

Google の科学者 Nature のコメント: 人工知能はどのようにして脳をよりよく理解できるのか

コンピレーション | グリーン ディオール
2023 年 11 月 7 日、Google Research の上級研究員で Google チームのコネクトミクス責任者である Viren Jain が、「Nature」誌に発表しました。 「AI が脳のより良い理解にどのようにつながるか」というタイトルのレビュー記事。
論文リンク: https://www.nature.com/articles/d41586-023-03426-3
コンピューターは、脳? ?これは、数学者、理論家、実験家が長年尋ねてきた問題です。人工知能 (AI) を作成したいという願望からか、あるいは数学やコンピューターが脳のような複雑なシステムを再現できる場合にのみその動作を理解できるためです。この疑問に答えようと、研究者たちは 1940 年代から脳のニューラル ネットワークの簡略化されたモデルを開発してきました。実際、今日の機械学習の爆発的な発展は、生物学的システムに触発された初期の研究に遡ることができます。
しかし、これらの取り組みの結果により、研究者は少し異なる質問をすることができるようになりました。機械学習を使用して、脳活動をシミュレートする計算モデルを構築できるでしょうか?
こうした開発の中心にあるのは、脳データの量の増加です。 1970 年代から神経科学者は、特定の瞬間の脳の静的表現を捕捉する神経結合と形態のマップであるコネクトームを作成しており、それ以来この研究は強化されています。これらの進歩に加えて、研究者は、単一細胞の解像度で経時的な神経活動の変化を測定できる機能記録を作成する能力も向上させました。一方、トランスクリプトミクスの分野では、研究者が組織サンプル内の遺伝子活性を測定し、その活性がいつどこで起こるかをマッピングすることもできます。
これまで、これらの異なるデータ ソースを接続したり、同じサンプルの脳全体から同時に収集したりする試みはほとんど行われていません。しかし、データセットの詳細レベル、サイズ、数が増加するにつれて、特に比較的単純なモデル生物の脳では、機械学習システムによって脳モデリングへの新しいアプローチが実現可能になりつつあります。これには、コネクトームやその他のデータに基づいて人工知能プログラムをトレーニングし、生物学的システムで見られると予想される神経活動を再現することが含まれます。
計算神経科学者などは、機械学習を使用して脳全体のシミュレーションを構築する前に、いくつかの課題を解決する必要があります。ただし、従来の脳モデリング技術からの情報と、さまざまなデータセットでトレーニングされた機械学習システムを組み合わせたハイブリッド アプローチを使用すると、取り組み全体をより厳密で有益なものにすることができます。
脳のマッピング
脳のマッピングの探求は、ほぼ半世紀前、線虫カエノラブディティス・エレガンスの15年間にわたる骨の折れる研究から始まりました。過去 20 年にわたり、自動化された組織切片作成とイメージングの開発により、研究者は解剖学的データをより利用しやすくなり、コンピューティングと自動画像解析の進歩により、これらのデータセットの解析が変革されました。
