

NeRFと自動運転の過去と現在、10本近くの論文をまとめました!

Neural Radiance Fields が 2020 年に提案されて以来、関連論文の数は飛躍的に増加し、3 次元再構築の重要な方向性となっただけでなく、重要なツールとして研究の最前線でも徐々に活発になってきました。自動運転に向けて。
NeRF は、過去 2 年間で突然登場しました。その主な理由は、特徴点の抽出とマッチング、エピポーラ幾何学と三角形分割、PnP とバンドル調整、および従来の CV 再構成パイプラインのその他のステップを省略し、さらにメッシュ、テクスチャ、およびレイ トレーシングの再構成により、2D 入力イメージから放射線フィールドを直接学習し、実際の写真に近い放射線フィールドからレンダリングされたイメージを出力します。言い換えれば、ニューラル ネットワークに基づく暗黙的な 3D モデルを指定された視点から 2D 画像に適合させ、新しい視点の合成と機能の両方を持たせます。 NeRF の開発は自動運転にも密接に関連しており、特に実際のシーンの再構築と自動運転シミュレーターのアプリケーションに反映されています。 NeRF は写真レベルの画像のレンダリングに優れているため、NeRF でモデル化された街路シーンは自動運転用の非常に現実的なトレーニング データを提供できます。NeRF マップを編集して、建物、車両、歩行者を現実ではキャプチャするのが難しいさまざまなコーナーに結合することができます。このケースは、知覚、計画、障害物回避などのアルゴリズムのパフォーマンスをテストするために使用できます。したがって、NeRF は 3D 再構築の一分野であり、モデリング ツールであり、NeRF を使いこなすことは、再構築や自動運転を行う研究者にとって必須のスキルとなっています。
今日は、Nerf と自動運転に関するコンテンツを整理します。ほぼ 11 の記事で、Nerf と自動運転の過去と現在を探索できます。
1. Nerf の始まり 書き換えられた内容は次のとおりです: NeRF: ビュー合成のためのシーンの神経放射フィールド表現。 ECCV2020
