
 テクノロジー周辺機器
AI
Google の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。
テクノロジー周辺機器
AI
Google の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。
Google の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。

Google DeepMind によって最近発見された新しい結果は、Transformer 分野で広範な論争を引き起こしました:
その一般化能力は、トレーニング データを超えるコンテンツには拡張できません。
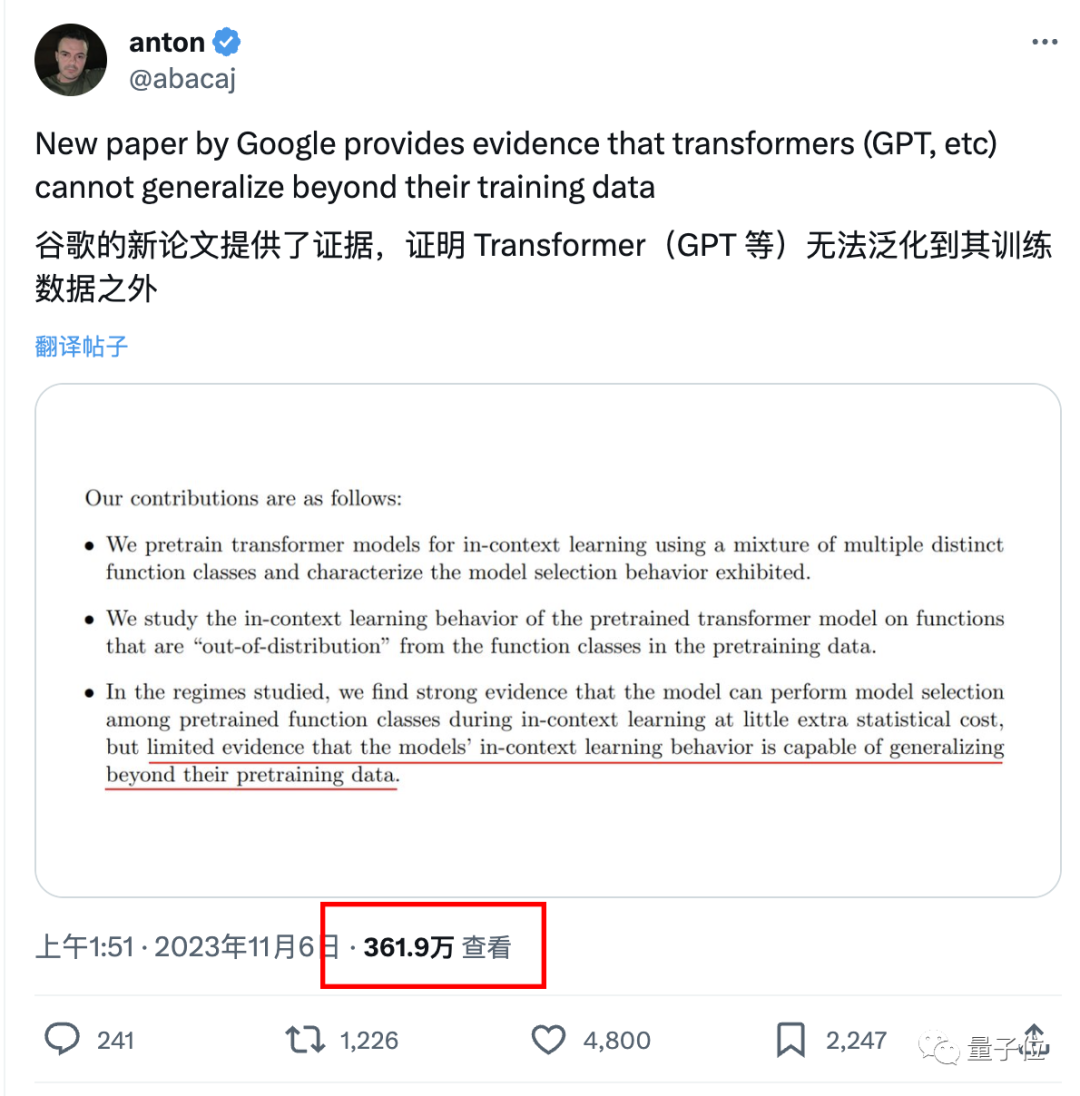
この結論はまださらに検証されていませんが、多くの著名人を驚かせています。たとえば、ケラスの父親であるフランソワ・ショレ氏は、もしこのニュースが本当なら、と述べました。 、それは大きなニュースになるでしょう、モデル界では大きな出来事です。

Google Transformer は今日の大規模モデルの背後にあるインフラストラクチャであり、私たちがよく知っている GPT の「T」はそれを指します。
一連の大規模モデルは強力なコンテキスト学習機能を示し、例を迅速に学習して新しいタスクを完了できます。
しかし現在、Google の研究者もその致命的な欠陥を指摘しているようです。それは、トレーニング データ、つまり人間の既存の知識を超えると無力です。
一時期、多くの専門家は、AGI は再び手の届かないものになったと信じていました。
