

GPT-4の不正行為が発覚! LeCun氏は、トレーニングセット、チワワまたはマフィンの順序の混乱がエラーにつながるテストを行う場合は注意を呼び掛けています

GPT-4 は、かつて無数の人々を驚かせた有名なインターネット ミーム「チワワまたはブルーベリー マフィン」を解決しました。
しかし、今度は「不正行為」として告発されてしまったのです!
 写真
写真
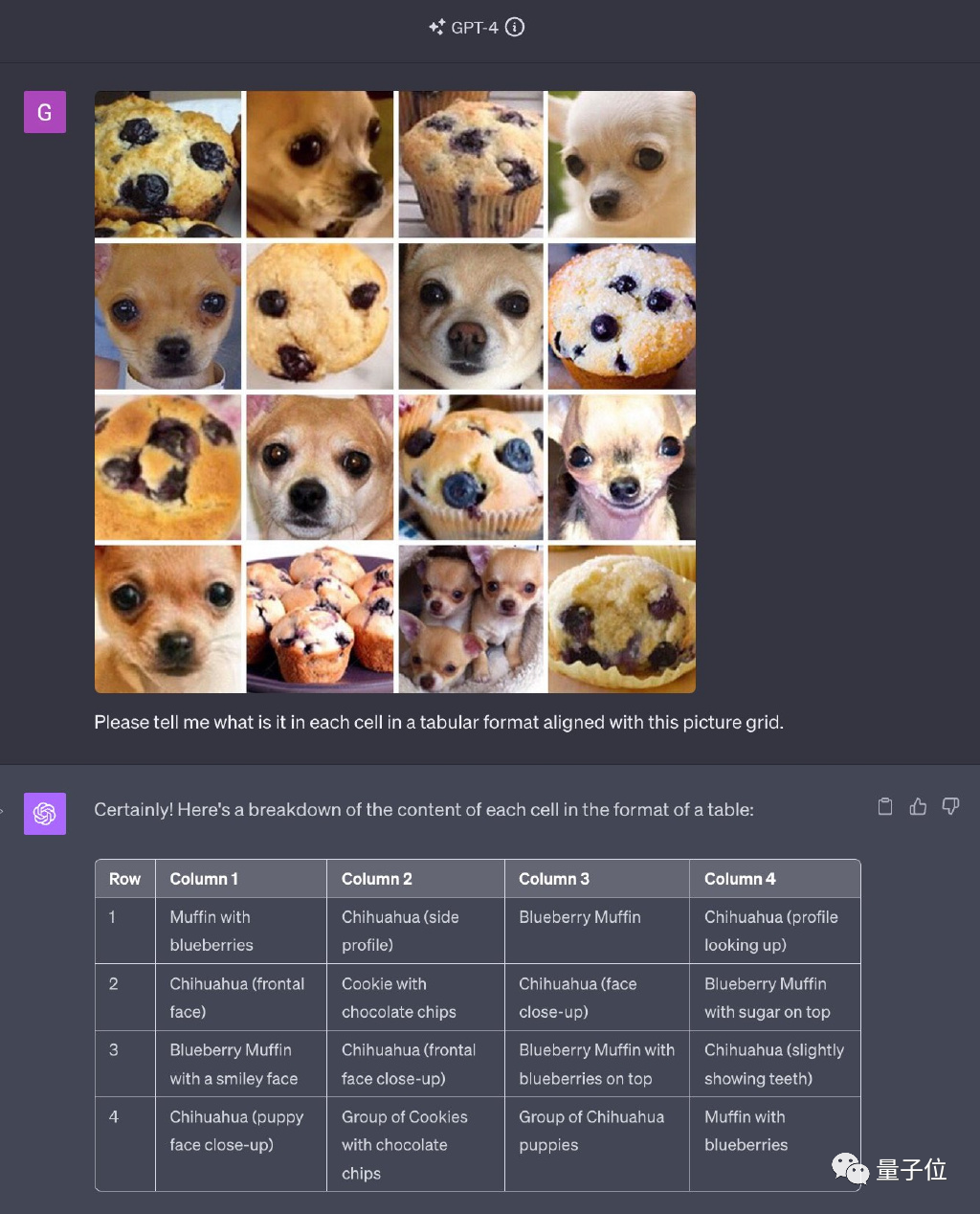
元の質問に表示されている写真はすべて使用されていますが、順序と配置がめちゃくちゃです。
GPT-4 の最新バージョンは、オールインワン機能で有名です。しかし、驚くべきことに、認識した画像の数に誤りがあり、本来は正しく認識されていたチワワでも認識誤りが発生しました。
 Pictures
Pictures
GPT-4 が元の画像で良好なパフォーマンスを発揮する理由は何ですか?