の最初の記事では、疎な入力ビュー セットを使用して基礎となる連続ボリューム シーン関数を最適化し、複雑なシーンを合成するための最新のビュー結果を実現する Nerf メソッドが提案されています。このアルゴリズムは、完全に接続された (非畳み込みの) ディープ ネットワークを使用してシーンを表現します。入力は単一の連続 5D 座標 (空間位置 (x、y、z) と視線方向 (θ、ξ) を含む) であり、出力はは、体積密度とビュー関連放出放射の空間位置です。NERF は、2D ポーズ画像を監視として使用します。画像を畳み込む必要はありません。代わりに、位置エンコーディングを継続的に学習することで、一連の隠された画像を学習します。複雑な 3 次元シーンを表現する式パラメータとして画像の色を使用します。暗黙的表現により、あらゆる視点からのレンダリングを完了できます。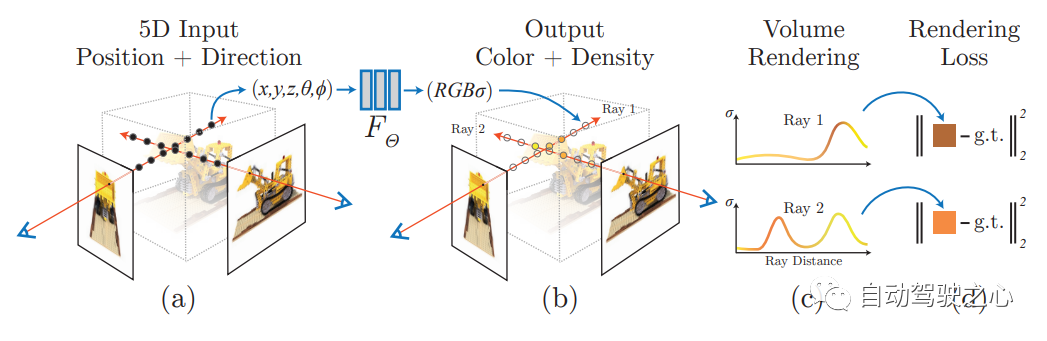 2.Mip-NeRF 360
2.Mip-NeRF 360
CVPR2020の研究内容は、アウトドアのボーダレスシーンに関するものです。その中で、Mip-NeRF 360: Boundless anti-aliasing neural radio field は研究方向の 1 つです。
論文リンク: https://arxiv.org/pdf/2111.12077.pdf Neural Radiative Fields (NeRF) は、オブジェクトと空間の小さな境界領域で優れたビュー合成結果を実証していますが、カメラが任意の方向を向いていて、コンテンツが任意の距離に存在する可能性がある「境界のない」シーンで実装するのは困難です。この場合、既存の NeRF のようなモデルは、不鮮明なレンダリングや低解像度のレンダリングを生成することが多く (近くのオブジェクトと遠くのオブジェクトの詳細とスケールが不均衡なため)、トレーニングに時間がかかり、一連の小さな画像からの再構成が不十分になる可能性があります。大規模なシーンでは、タスクに固有のあいまいさが原因で発生します。この論文では、サンプリングとエイリアシングの問題を解決する NeRF のバリアントである mip-NeRF の拡張を提案し、非線形シーン パラメータ化、オンライン蒸留、および無制限のシーンによってもたらされる問題を克服するための新しい歪みベースの正則化を使用します。 mip-NeRF と比較して平均二乗誤差の 57% 削減を達成し、非常に複雑で境界のない現実世界のシーンに対してリアルな合成ビューと詳細な深度マップを生成できます。
#3.Instant-NGP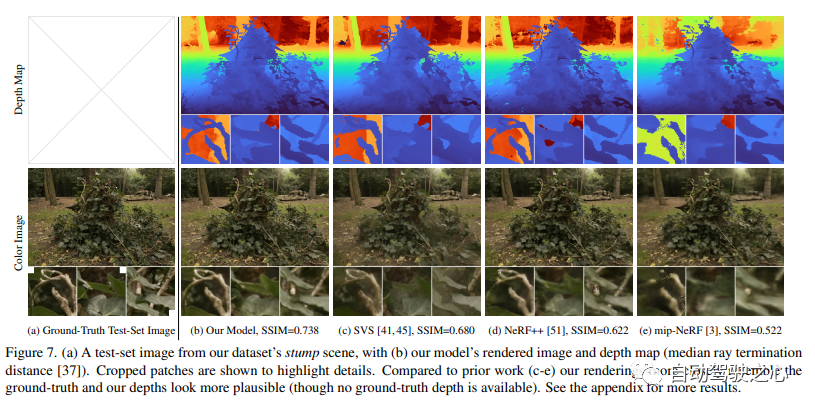
