

GPT-4 は「世界モデル」を作成し、LLM が「間違った質問」から学習し、推論能力を大幅に向上できるようにします。

最近、大規模な言語モデルは、さまざまな自然言語処理タスク、特に複雑な思考連鎖 (CoT) 推論を必要とする数学的問題において大きな進歩を遂げています
たとえば、GSM8KやMATHなどの難しい数学的タスクのデータセットでは、GPT-4やPaLM-2を含む独自のモデルが顕著な成果を上げています。この点で、オープンソースの大規模モデルにはまだ改善の余地がかなりあります。数学的タスク用のオープンソースの大規模モデルの CoT 推論機能をさらに向上させるための一般的なアプローチは、注釈付き/生成された質問と推論のデータ ペア (CoT データ) を使用してこれらのモデルを微調整することです。タスク中に CoT 推論を実行します。
最近、西安交通大学、マイクロソフト、北京大学の研究者らは、論文の中で、逆学習プロセス(つまり、大学の間違いから学ぶこと)による改善アイデアを検討しました。 LLM ) 推論能力をさらに向上させるために
#数学を学び始める生徒と同じように、まず教科書の知識ポイントと例を学習して理解を深めます。しかし同時に、学んだことを定着させるための演習も行っています。困難に遭遇したり、問題の解決に失敗したりすると、自分がどのような間違いを犯したかに気づき、それを修正する方法を学び、「間違った問題集」を形成します。間違いから学ぶことで、彼の推論能力はさらに向上します
このプロセスに触発されたこの研究では、間違いを理解して修正することで LLM の推論能力がどのように向上するかを探ります。

論文アドレス: https://arxiv.org/pdf/2310.20689.pdf
特定の具体的には、研究者らはまず誤り訂正データのペア (訂正データと呼ばれる) を生成し、次にその訂正データを使用して LLM を微調整しました。修正データを生成するとき: 何を書き直す必要があるか、複数の LLM (LLaMA および GPT ファミリのモデルを含む) を使用して不正確な推論パス (つまり、最終的な答えが不正確) を収集し、その後 GPT-4 を「修正者」として使用しました。 、これらの不正確な推論パスに対する修正を生成します
#生成された修正には、(1) 元の解決策の間違ったステップ、(2) そのステップが間違っていたという説明の 3 つの情報が含まれています。間違っている 正しい理由; (3) 正しい最終答えに到達するために元の解決策を修正する方法。不正確な最終回答を含む修正を除外した後、手動評価により、修正データがその後の微調整フェーズに十分な品質を示していることがわかりました。研究者らは、QLoRA を使用して CoT データと補正データの LLM を微調整し、それによって「エラーからの学習」(LEMA) を実行しました。
