#### コンピューティングシステム110は、カメラ108A〜108Eからのデータから規定空間106の周囲の環境の深度マップを生成するように構成され得る。各カメラ108A〜108Eは、周囲環境の一部の強度画像データを取得するように構成されている。カメラはすべて、互いの空間的関係を認識しています。
さらに、図 1 に示すように、隣接するカメラの視野は重なっています。したがって、ステレオ イメージング技術を使用して、周囲環境内のオブジェクトの距離を決定し、深度マップを生成できます。他の例では、カメラ108A〜108Eとは別個のオプションの深度センサ115を使用して、周囲環境の深度マップを取得することができる。深度センサーの例には、LIDAR センサーと 1 つ以上の深度カメラが含まれます。このような例では、オプションで強度画像を取得するカメラの視野は重なり合わない可能性があります。
カメラからの強度データは、メッシュ内の各頂点や点群内の各点など、深度マップ内の各位置に関連付けられます。他の例では、カメラからの強度データが計算的に結合されて、深度マップ内の各位置について計算された結合強度データが形成される。たとえば、深度マップの位置が 2 つ以上の異なるカメラからのセンサー ピクセルによって画像化される場合、2 つ以上の異なるカメラからのピクセル値を計算して保存できます。
### 次に、コンピューティングシステム110は、少なくとも各ユーザ102、104のジェスチャに基づいて、各ユーザ102、104が見ている定義された空間の周囲の環境の一部を決定し、次の視点からの表現を取得することができる。各ユーザ102、104は、環境のこの部分の画像データを取得し、その画像データを各ヘッドディスプレイ112、114に提供する。例えば、定義された空間106内のユーザの姿勢、および周囲環境の深度マップと定義された空間106の間の空間関係を知ることによって、各ユーザの姿勢を深度マップに関連付けることができる。次に、各ユーザーの視野を定義して深度マップに投影し、ユーザーの視野内にある深度マップの部分を決定できます。
次に、レイ キャスティングなどの手法を使用して、視野内に表示される深度マップ内の位置を決定できます。位置に関連付けられた強度データを使用して、表示用の画像を形成できます。コンピューティングシステム110は、オプションで、クラウドサービスなどのリモートコンピューティングシステム124と通信することができる。そのような場合、そのような処理ステップのうちの1つまたは複数は、リモートコンピューティングシステム124によって実行され得る。
このようにして、特定の空間内で、さまざまなユーザーが個人的な視点から周囲の環境の画像を観察することができます。ユーザ102の視点からヘッドセット112によって表示される画像は、環境内のオブジェクト126およびオブジェクト128のビューを含むことができるが、ユーザの視点からヘッドセット114によって表示される画像では、オブジェクト128のビューがオブジェクト126によって遮られる可能性がある。 104.
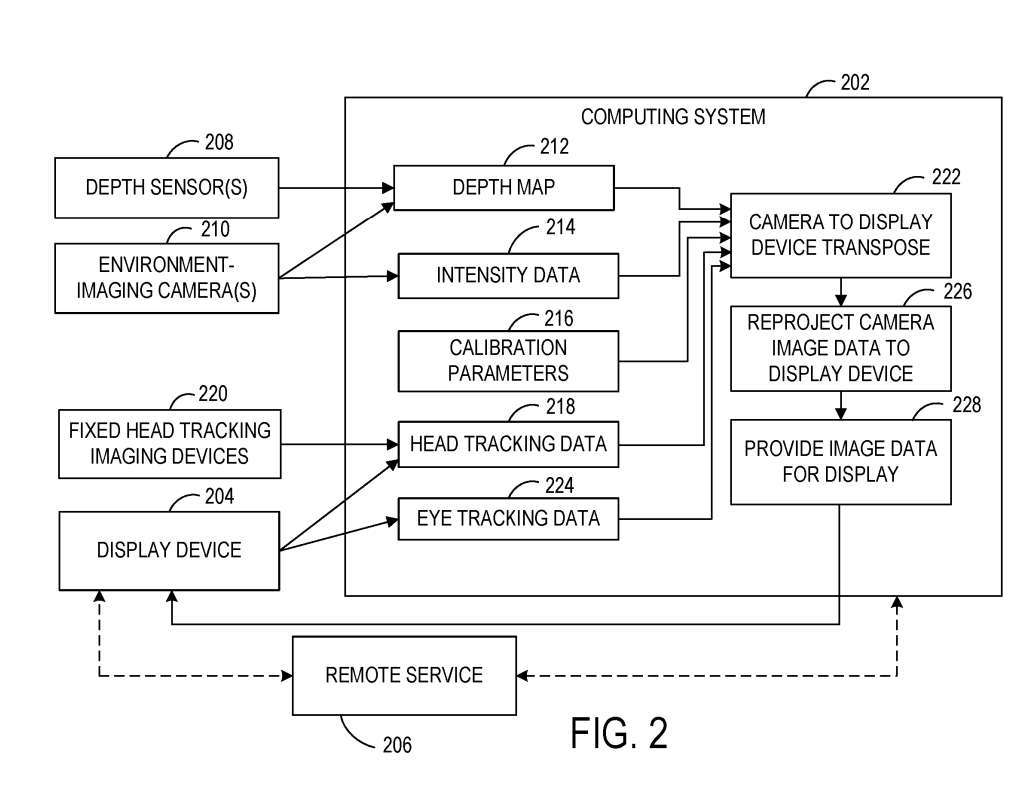