UCSC 助教授 Xin Eric Wang の推測によると、このテストを実施する理由は、インターネット上のオリジナル画像の人気が高すぎるためです。彼は、GPT-4 がトレーニング プロセス中に元の答えに何度も遭遇し、それらをうまく記憶したと信じています。
チューリング賞受賞者の 3 人のうちの 1 人である LeCun 氏も、この点に注目し、次のように述べています:
トレーニング セットでのテストには注意してください。
 写真
写真
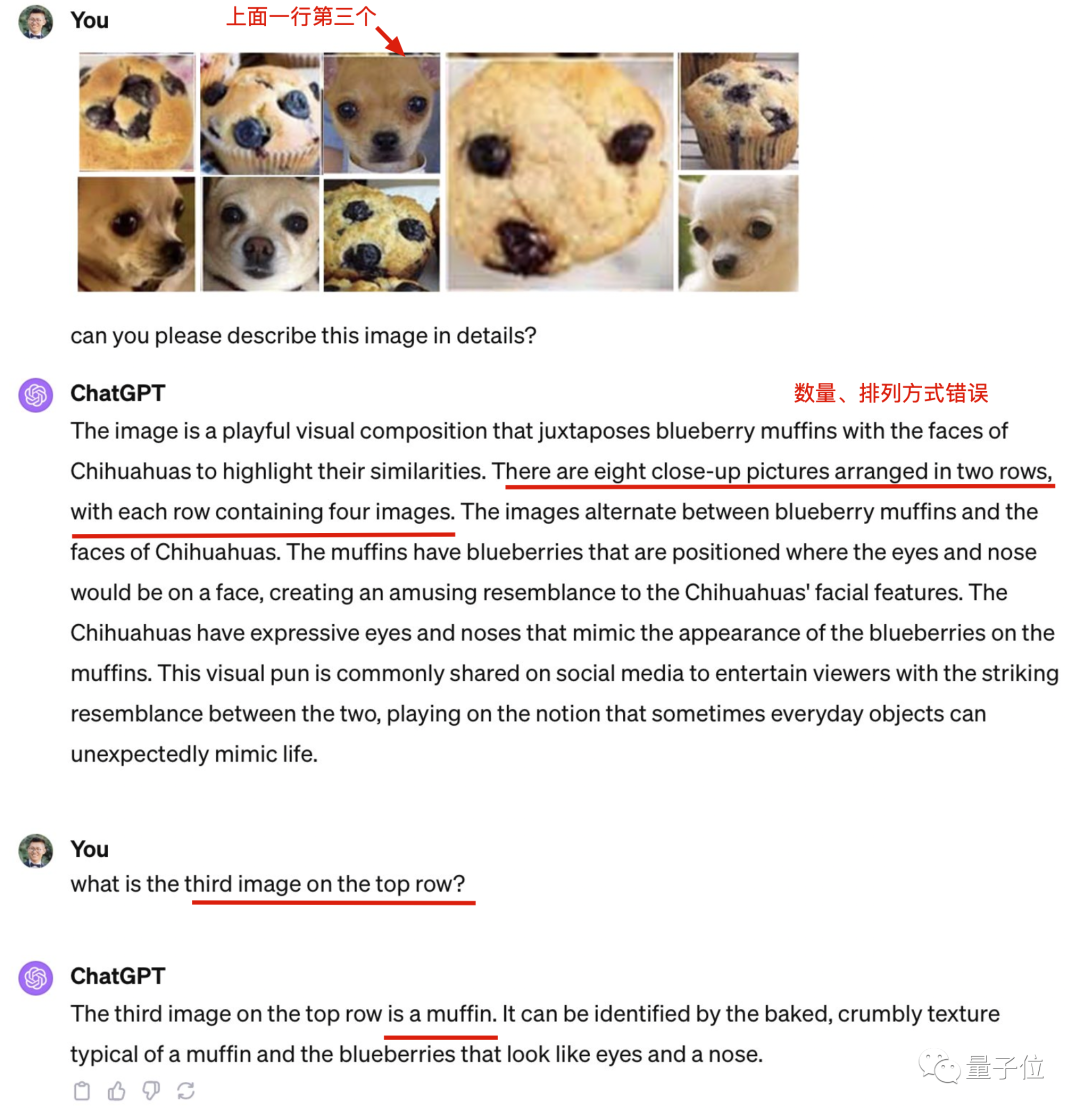
テディとフライドチキンの違いがわかりません
元の写真の人気はどうですか。インターネット上でのみ この有名な問題は、コンピュータ ビジョンの分野では古典的な問題となっており、関連する論文研究でも何度も登場しています。
 写真
写真
多くのネチズンは、元の画像の影響に関係なく、GPT-4 の機能が制限されている領域に関して独自のテスト計画を提案しています
配置が複雑すぎて影響を与える可能性を排除するために、単純な 3x3 配置に変更し、多くの間違いを犯した人もいます。
 写真
写真
 写真
写真
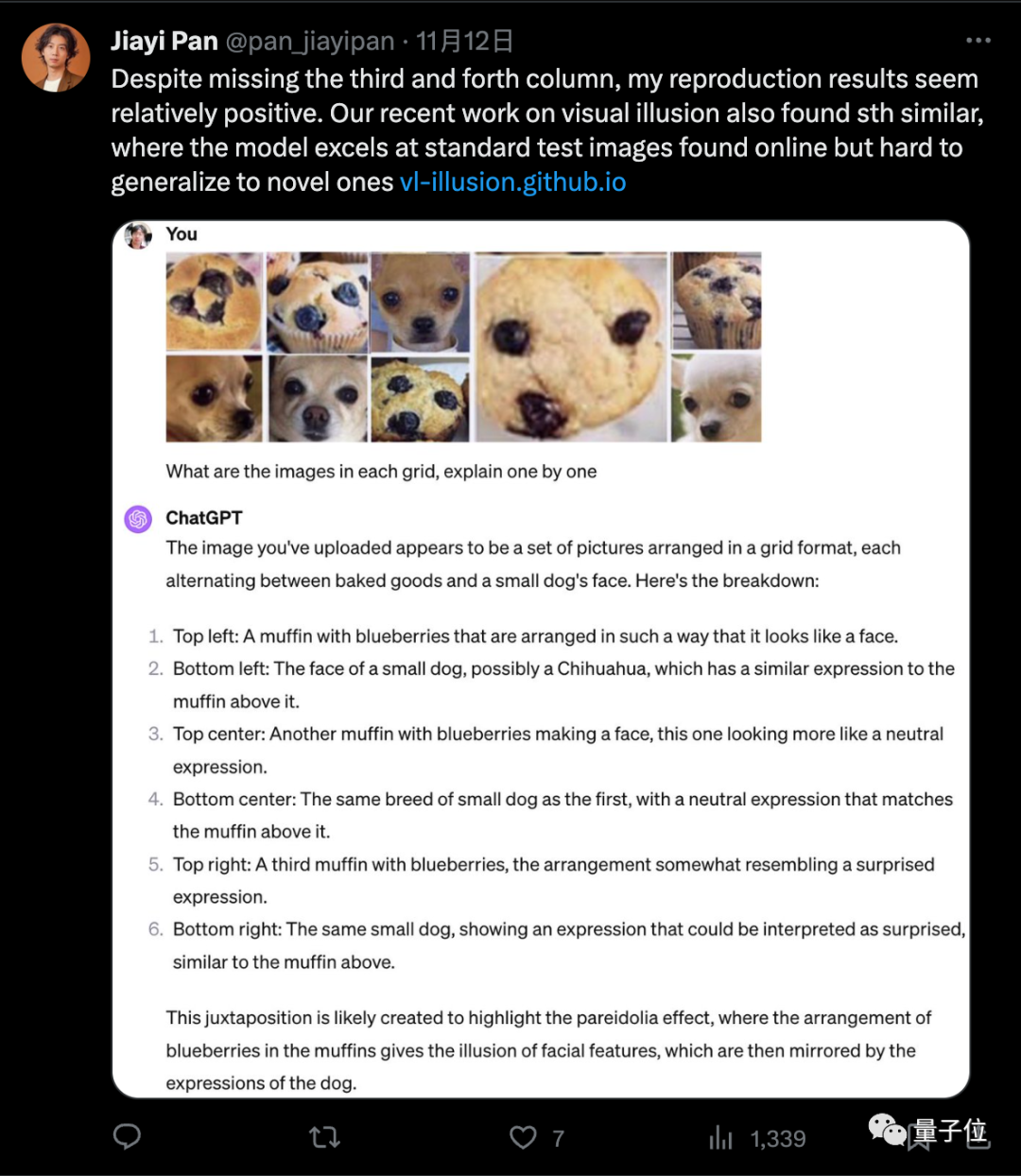
誰かが写真の一部を取り出して GPT に送信しました別に - 4、正解率は 5/5 でした。
 #写真
#写真
#写真 最終的に、誰かが人工知能に「深呼吸」と「段階的に考える」という 2 つの重要なテクニックを同時に使用することに成功し、正しい答えを導き出しました。結果
最終的に、誰かが人工知能に「深呼吸」と「段階的に考える」という 2 つの重要なテクニックを同時に使用することに成功し、正しい答えを導き出しました。結果
写真 GPT-4の回答「これは視覚的なダジャレまたは有名なミームの一例です」の文言からも、元の画像がトレーニング データに実際に存在する可能性があります。以下のように言い換えます: ただし、GPT-4 はその回答で「これは視覚的なダジャレまたは有名なミームの一例です」と使用しており、これは元の画像が実際にトレーニング データに存在する可能性があることも明らかにしています
GPT-4の回答「これは視覚的なダジャレまたは有名なミームの一例です」の文言からも、元の画像がトレーニング データに実際に存在する可能性があります。以下のように言い換えます: ただし、GPT-4 はその回答で「これは視覚的なダジャレまたは有名なミームの一例です」と使用しており、これは元の画像が実際にトレーニング データに存在する可能性があることも明らかにしています