一部のネチズンは、論文には見落とされている重要な詳細がいくつかあると指摘しました。たとえば、実験には GPT-2 の規模のみが含まれ、トレーニングは含まれていませんデータが十分に豊富ではない
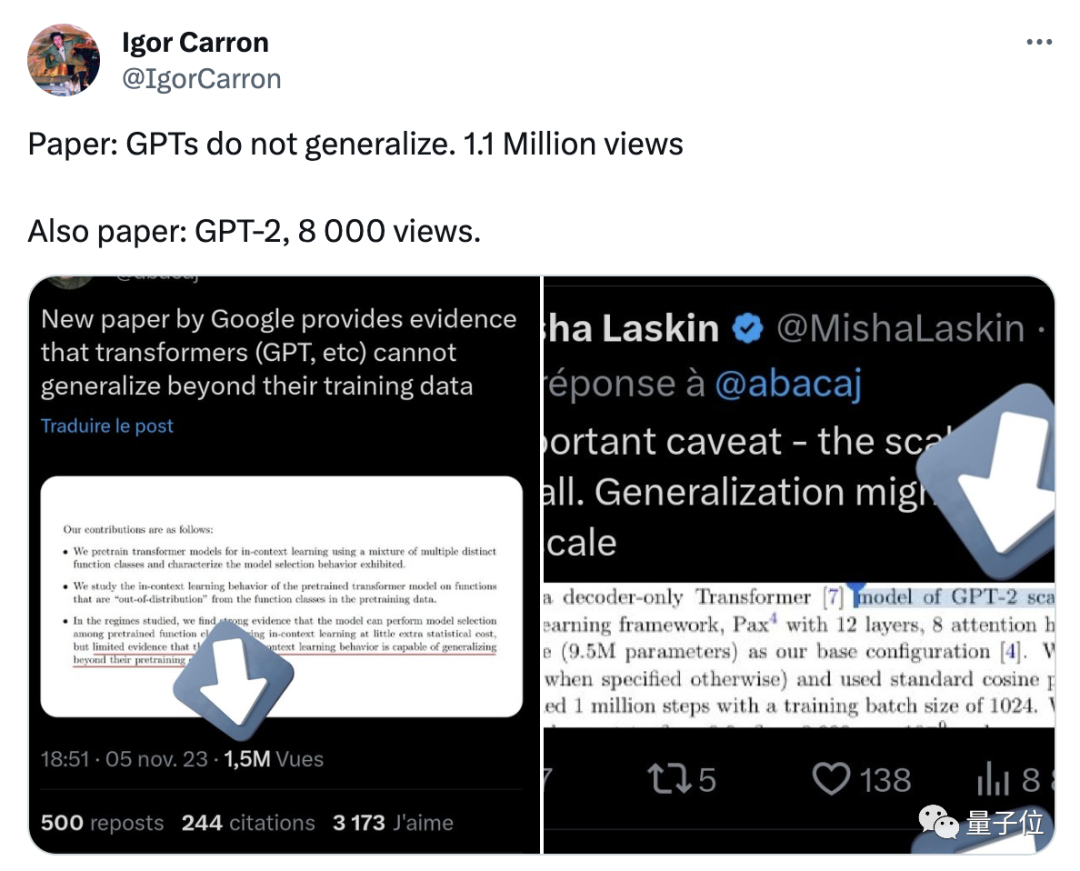
時間が経つにつれて、この論文を注意深く研究したネットユーザーが研究結果自体には何も間違っていないことを指摘するようになりましたが、人々はそれを踏まえた過剰な解釈。

この論文がネチズンの間で激しい議論を引き起こした後、著者の一人も次の 2 つの点を公に明らかにしました:
まず第一に、実験では単純なトランスフォーマーを使用しました。は「大きな」モデルでも言語モデルでもありません;
第二に、モデルは新しいタスクを学習できますが、新しいタイプタスク##に一般化することはできません。


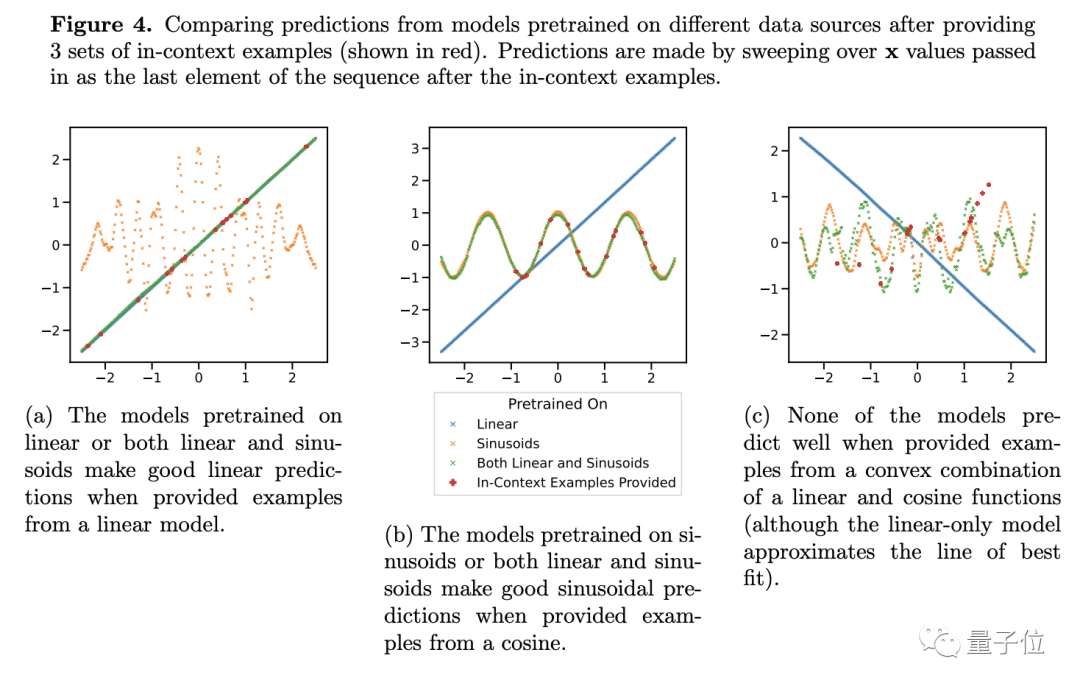
彼の結論をさらに検証するために、著者は線形または正弦関数の重みを調整しましたが、それでも Transformer の予測パフォーマンスは大きく変わりませんでした。
例外が 1 つだけあります。項目の 1 つの重みが 1 に近い場合、モデルの予測結果は実際の状況とより一致します。
##重みが 1 の場合、未知の新しい関数がトレーニング中に見られた関数になることを意味します。この種のデータは明らかにモデルの一般化能力には役立ちません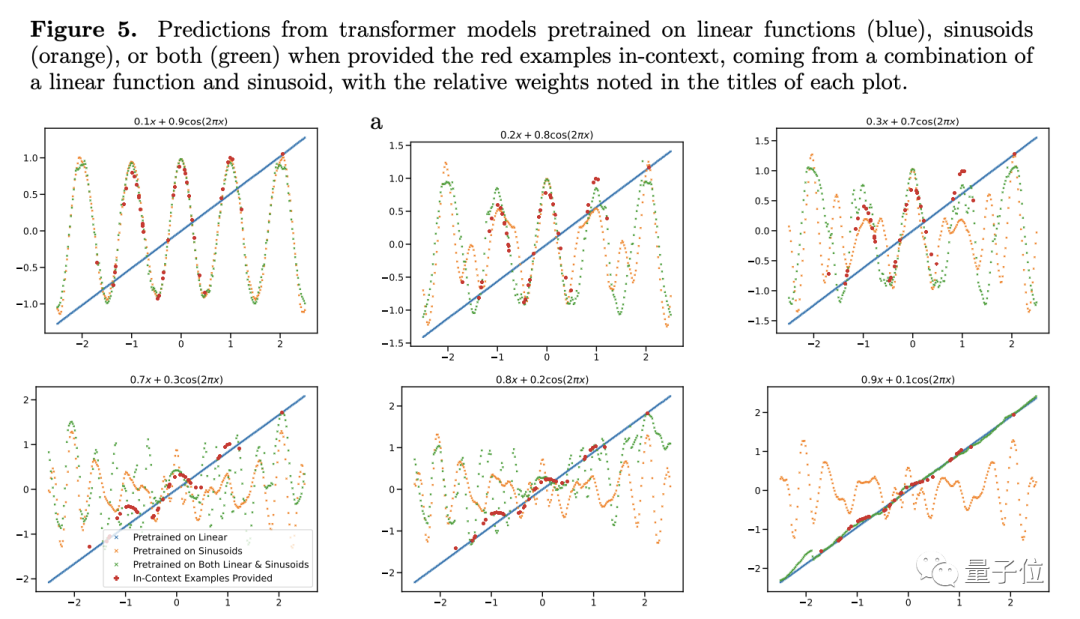
