
 テクノロジー周辺機器
AI
リアルタイム画像速度が 5 ~ 10 倍に向上し、清華 LCM/LCM-LoRA が人気となり、100 万回以上の再生回数と 200,000 回以上のダウンロードを達成しました。
テクノロジー周辺機器
AI
リアルタイム画像速度が 5 ~ 10 倍に向上し、清華 LCM/LCM-LoRA が人気となり、100 万回以上の再生回数と 200,000 回以上のダウンロードを達成しました。
リアルタイム画像速度が 5 ~ 10 倍に向上し、清華 LCM/LCM-LoRA が人気となり、100 万回以上の再生回数と 200,000 回以上のダウンロードを達成しました。

生成モデルは「リアルタイム」時代に突入しますか?
Vincentian 図と Tusheng 図の使用は、もはや新しいことではありません。しかし、これらのツールを使用する過程で、ツールの動作が遅く、生成された結果を取得するまでにしばらく待たされることが多いことがわかりました。
しかし最近、「LCM」と呼ばれるモデルによってこれが変更されました。 、リアルタイムで連続的に画像を生成することもできます。


# 出典: https://twitter.com/javilopen/status/1724398666889224590
LCM の正式名は Latent Consistency Models (潜在整合性モデル) で、清華大学学際情報研究所の研究者によって構築されました。このモデルがリリースされる前は、安定拡散などの潜在拡散モデル (LDM) は、反復サンプリング プロセスの計算の複雑さのため、生成に非常に時間がかかりました。いくつかの革新的な方法により、LCM はわずか数ステップの推論で高解像度の画像を生成できます。統計によると、LCM は主流のヴィンセント グラフ モデルの効率を 5 ~ 10 倍向上させることができるため、リアルタイムの効果を示すことができます。
- 論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2310.04378.pdf
- プロジェクトのアドレス: https://github.com/luosiallen/latent-consistency-model
技術レポートのリンク: https://arxiv.org/ pdf /2311.05556.pdf
 画像出典: https://twitter.com/javilopen/status/1724398666889224590
画像出典: https://twitter.com/javilopen/status/1724398666889224590
書き直す必要がある内容は次のとおりです: 画像出典: https://twitter.com/javilopen/status/1724398708052414748
## 私たちのチームは LCM のコードを完全にオープンソース化し、SD-v1.5 や SDXL などの事前トレーニング済みモデルの内部蒸留に基づくモデル重みファイルとオンライン デモンストレーションを公開しました。さらに、Hugging Face チームは潜在的な整合性モデルをディフューザーの公式リポジトリに統合し、LCM と LCM-LoRA の関連コード フレームワークを 2 つの連続した公式バージョン v0.22.0 と v0.23.0 で更新して、潜在的な一貫性の理解を提供しました。一貫性モデル: 一貫性モデルの優れたサポート。 Hugging Face で公開されたモデルは、今日の人気リストで 1 位にランクされ、すべてのプラットフォームで最も人気のある Vincent グラフ モデルとなり、すべてのカテゴリで 3 番目に人気のあるモデルになりました

次に、LCMとLCM-LoRAの2つの研究成果をそれぞれ紹介します。