 ##最後に、よく一緒に現れる「テディまたはフライドチキン」テストも誰かがテストしたところ、GPT-4 がうまく区別できないことがわかりました。
##最後に、よく一緒に現れる「テディまたはフライドチキン」テストも誰かがテストしたところ、GPT-4 がうまく区別できないことがわかりました。
写真
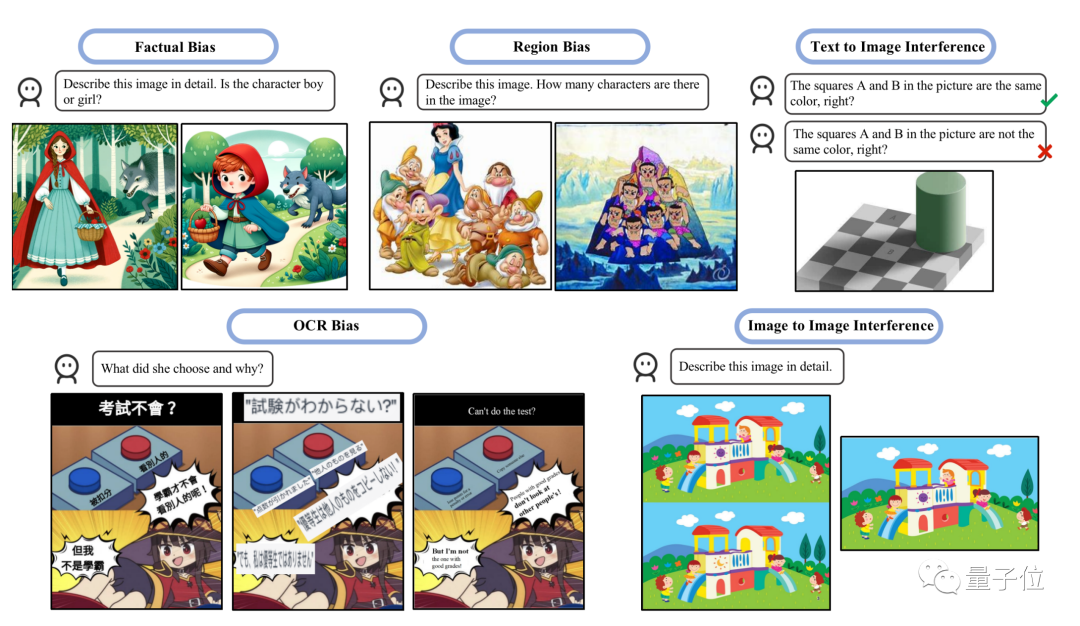
大きなモデルの「ナンセンス」は、学術界では錯視問題と呼ばれています。大型モデル 幻視の問題は、最近、研究の方向性として注目されています。 EMNLP 2023 での研究では、1,600 個のデータ ポイントを含む GVIL データセットを作成し、錯視の問題の体系的な評価を実施しました 研究によると、大規模なモデルは錯覚の影響を受けやすく、人間の知覚に近いことがわかっています もう 1 つの最近の研究バイアスと干渉という 2 種類の錯覚の評価に焦点を当てます 調査では、GPT-4V は複数の画像を一緒に解釈するときに混乱することが多く、画像を個別に送信するときにパフォーマンスが向上することが指摘されています。 「チワワまたはワッフル」テストの観察結果と一致します。 自己修正や思考連鎖プロンプトなどの一般的な緩和策は、これらの問題を効果的に解決できず、テストの結果、LLaVA と Bard はなど。モーダル モデルにも同様の問題があります。 さらに、研究では、GPT-4V は西洋文化的背景を持つ画像や英語のテキストを持つ画像の解釈に優れていることもわかりました。 たとえば、GPT-4V は 7 人の小人の白雪姫を正しく数えることができますが、7 つのひょうたん人形は 10 に数えます。 参考リンク: [1]https://twitter.com/xwang_lk/status/1723389615254774122[2]https://arxiv. org/abs/2311.00047[3]https://arxiv.org/abs/2311.03287 この「ブルーベリーまたはチョコレートビーン」はちょっと多すぎます...
この「ブルーベリーまたはチョコレートビーン」はちょっと多すぎます... 写真
写真錯視は一般的な方向になりました
 Picture
