

大手モデルは「ランキングに勝つ」ために近道をしているのだろうか?データ汚染の問題は注目に値する

生成 AI の最初の 1 年で、全員の作業ペースははるかに速くなりました。
特に今年は大型モデルの投入に力を入れており、最近では国内外の大手テクノロジー企業やスタートアップ企業が次々と大型モデルを投入しています。 、それらはすべて大きな進歩であり、各企業は重要なベンチマーク リストを更新し、第 1 位または第 1 層にランクされました。
テクノロジーの急速な進歩に興奮した後、多くの人は何かが間違っているように見えることに気づきます。なぜ誰もがランキングの上位にシェアを持っているのでしょうか?この仕組みは何でしょうか?
それに伴い、「ランキング不正行為」の問題も注目され始めています。
最近、WeChat モーメントと Zhihu コミュニティで、大規模モデルの「ランキングのスワイプ」問題に関する議論がますます増えていることに気づきました。特に、Zhihu への投稿: Tiangong Large Model Technical Report が指摘した、多くの大規模モデルがランキングを上げるために現場のデータを使用しているという現象をどのように評価しますか?それはみんなの議論を呼び起こしました。
リンク: https://www.zhihu.com/question/628957425
多くの大型モデルのランク付けメカニズムが公開
この研究は、Kunlun Wanwei の「Tiangong」大型モデル研究チームによるもので、先月末にプレプリント版の技術レポートを発表しました。 arXiv プラットフォーム上で。

