

NetEase Cloud Musicコールドスタート技術の推奨システム


#1. 問題の背景: コールド スタート モデリングの必要性と重要性
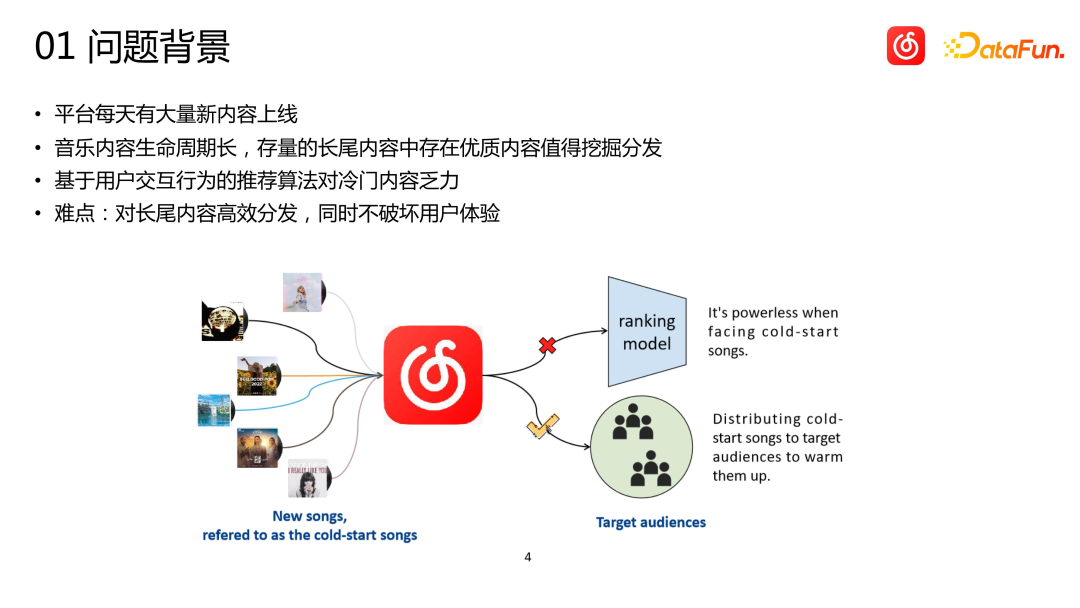
Asコンテンツ プラットフォームである Cloud Music には、毎日大量の新しいコンテンツがオンラインに配信されます。クラウド音楽プラットフォーム上の新しいコンテンツの量は、ショートビデオなどの他のプラットフォームに比べて比較的少ないですが、実際の量は皆の想像をはるかに超えている可能性があります。同時に、音楽コンテンツは、短いビデオ、ニュース、製品の推奨とは大きく異なります。音楽のライフサイクルは非常に長期間に及び、多くの場合、数年単位で測定されます。曲によっては数か月、数年眠っていた後に爆発することもありますし、名曲は10年以上経ってもなお強い生命力を持っていることもあります。したがって、音楽プラットフォームのレコメンド システムでは、他のカテゴリーでのレコメンドよりも、人気のないロングテールの高品質コンテンツを発見し、適切なユーザーにレコメンドすることが重要です。ロングテール アイテム (曲) にはユーザー インタラクション データが不足しているため、主に行動データに依存するレコメンデーション システムの場合、正確な配信を実現することは非常に困難です。理想的な状況は、トラフィックのごく一部を探索と配信に使用できるようにし、探索中にデータを蓄積できることです。ただし、オンライン トラフィックは非常に貴重なので、探索するとユーザー エクスペリエンスが簡単に損なわれることがよくあります。ビジネス指標に直接責任を負う役割として、推奨事項により、これらのロングテール項目について不確実な調査をあまり行うことはできません。したがって、アイテムの潜在的なターゲット ユーザーを最初からより正確に見つけることができる必要があります。つまり、インタラクション レコードがゼロでアイテムをコールド スタートする必要があります。
2. 技術的ソリューション: 機能の選択、モデルのモデリング
