

大規模な AI モデルに自律的に質問させる: GPT-4 は人間と会話する際の障壁を打ち破り、より高いレベルのパフォーマンスを実証します

人工知能分野の最新の傾向では、人工的に生成されたプロンプトの品質が大規模言語モデル (LLM) の応答精度に決定的な影響を与えます。 OpenAI は、これらの大規模な言語モデルのパフォーマンスには、正確で詳細かつ具体的な質問が重要であると提案しています。しかし、一般ユーザーは自分の質問が LLM にとって十分に明確であることを保証できるでしょうか?
書き直す必要がある内容は次のとおりです。特定の状況における人間の自然な理解と機械の解釈との間には大きな違いがあることは注目に値します。たとえば、「偶数月」という概念は人間にとって明らかに 2 月や 4 月などの月を指しますが、GPT-4 はそれを偶数日の月と誤解する可能性があります。これは、日常のコンテキストを理解する際の人工知能の限界を明らかにするだけでなく、これらの大規模な言語モデルとより効果的にコミュニケーションする方法について熟考するよう促します。人工知能技術の継続的な進歩に伴い、人間と機械の間の言語理解のギャップをどのように埋めるかは、今後の研究の重要なテーマです。
# この件について、カリフォルニア大学ロサンゼルス校は次のように述べています。アンヘレス (UCLA) の一般人工知能研究所 (Gu Quanquan 教授率いる) は、大規模な言語モデル (GPT-4 など) の問題理解における曖昧さの問題に対する革新的な解決策を提案する研究レポートを発表しました。この研究は、博士課程の学生であるDeng Yihe、Zhang Weitong、Chen Zixiangによって完了しました

- ##論文アドレス: https://arxiv.org/pdf/2311.04205.pdf
- プロジェクトアドレス: https://uclaml.github.io/Rephrase-and -応答
書き直された中国語のコンテンツは次のとおりです。 このソリューションの核心は、大規模な言語モデルに質問を繰り返し拡張させて、回答の精度を向上させることです。研究の結果、GPT-4 によって再定式化された質問はより詳細になり、質問形式がより明確になったことがわかりました。この再表現と拡張の方法により、モデルの応答精度が大幅に向上します。実験によれば、十分にリハーサルを行った質問は、回答の精度が 50% から 100% 近くまで向上します。このパフォーマンスの向上は、大規模な言語モデル自体が改善される可能性を実証するだけでなく、人工知能が人間の言語をより効果的に処理し理解する方法についての新しい視点も提供します。
方法
上記の調査結果に基づいて、研究者らは、「質問を言い換えて展開し、応答する」(略して RaR) というシンプルだが効果的なプロンプトを提案しました。このプロンプトワードは、質問に対する LLM の回答の質を直接的に向上させ、問題処理における重要な改善を示しています。

研究チームは、GPT-4 などを最大限に活用するために、「Two-step RaR」と呼ばれる RaR の亜種も提案しました。大きなモデルを使って問題を再現します。このアプローチは 2 つのステップに従います: 第 1 に、特定の質問に対して、特殊な言い換え LLM を使用して言い換え質問を生成します。第 2 に、元の質問と言い換え質問を組み合わせて、応答 LLM に回答を求めるために使用します。