#書き換える必要がある内容は次のとおりです。ボクセルと暗黙的な特徴の混合シーン表現を表示 (SIGGRAPH 2022)>>マルチ解像度ハッシュでエンコードされたリアルタイム ニューログラフィック プリミティブ
書き換える必要がある内容は次のとおりです: リンク: https : //nvlabs.github.io/instant-ngp
まず、Instant-NGP と NeRF の類似点と相違点を見てみましょう:
- これもボリューム レンダリングに基づいています
- NeRF の MLP とは異なり、NGP はシーン表現としてスパース パラメーター化されたボクセル グリッドを使用します;
- 勾配に基づいて、シーンと MLP を最適化します。同時に (MLP の 1 つがデコーダとして使用されます)。
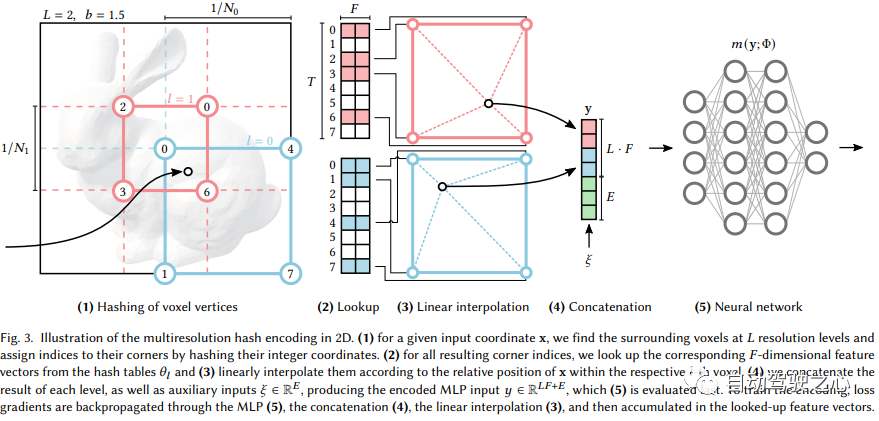
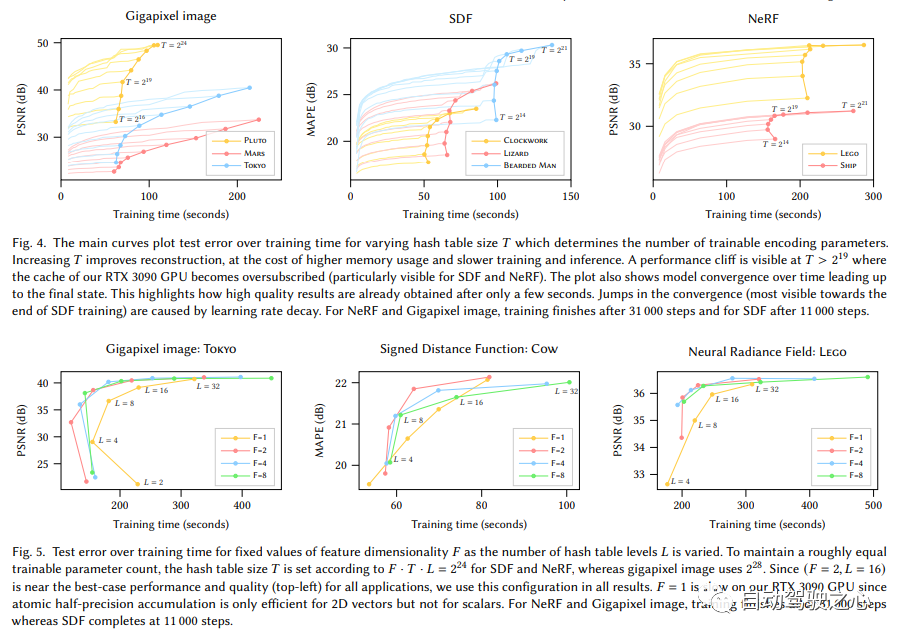
大きなフレームワークは同じであることがわかりますが、最も重要な違いは、NGP がパラメータ化されたボクセル グリッドをシーン表現として選択していることです。学習により、ボクセルに保存されたパラメータがシーン密度の形状になります。 MLP の最大の問題は遅いことです。シーンを高品質に再構成するには、比較的大規模なネットワークが必要になることが多く、サンプリング ポイントごとにネットワークを通過するのに多くの時間がかかります。グリッド内の補間ははるかに高速です。ただし、グリッドで高精度のシーンを表現したい場合は、高密度のボクセルが必要となり、メモリ使用量が非常に多くなります。シーン内には空白の場所が多くあることを考慮して、NVIDIA はシーンを表現するためのスパース構造を提案しました。
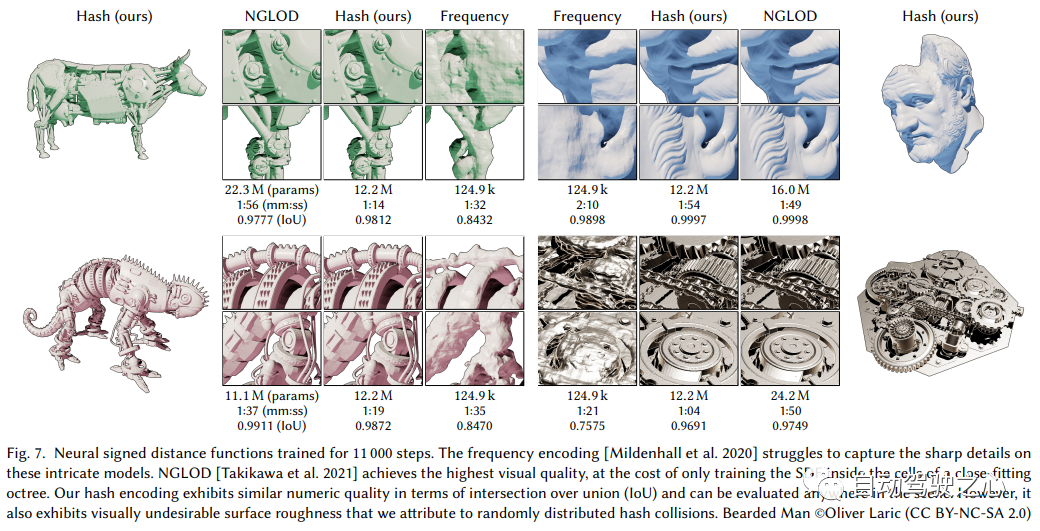

4. F2-NeRF
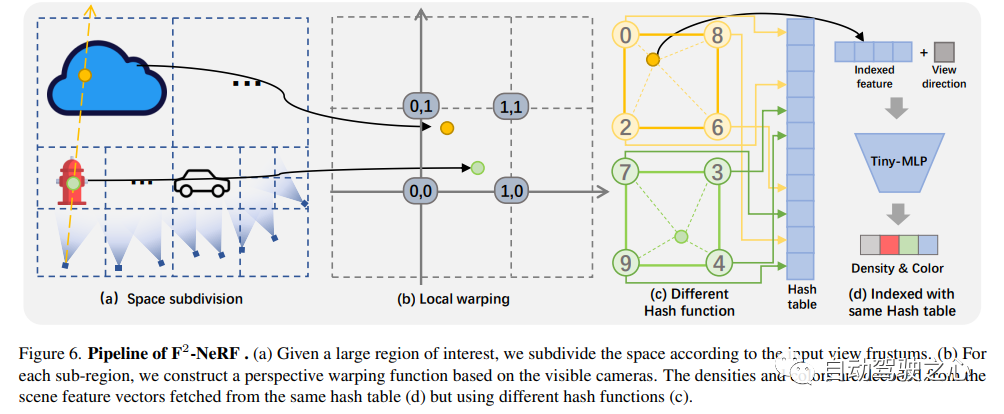
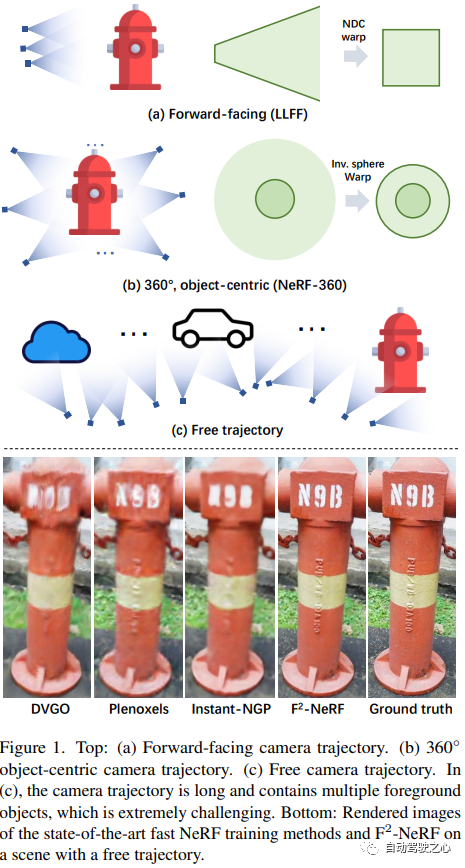
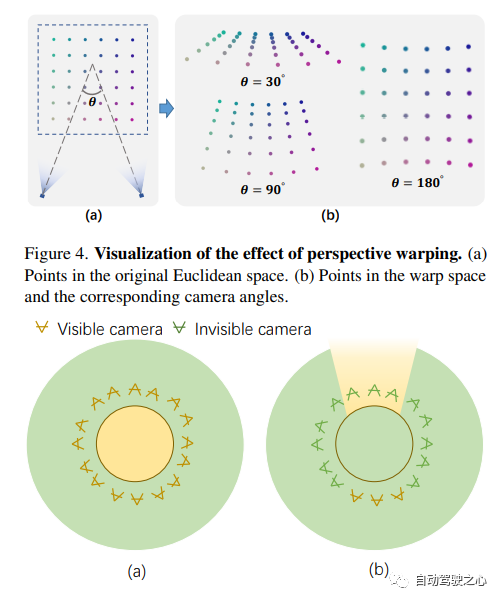
F2-NeRF: フリー カメラ軌跡を使用した高速ニューラル ラディアンス フィールド トレーニングペーパーリンク: https://totoro97.github.io/projects/f2-nerf/新しいビュー合成のために、F2-NeRF (Fast Free NeRF) と呼ばれる新しいグリッドベースの NeRF を提案しました。