Picture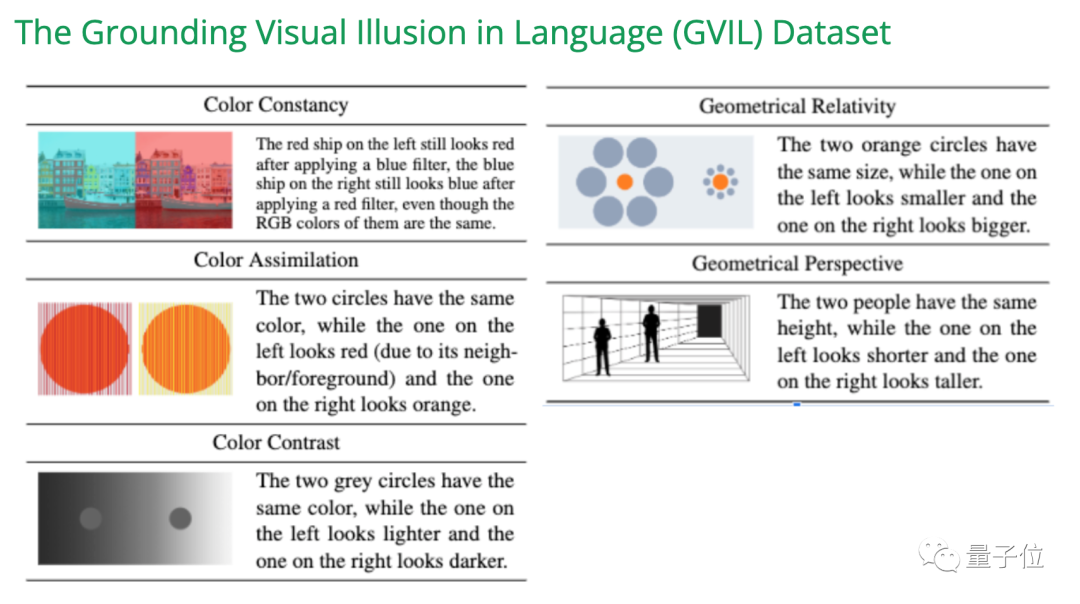 写真
写真 図
図
 写真
写真 写真
写真 写真
写真
以上がGPT-4の不正行為が発覚! LeCun氏は、トレーニングセット、チワワまたはマフィンの順序の混乱がエラーにつながるテストを行う場合は注意を呼び掛けていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
81
11
21
68
15
1378
52
81
11
21
68

 GPT-4の不正行為が発覚! LeCun氏は、トレーニングセット、チワワまたはマフィンの順序の混乱がエラーにつながるテストを行う場合は注意を呼び掛けています
Nov 13, 2023 pm 08:17 PM
GPT-4の不正行為が発覚! LeCun氏は、トレーニングセット、チワワまたはマフィンの順序の混乱がエラーにつながるテストを行う場合は注意を呼び掛けています
Nov 13, 2023 pm 08:17 PM
GPT-4 は、かつて数え切れないほどの人を驚かせた、有名なインターネット ミーム「チワワまたはブルーベリー ワッフル」を解決しました。しかし、今度は「不正行為」の疑いがかけられているのです!写真はすべて原題に出てくるものですが、順番や配置がめちゃくちゃです。 GPT-4 の最新バージョンは、オールインワン機能で有名です。しかし、驚くべきことに、認識する画像の数に誤りがあり、本来正しく認識されているチワワですら間違った画像を認識してしまうことがありました。 UCSCの助教授であるXinEricWang氏によると、このテストを実施した理由は、インターネット上のオリジナル画像の人気が高すぎるためだという。彼は、GPT-4 がトレーニング中に元の答えに何度も遭遇し、それらを記憶することに成功したと信じています。
 ChatGPT と Bard は高価すぎるため、8 つの無料のオープンソースの大規模モデル ソリューションを紹介します。
May 08, 2023 pm 10:13 PM
ChatGPT と Bard は高価すぎるため、8 つの無料のオープンソースの大規模モデル ソリューションを紹介します。
May 08, 2023 pm 10:13 PM