研究によると、現在の LLM は段階的なアプローチを使用して問題を解決できることが示されていますが、この複数段階の生成プロセスは、LLM 自体が強力な推論能力を備えていることを意味するものではありません。これは、基礎的なロジックと必要なルールを真に理解せずに、人間の推論の表面的な動作を模倣するだけである可能性があるためです。
この理解の欠如は、推論プロセスでエラーを引き起こす可能性があるため、ヘルプ「世界モデル」は現実世界の論理とルールを先験的に認識しているため、「世界モデル」の理解が必要となります。この観点から、この記事の LEMA フレームワークは、単に段階的な動作を模倣するのではなく、より小さなモデルにこれらのロジックやルールに従うように教えるための「ワールド モデル」として GPT-4 を使用していると見ることができます。
##次に、この研究の具体的な実装手順を見てみましょう#方法の概要
# 以下の図 1 (左) を参照してください。これは、修正データを生成する 2 つの主要な段階 (書き換えが必要なコンテンツと LLM の微調整) を含む LEMA のプロセス全体を示しています。図 1 (右) は、GSM8K および MATH データ セットでの LEMA のパフォーマンスを示しています。
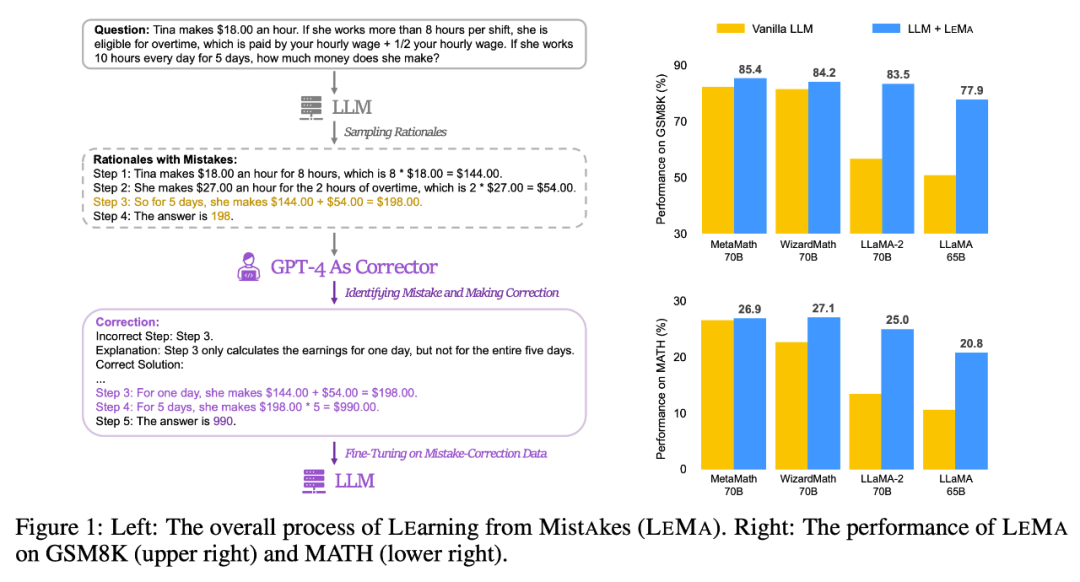
質問と回答の例 #不正確な推論パスの修正。研究者は、次の式(1)に示すように、まず推論モデル M_r を使って質問 q_i ごとに複数の推論パスをサンプリングし、最終的に正解 a_i に至らなかったパスのみを保持します。 エラーに対する修正 を生成します。質問 q_i と不正確な推論パス #具体的には、注釈付きの修正には、次の 3 つのカテゴリの情報が含まれます。 エラー ステップ: 元の推論パス どのステップが間違っていたか。 修正された人間の評価を生成します 。より大きなデータを生成する前に、まず生成された補正の品質を手動で評価しました。彼らは LLaMA-2-70B を M_r として、GPT-4 を M_c として使用し、GSM8K トレーニング セットに基づいて 50 個の誤り訂正されたデータ ペアを生成しました。 研究者らは、リビジョンを 3 つの品質レベル (優れた、良好、不良) に分類しました。以下は 3 つのレベルの例です
微調整が必要なのは LLM です 修正データを生成した後、書き直す必要があるものを研究者らは LLM を微調整し、モデルが間違いから学習できるかどうかを評価しました。主に、次の 2 つの微調整設定の下でパフォーマンスの比較を実行します。 1 つ目は、 思考連鎖 (CoT) データの を微調整することです。研究者は、疑問の根拠となるデータのみに基づいてモデルを微調整します。各タスクには注釈付きデータがありますが、さらに CoT データ拡張が採用されています。