

約 1 年前、私はファイルからデータ (主にテーブルに含まれるデータ) を抽出して構造化するタスクを割り当てられました。私にはコンピューター ビジョンに関する予備知識がなかったので、適切な「プラグ アンド プレイ」ソリューションを見つけるのに苦労しました。当時利用可能なオプションは、大規模で扱いにくい最新のニューラル ネットワーク (NN) に基づくソリューションか、一貫性が十分ではない OpenCV に基づくシンプルなソリューションのいずれかでした。
既存の OpenCV スクリプトからインスピレーションを得て、テーブルを抽出するシンプルで一貫した方法を開発し、それをオープンソースの Python ライブラリにしました: img2table
必要なコンテンツ書き換えられる内容は次のとおりです: リンク: https://github.com/xavctn/img2table

深層学習ソリューションと比較して、この軽量パッケージはトレーニングを必要とせず、最小限のパラメーター化を必要とします。次の機能を提供します。
pip install img2table
从img2table.document导入Image类# 图像实例化 img = Image(src="myimage.jpg")# 表格识别 img_tables = img.extract_tables()# 表格识别结果 img_tables[ExtractedTable(title=None, bbox=(10, 8, 745, 314),shape=(6, 3)), ExtractedTable(title=None, bbox=(936, 9, 1129, 111),shape=(2, 2))]
書き換える必要がある内容は次のとおりです: 上記の例で使用されている画像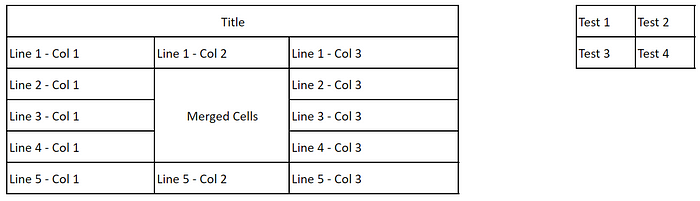
from img2table.document import PDFfrom img2table.ocr import TesseractOCR# Instantiation of the pdfpdf = PDF(src="mypdf.pdf")# Instantiation of the OCR, Tesseract, which requires prior installationocr = TesseractOCR(lang="eng")# Table identification and extractionpdf_tables = pdf.extract_tables(ocr=ocr)# We can also create an excel file with the tablespdf.to_xlsx('tables.xlsx',ocr=ocr)サンプル表は、PDF ファイルから抽出されたサンプルです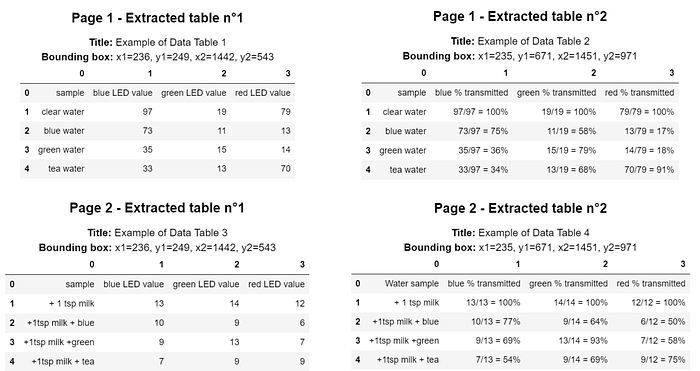
元の意味を変更する必要はありません。書き直す必要があるのは、「ボーダレス」テーブルの抽出例です。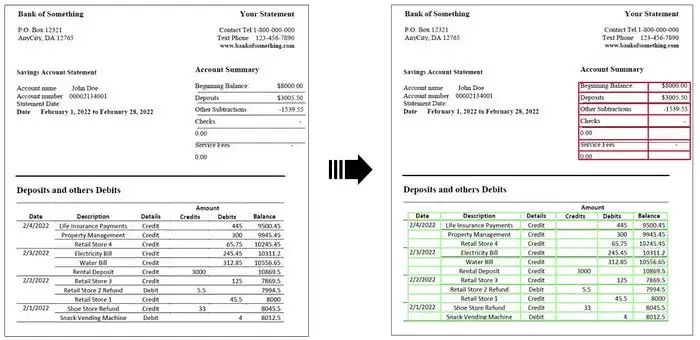
需要重写的内容是:cv2.HoughLinesP(img, rho, theta, threshold, None, minLinLength, maxLineGap)
簡素化されたアルゴリズム表現の実装 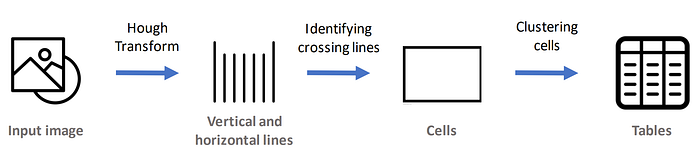
以上がPythonを使用して画像からテーブルを抽出するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



