


11 月 10 日のニュースでは、大規模言語モデル (LLM) が急速に台頭しており、言語の生成と理解に明るい見通しが示されており、その影響は言語分野を超えて論理と数学にまで広がっています。 、物理学およびその他の分野。
ただし、これらの「並外れたエネルギー」を解放したい場合は、高い代償を支払う必要があります。たとえば、540B モデルのトレーニングには、Project PaLM の 6144 TPUv4 チップが必要です。 ; 175B モデル GPT-3 のトレーニングには、数千ペタフロップス/s-day が必要です。
良い解決策は、低精度でトレーニングすることです。これにより、処理速度が向上し、メモリ使用量と通信コストが削減されます。現在主流のトレーニング システムには、Megatron-LM、MetaSeq、Colossal-AI が含まれます。これらは、大規模な言語モデルをトレーニングするためにデフォルトで FP16/BF16 混合精度または FP32 完全精度を使用します
これらの精度レベルは大規模な言語モデルには必要ですが、不可欠ですが、計算コストがかかります。
FP8 低精度を使用すると、速度が 2 倍向上し、メモリコストが 50% ~ 75% 削減され、通信コストも節約できます。
現在、FP8 フレームワークと互換性があるのは Nvidia Transformer Engine だけであり、マスターの重みと勾配を FP16 または FP32 の高精度に維持しながら、主に GEMM (一般行列乗算) 計算にこの精度を利用します。
この課題に対処するために、Microsoft Azure と Microsoft Research の研究者チームは、大規模な言語モデルのトレーニングに合わせて調整された効率的な FP8 混合精度フレームワークを導入しました。
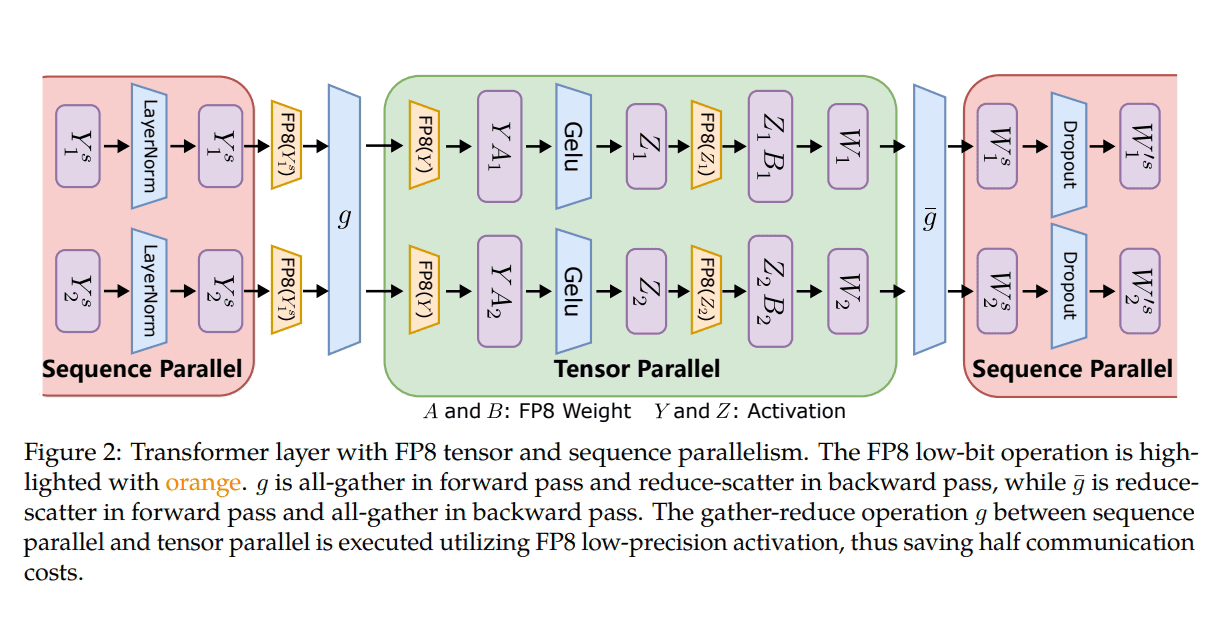
Microsoft は、分散型および混合精度トレーニングに FP8 を活用するために 3 つの最適化ステージを導入しました。これらのレベルが進むにつれて、FP8 の統合の増加が明らかになり、LLM トレーニング プロセスへの影響が大きくなることを示唆しています。