#### システム200は、1つまたは複数のカメラ210を含み、環境を画像化するように構成されている。一例では、カメラ210はパッシブステレオカメラとして使用され、ステレオ画像化方法を使用して強度データおよび深度データを取得する。他の例では、定義された空間の周囲の深度データを取得するために、1つまたは複数の深度センサ208が任意選択で使用される。
####コンピューティングシステム202は、深度データから環境の深度マップ212を構築するための実行可能命令を含む。深度マップ212は、3D点群またはメッシュなどの任意の適切な形式を取ることができる。上述したように、コンピューティングシステム202は、1つまたは複数のカメラ210によって取得された画像データに基づいて、深度マップ212の各位置に関連付けられた強度データ214を受信および記憶し得る。###深度センサー208とカメラ210の相対的な空間位置は、相互に、また定義された空間の幾何学的形状に合わせて校正される。したがって、図2は、カメラ210および深度センサ208のビューをユーザの姿勢に置き換えることを支援するための入力として使用され得、それによって、画像データをカメラの視点からユーザの視点に再投影して表示するのを助けることができる校正パラメータ216を示す。 . .
### 一実施形態では、表示装置204および/または画定された空間は周囲環境に対して継続的に移動する可能性があるため、深度マップ212に対する表示装置204の位置を校正するために継続的な外部校正を実行することができる。例えば、表示装置204による深度マップ212の校正は、表示装置204による表示のフレームレートで実行され得る。#### コンピューティングシステム202は、定義された空間内のユーザの姿勢に関する情報をさらに取得することができる。ユーザーの姿勢は、より具体的には頭の位置と頭の向きを指し、これはユーザーが探している定義された空間の周囲の環境の一部を決定するのに役立ちます。コンピューティングシステム202は、頭部追跡データ218を受信するように構成されている。頭部追跡データ218は、追加的にまたは代替的に、定義された空間内の基準フレームに固定された1つまたは複数の撮像装置から受信されてもよい。
### 上述したように、コンピューティングシステム202は、ヘッドトラッキングデータ218から決定されるユーザの姿勢と併せて深度マップ212および対応する強度データ214を使用して、表示装置204のユーザの視点から表示するための画像データを決定する。#### コンピューティングシステム202は、ユーザの姿勢に基づいてユーザが見ている環境の部分を決定し、ユーザの視野を深度マップ上に投影し、次に、から見える深度マップの位置の強度データを取得することができる。ユーザーの視点。
表示のために表示装置に提供される画像データは、表示装置204のフレームバッファ内で事後再投影を受けることができる。たとえば、ポスト再投影を使用すると、レンダリング イメージが表示される直前に、レンダリング イメージ内のオブジェクトの位置を更新できます。
###ここで、表示装置204は移動中の車両内に配置されており、表示装置204のフレームバッファ内の画像データは、226における画像形成と画像表示との間に車両が移動した距離に基づいて再投影され得る。コンピューティングシステム202は、後の再投影のために車両運動ベースの装置204を表示するための運動ベクトルを提供することができる。他の例では、動きベクトルは、表示装置204の局所慣性測定ユニットからのデータから決定され得る。### 一実施形態では、カメラ210によって取得された強度データのフレームレートは、深度センサ208によって取得された深度マップのフレームレートと異なっていてもよい。たとえば、深度マップを取得するために使用されるフレーム レートは、強度データを取得するために使用されるフレーム レートよりも低い場合があります。