これは、任意の入力カメラ軌道を実現でき、トレーニング時間は数分しかかかりません。 Instant NGP、Plenoxels、DVGO、TensoRF などの既存の高速グリッドベースの NeRF トレーニング フレームワークは、主に境界のあるシーン向けに設計されており、境界のないシーンを処理するために空間ワーッピングに依存しています。広く使用されている 2 つの既存の空間ワーッピング手法は、前方を向いた軌道または 360° オブジェクト中心の軌道のみをターゲットにしており、任意の軌道を処理することはできません。この記事では、境界のないシーンを処理するための空間ワーピングのメカニズムを詳しく調査します。さらに、パースペクティブ ワーッピングと呼ばれる新しい空間ワーッピング手法を提案します。これにより、グリッド ベースの NeRF フレームワークで任意の軌道を処理できるようになります。広範な実験により、F2-NeRF が、収集された 2 つの標準データセットと新しい自由軌道データセットに対して同じパースペクティブ ワーピングを使用して高品質の画像をレンダリングできることが示されました。
リアルタイムレンダリング モバイル アプリケーションにはメッシュをエクスポートする Nerf の機能が実装されており、この技術は CVPR2023 カンファレンスで採用されました。
MobileNeRF: モバイル アーキテクチャでの効率的なニューラル フィールド レンダリングのためのポリゴン ラスター化パイプラインの活用。
書き換える必要がある内容は次のとおりです: https://arxiv.org/pdf/2208.00277.pdf
Neural Radiation Fields (NeRF) は、新しいビューから 3D シーン画像を合成する驚くべき能力を実証しました。ただし、これらは、広く導入されているグラフィックス ハードウェアの機能と一致しない、レイ マーチングに基づく特殊なボリューム レンダリング アルゴリズムに依存しています。このペーパーでは、標準のレンダリング パイプラインを通じて新しい画像を効率的に合成できる、新しいテクスチャ ポリゴン ベースの NeRF 表現を紹介します。 NeRF は、テクスチャがバイナリの不透明度と特徴ベクトルを表すポリゴンのセットとして表されます。 Z バッファを使用した従来のポリゴンのレンダリングでは、各ピクセルが最終的なピクセル カラーを生成するためにフラグメント シェーダ内で実行される小さなビュー依存 MLP によって解釈される特性を持つイメージが生成されます。