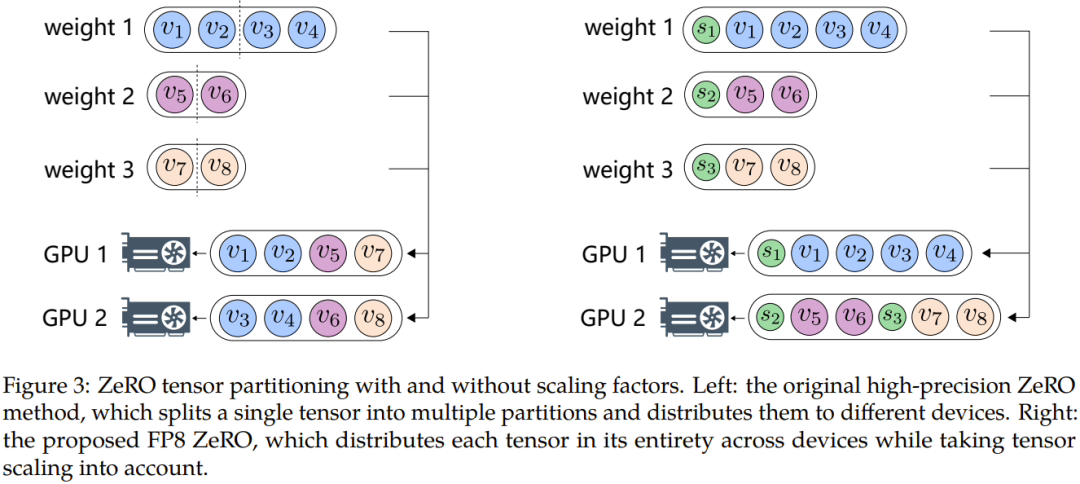
さらに、データのオーバーフローやアンダーフローなどの問題を克服するために、マイクロソフトの研究者は、自動サンプリングと正確なデカップリングという 2 つの主要な方法を提案しました。前者には、精度に敏感ではないコンポーネントが含まれるため、精度が低下し、動的にデカップリングが行われます。 Tensor サンプリング係数を調整して、勾配値が FP8 表現範囲内に収まるようにします。これにより、通信中のアンダーフローやオーバーフローのイベントが防止され、よりスムーズなトレーニング プロセスが保証されます。
Microsoft は、広く採用されている BF16 混合精度方式と比較して、 メモリ使用量が 27% ~ 42% 削減され、 重み勾配通信のオーバーヘッドが 63% ~ 65% 大幅に削減されることをテストしました。 Megatron-LM などの広く採用されている BF16 フレームワークよりも 64% 高速に実行され、Nvidia Transformer Engine よりも 17% 高速に実行されます。
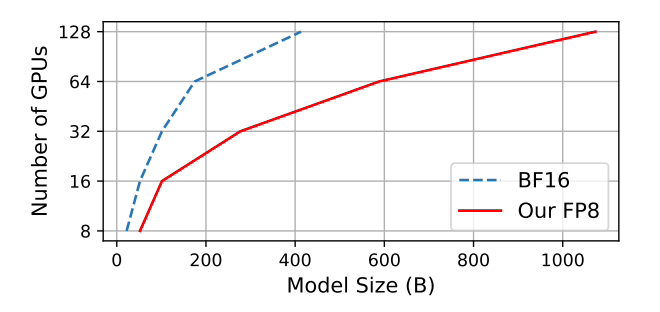
GPT-175B モデルをトレーニングする場合、ハイブリッド FP8 高精度フレームワークは、TE (Transformer Engine) と比較して、H100 GPU プラットフォーム上のメモリを 21% 節約します。時間が 17% 短縮されます。
このサイトには、GitHub アドレス と論文のアドレスが添付されています: https://www.php.cn/link/7b3564b05f78b6739d06a2ea3187f5ca#
以上がMicrosoft、新しい混合精度トレーニング フレームワーク FP8 をリリース: BF16 より 64% 高速、メモリ使用量が 42% 削減の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



