

LLaMA をベースにテンソル名を変更した Kai-Fu Lee の大規模モデルは物議を醸しました。公式の回答はこちらです

少し前に、オープンソースの大規模モデルの分野に新しいモデルが導入されました。コンテキスト ウィンドウのサイズは 200k を超え、一度に 400,000 個の漢字の「易」を処理できます。
Innovation Works の会長兼 CEO である Kai-fu Lee 氏は、大規模模型会社「Zero One Thousand Things」を設立し、Yi-6B や Yi-34B を含むこの大型模型を製作しました。バージョン
Hugging Face English オープンソース コミュニティ プラットフォームと C-Eval 中国語評価リストによると、Yi-34B は発売時に SOTA 国際最高パフォーマンス指標の認定を数多く達成し、このモデルは、LLaMA2 や Falcon などのオープンソースの競合製品を破った「ダブルチャンピオン」です。
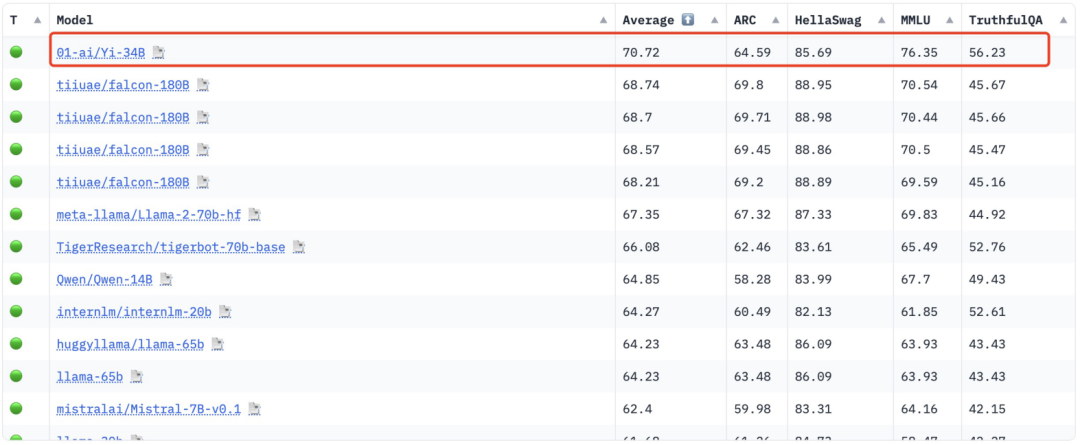
Yi-34B はまた、Hugging Face の世界的なオープンソース モデル ランキングでトップに輝いた唯一の国内モデルとなりました。当時は「世界最強のオープンソースモデル」と呼ばれていました。
発表後、このモデルは国内外の多くの研究者や開発者の注目を集めました
しかし最近、一部の研究者が次のことを発見しました。 Yi-34B モデルは、2 つのテンソルの名前が変更されていることを除いて、基本的に LLaMA アーキテクチャを採用しています。
# 元の投稿を表示するには、このリンクをクリックしてください: https://news.ycombinator.com/item?id=38258015
この投稿では次のようにも言及されています:
Yi-34B のコードは実際には LLaMA コードを再構築したものですが、実質的な変更は加えられていないようです。このモデルは明らかにオリジナルの Apache バージョン 2.0 LLaMA ファイルに基づいて編集されたものですが、LLaMA については言及されていません:

Yi vs LLaMAコードの比較。コード リンク: https://www.diffchecker.com/bJTqkvmQ/
さらに、これらのコード変更は、プル リクエストを通じてトランスフォーマー プロジェクトに送信されません。ですが、代わりに外部コードとしてアタッチすると、セキュリティ上のリスクが生じたり、フレームワークでサポートされなかったりする可能性があります。このモデルにはカスタム コード戦略がないため、HuggingFace リーダーボードでは、最大 200K のコンテキスト ウィンドウでこのモデルのベンチマークを行うことさえできません。
これは 32K モデルであると主張していますが、4K モデルとして構成されており、RoPE スケーリング構成はなく、スケーリング方法の説明もありません (注: 前にゼロ 1 という意味があります)モデル自体はトレーニング用に 4K シーケンス上にありますが、推論フェーズ中に 32K までスケールできるということです)。現時点では、その微調整データに関する情報はありません。また、疑わしいほど高い MMLU スコアを含むベンチマークを再現するための手順も提供していませんでした。 人工知能の分野でしばらく働いたことがある人なら誰でも、これを無視することはできないでしょう。これは虚偽の広告ですか?ライセンス違反?実際にベンチマークを不正行為していたのでしょうか?誰が気にする?論文を変更することもできますし、この場合はベンチャーキャピタルの資金をすべて受け取ることもできます。少なくとも Yi は基準を上回っています。なぜなら、これは基本的なモデルであり、そのパフォーマンスが非常に優れているからです。数日前、Huggingface コミュニティで、開発者は次のことも指摘しました。
私たちの理解によれば、2 つのテンソルの名前を変更することを除いて、Yi は LLaMA アーキテクチャを完全に採用しています。 (input_layernorm、post_attention_layernorm)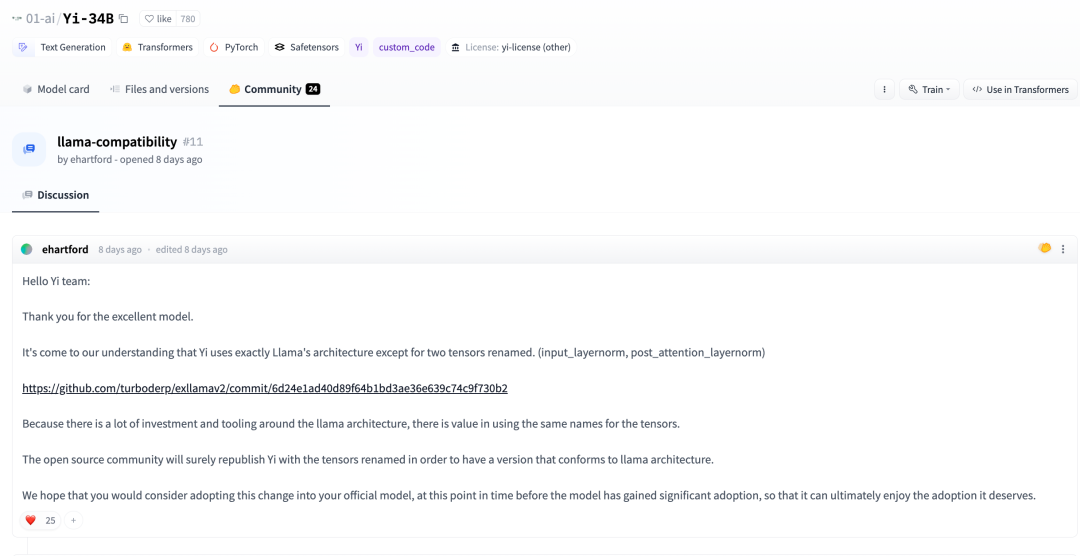
#ディスカッションの中で、一部のネチズンは次のように述べました。Meta LLaMA のアーキテクチャ、コード ベース、およびその他の関連リソースを正確に使用したい場合は、 LLaMA が規定するライセンス契約を遵守してください