同様に、フレーム レートは、車両速度の変化、環境内の移動物体、および/またはその他の環境要因に基づいて変化する場合があります。このような例では、強度データを深度マップの位置に関連付ける前に、強度データおよび/または深度データを変換して、強度データが取得された時間と深度マップが取得された時間との間に生じる動きを補正することができる。
### 複数のカメラ210が強度データを取得するために使用される場合、画定された空間を囲む環境内の物体が、複数のカメラ210からの画像データに現れる可能性がある。このような例では、オブジェクトを撮像する各カメラからの強度データをユーザーの視点に再投影することができます。他の例では、物体を撮像する 1 台のカメラまたはカメラのサブセットからの強度データをユーザーの視点に再投影することができます。これは、オブジェクトを撮像するすべてのカメラからの画像データをユーザーの視点に置き換えるよりも、使用するコンピューティング リソースが少なくなる可能性があります。
#### このような例では、ユーザの視点に最も近いと判断された視点を有するカメラからの画像データが使用され得る。別の例では、選択された深度マップ位置に対する複数のカメラからのピクセル強度データは、平均化されるか、さもなければ計算的に結合され、その後、深度マップ位置について保存され得る。#### 図1の例では、ユーザ102および104は、ヘッドセット112、114を介してコンピューティングシステム110によって生成された視点依存画像を見る。図3の例示的なシナリオ300では、ユーザは、定義された空間304内の固定位置に配置された表示パネル上でカメラ306A〜306Eによって取得された画像データを見ている。
### ただし、カメラ306A〜306Eの視点から画像を表示する代わりに、カメラ306A〜306Eからの画像データは、画像データから決定された深度マップ、または深度センサから取得されたデータから決定された深度マップに関連付けられる。 . ユニオン。
これにより、画像データをユーザー 302 の斜視図に変換できます。カメラ312、314は、定義された空間304の内部を画像化して、ユーザジェスチャ追跡を実行する。ユーザーの姿勢を判断するために、1 つ以上の深度センサーがさらに使用されます。ユーザ302の視点からの画像データは、カメラ312、314からのデータから決定されたユーザジェスチャデータに基づいて表示パネル310上に表示され得る。 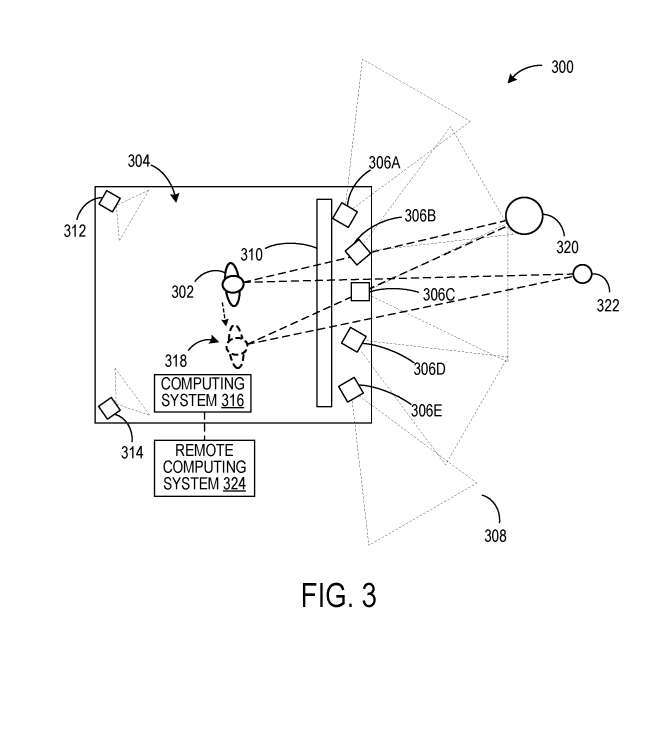
####したがって、ユーザ302が新しい位置318に移動すると、環境内のオブジェクト320、322は、ユーザ302の元の位置とは異なる角度から現れる。コンピューティングシステム316は、オプションで、クラウドサービスなどのリモートコンピューティングシステム324と通信することができる。