コネクトームは、線虫、幼虫、成虫のキイロショウジョウバエの脳全体と、マウスとヒトの脳の一部 (それぞれ 1,000 分の 1 と 100 万分の 1) に対して生成されました。
これまでに作成された解剖図には大きな欠陥があります。イメージング手法では、化学的シナプス接続とともに電気的接続を大規模にマッピングすることはできません。研究者らは主にニューロンに焦点を当ててきたが、ニューロンをサポートする非ニューロン性グリア細胞は、神経系の情報の流れにおいて重要な役割を果たしているようだ。マッピングされたニューロンやその他の細胞に発現する遺伝子やタンパク質については、まだ不明な点が多くあります。
それでも、このような地図はいくつかの洞察をもたらしました。たとえば、キイロショウジョウバエでは、コネクトミクスによって、研究者は攻撃性などの行動に関与する神経回路の背後にあるメカニズムを特定することができます。この脳地図はまた、ショウジョウバエが自分がどこにいるのか、ある場所から別の場所にどうやって行くのかを知る回路でどのように情報を計算しているのかも明らかにした。ゼブラフィッシュ (ダニオ・レリオ) の幼生では、コネクトミクスは、匂いの分類、目の位置と動きの制御、ナビゲーションの基礎となるシナプス回路の働きを明らかにするのに役立ちました。
最終的にマウスの脳のコネクトーム全体を生成する可能性のある取り組みが進行中ですが、現在の方法ではこれには 10 年以上かかる可能性があります。マウスの脳は、約 150,000 個のニューロンで構成されるキイロショウジョウバエの脳よりも 1,000 倍近く大きい。
コネクトミクスにおけるこれらすべての進歩に加え、研究者は単一細胞および空間トランスクリプトミクスを活用して、ますます精度と特異性が高まる遺伝子発現パターンを捕捉しています。さまざまな技術により、研究者は脊椎動物の脳全体の神経活動を一度に何時間も記録することもできます。ゼブラフィッシュ幼生の脳の場合、これは約 100,000 個のニューロンから記録することを意味します。これらには、電圧やカルシウムレベルの変化に応じて変化する蛍光特性を持つタンパク質や、単一細胞の解像度で生きた脳の3Dイメージングを可能にする顕微鏡技術が含まれます。 (この方法での神経活動の記録は、電気生理学的記録よりも正確な画像が得られませんが、機能的磁気共鳴画像法などの非侵襲的方法よりははるかに優れています。)
数学と物理学
脳活動パターンをシミュレートしようとするとき、科学者は主に物理学に基づいた方法を使用します。これには、実際のニューロンまたは実際の神経系の一部の動作の数学的記述を使用して、神経系または神経系の一部のシミュレーションを生成する必要があります。また、ネットワーク接続など、観察によって検証されていない回路の側面について情報に基づいて推測することも必要です。
場合によっては、推測が広範に及ぶこともありますが (「ミステリー モデル」を参照)、別の方法では、単一細胞および単一シナプスの解像度での解剖学的マップは、研究者が仮説を反駁し、生成するのに役立ちます。
謎のモデル
データが不足しているため、特定のニューラル ネットワーク モデルが実際のシステムで起こっていることを捉えているかどうかを評価することは困難です。