LLaMA のオープンソース ライセンスに準拠するために、開発者は名前を元に戻して再公開することにしましたハグフェイス
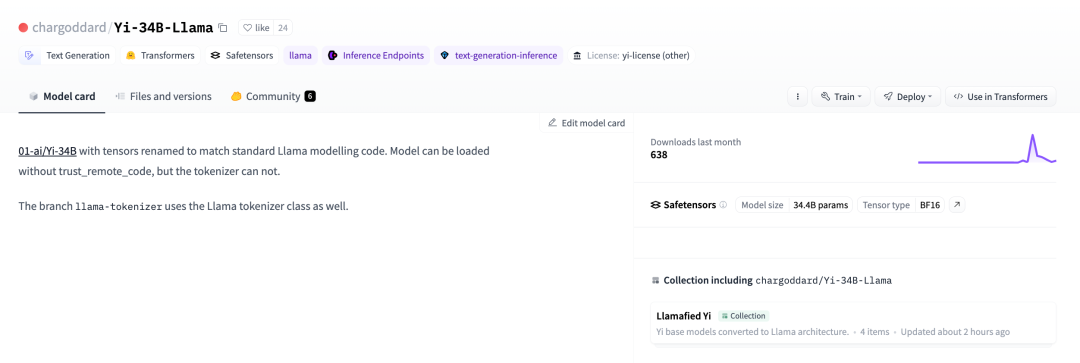 01-ai/Yi-34B では、標準 LLaMA モデル コードに一致するようにテンソルの名前が変更されました。関連リンク: https://huggingface.co/chargoddard/Yi-34B-LLaMA
01-ai/Yi-34B では、標準 LLaMA モデル コードに一致するようにテンソルの名前が変更されました。関連リンク: https://huggingface.co/chargoddard/Yi-34B-LLaMA
この内容を読むと、賈陽青氏がアリババを辞めて起業したというニュースが数日前に友人たちの間で話題になったと推測できます

## この件に関しては、ハート・オブ・ザ・マシーンもゼロワンとオールシングスに検証を求めていた。 Lingyiwu 氏は次のように答えました。
GPT は業界で認められた成熟したアーキテクチャであり、LLaMA は GPT についての概要を作成しました。 Zero One Thousand Things の大規模な研究開発モデルの構造設計は、GPT の成熟した構造に基づいており、業界トップレベルの公開結果を活用しています。同時に、Zero One Thousand Things チームは多くの作業を行ってきました。モデルの理解とトレーニングについては、基礎の 1 つである優れた結果をリリースするのは初めてです。同時に、Zero One Thousand Things は、モデル構造レベルでの本質的なブレークスルーの模索も続けています。
モデル構造はモデル トレーニングの一部にすぎません。 Yi のオープンソース モデルは、データ エンジニアリング、トレーニング方法、ベビーシッター (トレーニング プロセスのモニタリング) スキル、ハイパーパラメータ設定、評価方法、評価指標の性質の理解の深さ、評価の原理に関する研究の深さなど、他の側面に重点を置いています。モデル汎用化機能、業界トップのAIインフラ機能など、多くの研究開発と基盤作業が投資されており、これらのタスクは基本的な構造よりも大きな役割と価値を果たしていることが多く、これらはZeroのコアテクノロジーでもあります大型モデルの事前訓練段階にある 1 台のワゴン。堀。
多数のトレーニング実験を実施する過程で、実験の実行のニーズに応じてコードの名前を変更しました。私たちはオープン ソース コミュニティからのフィードバックを非常に重視しており、Transformer エコシステムへの統合を改善するためにコードを更新しました
コミュニティからのフィードバックに非常に感謝しています。私たちはオープン ソース コミュニティに参加したばかりです。皆様と協力してコミュニティを構築していきたいと考えています。繁栄、イー・カイユアンは今後も進歩し続けるために最善を尽くします
以上がLLaMA をベースにテンソル名を変更した Kai-Fu Lee の大規模モデルは物議を醸しました。公式の回答はこちらですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7564
7564
 15
1386
52
87
11
28
100
15
1386
52
87
11
28
100

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosでgitlabデータベースを選択する方法
Apr 14, 2025 pm 05:39 PM
Centosでgitlabデータベースを選択する方法
Apr 14, 2025 pm 05:39 PM
CENTOSシステムにGitLabをインストールして構成する場合、データベースの選択が重要です。 gitlabは複数のデータベースと互換性がありますが、PostgreSQLとMySQL(またはMariaDB)が最も一般的に使用されています。この記事では、データベースの選択要因を分析し、詳細なインストールと構成の手順を提供します。データベース選択ガイドデータベースを選択する際には、次の要因を考慮する必要があります。PostGreSQL:GitLabのデフォルトデータベースは強力で、スケーラビリティが高く、複雑なクエリとトランザクション処理をサポートし、大規模なアプリケーションシナリオに適しています。 MySQL/MariadB:Webアプリケーションで広く使用されている人気のあるリレーショナルデータベース、安定した信頼性の高いパフォーマンスを備えています。 MongoDB:NOSQLデータベース、専門
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
