

大規模不正モデルを見分ける1つのトリック、医師の弟のオープンソースAI数学「デーモンミラー」

現在、多くの有名モデルが数学が得意だと主張しています。本当の才能を持っているのは誰でしょうか?連続テスト問題で「カンニング」したのは誰ですか?
今年、誰かがハンガリー国立数学最終試験のために発表されたばかりの問題について包括的なテストを実施しました
多くのモデルが突然成功しました"元の形状になりました。」 。
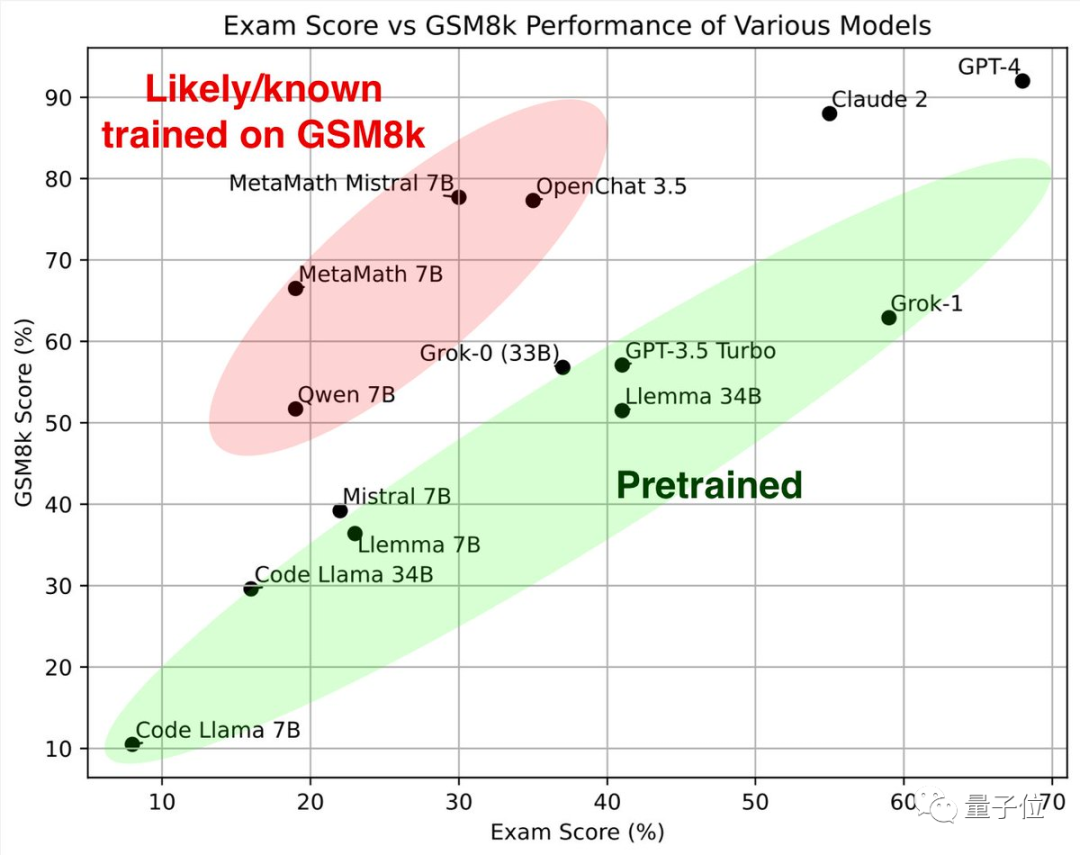
最初に緑色の部分を見てください。これらの大規模モデルは、古典的な数学テスト セット GSM8k と新しい論文で同様の結果を示しています。 一緒にそれらは参照標準 を形成します。
##赤い部分# を見ると、GSM8K での結果は、同じパラメータ スケールを持つ大型モデルの結果よりも大幅に高くなります。到着次第 新品紙のスコアは大幅に下がり、同サイズの大型モデルとほぼ同等でした。 研究者らは、彼らを 「GSM8k でトレーニングを受けた疑いがある、または既知である」
として分類しました。このテストを見た後、これまで見たことのない質問を評価し始めるべきだと言う人もいます。
この種のテストは、と考える人もいます。誰もが実際に大規模モデルを使用した経験が現在唯一信頼できる評価方法です

Musk Grok は GPT-4 に次いで 2 番目であり、オープンソースの Llemma は優れた結果を示しています
テスター
大きなモデルにハンガリーの国立高校数学の最終試験を受けさせてください。このトリックは
Musk の xAI
xAI の Grok 大規模モデルがネットワーク データ内のテスト問題を誤って認識したという問題を排除するために、いくつかの一般的なテスト セットに加えて、このテストも実施されました 今年のこの試験テストは 5 月末に完了したばかりで、現在の大型モデルでは基本的にこの一連のテスト問題を見る機会がありませんでした。 #xAI は、比較のために GPT-3.5、GPT-4、および Claude 2 がリリースされたときにその結果も発表しました。
この一連のデータに基づいて、Paster はさらなるテストを実施しました。テスト オブジェクトは、強力な数学的機能を備えた複数のオープン ソース モデルでした。およびテスト問題は、各モデルのテスト スクリプトと回答結果は、誰もが他のモデルを確認してさらにテストできるように、Huggingface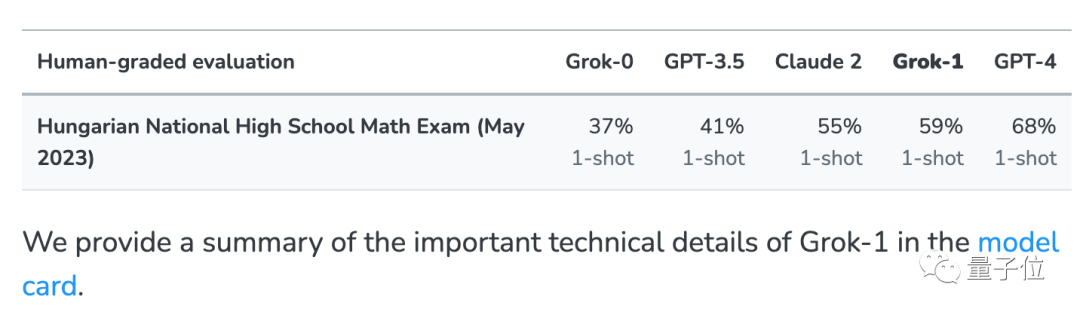 でオープンソース化されています。
でオープンソース化されています。
結果は、GPT-4 と Claude-2 が最初の段階を形成し、GSM8k と新しい論文で非常に高いスコアを示していることを示しています。 これは、GPT-4 と Claude 2 のトレーニング データに GSM8k のリークされた質問がないという意味ではありませんが、少なくともそれらは優れた一般化機能を備えており、新しい質問を正しく解決できるため、リークされた質問は存在しません。お手入れ。