このアプローチにより、NeRF は、大規模なピクセル レベルの並列処理を提供する従来のポリゴン ラスタライゼーション パイプラインを使用してレンダリングできるようになり、携帯電話を含むさまざまなコンピューティング プラットフォーム全体でインタラクティブなフレーム レートが可能になります。
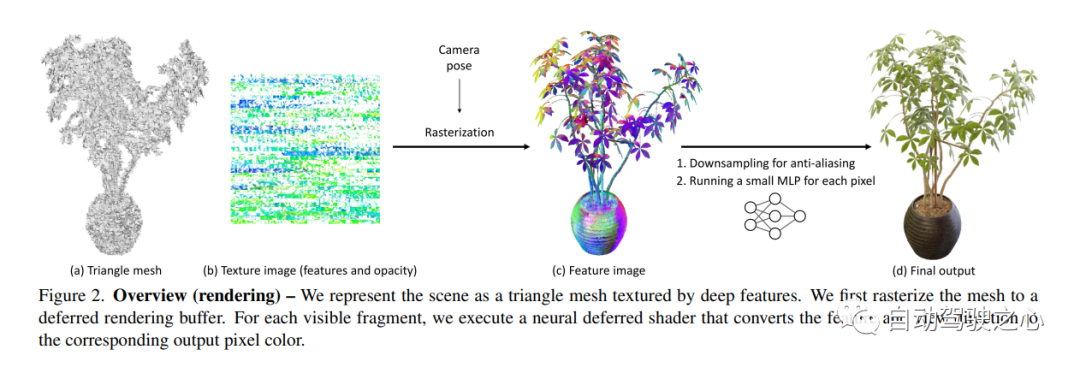
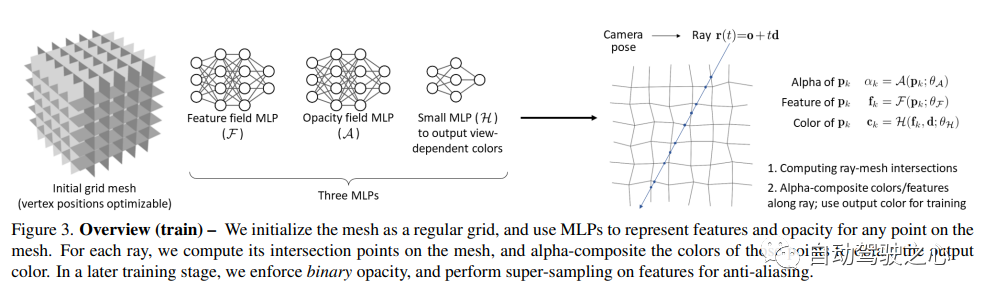

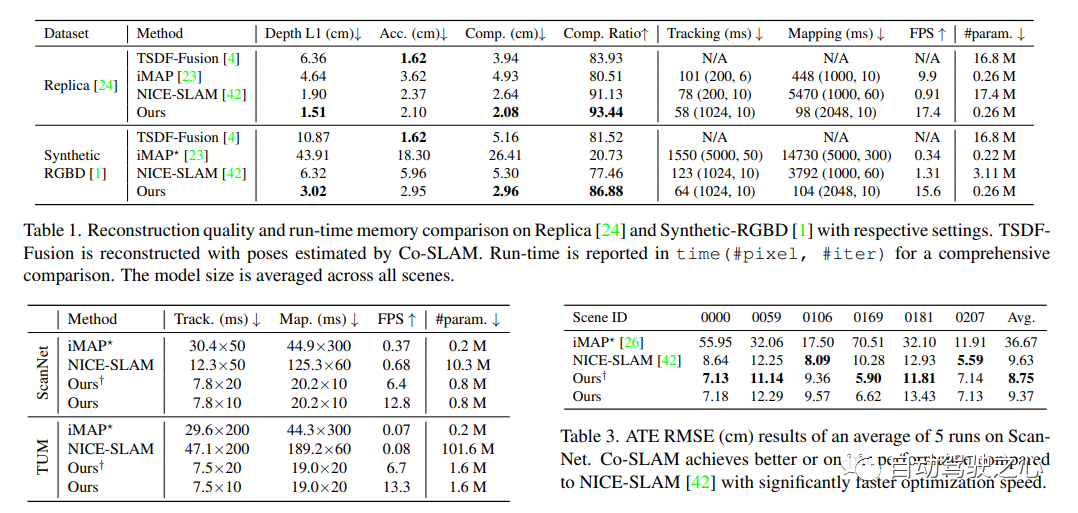
6.Co-SLAM
当社のリアルタイム ビジュアル ローカリゼーションと NeRF マッピングの作業は CVPR2023
に含まれていますCo-SLAM: ニューラル リアルタイム SLAM のためのジョイント座標エンコーディングとスパース パラメトリック エンコーディング:
論文リンク: https://arxiv.org/pdf/2304.14377.pdf
Co-SLAM は、本物の-time カメラ追跡と高忠実度の表面再構築にニューラル暗黙的表現を使用する RGB-D SLAM システム。 Co-SLAM は、シーンを多重解像度のハッシュ グリッドとして表現し、局所的な特徴を迅速に収束して表現する機能を活用します。さらに、表面一貫性事前分布を組み込むために、Co-SLAM はブロック符号化方式を使用します。これは、観察されていない領域でシーンの完成を強力に完了できることを証明しています。私たちの共同エンコーディングは、Co-SLAM の速度、高忠実度の再構成、表面一貫性事前分布の利点を組み合わせたもので、レイ サンプリング戦略を通じて、Co-SLAM はすべてのキーフレームに対する調整をグローバルにバンドルすることができます。
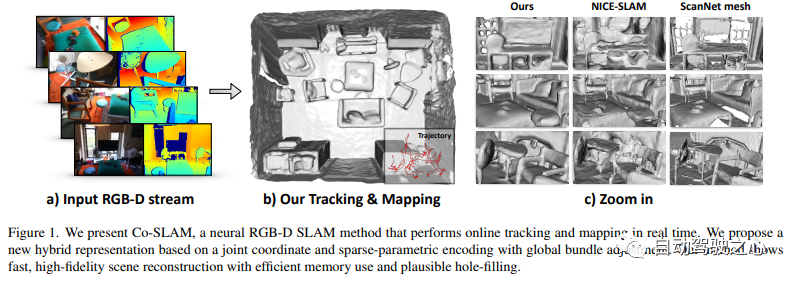
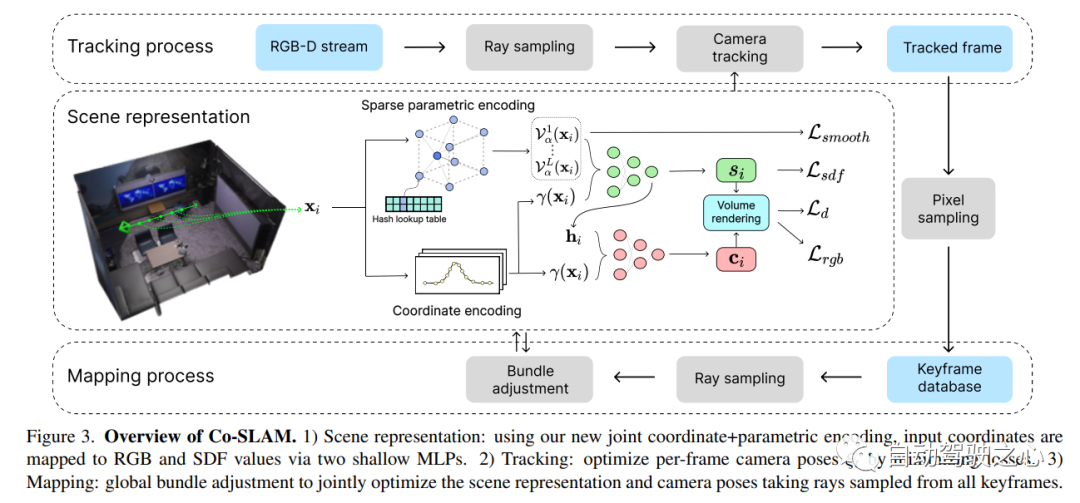

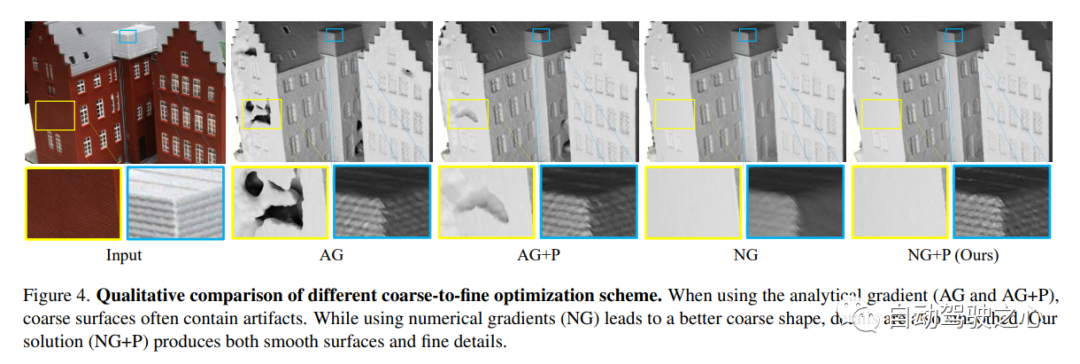
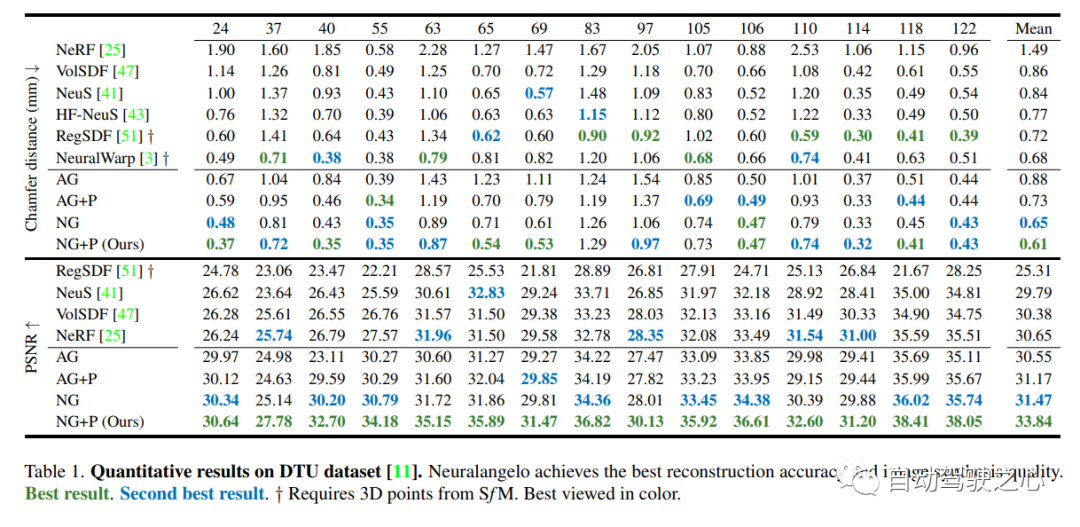
7.Neuralangelo
現時点で最も優れた NeRF 表面再構成法 (CVPR2023)


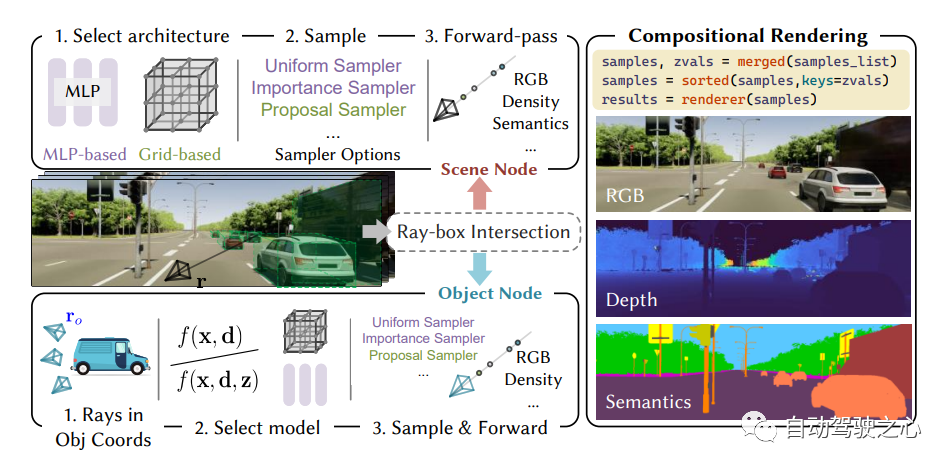