LCM: わずか数ステップの推論で高解像度画像を生成
AIGC 時代 (安定拡散や DALL-E などの拡散モデルベースのビンセント マップを含む) 3 このモデルは広く注目を集めています。拡散モデルは、トレーニング データにノイズを追加し、そのプロセスを逆にすることで高品質の画像を生成します。ただし、拡散モデルでは画像を生成するために複数ステップのサンプリングが必要であり、これは比較的時間がかかるプロセスであり、推論のコストが増加します。このようなモデルを導入する場合、複数ステップのサンプリングが遅いという問題が大きなボトルネックになります。
OpenAI の Song Yang 博士が今年提案した一貫性モデル (CM) は、上記の問題を解決するアイデアを提供します。整合性モデルは単一ステップで生成できるように設計されており、拡散モデルの生成を加速する大きな可能性を示していることが指摘されました。ただし、一貫性モデルは無条件の画像生成に限定されているため、Vincentian 画像、グラフ生成画像などを含む多くの実際のアプリケーションでは、まだこのモデルの潜在的な利点を享受できません。
潜在整合性モデル (LCM) は、上記の問題を解決するために生まれました。潜在一貫性モデルは、特定の条件下での画像生成タスクをサポートし、潜在コーディング、分類子なしのガイダンス、および拡散モデルで広く使用されているその他の多くのテクノロジーを組み合わせて、条件付きノイズ除去プロセスを大幅に高速化し、多くの実用的なアプリケーションを提供します。小道。
LCM 技術詳細
具体的には、潜在整合性モデルは、拡散モデルのノイズ除去問題を、以下のプロセスに示す拡張確率的流れ常微分方程式を解くものとして解釈します。
従来の普及モデルを改良することで、ソリューションの効率を向上させることができます。従来の方法では数値反復を使用して常微分方程式を解きますが、より正確なソルバーを使用した場合でも、各ステップの精度には限界があり、満足のいく結果を得るには約 10 回の反復が必要です
従来の反復解法では常微分方程式の場合、ポテンシャル整合性モデルは常微分方程式を直接シングル ステップで解く必要があり、方程式の最終的な解を予測します。理論的には、画像はシングル ステップで生成できます
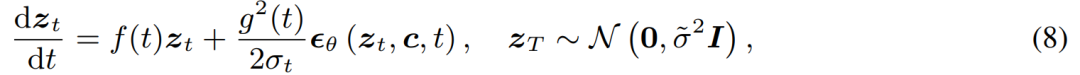
(3) スキップ戦略を使用して整合性損失を計算すると、潜在的整合性モデルの蒸留プロセスが大幅に高速化されます。潜在整合性モデルの蒸留アルゴリズムの擬似コードを次の図に示します。


# LCM
#LCM-LORA によって生成された画像: 一般的な安定した伝送加速モジュール潜在一貫性モデルに基づいて、著者チームはさらに、LCM-LoRA に関する技術レポートをリリースしました。潜在整合性モデルの蒸留プロセスは、元の事前トレーニング済みモデルの微調整プロセスとみなすことができるため、LoRA などの効率的な微調整手法を潜在整合性モデルのトレーニングに使用できます。 LoRA テクノロジーによってもたらされるリソースの節約のおかげで、著者のチームは安定拡散シリーズの中で最も多くのパラメーターを使用して SDXL モデルの蒸留を実施し、非常に少ないステップで生成できる潜在的なコンセンサスを取得することに成功しました。数十の SDXL ステップ、性的モデル。