次に、Cloud Music で採用されている技術的ソリューションを共有します。
#核心的な問題は、コールド スタート プロジェクトの潜在的なターゲット ユーザーを見つける方法です。質問を 2 つの部分に分けます:

ユーザーがクリックして再生せずにプロジェクトを配布するのに役立つ機能として、コールド スタート プロジェクトに関する他のどのような効果的な情報を使用できますか?ここでは、音楽のマルチモーダル機能を使用します
これらの機能を使用してコールド スタート配信をモデル化するにはどうすればよいですか?これに対処するために、次の 2 つの主要なモデリング ソリューションを共有します。
I2I モデリング: 自己誘導対照学習強化コールド スタート アルゴリズム。
- U2I モデリング: マルチモーダル DSSM ユーザー関心境界モデリング。
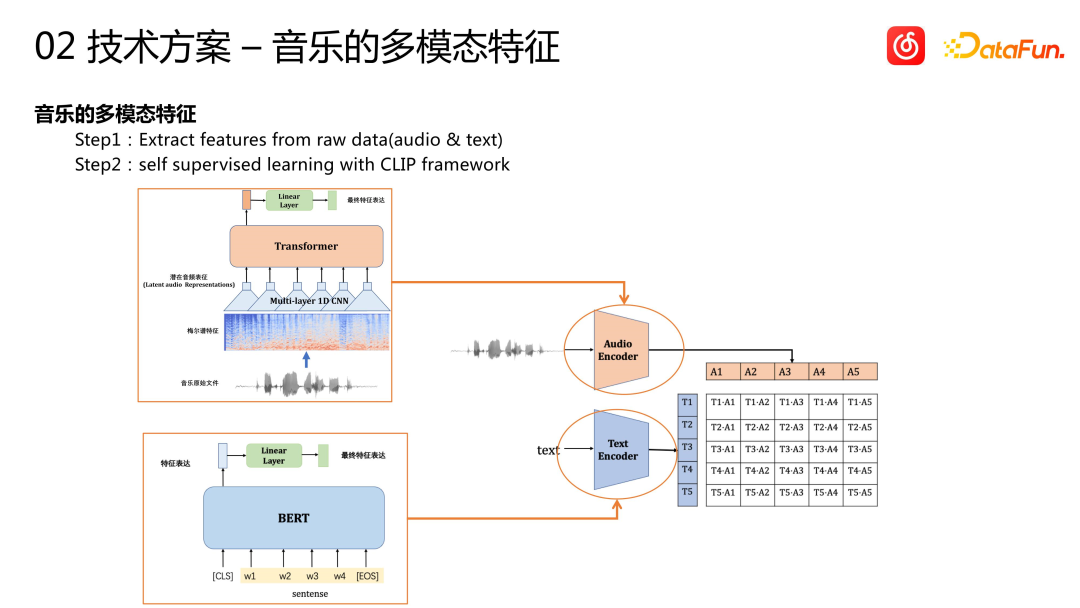
- #中国語に書き直すと: 楽曲自体は一種のマルチモーダル情報であり、言語やジャンルなどのタグ情報に加え、楽曲の音声やテキスト(曲名や歌詞など)にも豊富な情報が含まれています。この情報を理解し、その情報とユーザーの行動との相関関係を発見することが、コールド スタートを成功させる鍵となります。現在、クラウド音楽プラットフォームは CLIP フレームワークを使用してマルチモーダルな特徴表現を実現しています。オーディオ特徴の場合、最初にいくつかのオーディオ信号処理方法を使用してビデオ ドメインの形式に変換し、次に Transformer などのシーケンス モデルを使用して特徴抽出とモデリングを行い、最後にオーディオ ベクトルが取得されます。テキスト特徴の場合、BERT モデルが特徴抽出に使用されます。最後に、CLIP の自己監視型事前トレーニング フレームワークを使用してこれらの機能をシリアル化し、曲のマルチモーダル表現を取得します。