論文リンク: https://arxiv.org/abs/2310.19341
論文自体Tiangong の大規模言語モデル (LLM) シリーズである Skywork-13B の紹介です。著者らは、セグメント化されたコーパスを使用した 2 段階のトレーニング方法を紹介し、それぞれ一般トレーニングとドメイン固有の強化トレーニングを対象としています。
大規模モデルに関する新しい研究の常として、著者らは、自分たちのモデルが一般的なテスト ベンチマークで良好なパフォーマンスを発揮しただけでなく、多くの中国のテスト ベンチマークでも最先端の結果を達成したと述べています。ブランチタスク、芸術レベル(業界最高)。
重要なのは、この報告書が多くの大型モデルの実際の効果も検証し、他のいくつかの国産大型モデルには日和見主義の疑いがあると指摘していることだ。これは表 8 です:
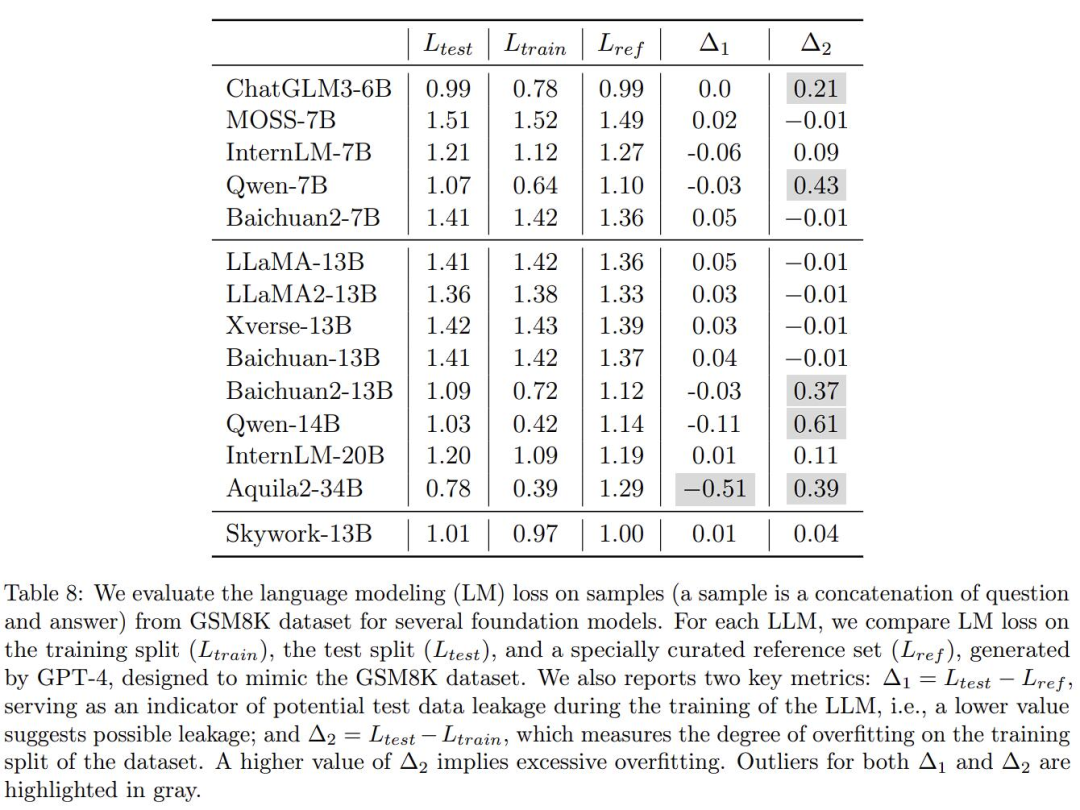
ここで、著者は業界で一般的ないくつかの大規模モデルの数学的応用を検証したいと考えています。問題のベンチマーク GSM8K での過学習の程度については、GPT-4 を使用して GSM8K と同じ形式のサンプルを生成しました。正確性は手動でチェックされ、これらのモデルは生成されたデータセットと元のトレーニングでテストされましたGSM8K のセットとテスト セットを比較し、損失を計算しました。さらに 2 つのメトリクスがあります:
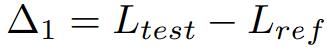
Δ1 モデルのトレーニング中にテスト データが漏洩する可能性を示す指標として、低い値が使用されます。漏れの可能性を示します。テストセットでトレーニングを行わない場合、値はゼロになるはずです。
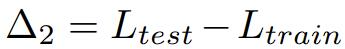
Δ2 は、データセットのトレーニング分割の過学習の程度を測定します。 Δ2 値が大きいほど、過学習を意味します。トレーニング セットでトレーニングされていない場合、値はゼロになるはずです。
これを簡単に説明すると、モデルがトレーニングされている場合、ベンチマーク テストの「実際の質問」と「回答」を学習教材として直接使用し、それらを使用してブラッシュアップ. ポイントの場合、ここでは例外が発生します。
わかりました。Δ1 と Δ2 の問題のある領域は、上で慎重に灰色で強調表示されています。
ネチズンは、ついに誰かが「データセット汚染」の公然の秘密を語った、とコメントした。
一部のネチズンは、大規模モデルのインテリジェンス レベルは依然としてゼロショット機能に依存しており、既存のテスト ベンチマークでは達成できないと述べています。

写真: Zhihu ネットユーザーのコメントのスクリーンショット
著者と読者とのやり取りの中で、著者は「これにより、誰もがランキングの問題をより合理的に見ることができるようになるでしょう。多くのモデルと GPT4 の間にはまだ大きなギャップがあります。」という希望も表明しました。
画像: Zhihu の記事のスクリーンショット https://zhuanlan.zhihu.com/p/664985891
データ汚染の問題は注目に値します
実際、これは一時的な現象ではありません。今年 9 月の arXiv の非常に皮肉な記事のタイトルが指摘しているように、Benchmark の導入以来、そのような問題は時折発生しています。必要なのはテスト セットでの事前トレーニングだけです。

さらに、人民大学とイリノイ大学アーバナシャンペーン校による最近の正式な研究でも、大規模モデルの評価における問題が指摘されています。タイトルは非常に目を引くものです。「LLM を評価ベンチマーク詐欺師にしないでください」:

論文リンク: https://arxiv。 org/abs/ 2311.01964
この論文は、現在注目されている大規模モデルの分野では、人々がベンチマークのランキングを気にするようになっているが、その公平性と信頼性が疑問視されていると指摘しています。主な問題はデータの汚染と漏洩であり、事前トレーニング コーパスを準備するときに将来の評価データ セットがわからない可能性があるため、意図せずに引き起こされる可能性があります。たとえば、GPT-3 では、事前トレーニング コーパスに Children's Book Test データ セットが含まれていることが判明し、LLaMA-2 論文では BoolQ データ セットからコンテキスト Web コンテンツを抽出することが記載されています。
データセットの収集、整理、ラベル付けには多くの人の労力が必要ですが、高品質のデータセットが評価に使用できるのであれば、当然のことながら使用される可能性があります。大規模なモデルのトレーニングに使用されます。
一方、既存のベンチマークを使用して評価する場合、評価した大規模モデルの結果は、ほとんどがローカル サーバー上で実行するか、API 呼び出しを通じて取得されます。この過程において、評価パフォーマンスの異常な向上につながる可能性のある不正な手段(データ汚染など)が厳密に検査されることはありませんでした。
さらに悪いことに、トレーニング コーパス (データ ソースなど) の詳細な構成が、既存の大規模モデルの中核となる「秘密」とみなされていることがよくあります。これにより、データ汚染の問題を調査することがさらに困難になります。
言い換えれば、優れたデータの量は限られており、多くのテスト セットでは GPT-4 と Llama-2 が必ずしも最適であるとは限りません。最高です。問題ありません。たとえば、GSM8K については最初の論文で言及されており、GPT-4 については公式技術レポートでそのトレーニング セットの使用について言及されています。
データは非常に重要だと言いませんか? では、トレーニング データが優れているため、「実際の質問」を使用する大規模モデルのパフォーマンスは向上するのでしょうか?答えは否定的です。
研究者らは、ベンチマーク リークにより大規模なモデルが誇張された結果を実行する可能性があることを実験的に発見しました。たとえば、一部のタスクでは 1.3B モデルが 10 倍のサイズを超える可能性があります。ただし、副作用として、この漏洩データをモデルの微調整やトレーニングにのみ使用すると、他の通常のテスト タスクにおけるこれらの大規模なテスト固有のモデルのパフォーマンスが悪影響を受ける可能性があります。
したがって、著者は、将来、研究者が大規模モデルを評価したり、新しいテクノロジーを研究したりする際には、次のことを行うべきであると提案しています。
- 基本的な能力 (例: テキスト生成) と高度な能力 (例: 複雑な推論) をカバーするさまざまなソースからのベンチマークをさらに使用して、LLM の機能を完全に評価します。
- 評価ベンチマークを使用する場合は、トレーニング前のデータと関連データ (トレーニング セットやテスト セットなど) の間でデータ サニタイズ チェックを実行することが重要です。また、評価ベースラインにおける汚染分析結果も参考として報告する必要がある。可能であれば、事前学習データの詳細な構成を公開することをお勧めします。
- プロンプトの感度の影響を軽減するために、多様なテスト プロンプトを使用することをお勧めします。また、潜在的な汚染リスクを警告するために、ベースライン データと既存のトレーニング前コーパスの間で汚染分析を実行することも意味があります。評価の目的で、各提出物に特別な汚染分析レポートを添付することをお勧めします。
最後に、幸いなことに、この問題は徐々にみんなの注目を集めていると言いたいと思います。技術レポート、論文調査、コミュニティでのディスカッションなど、誰もがお金を払い始めています。大きなモデルの「リストのスワイプ」問題に注意してください。
これに関するあなたの意見や効果的な提案は何ですか?
以上が大手モデルは「ランキングに勝つ」ために近道をしているのだろうか?データ汚染の問題は注目に値するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7536
7536
 15
1379
52
82
11
21
86
15
1379
52
82
11
21
86

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