次に、Musk xAI の Grok-0 (33B) 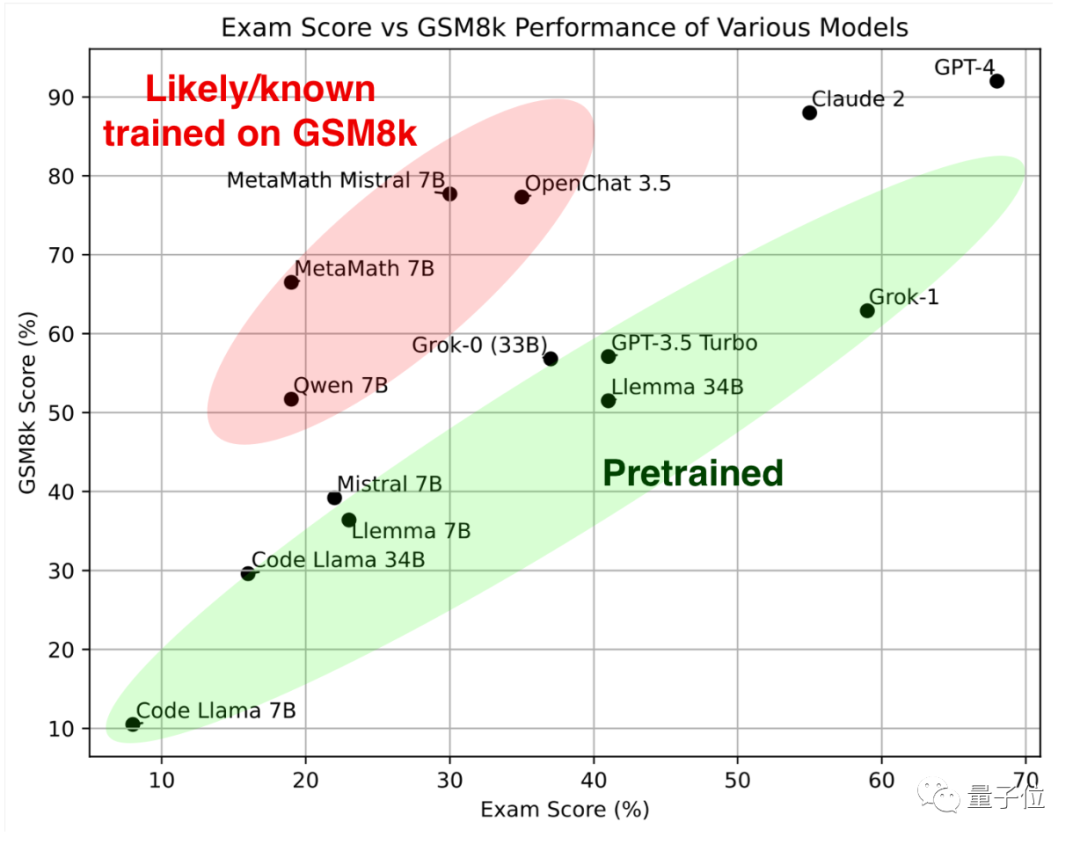 と Grok-1
と Grok-1
が良好なパフォーマンスを示しました。
Grok-1 は「不正行為をしないグループ」の中で最も高いスコアを持っており、彼の新しい論文のスコアは Claude 2 よりもさらに高くなっています。 GSM8k 上の Grok-0 のパフォーマンスは GPT3.5-Turbo に近く、新しい論文ではわずかに劣ります。
上記のクローズド モデルを除き、テスト内の他のモデルはすべてオープン ソースです。Code Llama シリーズ
は Meta の独自バージョンです。 Llama 2 の基本的には、自然言語に基づいてコードを生成することに重点を置いて微調整されています。
Code Llama に基づいて、多くの大学や研究機関が共同で Llemma シリーズ を立ち上げ、EleutherAI によってオープンソース化されました。 チームは、科学論文、数学を含むネットワーク データ、および数学的コードから Proof-Pile-2 データセットを収集しました。トレーニング後、Llemma はツールを使用して、それ以上の微調整を行わずに形式的な定理証明を行うことができます。
 新しい論文によると、Llemma 34B のパフォーマンスは GPT-3.5 Turbo レベルに近いです
新しい論文によると、Llemma 34B のパフォーマンスは GPT-3.5 Turbo レベルに近いです
Mistral シリーズ は、フランスの AI ユニコーンである Mistral AI によってトレーニングされています。Apache2.0 のオープンソース契約は Llama よりも緩和されており、羊 Tuo ファミリーに次いで、オープンソース コミュニティで最も人気のある基本モデル。 ##OpenChat 3.5 および MetaMath Mistral はすべてミストラル エコシステムに基づいて微調整されています。 および MAmmoTH Code は、Code Llama エコシステムに基づいています。 オープンソースの大規模モデルを実際のビジネスに採用することを選択する人は、このグループを避けるように注意する必要があります。なぜなら、これらのモデルはランキングを上げるためだけに優れたパフォーマンスを発揮する可能性が高いためですが、実際の機能はそれほど強力ではない可能性があります。同じスケールの他のモデル 多くのネチズンは、この実験がまさにモデルの実際の状況を理解するために必要なものであると信じて、この実験に対してパスター氏に感謝の意を表しました。 懸念を表明した人もいます: この日から、大規模モデルをトレーニングする全員が、過去のハンガリーの数学試験問題を追加することになります。 同時に、解決策は、独自のテストを行う # を設立することであると考えています。 

専門の大規模モデル評価会社  #テスト ベンチマークを確立することです。
#テスト ベンチマークを確立することです。
以上が大規模不正モデルを見分ける1つのトリック、医師の弟のオープンソースAI数学「デーモンミラー」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