ユーザーの操作なしで曲をユーザーに配布するにはどうすればよいですか?間接的なモデリング ソリューションを採用します。つまり、曲対ユーザー (I2U) 問題を曲類似曲ユーザー (I2I2U) 問題に変換します。つまり、最初にこのコールド スタート曲に似た曲を見つけ、次にこれらの類似した曲がユーザーと一致する コレクションやその他の比較的強いシグナルなど、いくつかの過去のインタラクション記録があり、ターゲット ユーザーのグループを見つけることができます。このコールド ローンチ ソングは、これらのターゲット ユーザーに配布されます。
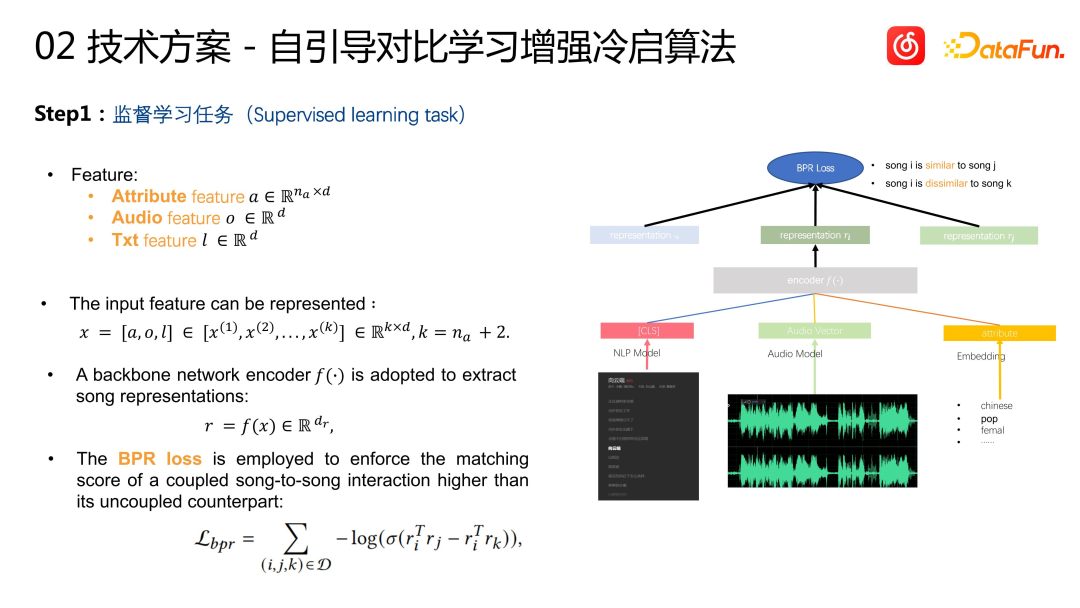
具体的な方法は次の通りで、最初のステップは教師あり学習のタスクです。曲の特徴に関しては、先ほど述べたマルチモーダル情報に加えて、言語、ジャンルなどの曲のタグ情報も含まれており、パーソナライズされたモデリングを実行するのに役立ちます。すべての特徴をまとめてエンコーダに入力し、最終的に歌ベクトルを出力します。各歌ベクトルの類似性はベクトル内積で表すことができます。学習目標は行動に基づいて計算されたI2Iの類似性、つまり協調フィルタリングの類似性であり、協調フィルタリングのデータ、つまりI2Iの推奨事項、ユーザーのフィードバック効果に基づいたテスト後の検証層を追加します学習目標の精度を確保するため、学習の正のサンプルとしてアイテムのペアが使用されます。ネガティブ サンプルは、グローバル ランダム サンプリングを使用して構築されます。損失関数は BPR 損失を使用します。これは、レコメンデーション システムにおける非常に標準的な CB2CF アプローチであり、曲のコンテンツとタグ情報に基づいて、ユーザーの行動特性における曲の類似性を学習します。 #上記の方法に基づいて、2 回目の反復として対照学習を導入しました。対照学習の導入を選択した理由は、この一連のプロセス学習では依然として CF データを使用し、ユーザーの対話動作を通じて学習する必要があるためです。しかし、このような学習方法では、学習項目に「人気のある項目は多く学習し、人気のない項目は学習する」という偏りが生じるという問題が生じる可能性がある。私たちの目標は、曲のマルチモーダルな内容から曲の動作の類似性までを学習することですが、実際のトレーニングでは、人気のあるバイアス問題と不人気なバイアスの問題が依然として存在することがわかります