研究者らは GPT-4 を使用して、トレーニング セット内の各質問に対してさらに推論パスを生成し、不正確な最終回答を含むパスを除外しました。彼らは、CoT データ拡張を活用して、CoT データのみを使用する堅牢な微調整ベースラインを構築し、微調整を制御するデータ サイズに関するアブレーション研究を促進します。 2 つ目は、CoT データ補正データを 微調整することです。 CoT データに加えて、研究者らは微調整用の誤り訂正データ (つまり LEMA) も生成しました。また、データ サイズの増加による影響を軽減するために、データ サイズを制御したアブレーション実験も実施しました。
その後のアブレーション研究では、LEMA が同じ量のデータで CoT のみの微調整よりも優れたパフォーマンスを示していることが示されています。これは、両方のデータ ソースを組み合わせた方が単一のデータ ソースを使用するよりも大きな改善が得られるため、CoT データと修正データの効果が同等ではないことを示唆しています。これらの実験結果と分析は、LLM 推論機能を強化するためにエラーから学習する可能性を強調しています。 研究の詳細については、元の論文を参照してください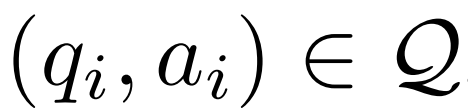 、修正モデル M_c と推論モデル M_r を考慮して、研究者は誤り修正データのペアを生成しました。
、修正モデル M_c と推論モデル M_r を考慮して、研究者は誤り修正データのペアを生成しました。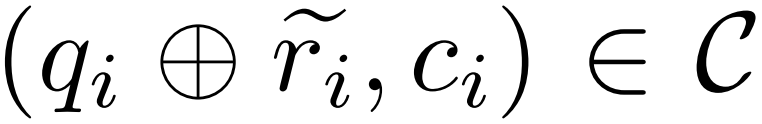 、
、 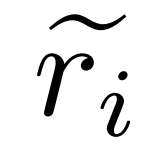 は質問 q_i の不正確な推論パスを表し、c_i は
は質問 q_i の不正確な推論パスを表し、c_i は 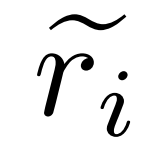 に対する修正を表します。
に対する修正を表します。 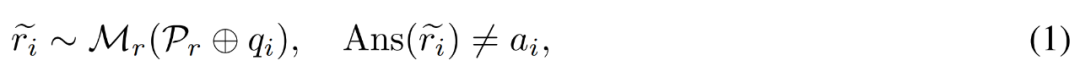
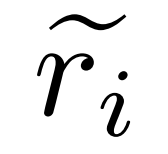 について、研究者は、以下の式 (2) に示すように、修正モデル M_c を使用して修正を生成し、修正内の正解を確認します。
について、研究者は、以下の式 (2) に示すように、修正モデル M_c を使用して修正を生成し、修正内の正解を確認します。 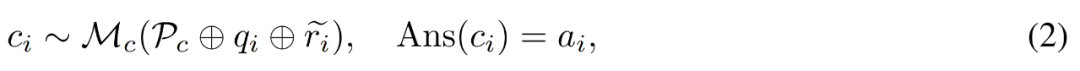


 ##評価の結果、次のことがわかりました。 , 50 件のビルド修正のうち、35 件は優れた品質、11 件は良好、4 件は低品質でした。この評価に基づいて、研究者らは、GPT-4 を使用して生成された補正の全体的な品質は、さらなる微調整段階に十分であると結論付けました。したがって、より大規模な修正を生成し、最終的に微調整が必要な LLM の正解につながるすべての修正を使用しました。
