

利益予測はもう難しくありません。scikit-learn 線形回帰手法を使用すると、半分の労力で 2 倍の結果を得ることができます

1. はじめに
生成人工知能は間違いなく革新的なテクノロジーですが、ほとんどのビジネス上の問題に対しては、回帰や分類などの従来の機械学習モデルが依然として第一の選択肢です。
書き直された内容: プライベート エクイティやベンチャー キャピタルなどの投資家が機械学習をどのように活用できるかを想像してみてください。この質問に答えるには、まず、データ投資家が何に関心を持っているか、そしてそれがどのように使用されているかを理解する必要があります。企業への投資に関する意思決定は、経費、成長、バーンレートなどの定量化可能なデータだけでなく、創業者の記録、顧客からのフィードバック、製品体験などの定性的なデータにも基づいています
この記事では基本事項を紹介します。線形回帰に関する知識があれば、完全なコードはここにあります。
書き直す必要がある内容は次のとおりです: [コード]: https://github.com/RoyiHD/linear-regression
2. プロジェクト設定
この記事このプロジェクトには Jupyter Notebook を使用します。まずいくつかのライブラリをインポートします。
インポート ライブラリ
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3. データ
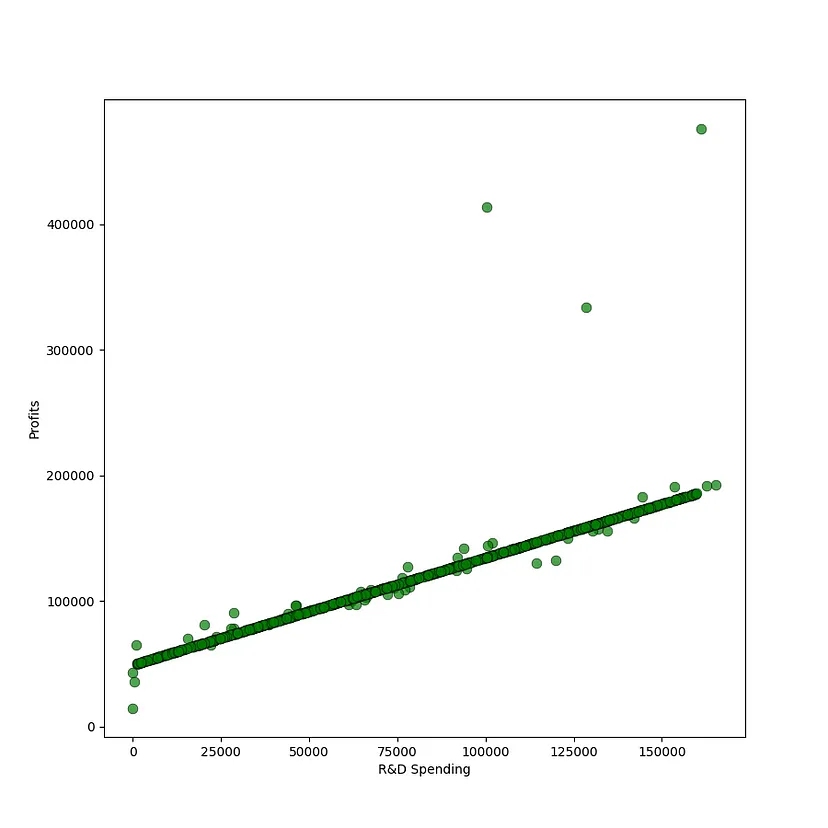
問題を単純化するために、この記事では地域データを使用します。データは会社の経費カテゴリと利益を表します。さまざまなデータポイントの例をいくつか見ることができます。この記事では、支出データを使用して線形回帰モデルをトレーニングし、利益を予測したいと考えています。
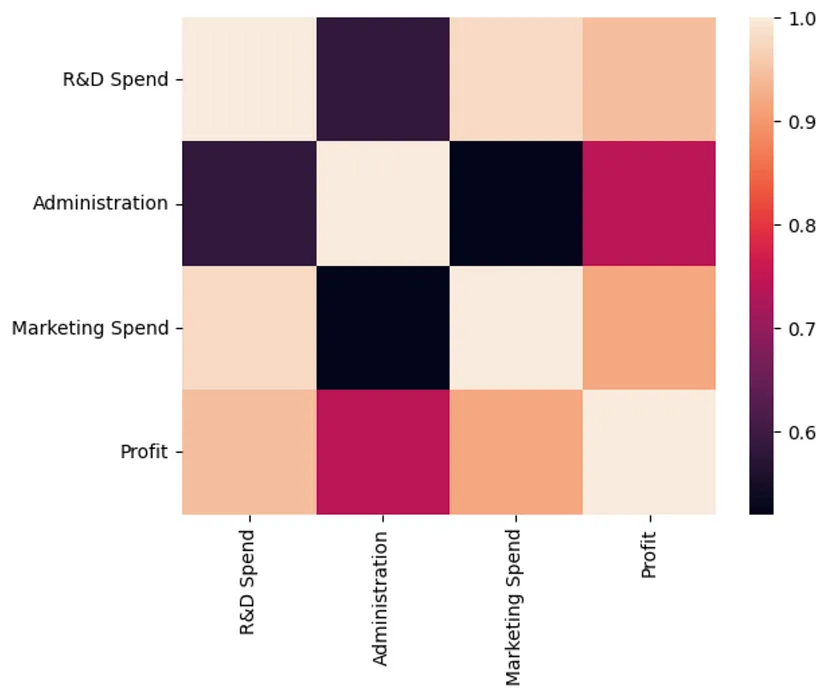
この記事で説明されているデータは企業の支出に関するものであることを理解することが重要です。有意義な予測力は、支出データを収益増加、地方税、償却、市場状況に関するデータと組み合わせた場合にのみ導き出されます
研究開発費 |
管理 |
# #マーケティング
|
投資収益 |
| 書き換える必要がある内容は次のとおりです: 165349.2 | ##136897.8
| 書き換える必要があるのは: 192261.83||
|
|
|
|
|
| #153441.51 | ##101145.55
|
|
以上が利益予測はもう難しくありません。scikit-learn 線形回帰手法を使用すると、半分の労力で 2 倍の結果を得ることができますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7680
7680
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 ファルコン3にアクセスする方法は? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
ファルコン3にアクセスする方法は? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
ファルコン3:革新的なオープンソースの大規模な言語モデル LLMSの称賛されたFalconシリーズの最新のイテレーションであるFalcon 3は、AIテクノロジーの重要な進歩を表しています。 Technology Innovation Institute(TII)によって開発されたこのオープン
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