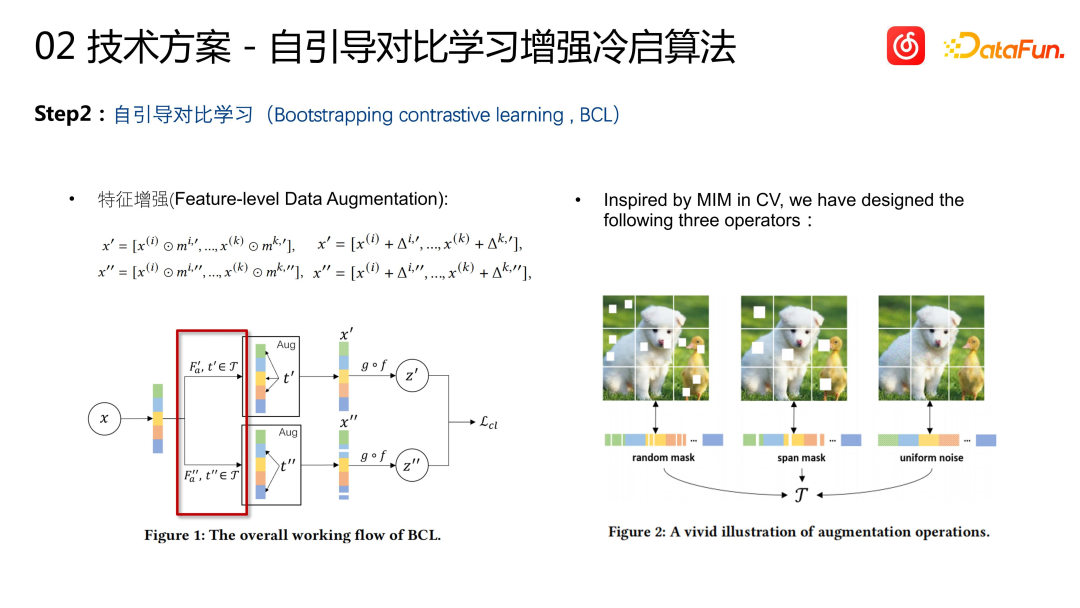
機能強化に基づいて、関連付けグループ化メカニズムも追加しました

オンライン展開と推論プロセス: オフライン トレーニングが完了すると、既存のすべての曲に対してベクトル インデックスが構築されます。新しいコールド スタート プロジェクトの場合、そのベクトルはモデル推論を通じて取得され、最も類似したプロジェクトのいくつかがベクトル インデックスから取得されます。これらのプロジェクトは過去のストック プロジェクトであるため、それらとの一連の履歴インタラクションがあります。ユーザー ( (再生、コレクションなど) コールド スタートを必要とするプロジェクトをこのユーザー グループに配布し、プロジェクトのコールド スタートを完了します
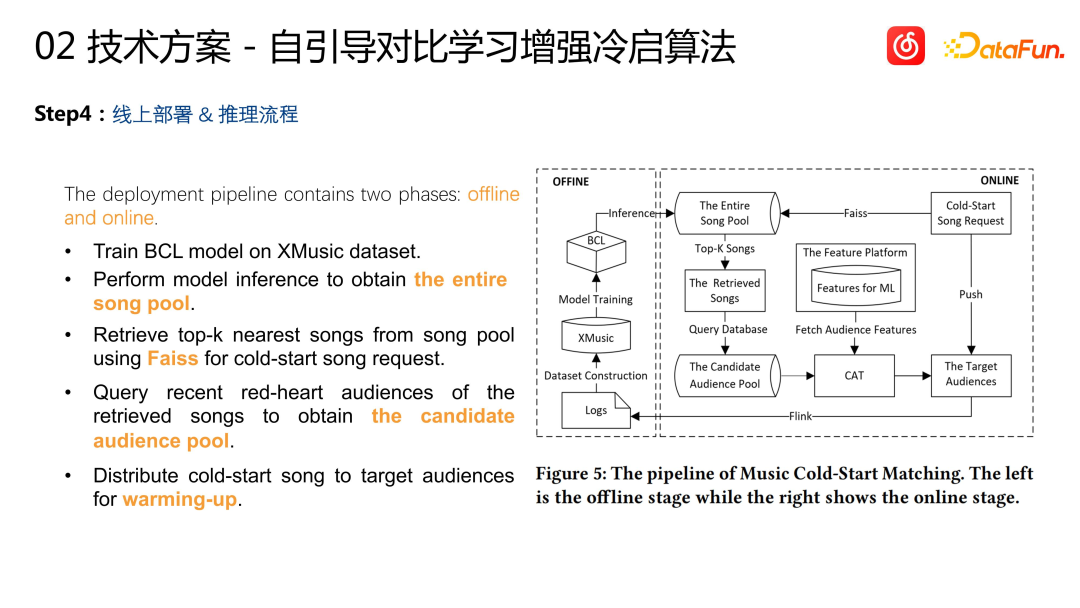
オフラインおよびオフライン指標の評価を含むコールド スタート アルゴリズムを評価し、非常に良好な結果が得られました。上図に示すように、コールド スタート モデルによって計算された楽曲表現は、ジャンルごとに異なる効果をもたらします。 . 曲は優れたクラスタリング効果を実現できます。一部の結果は公開論文で発表されています (Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching)。オンラインでは、コールド スタート アルゴリズムにより、より多くの潜在的な対象ユーザー (38%) を発見すると同時に、コールド スタート項目の収集率 (1.95%) や完了率 (1.42%) などのビジネス指標の改善も達成しました。

さらに考えてみましょう:
- 上記の I2I2U スキームでは、いいえです。ユーザー側の機能が使用されます。
- #アイテムのコールド スタートを支援するユーザー特性を導入するにはどうすればよいですか?