1. LLaMALLaMA プロジェクトには、70 億から 650 億のパラメーターのサイズを持つ基本的な言語モデルのセットが含まれています。これらのモデルは数百万のトークンでトレーニングされ、すべて公開されているデータセットでトレーニングされます。その結果、LLaMA-13B は GPT-3 (175B) を上回りましたが、LLaMA-65B は Chinchilla-70B や PaLM-540B などの最高のモデルと同様のパフォーマンスを示しました。 LLaMA リソースからの画像: 研究論文: 「LLaMA: OpenandEfficientFoundationLanguageModels(arxiv.org)」 [https://arxiv.or
 カリフォルニア大学バークレー校は大規模な一般視覚推論モデルの開発に成功し、3 人の上級学者が研究に参加するために力を合わせました
Dec 04, 2023 pm 06:25 PM
カリフォルニア大学バークレー校は大規模な一般視覚推論モデルの開発に成功し、3 人の上級学者が研究に参加するために力を合わせました
Dec 04, 2023 pm 06:25 PM
ビジュアル (ピクセル) モデルだけでどこまでできるでしょうか?カリフォルニア大学バークレー校とジョンズ・ホプキンス大学の新しい論文では、この問題を調査し、さまざまな CV タスクに対するラージ ビジョン モデル (LVM) の可能性を実証しています。最近、GPT や LLaMA などの大規模言語モデル (LLM) が世界中で普及しています。 Large Vision Models (LVM) の構築は大きな懸念事項です。それを達成するには何が必要でしょうか? LLaVA などの視覚言語モデルによって提供されるアイデアは興味深いものであり、検討する価値がありますが、動物界の法則によれば、視覚能力と言語能力には関連がないことがすでにわかっています。たとえば、人間とは異なる言語体系を持っているにもかかわらず、人間以外の霊長類の視覚世界は人間の視覚世界と非常に似ていることが多くの実験で示されています。
 清華大学と浙江大学がオープンソース ビジュアル モデルの爆発的な普及を主導し、GPT-4V、LLaVA、CogAgent などのプラットフォームが革命的な変化をもたらす
Jan 04, 2024 am 08:10 AM
清華大学と浙江大学がオープンソース ビジュアル モデルの爆発的な普及を主導し、GPT-4V、LLaVA、CogAgent などのプラットフォームが革命的な変化をもたらす
Jan 04, 2024 am 08:10 AM