9 月に終了した物議を醸した欧州人間脳プロジェクトは、当初は人間の脳全体をコンピューターでシミュレートすることを目的としていた。その目標は放棄されましたが、このプロジェクトでは、限られた生物学的測定とさまざまな合成データ生成手順に基づいて、げっ歯類の海馬モデルにおける数万個のニューロンを含むげっ歯類と人間の脳の一部をシミュレートしました。
このアプローチの大きな問題は、詳細な解剖学的図や機能図がないと、結果として得られるシミュレーションが生物学的システムで何が起こっているかをどの程度正確に捉えているかを評価することが難しいことです。
約 70 年間、神経科学者はキイロショウジョウバエの動きの計算を可能にする回路の理論的説明を洗練させてきました。 2013 年の完成以来、動き検出回路コネクトーム、そしてその後のより大型の飛行コネクトームは、回路がどのように機能するかについてのいくつかの仮説を裏付ける詳細な回路図を提供してきました。
しかし、実際のニューラル ネットワークから収集されたデータは、解剖学主導のアプローチの限界も浮き彫りにしています。
たとえば、1990 年代に完成した神経回路モデルには、カニ (Cancer borealis) の口胃神経節 (動物の胃を制御する) を構成する約 30 個のニューロンの接続性と生理機能の詳細な分析が含まれていました。動きの構造)。研究者らは、さまざまな条件下でニューロンの活動を測定することで、比較的小さなニューロンの集合であっても、神経調節物質(ニューロンやシナプスの性質を変える物質)の導入など、一見微妙な変化も完全に活性化することを発見した。回路の動作を変更します。これは、神経回路に関する仮説を導き制約するためのコネクトームやその他の豊富なデータセットがあっても、今日のデータはモデラーが生物学的システムで何が起こっているかを把握できるほど詳細ではない可能性があることを示唆しています。
これは、機械学習が前進する方法を提供できる分野です。
コネクトームやその他のデータに基づいて数千、さらには数十億のパラメーターを最適化することで、セルラー解像度機能を使用して、実際のニューラル ネットワークの動作と一致するニューラル ネットワークの動作を生成するように機械学習モデルをトレーニングできます。測定を記録します。
この機械学習モデルは、最適化されたパラメトリック接続マップを使用してニューロンの活動電位 (膜電圧の変化全体にわたって) がどのように開始され伝播されるかを記述するホジキン・ハクスリー モデルなどの従来の脳モデリング手法からの情報を組み込むことができます。 、機能活動の記録、または脳全体について取得されたその他のデータセット。あるいは、機械学習モデルには、明示的に指定された生物学的知識はほとんど含まれないが、すべて経験的に最適化された数十億または数千億のパラメータが含まれる「ブラック ボックス」アーキテクチャを含めることもできます。
たとえば、研究者は、システムの神経活動の予測を実際の生物学的システムの記録と比較することによって、そのようなモデルを評価できます。重要なのは、機械学習プログラムにトレーニングされていないデータが与えられると、機械学習システムを評価する際の標準的な手法と同様に、モデルの予測がどのように比較されるかを評価することです。
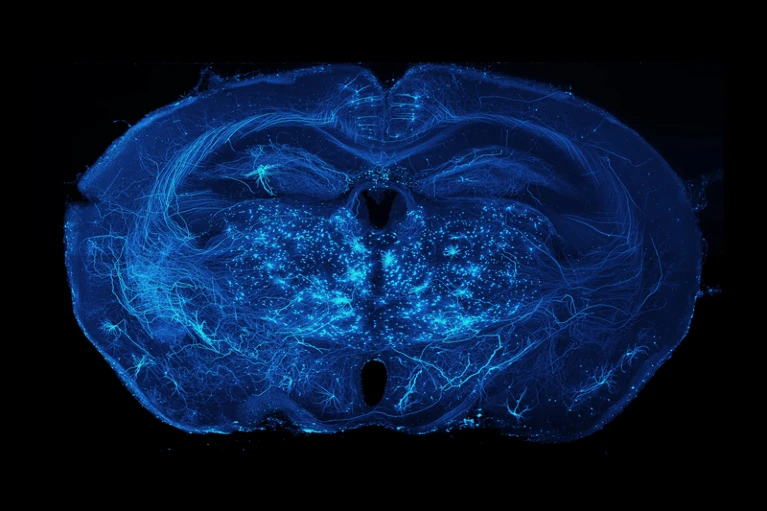