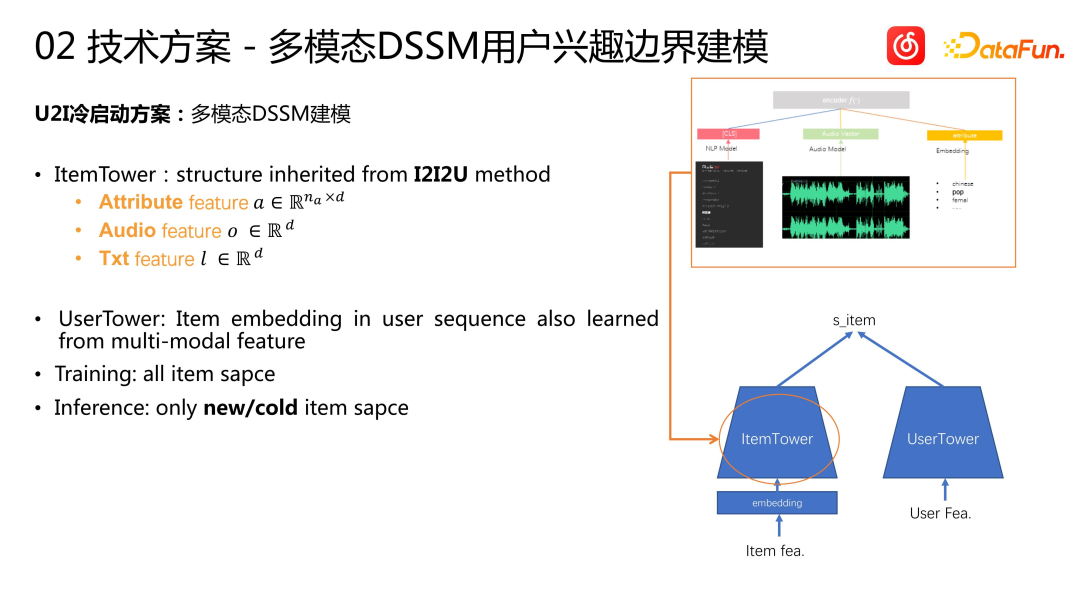
U2I コールド スタート スキームは、マルチモーダル DSSM モデリング アプローチを採用しています。モデルは、ItemTower と UserTower で構成されます。前の曲のマルチモーダル機能をItemTower、User Towerに継承し、通常のUser Towerを作成しました。ユーザーシーケンスのマルチモーダル学習モデリングを行います.モデルトレーニングはフルアイテム空間に基づいて行われます.人気のない曲でも人気のある曲でもサンプルとしてモデルをトレーニングします.推測する場合は、丸が付いている新曲または不人気曲プールについてのみ推測してください。このアプローチは、以前のいくつかの 2 タワー ソリューションに似ています。人気のあるアイテムの場合は 1 つのタワーを構築し、新しいアイテムまたは不人気なアイテムの場合は、それらを処理するために別のタワーを構築します。ただし、レギュラー品とコールドスタート品はより独立して取り扱っております。通常のアイテムには通常のリコール モデルを使用し、不人気なアイテムには特別に構築された DSSM モデルを使用します
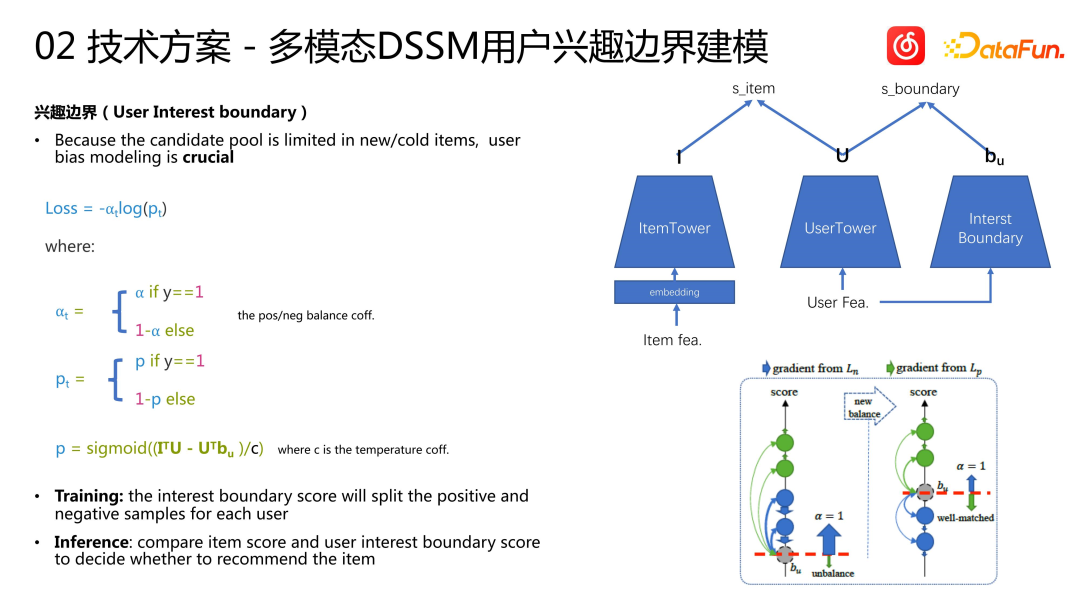
#コールドスタート DSSM のためこのモデルは、人気のない曲や新しい曲について推論するためにのみ使用されますが、すべてのユーザーが人気のないアイテムや新しいアイテムを好むとは限らないため、ユーザーのバイアスをモデル化することが非常に重要であることがわかりました。候補セット自体は非常に大きなプールであり、ユーザーのアイテムをモデル化する必要があります。これは、ユーザーによっては人気のあるアイテムを好む場合があり、そのお気に入りのアイテムが推奨プールから欠落している可能性があるためです。したがって、従来の手法に基づいて、ユーザーの好みをモデル化する「関心境界」と呼ばれるタワーを構築します。関心境界は、正のサンプルと負のサンプルを分離するために使用されます。トレーニング中に、関心境界スコアは、各ユーザーの正のサンプルと負のサンプルを分割するために使用されます。推論中に、アイテム スコアとユーザーの関心境界スコアが比較され、アイテム スコアとユーザーの関心境界スコアが比較されます。アイテムを勧めます。トレーニング中に、関心境界ベクトルとユーザー関心ベクトルを使用して内積計算を実行し、境界表現ベクトルを取得します。上図の損失に基づいて、従来の 2 クラスのクロス エントロピーがモデリングに使用されます。負のサンプルはユーザーの関心の境界を上げ、正のサンプルはユーザーの関心の境界を下げます。最終的にはトレーニング後に平衡状態に達し、ユーザーの関心の境界は正のサンプルと負のサンプルを分離します。オンラインで適用される場合、ユーザーの興味の範囲に基づいて、人気のないアイテムやロングテールのアイテムをユーザーに推奨するかどうかを決定します。
3. まとめ

最後にまとめを行います。 Cloud Music が推奨するマルチモーダル コールド スタート モデリングの主な作業には次のものが含まれます。
- 機能の面では、CLIP 事前トレーニング フレームワークを使用してマルチモーダル コールド スタート モデリングが推奨されます。 -モダリティ。
- モデリング スキームでは、I2I2U 間接モデリングとコールド スタート マルチモーダル DSSM 直接モデリングの 2 つのモデリング スキームが使用されます。
- #損失と学習の目標に関しては、BPR と対比学習がアイテム側に導入され、ユーザー側の興味境界線が不人気なアイテムの学習と学習を強化します。ユーザーの学習。