現在、GPT-4Vision は言語理解と視覚処理において驚くべき能力を示しています。ただし、パフォーマンスを犠牲にすることなく、コスト効率の高い代替手段を探している人にとって、オープンソースは無限の可能性を秘めた選択肢となります。 Youssef Hosni は外国の開発者で、GPT-4V に代わる絶対にアクセシビリティが保証された 3 つのオープンソースの代替案を提供してくれました。 3 つのオープンソース視覚言語モデル LLaVa、CogAgent、BakLLaVA は視覚処理の分野で大きな可能性を秘めており、私たちが深く理解する価値があります。これらのモデルの研究開発により、より効率的で正確な視覚処理ソリューションが提供されます。これらのモデルを適用することで、グラフを改善できます。
 GPT-4は受け入れを拒否し、Bardに追い抜かれた:最新モデルが市場に参入
Feb 01, 2024 pm 05:39 PM
GPT-4は受け入れを拒否し、Bardに追い抜かれた:最新モデルが市場に参入
Feb 01, 2024 pm 05:39 PM
ChatbotArena の「大規模モデル予選コンテスト」の権威あるリストが更新されました。Google Bard が GPT-4 を上回り、GPT-4 Turbo に次いで 2 位にランクされました。しかし、これに対して多くのネチズンは「不満」と「不公平」を表明した。 Google AI責任者のジェフ・ディーン氏が、大型モデルの新バージョンであるGemini Pro-scaleが搭載されているため、Bardのパフォーマンスが大幅に向上したと明らかにしたことが判明した。これは、「ランク マッチ」でプレイする吟遊詩人にはネットワーク機能があることも意味します。ネチズンの疑問はこの点を中心に展開しています。オンラインとオフラインの大規模モデルを同じランキング リストに混在させると、非常に誤解を招きやすいのです。ハギングフェイスの「アルパカ最高責任者」オマール・サンセビエロも
 Bard: ChatGPT の新たな競合相手
Nov 08, 2023 am 11:46 AM
Bard: ChatGPT の新たな競合相手
Nov 08, 2023 am 11:46 AM
人工知能のユーザー エクスペリエンスの最適化を継続的に追求する中で、Google は最新かつ最先端の会話システム Bard を発表しました。