初のオープンソース自動運転 NeRF シミュレーション ツール。
書き直す必要があるのは: https://arxiv.org/pdf/2307.15058.pdf
自動運転車は通常の条件下でスムーズに走行できます。シミュレーションは、残りのコーナー状況を解決する上で重要な役割を果たします。この目的を達成するために、MARS は神経放射場に基づいた自動運転シミュレーターを提案しています。既存の作品と比較して、MARS には次の 3 つの特徴があります。 (1) インスタンスの認識。シミュレーターは、インスタンスの静的特性 (サイズや外観など) と動的特性 (軌道など) を個別に制御できるように、別個のネットワークを使用して前景インスタンスと背景環境を個別にモデル化します。 (2) モジュール性。シミュレータを使用すると、さまざまな最新の NeRF 関連バックボーン、サンプリング戦略、入力モードなどを柔軟に切り替えることができます。このモジュール設計により、NeRF ベースの自動運転シミュレーションの学術的進歩と産業展開が促進されることが期待されています。 (3) 本物。シミュレータは、最適なモジュールを選択して最先端のフォトリアリスティックな結果が得られるようにセットアップされています。
最も重要な点は、オープンソースであることです。
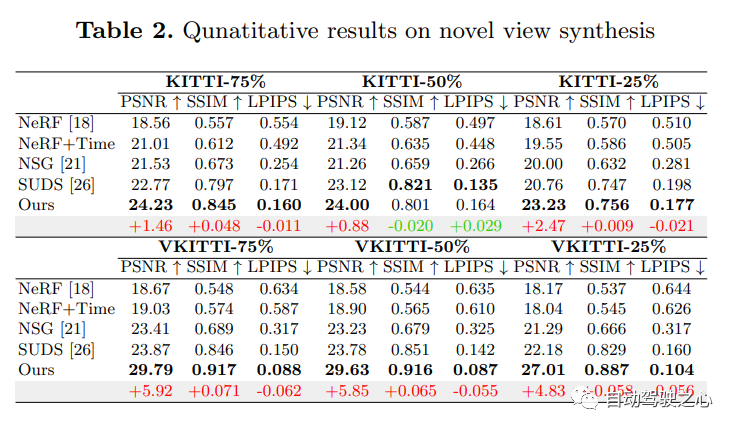
9.UniOcc
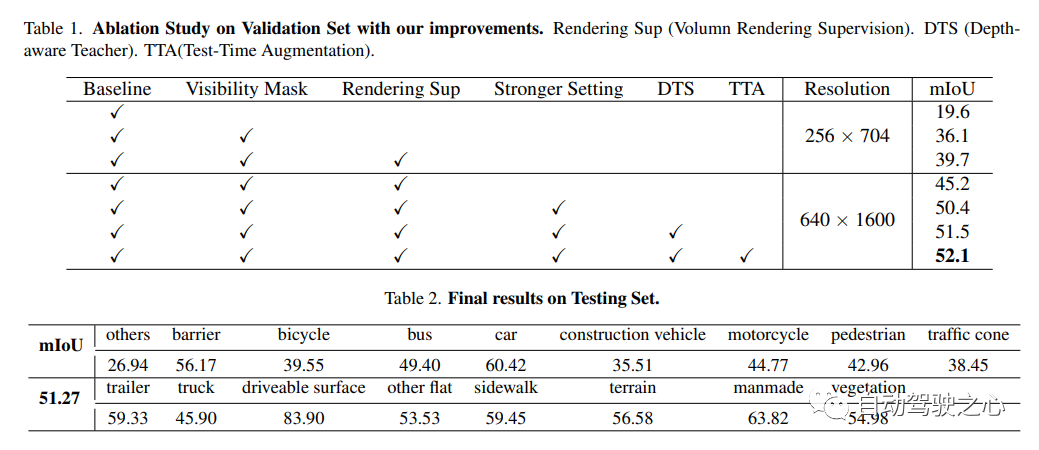
書き換えが必要な内容については、「NeRF と 3D」ネットワークを占拠する、AD2023 チャレンジ「UniOcc: 幾何学的およびセマンティック レンダリングによるビジョン中心の 3D 占有予測の統合。論文リンク: https://arxiv.org/abs/2306.09117 UniOCC は、視覚中心の 3D 占有予測方法です。従来の占有予測方法は、主に 3D 占有ラベルを使用して 3D 空間の投影機能を最適化します。しかし、これらのラベルの生成プロセスは複雑で高価で、3D セマンティック アノテーションに依存し、ボクセル解像度によって制限され、きめ細かい空間を提供できません。 . セマンティクス。この問題に対処するために、この論文では、空間幾何学的制約を明示的に課し、ボリューム レイ レンダリングを通じてきめ細かいセマンティック監視を補足する、新しい統合占有 (UniOcc) 予測方法を提案します。