論文の冒頭で、この研究は、潜在拡散モデル (LDM) がテキスト画像や線画画像の生成には成功しているものの、逆サンプリング プロセスが遅いため、リアルタイム アプリケーションが制限され、ユーザー体験。現在のオープン ソース モデルとアクセラレーション テクノロジは、通常のコンシューマー グレードの GPU でリアルタイム生成をまだ実現できません。LDM を高速化する方法は、一般に 2 つのカテゴリに分類されます。最初のカテゴリには、DDIM、DPMSolver、DPM ソルバーなどの高度な ODE ソルバーが含まれます。生成プロセスを高速化します。 2 番目のカテゴリでは、LDM を蒸留して機能を簡素化します。 ODE - ソルバーは推論ステップを削減しますが、特に分類器を使用しないガイダンスを採用する場合には、依然としてかなりの計算オーバーヘッドが必要です。一方、Guided-Distill などの蒸留方法は有望ではありますが、集中的な計算要件による実用的な制限に直面しています。 LDM で生成された画像の速度と品質のバランスを見つけることは、依然としてこの分野の課題です。
最近、一貫性モデル (CM) に触発されて、画像生成におけるサンプリングが遅い問題の解決策として潜在一貫性モデル (LCM) が登場しました。 LCM は、逆拡散プロセスを強化された確率フロー ODE (PF-ODE) 問題としてみなします。このタイプのモデルは、数値 ODE ソルバーによる反復解を必要とせずに、潜在空間内の解を革新的に予測します。その結果、わずか 1 ~ 4 の推論ステップで高解像度画像を効率的に合成できます。さらに、LCM は蒸留効率の点でも優れており、最小ステップ推論を完了するには、A100 を使用した 32 時間のトレーニングのみが必要です。
これに基づいて、潜在整合性微調整 (LCF) 法と呼ばれる手法が使用されます。 、教師拡散モデルから始めることなく、事前トレーニングされた LCM を微調整できます。アニメ、実際の写真、ファンタジー画像データセットなどの特殊なデータセットの場合は、潜在整合蒸留 (LCD) を使用して事前トレーニング済み LDM を LCM に蒸留するか、LCF を使用して LCM を直接微調整するなど、追加の手順が必要です。ただし、この追加のトレーニングは、さまざまなデータセットでの LCM の迅速な展開を妨げる可能性があり、カスタム データセットでトレーニング不要の高速な推論を実現できるかどうかという重要な疑問が生じます。上記の疑問に答えるために、研究者らは LCM-LoRA を提案しました。 LCM-LoRA は、トレーニング不要の一般的な加速モジュールであり、さまざまな安定拡散 (SD) 微調整モデルまたは SD LoRA に直接接続して、最小限のステップで高速推論をサポートできます。 DDIM、DPM ソルバー、DPM ソルバーなどの初期の数値確率的フロー ODE (PF-ODE) ソルバーと比較して、LCM-LoRA はニューラル ネットワークに基づく新しいクラスの PF-ODE ソルバー モジュールを表します。これは、さまざまな微調整された SD モデルと LoRA
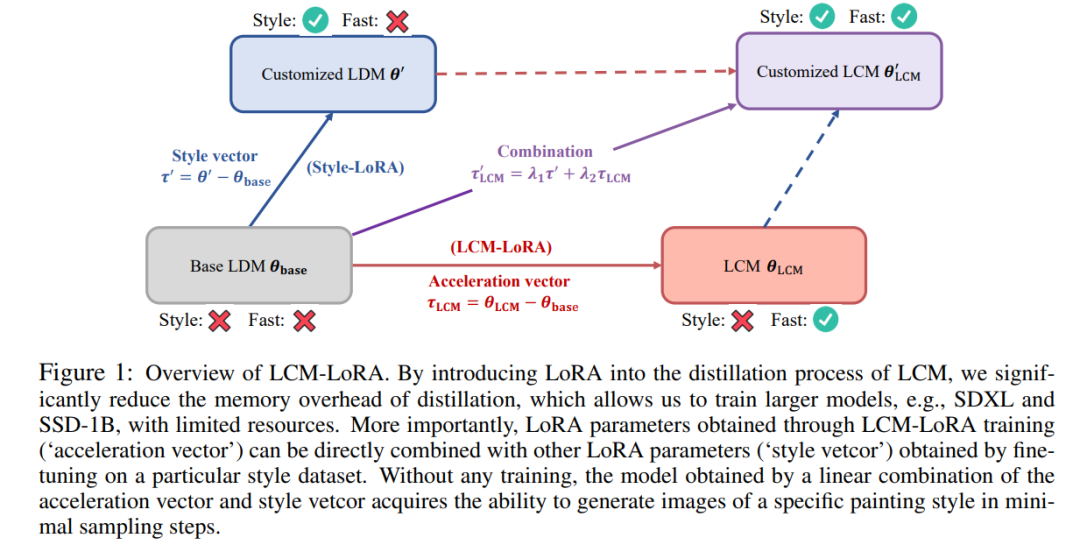 LCM-LoRA 概要プロットにわたる強力な一般化機能を示します。 LoRA を LCM の蒸留プロセスに導入することで、この研究では蒸留のメモリ オーバーヘッドが大幅に削減され、限られたリソースを利用して SDXL や SSD-1B などのより大きなモデルをトレーニングできるようになりました。さらに重要なのは、LCM-LoRA トレーニングを通じて取得された LoRA パラメーター (加速ベクトル) は、特定のスタイル データセットの微調整によって取得された他の LoRA パラメーター (スタイル ベクトル) と直接組み合わせることができることです。トレーニングを行わなくても、加速度ベクトルとスタイル ベクトルの線形結合によって得られるモデルは、最小限のサンプリング ステップで特定の絵画スタイルの画像を生成できます。