結果
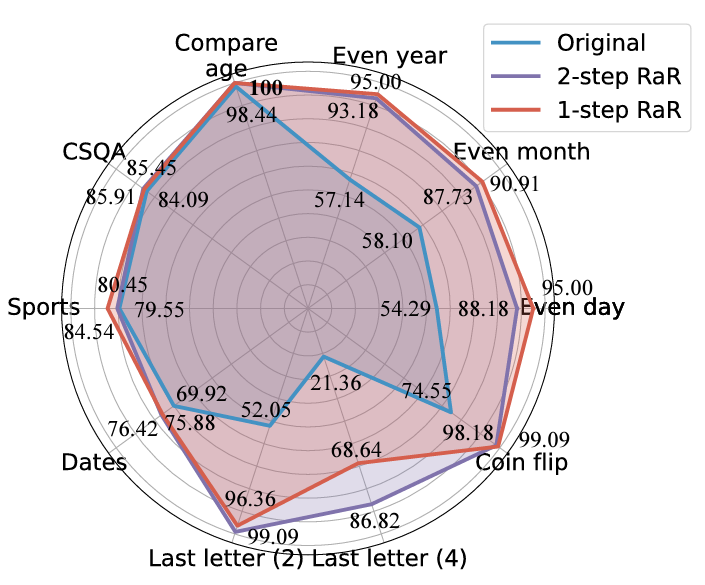
研究者らはさまざまなタスクを実施しました。結果は、シングルステップ RaR または 2 ステップ RaR のいずれかが GPT4 の解答精度を効果的に向上できることを示しています。特に、RaR は、GPT-4 では困難だったタスクで大幅な改善を示し、場合によっては 100% の精度に近づくことさえあります。研究チームは、次の 2 つの重要な結論を要約しました:
1. Restate and Extend (RaR) は、プラグアンドプレイのブラックボックス プロンプト手法を提供し、システム上の LLM パフォーマンスを効果的に向上させることができます。さまざまなタスク。
2. 質問応答 (QA) タスクで LLM のパフォーマンスを評価する場合、質問の品質をチェックすることが重要です。
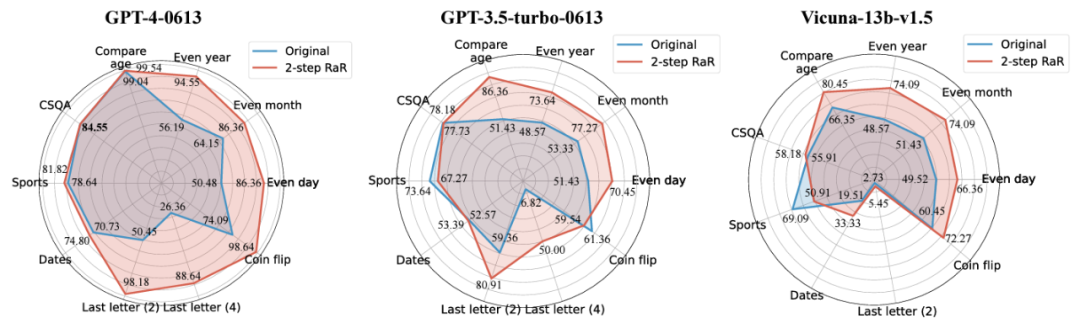
研究者らは、2 ステップ RaR 法を使用して、GPT-4、GPT-3.5、Vicuna-13b-v.15 などのさまざまなモデルのパフォーマンスを調査する研究を実施しました。実験結果は、GPT-4 など、より複雑なアーキテクチャと強力な処理能力を備えたモデルの場合、RaR 手法により処理問題の精度と効率が大幅に向上できることを示しています。 Vicuna などのより単純なモデルの場合、改善は小さくなりますが、それでも RaR 戦略の有効性が示されています。これに基づいて、研究者たちは、さまざまなモデルを再話した後、質問の質をさらに調査しました。小規模なモデルに対する言い換え質問は、質問の意図を混乱させる可能性があります。また、GPT-4 のような高度なモデルは、人間の意図に一致する言い換え質問を提供し、他のモデルの回答を強化することができます