このアプローチにより、モデルのパフォーマンスが大幅に向上し、手動によるアノテーションのコストが削減される可能性が実証されます。 3D 占有率のラベル付けの複雑さを考慮して、ラベルなしのデータを利用して予測精度を向上させるために、深度センシング教師生徒 (DTS) フレームワークをさらに導入します。当社のソリューションは、単一モデルの公式ランキングで 51.27% の mIoU スコアを達成し、この課題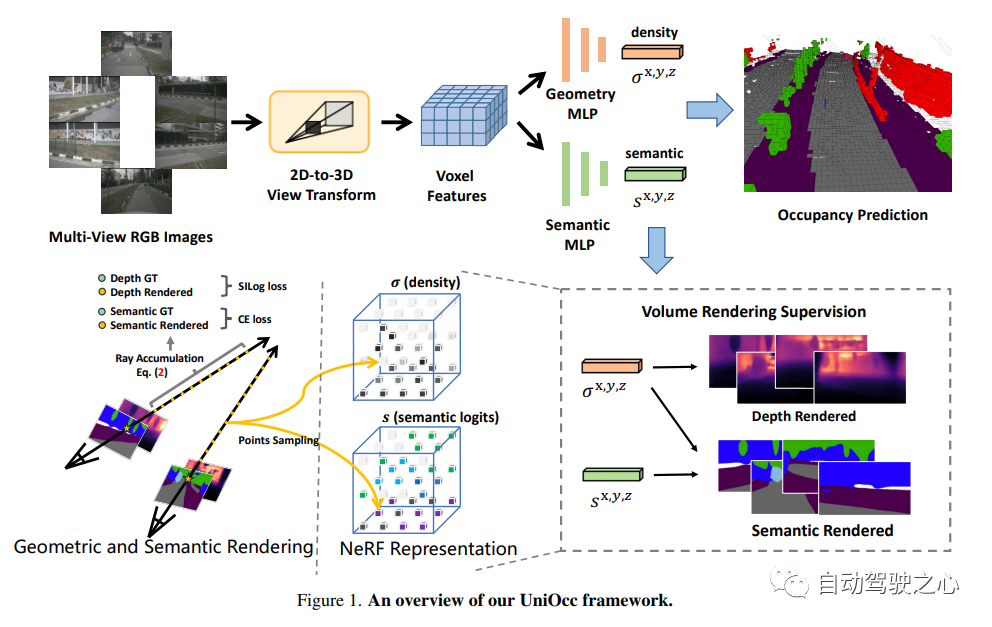
#10 で 3 位にランクされました。 Unisim
Wowaoao が制作しており、間違いなく高品質の製品です。 UniSim: ニューラル閉ループセンサーシミュレーター論文リンク: https://arxiv.org/pdf/2308.01898.pdf普及を妨げる重要な理由しかし、セキュリティはまだ十分ではありません。現実の世界は、特にロングテール効果により、あまりにも複雑です。境界シナリオは安全な運転にとって重要であり、多様ですが遭遇するのは困難です。これらのシナリオで自動運転システムのパフォーマンスをテストすることは非常に困難です。現実の世界でテストするのは困難であり、非常に高価で危険なためです。この課題を解決するために、産業界と学術界の両方が取り組み始めています。シミュレーションシステム開発に注目当初、シミュレーション システムは、他の車両/歩行者の移動挙動のシミュレーションと自動運転計画モジュールの精度のテストに主に焦点を当てていました。近年、研究の焦点はセンサーレベルのシミュレーション、つまりライダーやカメラ画像などの生データを生成するシミュレーションに徐々に移行し、知覚、予測、計画に至る自動運転システムのエンドツーエンドのテストを実現しています。 。 これまでの作品とは異なり、UniSim は初めて同時に達成しました:- 高いリアリズム: 現実の世界を正確にシミュレートできます (
- 閉ループ シミュレーション: 無人車をテストするためにまれに危険なシーンを生成でき、無人車が自由に対話できるようにします。 #スケーラブル:
- より多くのシーンに簡単に拡張でき、データを一度収集するだけで、テストを再構築してシミュレーションできます
 #書き換える内容は、シミュレーションシステムの構築です。
#書き換える内容は、シミュレーションシステムの構築です。