 Calabash Kids ですらそれを理解できず、リーグ・オブ・レジェンドを説明する GPT-4V は幻覚の問題に直面しています。
Nov 13, 2023 pm 09:21 PM
Calabash Kids ですらそれを理解できず、リーグ・オブ・レジェンドを説明する GPT-4V は幻覚の問題に直面しています。
Nov 13, 2023 pm 09:21 PM
大規模なモデルに画像とテキストの両方を理解させるのは、思っているよりも難しい場合があります。 「AI Spring Festival Gala」として知られる OpenAI の最初の開発者カンファレンスの開幕後、コードを書かずにアプリケーションをカスタマイズできる GPT など、同社がリリースした新製品が多くの人の友人の輪に殺到しました。フットボールの試合や「リーグ・オブ・レジェンド」のゲームなどを解説するためのビジュアル API。しかし、誰もがこれらの製品の使いやすさを賞賛している一方で、一部の人々は弱点を発見し、GPT-4V のような強力なマルチモーダル モデルには実際にはまだ大きな錯覚があり、基本的な視覚能力がまだ備わっていると指摘しています。 「ソングケーキとチワワ」、「テディドッグとフライドチキン」などの類似した画像を区別できない。 GPT-4Vにはスポンジケーキとチワワの違いがわかりません。出典:習
 ChatGPT vs Google Bard (2023): 徹底した比較
Jun 08, 2023 pm 05:10 PM
ChatGPT vs Google Bard (2023): 徹底した比較
Jun 08, 2023 pm 05:10 PM
ChatGPT と GoogleBard はどちらも、ユーザーが入力したプロンプトに対する応答を生成するように設計された人工知能チャットボットです。適切に使用すれば、ChatGPT と GoogleBard の両方を使用して、コンテンツの制作と開発における一部のビジネス プロセスをサポートできます。この記事を読んで各ツールの機能、長所、短所を学び、どれがあなたのビジネスに最適かを判断してください。 ChatGPTとは何ですか? ChatGPT は OpenAI によって開発された人工知能チャットボットで、ユーザーが入力したテキストに基づいて人間のような回答を生成でき、多数の大規模な言語モデルでトレーニングされています。 GoogleBardとは何ですか? GoogleBard も人工知能チャットボットです。 ChatGで