Sony InteractiveEntertainmentのチーフアーキテクト(SIE、Sony Interactive Entertainment)のMark Cernyは、パフォーマンスアップグレードAMDRDNA2.xアーキテクチャGPU、およびAMDとの機械学習/人工知能プログラムコードノームの「Amethylst」を含む、次世代ホストPlayStation5Pro(PS5PRO)のハードウェアの詳細をリリースしました。 PS5PROパフォーマンスの改善の焦点は、より強力なGPU、高度なレイトレース、AI搭載のPSSRスーパー解像度関数を含む3つの柱に依然としてあります。 GPUは、SonyがRDNA2.xと名付けたカスタマイズされたAMDRDNA2アーキテクチャを採用しており、RDNA3アーキテクチャがあります。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CentosでのZookeeperのパフォーマンスを調整する方法は何ですか
Apr 14, 2025 pm 03:18 PM
CENTOSでのZookeeperパフォーマンスチューニングは、ハードウェア構成、オペレーティングシステムの最適化、構成パラメーターの調整、監視、メンテナンスなど、複数の側面から開始できます。特定のチューニング方法を次に示します。SSDはハードウェア構成に推奨されます。ZookeeperのデータはDISKに書き込まれます。十分なメモリ:頻繁なディスクの読み取りと書き込みを避けるために、Zookeeperに十分なメモリリソースを割り当てます。マルチコアCPU:マルチコアCPUを使用して、Zookeeperが並行して処理できるようにします。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 最後に変わった! Microsoft Windows検索機能は新しいアップデートの先導
Apr 13, 2025 pm 11:42 PM
最後に変わった! Microsoft Windows検索機能は新しいアップデートの先導
Apr 13, 2025 pm 11:42 PM
MicrosoftのWindows検索機能に対する改善は、EUのWindows Insiderチャネルでテストされています。以前は、統合されたWindows検索機能はユーザーによって批判されており、経験が不十分でした。この更新は、検索機能を2つの部分に分割します。ローカル検索とBingベースのWeb検索でユーザーエクスペリエンスを向上させます。検索インターフェイスの新しいバージョンは、デフォルトでローカルファイル検索を実行します。オンラインで検索する必要がある場合は、[Microsoft BingWebsearch]タブをクリックして切り替える必要があります。切り替え後、検索バーには「Microsoft BingWebsearch:」が表示され、ユーザーはキーワードを入力できます。この動きにより、ローカル検索結果とBing検索結果の混合が効果的に回避されます