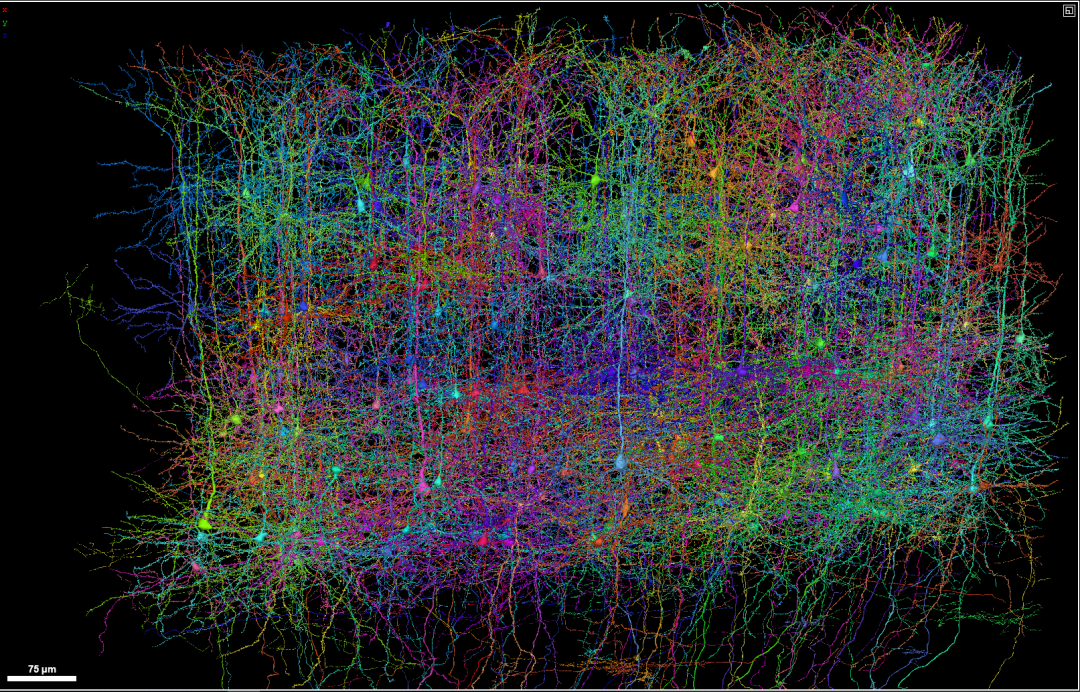
マウスの脳におけるニューロンの軸索投射。 (出典: Adam Glaser、Jayaram Chandrashekar、Karel Svoboda、アレン神経力学研究所)
このアプローチにより、数千以上のニューロンを含む脳のより厳密なモデリングが可能になります。たとえば、研究者は、より詳細な生物物理学的情報を提供する複雑なモデルよりも、計算が容易な単純なモデルの方がニューラル ネットワークを適切にシミュレートできるかどうか、またはその逆を評価できるようになります。
機械学習は、他の非常に複雑なシステムの理解を向上させるために、すでにこの方法で使用されています。たとえば、1950 年代以来、天気予報システムは通常、注意深く構築された気象現象の数学的モデルに依存してきました。現代のシステムは、数百人の研究者によるそのようなモデルの改良を繰り返した結果です。しかし、過去 5 年ほどにわたって、研究者たちは機械学習を活用したいくつかの気象予測システムを開発してきました。たとえば、これらには、気圧勾配が風速の変化を引き起こす仕組みや、風速が大気中の水分をどのように移動させるかに関する仮定がほとんど含まれていません。その代わりに、機械学習を通じて何百万ものパラメータが最適化され、過去の気象パターンのデータベースと一致する気象挙動のシミュレーションが生成されます。
この方法にはいくつかの課題が伴います。モデルが正確な予測を行ったとしても、それがどのように行われるかを説明するのは困難です。さらに、モデルはトレーニング データに含まれていないシナリオを予測できないことがよくあります。今後数日を予測するように訓練された気象モデルでは、数週間または数か月先の予測を推定するのは困難です。しかし、場合によっては、数時間先の降雨量を予測する場合、機械学習手法が従来の手法を上回るパフォーマンスを発揮します。機械学習モデルには実用的な利点もあります。これらはより単純な基礎コードを使用しており、気象学の専門知識があまりない科学者でも使用できます。
脳モデリングの場合、このアプローチは、現在のデータセットのギャップの一部を埋めるのに役立ち、個々のニューロンなどの個々の生物学的構成要素のより詳細な測定の必要性を減らすのに役立ちます。一方で、より包括的なデータセットが利用可能になると、データをモデルに組み込むことが簡単になります。
Think Big
このアイデアを実現するには、いくつかの課題を解決する必要があります。
機械学習プログラムの良さは、そのプログラムのトレーニングと評価に使用されるデータによって決まります。したがって、神経科学者はサンプルの脳全体からデータセットを取得することを目指すべきであり、それがより実現可能であれば体全体からもデータセットを取得する必要があります。脳の特定の部分からデータを収集するのは簡単ですが、機械学習を使用してニューラル ネットワークなどの高度に相互接続されたシステムをモデル化しても、システムの多くの部分が基礎となるデータに存在しない場合、有用な情報が得られる可能性は低くなります。