# A1: 多くの指標に注目しますが、中でも重要となるのが回収率と完了率です 回収率=回収PV/再生PV、完了率=完全再生率PV /PVを再生します。 A2: 現在のソリューションは、CLIP フレームワークに基づいて事前トレーニングし、事前トレーニングから得られたマルチモーダル機能を使用して、下流のリコールおよび並べ替えサービスをサポートすることです。事前トレーニング プロセスは、エンドツーエンドのトレーニングではなく 2 段階で実行されます。理論的にはエンドツーエンドのトレーニングの方が優れているかもしれませんが、より高いマシン要件とコストも必要になります。 xx は、曲のオーディオ、テキスト マルチモーダル機能、および曲の元の機能を表します。言語ジャンルやその他のラベル機能。これらの特徴はグループ化され、2 つの異なるランダム変換 F'a と F''a が適用されて、x' と x'' が取得されます。 f はエンコーダであり、モデルのバックボーン構造でもあります。g はエンコーダ出力の後のヘッダーに追加され、対照学習部分にのみ使用されます A3: モデルには常に 1 つのタワーであるエンコーダーが 1 つだけあるため、パラメーターの共有の問題はありません。 理由について不人気なアイテム 役に立ちました。このように理解しました。不人気なアイテムに対して追加のネガティブ サンプリングやその他の作業を実行する必要はありません。実際、教師あり学習に基づいて楽曲の埋め込み表現を学習するだけではバイアスが生じる可能性があります。学習されたデータは協調フィルタリングであるため、人気のある曲が優先されるという問題が発生し、最終的な埋め込みベクトルも偏ることになります。対比学習メカニズムと最終損失関数での対比学習の損失を導入することにより、協調フィルタリング データの学習の偏りを修正できます。したがって、対照学習を通じて、不人気項目の追加処理を必要とせずに、空間内のベクトルの分布を改善できます。 A4: マルチモーダル DSSM モデリングには、ItemTower と UserTower が含まれており、UserTower に基づいて、関心境界タワーと呼ばれる、ユーザー特性に応じた追加のタワーをモデル化します。これら 3 つのタワーはそれぞれベクトルを出力します。トレーニング中に、アイテム ベクトルとユーザー ベクトルの内積を実行してアイテム スコアを取得し、次にユーザー ベクトルとユーザーの興味境界ベクトルの内積を実行してユーザーの興味境界スコアを表します。パラメータ ⍺ は、損失に寄与する正のサンプルと負のサンプルの割合のバランスを取るために使用される従来のサンプル重み付けパラメータです。 p はアイテムの最終スコアで、アイテム ベクトルとユーザー ベクトルの内積スコアからユーザー ベクトルとユーザー興味境界ベクトルの内積スコアを減算し、シグモイド関数によって最終スコアを計算します。計算プロセス中、肯定的なサンプルはアイテムとユーザーの内積スコアを増加させ、ユーザーとユーザーの興味の境界の内積スコアを減少させますが、否定的なサンプルはその逆を行います。理想的には、ユーザーの内積スコアとユーザーの関心の境界により、肯定的なサンプルと否定的なサンプルを区別できます。オンラインでの推奨段階では、興味の境界を基準値として使用し、スコアの高いアイテムをユーザーに推奨し、スコアの低いアイテムは推奨しません。ユーザーが人気のあるアイテムのみに興味がある場合、理想的にはユーザーの境界スコア、つまりユーザー ベクトルと興味境界ベクトルの内積は非常に高く、すべてのコールドスタート アイテム スコアよりもさらに高くなります。 、一部のコールド スタート項目はユーザーに推奨されません A5: 2 つの入力は確かに同じで、構造も似ていますが、パラメーターは共有されていません。最大の違いは損失関数の計算のみです。ユーザータワーの出力とアイテムタワーの出力の内積を計算し、アイテムスコアを求める。関心境界タワーの出力とユーザータワーの出力の内積が計算され、その結果が境界スコアとなります。トレーニング中に、この 2 つは減算され、バイナリ損失関数の計算に参加します。推論中に、2 つのサイズが比較されて、ユーザーにアイテムを推奨するかどうかが決定されます。4. 質疑応答セッション
Q1: 音楽のコールド スタートの中心的な指標は何ですか?