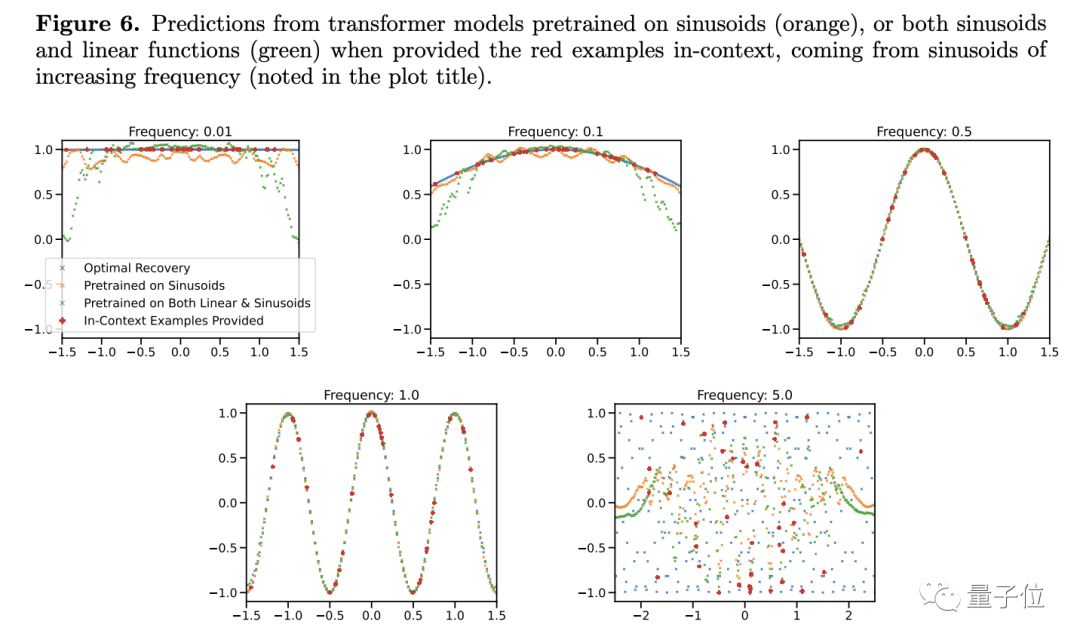 #したがって、著者は条件が少しでも良ければと考えていますが、それは少し異なります。大規模なモデルではどうすればよいかわかりません。これは一般化能力が低いということを意味しませんか?
#したがって、著者は条件が少しでも良ければと考えていますが、それは少し異なります。大規模なモデルではどうすればよいかわかりません。これは一般化能力が低いということを意味しませんか?
著者は、研究におけるいくつかの制限と、関数データの観察をトークン化された自然言語の問題に適用する方法についても説明します。
チームは言語モデルでも同様の実験を試みましたが、いくつかの障害に遭遇し、タスクファミリー(ここでは関数の種類に相当)や凸の組み合わせなどを適切に定義する方法はまだ解決されていません。
ただし、Samuel のモデルは規模が小さく、レイヤーが 4 つしかありません。Colab で 5 分間トレーニングした後は、線形関数と正弦関数の組み合わせに適用できます
##一般化できない場合はどうすればよいか
スローン賞受賞者でUCLA教授のGu Quanquan氏は、論文の結論自体は物議を醸すものではないが、過度に解釈すべきではないと述べた。 
Transformer の汎化能力を注意深く調査すると、残念ながらかなりの時間がかかると思います。弾丸だ、もう少し長く飛べ。 
は万能薬ではないため、この現象は実際には驚くべきことではありません。
トレーニング データが適切であるため、大規模モデルのパフォーマンスは良好です。私たちが重視するコンテンツ。
Jim はさらに付け加えました。「これは、1,000 億枚の犬と猫の写真を使用して視覚モデルをトレーニングし、そのモデルに航空機を識別させて、次のことを見つけてください、と言っているようなものです。」うわー、本当に彼のことを知りません。

この表現を中国語に変えてください。汎化能力が足りないので、学習サンプル以外のデータがなくなるまで学習させます。
それでは、この研究についてどう思いますか?
文書アドレス: https://arxiv.org/abs/2311.00871
以上がGoogle の大規模モデル研究は激しい論争を引き起こしました。トレーニング データを超えた一般化能力が疑問視されており、ネットユーザーは AGI 特異点が遅れる可能性があると述べています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7503
7503
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54


 DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekは、特定のデータベースまたはシステムでのみ検索する独自の検索エンジンであり、より速く、より正確です。それを使用する場合、ユーザーはドキュメントを読み、さまざまな検索戦略を試し、ユーザーエクスペリエンスに関するヘルプを求めてフィードバックを求めて、利点を最大限に活用することをお勧めします。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
 2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