#### 図4は、定義された空間内のユーザの視点から、定義された空間を取り囲む環境の画像データを表示用に提供する例示的な方法400を示す。
### 402において、方法400は、定義された空間内のユーザの姿勢に関する情報を取得することを含む。上で述べたように、たとえば、ユーザーの姿勢は頭の位置と向きを反映する場合があります。ユーザのジェスチャは、空間基準フレーム内に固定された1つまたは複数のカメラからの画像データに基づいて決定され得る。別の例として、406において、ユーザのジェスチャは、ユーザが装着するヘッドセットから受信され、例えば、ヘッドセットの1つ以上の画像センサからの画像データから決定され得る。
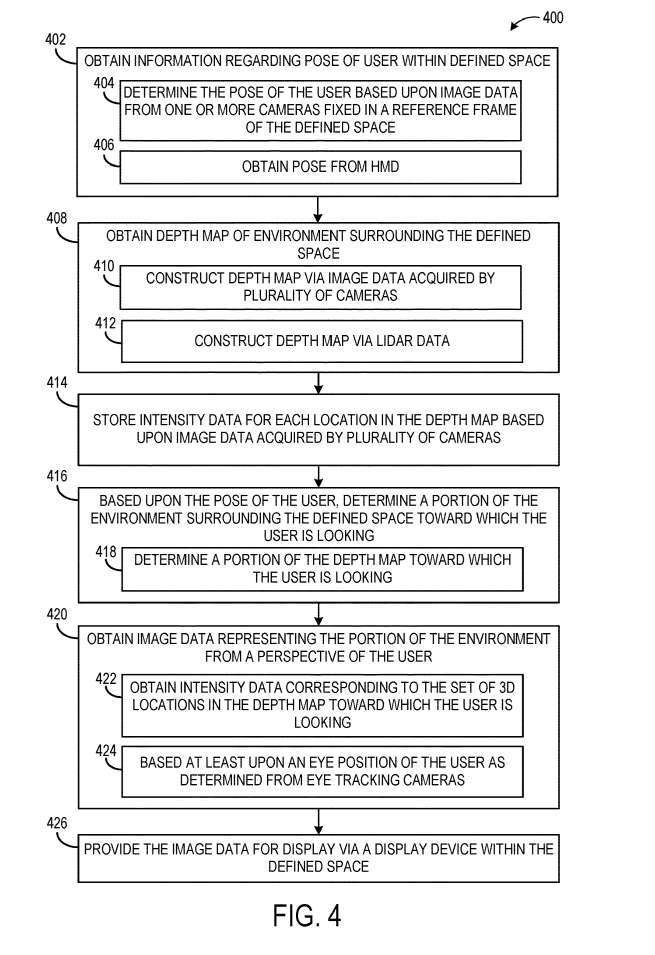 408では、定義された空間の周囲の環境の深度マップを取得することが含まれる。深度マップは、410で環境を撮像する複数のカメラによって取得された画像データから構築されてもよく、または412でLIDARセンサによって取得されたLIDARデータから構築されてもよい。
408では、定義された空間の周囲の環境の深度マップを取得することが含まれる。深度マップは、410で環境を撮像する複数のカメラによって取得された画像データから構築されてもよく、または412でLIDARセンサによって取得されたLIDARデータから構築されてもよい。
他の例では、飛行時間型深度イメージングなど、他の適切なタイプの深度センシングが利用されてもよい。次に、414で、方法400は、深度マップ内の各位置の強度データを格納することを含む。
####次に416で、ユーザの姿勢に基づいて、ユーザが求めている定義された空間を囲む環境の一部が決定される。これには、418において、ユーザが深度マップのどの部分を見ているかを決定することが含まれる場合がある。一例では、ユーザの視野を深度マップ上に投影して、ユーザの視点から見える深度マップ内の位置を決定することができる。####方法400はまた、420で、ユーザの視点から環境の一部を表す画像データを取得することを含む。方法400はまた、426において、画定された空間内で表示装置によって表示するための画像データを提供することを含む。
### 図5は、ヘッドマウントディスプレイを介してユーザの視点から環境画像データを表示するための例示的な方法500のフローチャートを示す。
### 502において、方法500は、定義された空間内のヘッドセットの姿勢に関する情報を取得することを含む。ヘッドセットの姿勢は、1 つ以上のヘッドセットの頭部追跡カメラからの画像データに基づいて追跡できます。 504において、ヘッドセットの姿勢は、空間を画定する基準フレーム内に固定された1つまたは複数のカメラに基づいて決定され得る。 506で、1つまたは複数の固定カメラがヘッドセットと通信する。### 508において、方法500はまた、深度マップの各位置の深度データおよび強度データを含む深度マップを取得することを含み、深度マップは定義された空間の周囲の環境を表す。
### 512において、定義された空間内のヘッドセットの姿勢に少なくとも基づいて、ヘッドセットのユーザが見ている定義された空間を取り囲む環境の一部が決定される。これには、514で、ユーザが見ている深度マップの部分を決定することが含まれる場合がある。ユーザが見ている環境/深度マップの部分は、少なくともユーザの目の位置にさらに基づくことができる。
### 方法500は、518において、深度マップ部分の各位置の強度データを含む画像データを取得するステップと、520において画像データを表示するステップとをさらに含む。
関連特許