Q2: マルチモーダル機能はエンドツーエンドでトレーニングされていますか、それとも事前トレーニングされていますか? 2 番目のステップで比較ビューを生成するとき、入力 x の具体的な特性は何ですか?
Q3: 2 つのグループ対照学習トレーニング中の拡張機能の強化 タワーの埋め込み層と DNN は共有されていますか?対照学習がコンテンツのコールド スタートに効果的であるのはなぜですか? それは特に非コールド スタート コンテンツに対するネガティブ サンプリングですか?
Q4: 関心のある境界には多目的モデリングがありますか?あまり多くないようですが、⍺ と p という 2 つの量を紹介してもらえますか?
Q5: ユーザー タワー (userTower) と関心境界タワーの構造的な違いは何ですか?同じです?
以上がNetEase Cloud Musicコールドスタート技術の推奨システムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7492
7492
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 Go 言語と Redis を使用してレコメンデーション システムを実装する方法
Oct 27, 2023 pm 12:54 PM
Go 言語と Redis を使用してレコメンデーション システムを実装する方法
Oct 27, 2023 pm 12:54 PM
Go 言語と Redis を使用してレコメンデーション システムを実装する方法レコメンデーション システムは、最新のインターネット プラットフォームの重要な部分であり、ユーザーが興味のある情報を発見して入手するのに役立ちます。 Go 言語と Redis は、レコメンデーション システムの実装プロセスで重要な役割を果たす 2 つの非常に人気のあるツールです。この記事では、Go 言語と Redis を使用して簡単なレコメンデーション システムを実装する方法と、具体的なコード例を紹介します。 Redis は、キーと値のペアのストレージ インターフェイスを提供し、さまざまなデータをサポートするオープンソースのインメモリ データベースです。
 Javaで実装されたレコメンデーションシステムのアルゴリズムとアプリケーション
Jun 19, 2023 am 09:06 AM
Javaで実装されたレコメンデーションシステムのアルゴリズムとアプリケーション
Jun 19, 2023 am 09:06 AM
インターネット技術の継続的な発展と普及に伴い、重要な情報フィルタリング技術としてレコメンドシステムがますます広く利用され、注目されています。レコメンデーション システム アルゴリズムの実装に関しては、高速で信頼性の高いプログラミング言語として Java が広く使用されています。この記事では、Java で実装されたレコメンデーション システム アルゴリズムとアプリケーションを紹介し、ユーザー ベースの協調フィルタリング アルゴリズム、アイテム ベースの協調フィルタリング アルゴリズム、およびコンテンツ ベースのレコメンデーション アルゴリズムという 3 つの一般的なレコメンデーション システム アルゴリズムに焦点を当てます。ユーザーベースの協調フィルタリングアルゴリズムは、ユーザーベースの協調フィルタリングに基づいています
 応用例:go-microを利用したマイクロサービスレコメンドシステムの構築
Jun 18, 2023 pm 12:43 PM
応用例:go-microを利用したマイクロサービスレコメンドシステムの構築
Jun 18, 2023 pm 12:43 PM
インターネット アプリケーションの人気に伴い、マイクロサービス アーキテクチャが一般的なアーキテクチャ手法になりました。その中でも、マイクロサービス アーキテクチャの鍵となるのは、アプリケーションを異なるサービスに分割し、RPC で通信することで疎結合なサービス アーキテクチャを実現することです。この記事では、実際の事例をもとに、go-microを使ってマイクロサービスレコメンドシステムを構築する方法を紹介します。 1. マイクロサービス レコメンデーション システムとは何ですか? マイクロサービス レコメンデーション システムは、マイクロサービス アーキテクチャに基づいたレコメンデーション システムであり、レコメンデーション システム内のさまざまなモジュール (特徴量エンジニアリング、分類など) を統合します。
 正確なレコメンデーションの秘密: アリババの分離ドメイン適応不偏リコール モデルの詳細な説明
Jun 05, 2023 am 08:55 AM
正確なレコメンデーションの秘密: アリババの分離ドメイン適応不偏リコール モデルの詳細な説明
Jun 05, 2023 am 08:55 AM
1. シナリオの紹介 まず、今回のシナリオである「良い商品が手に入る」シナリオを紹介します。その場所はタオバオのホームページ上の 4 つの正方形のグリッド内にあり、1 ホップの選択ページと 2 ホップの承認ページに分かれています。受付ページには主に 2 つの形式があり、1 つは画像とテキストの受付ページ、もう 1 つは短いビデオの受付ページです。このシナリオの主な目標は、ユーザーに満足のいく商品を提供し、GMV の成長を促進し、それによって専門家の供給をさらに活用することです。 2. 人気バイアスとは何ですか。なぜ次に、この記事の焦点である人気バイアスについて説明します。人気バイアスとは何ですか?人気の偏りはなぜ起こるのでしょうか? 1. 人気バイアスとは 人気バイアスには、マシュー効果や情報コクーンルームなどの別名があり、直感的に言えば爆発性の高い製品のカーニバルであり、人気のある製品ほど露出されやすくなります。この結果、
 Go 言語はクラウド検索と推奨システムをどのように実装しますか?
