

Microsoft、「人間の学習プロセスを模倣し、AIの推論能力を向上させる」と主張する「間違いから学ぶ」モデルトレーニング手法を発表

マイクロソフト リサーチ アジアは最近、北京大学、西安交通大学、その他の大学と協力して、「間違いからの学習 (LeMA)」と呼ばれる人工知能のトレーニング方法を提案しました。この手法は、人間の学習プロセスを模倣することで人工知能の推論能力を向上させることができると主張しています。
現在、OpenAI GPT-4 や Google aLM などの大規模な言語モデルが開発されています。 -2 は自然言語で広く使用されており、処理 (NLP) タスクや思考連鎖 (CoT) 推論数学パズル タスクで優れたパフォーマンスを発揮します。
しかし、LLaMA-2 や Baichuan-2 などのオープンソースの大規模モデルは、関連する問題に対処するときに強化する必要があります。これらの大規模なオープンソース言語モデルの思考連鎖推論能力を向上させるために、 研究チームは LeMA 手法を提案しました。この手法は主に人間の学習プロセスを模倣し、「間違いから学ぶ」ことでモデルの推論能力を向上させます。
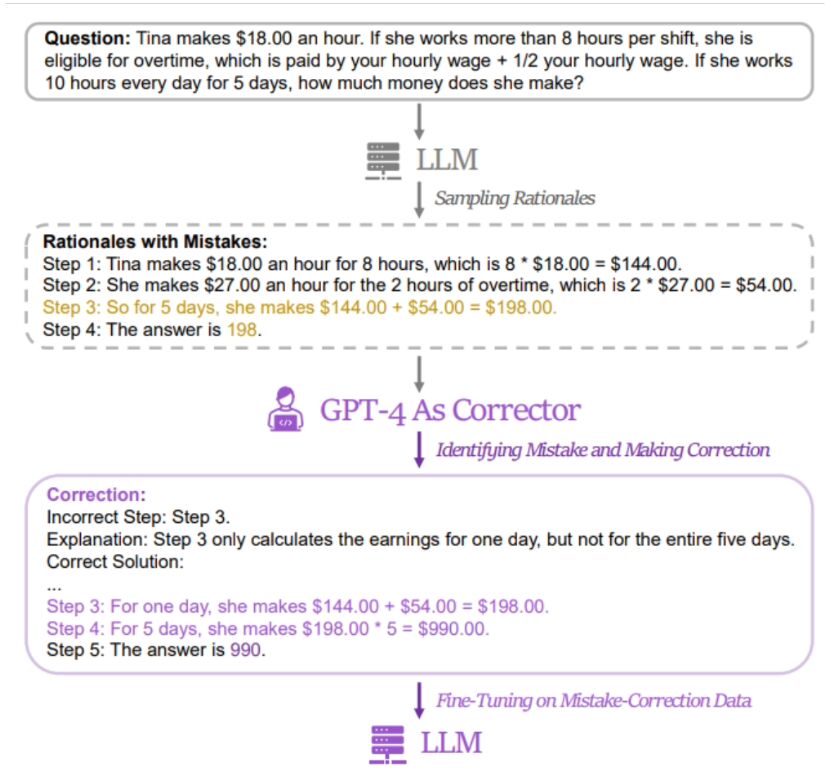
研究者の手法は「誤った答え」と「正しい答え」のペアを使用することであることがわかりました。関連モデルを微調整するための「正解」データ。関連データを取得するために、研究者らは 5 つの異なる大規模言語モデル (LLaMA および GPT シリーズを含む) の誤った回答と推論プロセスを収集し、GPT-4 を「改訂版」として使用して修正した回答を提供しました。
修正された正解には、元の推論過程での誤りの断片、元の推論過程での誤りの理由、および元の推論過程での誤りを得るために元の方法をどのように変更するかという 3 種類の情報が含まれていると報告されています。正しい答え。 研究者らは、GSM8K と MATH を使用して、5 つのオープンソースの大規模モデルに対する LeMa トレーニング手法の効果をテストしました。結果は、改良された LLaMA-2-70B モデルでは、GSM8K の精度率がそれぞれ 83.5% と 81.4% であるのに対し、MATH の精度率はそれぞれ 25.0% と 23.6% であることを示しています。現在、研究者らはLeMA 関連情報は GitHub で公開されています。興味のある方はここをクリックしてジャンプ してください。
以上がMicrosoft、「人間の学習プロセスを模倣し、AIの推論能力を向上させる」と主張する「間違いから学ぶ」モデルトレーニング手法を発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7464
7464
 15
1376
52
77
11
18
18
15
1376
52
77
11
18
18

 Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
翻訳者 | Bugatti レビュー | Chonglou この記事では、GroqLPU 推論エンジンを使用して JanAI と VSCode で超高速応答を生成する方法について説明します。 Groq は AI のインフラストラクチャ側に焦点を当てているなど、誰もがより優れた大規模言語モデル (LLM) の構築に取り組んでいます。これらの大型モデルがより迅速に応答するためには、これらの大型モデルからの迅速な応答が鍵となります。このチュートリアルでは、GroqLPU 解析エンジンと、API と JanAI を使用してラップトップ上でローカルにアクセスする方法を紹介します。この記事では、これを VSCode に統合して、コードの生成、コードのリファクタリング、ドキュメントの入力、テスト ユニットの生成を支援します。この記事では、独自の人工知能プログラミングアシスタントを無料で作成します。 GroqLPU 推論エンジン Groq の概要
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 大規模モデルは時系列予測にも非常に強力です。中国チームがLLMの新機能を有効にし、従来のモデルを超えたSOTAを達成
Apr 11, 2024 am 09:43 AM
大規模モデルは時系列予測にも非常に強力です。中国チームがLLMの新機能を有効にし、従来のモデルを超えたSOTAを達成
Apr 11, 2024 am 09:43 AM
大規模な言語モデルの可能性が刺激され、大規模な言語モデルをトレーニングすることなく高精度の時系列予測を達成でき、従来のすべての時系列モデルを上回ります。モナシュ大学、Ant、IBM Research は共同で、モダリティ全体で配列データを処理する大規模言語モデルの機能を促進する一般的なフレームワークを開発しました。このフレームワークは重要な技術革新となっています。時系列予測は、都市、エネルギー、交通、リモート センシングなどの典型的な複雑なシステムにおける意思決定に役立ちます。それ以来、大規模モデルは時系列/時空間データ マイニングに革命をもたらすと期待されています。一般大規模言語モデル再プログラミング フレームワーク研究チームは、トレーニングなしで一般的な時系列予測に大規模言語モデルを簡単に使用するための一般的なフレームワークを提案しました。主に 2 つの主要なテクノロジが提案されています: タイミング入力再プログラミング、プロンプト プレフィックス。時間-
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
 世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
ボリュームはクレイジー、ボリュームはクレイジー、そして大きなモデルがまた変わりました。たった今、世界で最も強力な AI モデルが一夜にして交代し、GPT-4 が祭壇から引き抜かれました。 Anthropic が Claude3 シリーズの最新モデルをリリースしました 一言評価: GPT-4 を本当に粉砕します!マルチモーダルと言語能力の指標に関しては、Claude3 が勝ちます。 Anthropic 氏の言葉を借りれば、Claude3 シリーズ モデルは、推論、数学、コーディング、多言語理解、視覚において新たな業界のベンチマークを設定しました。 Anthropic は、セキュリティ概念の違いを理由に OpenAI から「離反」した従業員によって設立された新興企業であり、同社の製品は繰り返し OpenAI に大きな打撃を与えてきました。今回、Claude3は大きな手術まで受けました。
 OpenHarmony で大規模な言語モデルをローカルにデプロイする
Jun 07, 2024 am 10:02 AM
OpenHarmony で大規模な言語モデルをローカルにデプロイする
Jun 07, 2024 am 10:02 AM
この記事は、第 2 回 OpenHarmony テクノロジー カンファレンスで実証された「OpenHarmony での大規模言語モデルのローカル デプロイメント」の結果をオープンソース化します。オープンソースのアドレス: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty。 /InferLLM/docs/hap_integrate.md。実装のアイデアと手順は、軽量 LLM モデル推論フレームワーク InferLLM を OpenHarmony 標準システムに移植し、OpenHarmony 上で実行できるバイナリ製品をコンパイルすることです。 InferLLM はシンプルで効率的な L