: Microsoft特許 | 周囲環境の視点依存表示「周囲環境の視点依存表示」というタイトルの Microsoft 特許出願は、もともと 2022 年 3 月に提出され、最近米国特許商標庁によって公開されました。
以上がMicrosoft AR/VR の特許共有により、カメラ角度の違いによって生じるオクルージョンや視差の問題を解決の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7455
7455
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
バイブコーディングは、無限のコード行の代わりに自然言語を使用してアプリケーションを作成できるようにすることにより、ソフトウェア開発の世界を再構築しています。 Andrej Karpathyのような先見の明に触発されて、この革新的なアプローチは開発を許可します
 2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月は、生成AIにとってさらにゲームを変える月であり、最も期待されるモデルのアップグレードと画期的な新機能のいくつかをもたらしました。 Xai’s Grok 3とAnthropic's Claude 3.7 SonnetからOpenaiのGまで
 オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
Yolo(あなたは一度だけ見ています)は、前のバージョンで各反復が改善され、主要なリアルタイムオブジェクト検出フレームワークでした。最新バージョンYolo V12は、精度を大幅に向上させる進歩を紹介します
 Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast:天気予報のための革新的なAI 天気予報は、初歩的な観察から洗練されたAI駆動の予測に移行する劇的な変化を受けました。 Google DeepmindのGencast、グラウンドブレイク
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
この記事では、Lamda、Llama、GrokのようなChatGptを超えるAIモデルについて説明し、正確性、理解、業界への影響における利点を強調しています(159文字)
 O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
OpenaiのO1:12日間の贈り物は、これまでで最も強力なモデルから始まります 12月の到着は、世界の一部の地域で雪片が世界的に減速し、雪片がもたらされますが、Openaiは始まったばかりです。 サム・アルトマンと彼のチームは12日間のギフトを立ち上げています
 次のラグモデルにミストラルOCRを使用する方法
Mar 21, 2025 am 11:11 AM
次のラグモデルにミストラルOCRを使用する方法
Mar 21, 2025 am 11:11 AM
Mistral OCR:マルチモーダルドキュメントの理解により、検索された世代の革命を起こします 検索された生成(RAG)システムはAI機能を大幅に進めており、より多くの情報に基づいた応答のために膨大なデータストアにアクセスできるようになりました