May 16, 2023 pm 11:21 PM
Go 言語はクラウド検索と推奨システムをどのように実装しますか?
May 16, 2023 pm 11:21 PM
クラウド コンピューティング技術の継続的な開発と普及に伴い、クラウド検索および推奨システムの人気が高まっています。この需要に応えて、Go 言語も優れたソリューションを提供します。 Go 言語では、高速な同時処理機能と豊富な標準ライブラリを使用して、効率的なクラウド検索およびレコメンデーション システムを実装できます。以下では、Go 言語がこのようなシステムをどのように実装しているかを紹介します。 1. クラウド上の検索 まず、検索の姿勢と原則を理解する必要があります。検索姿勢とは、ユーザーが入力したキーワードに基づいてページを検索エンジンが照合することを指します。
 NetEase Cloud Musicコールドスタート技術の推奨システム
Nov 14, 2023 am 08:14 AM
NetEase Cloud Musicコールドスタート技術の推奨システム
Nov 14, 2023 am 08:14 AM
1. 問題の背景: コールド スタート モデリングの必要性と重要性 コンテンツ プラットフォームとして、Cloud Music には毎日大量の新しいコンテンツがオンラインにあります。クラウド音楽プラットフォーム上の新しいコンテンツの量は、ショートビデオなどの他のプラットフォームに比べて比較的少ないですが、実際の量は皆の想像をはるかに超えている可能性があります。同時に、音楽コンテンツは、短いビデオ、ニュース、製品の推奨とは大きく異なります。音楽のライフサイクルは非常に長期間に及び、多くの場合、数年単位で測定されます。曲によっては数か月、数年眠っていた後に爆発することもありますし、名曲は10年以上経ってもなお強い生命力を持っていることもあります。したがって、音楽プラットフォームのレコメンドシステムでは、他のカテゴリをレコメンドすることよりも、人気のないロングテールの高品質コンテンツを発見し、適切なユーザーにレコメンドすることが重要です。
 Ant Marketing の推奨シナリオにおける因果関係修正手法の適用
Jan 13, 2024 pm 12:15 PM
Ant Marketing の推奨シナリオにおける因果関係修正手法の適用
Jan 13, 2024 pm 12:15 PM
1. 因果関係修正の背景 1. レコメンデーションシステムにズレが生じる レコメンドモデルは、データを収集して学習し、ユーザーに適切なアイテムをレコメンドします。ユーザーが推奨アイテムを操作すると、収集されたデータはモデルをさらにトレーニングするために使用され、閉ループが形成されます。ただし、この閉ループにはさまざまな影響要因が存在し、エラーが発生する可能性があります。エラーの主な理由は、モデルのトレーニングに使用されるデータのほとんどが理想的なトレーニング データではなく観測データであり、露出戦略やユーザーの選択などの要因の影響を受けることです。このバイアスの本質は、経験的なリスク推定値の期待値と真の理想的なリスク推定値の期待値の違いにあります。 2. 一般的なバイアス レコメンデーション マーケティング システムにおける一般的なバイアスには、主に 3 つのタイプがあります: 選択的バイアス: ユーザーのルートに起因します。
 PHPによるレコメンデーションシステムと協調フィルタリング技術
May 11, 2023 pm 12:21 PM
PHPによるレコメンデーションシステムと協調フィルタリング技術
May 11, 2023 pm 12:21 PM
インターネットの急速な発展に伴い、推奨システムはますます重要になってきています。レコメンデーション システムは、ユーザーが興味のあるアイテムを予測するために使用されるアルゴリズムです。インターネット アプリケーションでは、推奨システムがパーソナライズされた提案や推奨を提供できるため、ユーザーの満足度とコンバージョン率が向上します。 PHP は、Web 開発で広く使用されているプログラミング言語です。この記事では、PHP のレコメンデーション システムと協調フィルタリング テクノロジについて説明します。レコメンデーション システムの原理 レコメンデーション システムは、機械学習アルゴリズムとデータ分析に依存しており、ユーザーの過去の行動を分析および予測します。