研究者は、同じサンプルからの脳全体から神経接続の解剖学的マップと機能記録 (おそらく将来は遺伝子発現マップ) を取得することにも取り組む必要があります。現在、どちらのグループも両方ではなく、どちらか一方を取得することだけに焦点を当てる傾向があります。
ニューロン数が 302 個しかない C. エレガンスの神経系には、研究者が 1 つのサンプルから得られた接続マップが他のサンプルでも同じであると想定できる十分な配線が備わっている可能性がありますが、一部の研究ではそうではないことが示されています。しかし、キイロショウジョウバエやゼブラフィッシュ幼生などのより大きな神経系の場合、サンプル間のコネクトームの変動が大きいため、同じサンプルから得られた構造および機能データに基づいて脳モデルをトレーニングする必要があります。
現時点では、これは 2 つの一般的なモデル生物でのみ達成できます。 C.エレガンスとゼブラフィッシュ幼生の体は透明であるため、研究者は生物の脳全体から機能を記録し、個々のニューロンの活動を正確に特定することができます。このような記録の後、動物を直ちに屠殺し、樹脂に埋め込んで切片にし、神経接続の解剖学的測定を行うことができます。しかし将来的には、研究者らは、たとえば、神経活動を高解像度で記録するための、おそらくは超音波を使用した新しい非侵襲的方法を開発することによって、そのような組み合わせたデータ取得が可能な生物の範囲を拡大する可能性がある。
同じサンプルからこのようなマルチモーダルなデータセットを取得するには、研究者間の広範な協力、大規模なチームサイエンスへの投資、より包括的な取り組みのための資金提供機関のサポートの強化が必要です。しかし、このアプローチには、2016年から2021年の間に1立方ミリメートルのマウスの脳の機能的および解剖学的データを取得した米国情報先端研究プログラム活動のMICrONSプロジェクトなどの前例があります。
このデータを取得することに加えて、神経科学者は主要なモデリング目標と進捗状況を測定するための定量的指標について合意する必要があります。モデルの目標は、過去の状態に基づいて個々のニューロンの動作を予測することなのか、それとも脳全体なのか?単一のニューロンの活動が重要な指標となるべきでしょうか、それとも活動している数十万のニューロンの割合であるべきでしょうか?同様に、生物学的システムにおける神経活動の正確な表現を構成するものは何でしょうか?正式に合意されたベンチマークは、モデリング手法を比較し、長期にわたる進捗状況を追跡するために不可欠です。
最後に、計算神経科学者や機械学習の専門家を含む多様なコミュニティに脳モデリングの課題を提示するには、研究者はより広範な科学コミュニティに対して、どのモデリングタスクが最優先であり、そのパフォーマンスを評価するためにどの指標を使用すべきかを明確にする必要があります。モデル。 WeatherBench は、天気予報モデルを評価および比較するためのフレームワークを提供するオンライン プラットフォームで、便利なテンプレートを提供します。
主要テクノロジーの複雑さ
脳モデリングへの機械学習アプローチが科学的に有用であるかどうかを疑問視する人もいますが、それは当然のことです。脳がどのように機能するかを理解しようとする問題は、単純に大規模な人工ネットワークがどのように機能するかを理解しようとする問題に置き換えることはできるでしょうか?