##評価の結果、次のことがわかりました。 , 50 件のビルド修正のうち、35 件は優れた品質、11 件は良好、4 件は低品質でした。この評価に基づいて、研究者らは、GPT-4 を使用して生成された補正の全体的な品質は、さらなる微調整段階に十分であると結論付けました。したがって、より大規模な修正を生成し、最終的に微調整が必要な LLM の正解につながるすべての修正を使用しました。 

研究者らは、実験結果を通じて、5 つのオープンソース LLM と 2 つの困難な数学的推論タスクに対する LEMA の有効性を実証しました
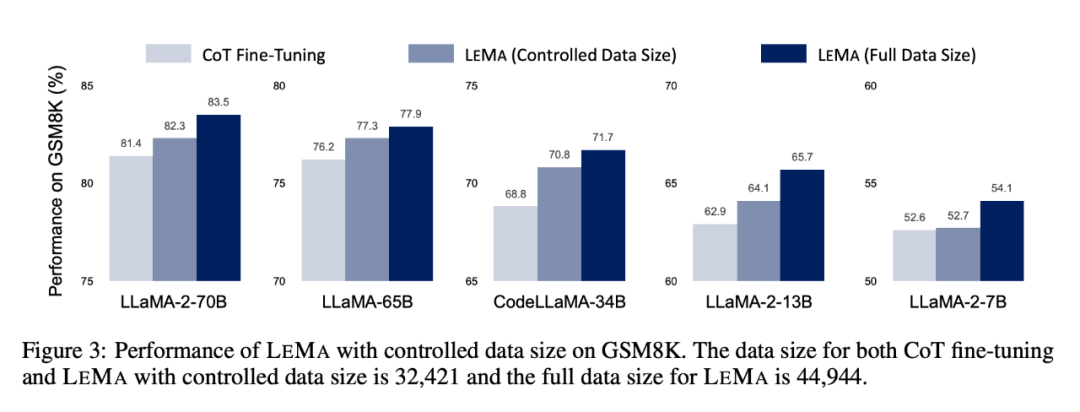 #LEMA は、CoT データを微調整するだけの場合と比較して、さまざまな LLM およびタスク全体のパフォーマンスを一貫して向上させます。たとえば、LLaMA-2-70B を使用した LEMA は、GSM8K と MATH でそれぞれ 83.5% と 25.0% を達成しましたが、CoT データのみの微調整ではそれぞれ 81.4% と 23.6% を達成しました
#LEMA は、CoT データを微調整するだけの場合と比較して、さまざまな LLM およびタスク全体のパフォーマンスを一貫して向上させます。たとえば、LLaMA-2-70B を使用した LEMA は、GSM8K と MATH でそれぞれ 83.5% と 25.0% を達成しましたが、CoT データのみの微調整ではそれぞれ 81.4% と 23.6% を達成しました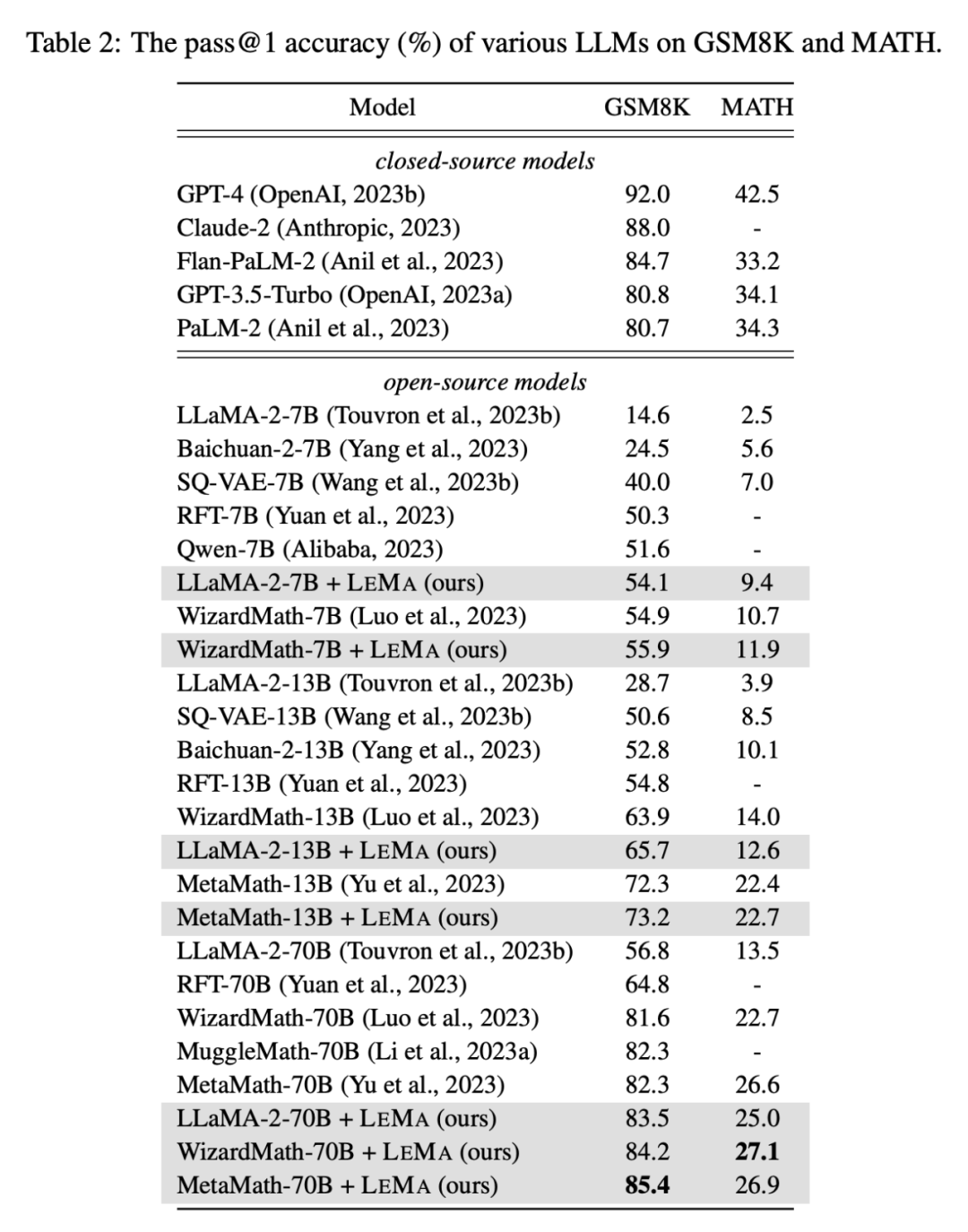 さらに、LEMA は独自の LLM と互換性があります。WizardMath-70B/MetaMath-70B を搭載した LEMA は、GSM8K 精度で 84.2%/85.4% pass@1 を達成し、27.1%/26.9 の pass@1 精度を達成します。 MATH では % を達成しており、これらの困難なタスクで多くのオープンソース モデルが達成する SOTA パフォーマンスを上回っています。
さらに、LEMA は独自の LLM と互換性があります。WizardMath-70B/MetaMath-70B を搭載した LEMA は、GSM8K 精度で 84.2%/85.4% pass@1 を達成し、27.1%/26.9 の pass@1 精度を達成します。 MATH では % を達成しており、これらの困難なタスクで多くのオープンソース モデルが達成する SOTA パフォーマンスを上回っています。
以上がGPT-4 は「世界モデル」を作成し、LLM が「間違った質問」から学習し、推論能力を大幅に向上できるようにします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