この調査結果により、重要な現象が明らかになります。言語モデルの異なるレベルによって練習される質問の質と有効性には違いがあります。特に GPT-4 のような高度なモデルの場合、再説明された問題は、問題をより明確に理解できるだけでなく、他の小規模なモデルのパフォーマンスを向上させるための効果的なインプットとしても機能します。
思考連鎖 (CoT) との違い
RaR と思考連鎖 (CoT) の違いを理解するために、研究者たちは数学的手法を提案しました。 RaR が CoT と数学的にどのように異なるのか、またそれらをどのように簡単に組み合わせることができるのかを説明します。
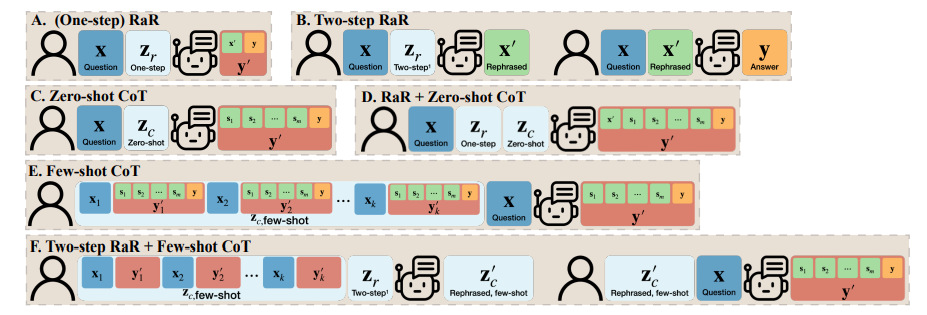
モデルの推論機能を強化する方法を詳しく検討する前に、この研究では、モデルの推論を確実に行うために質問の質を向上させる必要があることを指摘しています。能力を適切に評価できます。例えば、「コイン投げ」問題では、GPT-4は「投げる」を人間の意図とは異なるランダムな投げ動作として理解していることが判明した。 「ステップごとに考えてみましょう」という言葉でモデルを推論したとしても、この誤解は推論の過程で残ります。質問を明確にして初めて、大規模な言語モデルが意図した質問に答えました

さらに、研究者たちは、質問のテキストに加えて、Q&A が含まれていることにも気づきました。少数ショット CoT のサンプルも人間によって作成されます。このため、人工的に構築されたサンプルに欠陥がある場合、大規模言語モデル (LLM) はどのように反応するのかという疑問が生じます。この研究は興味深い例を提供し、貧弱な数ショットの CoT 例が LLM に悪影響を与える可能性があることを発見しました。 「最終文字結合」タスクを例にとると、以前に使用した問題例は、モデルのパフォーマンスの向上にプラスの効果を示しました。ただし、最後の文字の検索から最初の文字の検索など、プロンプト ロジックが変更されると、GPT-4 は間違った答えを返しました。この現象は、人為的な例に対するモデルの敏感さを浮き彫りにします。

研究者らは、RaR を使用すると、GPT-4 が特定の例の論理的欠陥を修正できるため、少数ショット CoT の品質とパフォーマンスが向上することを発見しました。堅牢性
結論
人間と大規模言語モデル (LLM) との間のコミュニケーションは誤解される可能性があります: 人間にとっては明らかな問題でも、他の問題は誤解される可能性があります大規模な言語モデルで理解できるようになります。 UCLA の研究チームは、LLM に質問に答える前に質問を言い換えて明確にする新しい方法である RaR を提案することでこの問題を解決しました。
RaR の有効性は、実行された多くの実験評価で実証されています。いくつかのベンチマーク データセットでの効果が確認されています。さらに分析した結果、問題を再記述することで問題の品質を向上させることができ、この改善効果は異なるモデル間で移行できることがわかりました。
将来の展望としては、RaR と同様のことが期待されます。手法は今後も改善され、CoT などの他の手法との統合により、人間と大規模な言語モデルの間の対話により正確かつ効率的な方法が提供され、最終的には AI の説明と推論能力の境界が拡大されます。
以上が大規模な AI モデルに自律的に質問させる: GPT-4 は人間と会話する際の障壁を打ち破り、より高いレベルのパフォーマンスを実証しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
vue.js文字列タイプの配列をオブジェクトの配列に変換する方法は?
Apr 07, 2025 pm 09:36 PM
概要:Vue.js文字列配列をオブジェクト配列に変換するための次の方法があります。基本方法:定期的なフォーマットデータに合わせてマップ関数を使用します。高度なゲームプレイ:正規表現を使用すると、複雑な形式を処理できますが、慎重に記述して考慮する必要があります。パフォーマンスの最適化:大量のデータを考慮すると、非同期操作または効率的なデータ処理ライブラリを使用できます。ベストプラクティス:コードスタイルをクリアし、意味のある変数名とコメントを使用して、コードを簡潔に保ちます。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