しかし、視覚や嗅覚などの感覚刺激を脳がどのように処理し、エンコードするかを決定することに関係する神経科学の分野で同様の手法を使用することは、心強いことです。研究者は、機械学習システムと組み合わせて、いくつかの生物学的詳細が指定された古典的にモデル化されたニューラル ネットワークをますます使用しています。後者は、画像認識などの神経システムの視覚または聴覚能力を再現するために、大規模な視覚または音声データセットでトレーニングされます。結果として得られたネットワークは、生物学的ネットワークと顕著な類似点を示しましたが、真のニューラル ネットワークよりも分析と調査が容易でした。
今のところは、おそらく、現在の脳マッピングやその他の研究からのデータで機械学習モデルを訓練し、生物学的システムで見られるものに対応する神経活動を再現できるかどうかを問うだけで十分でしょう。ここでは、失敗さえも楽しいものになる可能性があり、マッピング研究をより深く掘り下げる必要があることを示唆しています。
以上がGoogle の科学者 Nature のコメント: 人工知能はどのようにして脳をよりよく理解できるのかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
AI にとって、数学オリンピックはもはや問題ではありません。木曜日、Google DeepMind の人工知能は、AI を使用して今年の国際数学オリンピック IMO の本当の問題を解決するという偉業を達成し、金メダル獲得まであと一歩のところまで迫りました。先週終了したばかりの IMO コンテストでは、代数、組合せ論、幾何学、数論を含む 6 つの問題が出題されました。 Googleが提案したハイブリッドAIシステムは4問正解で28点を獲得し、銀メダルレベルに達した。今月初め、UCLA 終身教授のテレンス・タオ氏が、100 万ドルの賞金をかけて AI 数学オリンピック (AIMO Progress Award) を宣伝したばかりだったが、予想外なことに、AI の問題解決のレベルは 7 月以前にこのレベルまで向上していた。 IMO に関する質問を同時に行うのが最も難しいのは、最も歴史が長く、規模が最も大きく、最も否定的な IMO です。
 結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
編集者 |KX 今日に至るまで、単純な金属から大きな膜タンパク質に至るまで、結晶学によって決定される構造の詳細と精度は、他のどの方法にも匹敵しません。しかし、最大の課題、いわゆる位相問題は、実験的に決定された振幅から位相情報を取得することのままです。デンマークのコペンハーゲン大学の研究者らは、結晶相の問題を解決するための PhAI と呼ばれる深層学習手法を開発しました。数百万の人工結晶構造とそれに対応する合成回折データを使用して訓練された深層学習ニューラル ネットワークは、正確な電子密度マップを生成できます。この研究では、この深層学習ベースの非経験的構造解法は、従来の非経験的計算法とは異なり、わずか 2 オングストロームの解像度で位相問題を解決できることが示されています。これは、原子解像度で利用可能なデータのわずか 10% ~ 20% に相当します。
 自然の視点: 医療における人工知能のテストは混乱に陥っています。何をすべきでしょうか?
Aug 22, 2024 pm 04:37 PM
自然の視点: 医療における人工知能のテストは混乱に陥っています。何をすべきでしょうか?
Aug 22, 2024 pm 04:37 PM
編集者 | ScienceAI 限られた臨床データに基づいて、何百もの医療アルゴリズムが承認されています。科学者たちは、誰がツールをテストすべきか、そしてどのようにテストするのが最善かについて議論しています。デビン シン氏は、救急治療室で小児患者が治療を長時間待っている間に心停止に陥るのを目撃し、待ち時間を短縮するための AI の応用を模索するようになりました。 SickKids 緊急治療室からのトリアージ データを使用して、Singh 氏らは潜在的な診断を提供し、検査を推奨する一連の AI モデルを構築しました。ある研究では、これらのモデルにより医師の診察が 22.3% 短縮され、医療検査が必要な患者 1 人あたりの結果の処理が 3 時間近く高速化できることが示されました。ただし、研究における人工知能アルゴリズムの成功は、これを証明するだけです。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 最適な分子を自動的に特定し、合成コストを削減する MIT は、分子設計の意思決定アルゴリズム フレームワークを開発します。
Jun 22, 2024 am 06:43 AM
最適な分子を自動的に特定し、合成コストを削減する MIT は、分子設計の意思決定アルゴリズム フレームワークを開発します。
Jun 22, 2024 am 06:43 AM
編集者 | 創薬の合理化における Ziluo AI の利用は爆発的に増加しています。新薬の開発に必要な特性を備えている可能性のある候補分子を数十億個スクリーニングします。材料の価格からエラーのリスクまで、考慮すべき変数が非常に多いため、たとえ科学者が AI を使用したとしても、最適な候補分子の合成コストを秤量することは簡単な作業ではありません。ここで、MIT の研究者は、最適な分子候補を自動的に特定する定量的意思決定アルゴリズム フレームワークである SPARROW を開発しました。これにより、合成コストを最小限に抑えながら、候補が望ましい特性を持つ可能性を最大限に高めることができます。このアルゴリズムは、これらの分子を合成するために必要な材料と実験手順も決定しました。 SPARROW では、複数の候補分子が入手可能な場合が多いため、分子のバッチを一度に合成するコストが考慮されます。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