この記事では、Debian SystemsでApacheのログ形式をカスタマイズする方法について説明します。次の手順では、構成プロセスをガイドします。ステップ1:Apache構成ファイルにアクセスするDebianシステムのメインApache構成ファイルは、/etc/apache2/apache2.confまたは/etc/apache2/httpd.confにあります。次のコマンドを使用してルートアクセス許可を使用して構成ファイルを開きます。sudonano/etc/apache2/apache2.confまたはsudonano/etc/apache2/httpd.confステップ2:検索または検索または
 Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログは、メモリリークの問題を診断するための鍵です。 Tomcatログを分析することにより、メモリの使用状況とガベージコレクション(GC)の動作に関する洞察を得ることができ、メモリリークを効果的に見つけて解決できます。 Tomcatログを使用してメモリリークをトラブルシューティングする方法は次のとおりです。1。GCログ分析最初に、詳細なGCロギングを有効にします。 Tomcatの起動パラメーターに次のJVMオプションを追加します:-xx:printgcdetails-xx:printgcdateStamps-xloggc:gc.logこれらのパラメーターは、GCタイプ、リサイクルオブジェクトサイズ、時間などの情報を含む詳細なGCログ(GC.log)を生成します。分析GC.LOG
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
Debian Syslogのファイアウォールルールを構成する方法
Apr 13, 2025 am 06:51 AM
この記事では、Debian SystemsでiPtablesまたはUFWを使用してファイアウォールルールを構成し、Syslogを使用してファイアウォールアクティビティを記録する方法について説明します。方法1:Iptablesiptablesの使用は、Debian Systemの強力なコマンドラインファイアウォールツールです。既存のルールを表示する:次のコマンドを使用して現在のiPtablesルールを表示します。Sudoiptables-L-N-vでは特定のIPアクセスを許可します。たとえば、IPアドレス192.168.1.100がポート80にアクセスできるようにします:sudoiptables-input-ptcp - dport80-s192.166
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