UniSim まず、収集したデータから、 自動車、歩行者、道路、建物、交通標識などの自動運転シーンをデジタル世界で再構築します。次に、
simulation用に再構成されたシーンを制御して、いくつかのまれなキー シーンを生成します。 閉ループ シミュレーション
UniSim は閉ループ シミュレーション テストを実行でき、まず車の挙動を制御することで、危険でまれなシーンを作り出すことができます。例えば、現在の車線に突然対向車が来た場合、UniSim が対応するデータをシミュレーションして生成し、自動運転システムを実行して経路計画の結果を出力し、経路計画の結果に基づいて無人車両が移動します。次の指定された場所に移動し、シーン (無人車両や他の車両の位置) を更新し、引き続きシミュレーションを実行し、自動運転システムを実行し、仮想世界の状態を更新します... この閉ループ テストを通じて、自動運転システムとシミュレーション環境が相互作用して、元のデータとはまったく異なるシーンを作成できます

以上がNeRFと自動運転の過去と現在、10本近くの論文をまとめました!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1317
25
1268
29
1245
24
14
1423
52
1317
25
1268
29
1245
24

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
最初のパイロットおよび重要な記事では、主に自動運転技術で一般的に使用されるいくつかの座標系と、それらの間の相関と変換を完了し、最終的に統合環境モデルを構築する方法を紹介します。ここでの焦点は、車両からカメラの剛体への変換 (外部パラメータ)、カメラから画像への変換 (内部パラメータ)、および画像からピクセル単位への変換を理解することです。 3D から 2D への変換には、対応する歪み、変換などが発生します。要点:車両座標系とカメラ本体座標系を平面座標系とピクセル座標系に書き換える必要がある 難易度:画像の歪みを考慮する必要がある 歪み補正と歪み付加の両方を画面上で補正する2. はじめに ビジョンシステムには、ピクセル平面座標系 (u, v)、画像座標系 (x, y)、カメラ座標系 ()、世界座標系 () の合計 4 つの座標系があります。それぞれの座標系には関係性があり、
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