LCM-LoRA 概要プロットにわたる強力な一般化機能を示します。 LoRA を LCM の蒸留プロセスに導入することで、この研究では蒸留のメモリ オーバーヘッドが大幅に削減され、限られたリソースを利用して SDXL や SSD-1B などのより大きなモデルをトレーニングできるようになりました。さらに重要なのは、LCM-LoRA トレーニングを通じて取得された LoRA パラメーター (加速ベクトル) は、特定のスタイル データセットの微調整によって取得された他の LoRA パラメーター (スタイル ベクトル) と直接組み合わせることができることです。トレーニングを行わなくても、加速度ベクトルとスタイル ベクトルの線形結合によって得られるモデルは、最小限のサンプリング ステップで特定の絵画スタイルの画像を生成できます。
LCM-LoRA の技術的な詳細は次のように書き換えることができます:
一般的に、潜在整合性モデルは単一ステージのガイド付きモデルを使用してトレーニングされます。蒸留 このように進めて、このメソッドは、事前にトレーニングされたオートエンコーダーの潜在空間を利用して、ガイダンス拡散モデルを LCM に蒸留します。このプロセスには、確率的フロー ODE の強化が含まれます。これは、生成されたサンプルが高品質の画像を生成する軌道に従うことを保証する数式と考えることができます。 蒸留の焦点は、必要なサンプリング手順の数を大幅に削減しながら、これらの軌跡の忠実性を維持することであることは言及する価値があります。アルゴリズム 1 は、LCD の疑似コードを提供します。
LCM の蒸留プロセスは、事前にトレーニングされた拡散モデルのパラメーターに基づいて実行されるため、潜在的コンシステンシー蒸留は拡散の微調整プロセスとみなすことができます。したがって、LoRA などのいくつかの効率的なパラメータ調整方法を使用できます。LoRA 透過應用低秩分解來更新預訓練的權重矩陣。具體而言,給定一個權重矩陣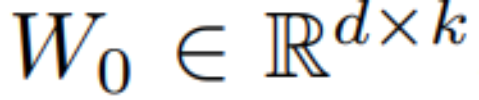 ,其更新方式表述為
,其更新方式表述為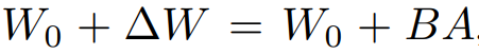 ,其中
,其中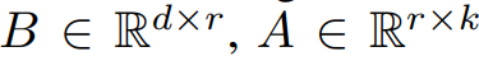 ,訓練過程中,W_0 保持不變,梯度更新只應用於 A 和 B 兩個參數。因而對於輸入x,前向傳播的變更表述為:
,訓練過程中,W_0 保持不變,梯度更新只應用於 A 和 B 兩個參數。因而對於輸入x,前向傳播的變更表述為:
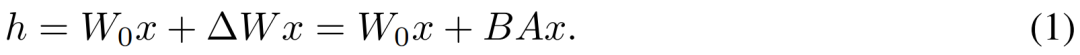
h 代表輸出向量,從公式(1)可以觀察到,透過將完整參數矩陣分解為兩個低秩矩陣的乘積,LoRA 顯著減少了可訓練參數的數量,從而降低了記憶體使用量。
下表將完整模型中的參數總數與使用 LoRA 技術時的可訓練參數進行了比較。顯然,透過在 LCM 蒸餾過程中結合 LoRA 技術,可訓練參數的數量顯著減少,有效降低了訓練的記憶體需求。

該研究透過一系列實驗顯示:LCD 範式可以很好地適應更大的模型如SDXL 、 SSD-1B ,不同模型的生成結果如圖2 所示。

作者發現使用LoRA技術可以提高蒸餾過程的效率,同時也發現透過訓練得到的LoRA參數可以作為一種通用的加速模組,可以直接與其他LoRA參數結合使用
如上圖1 所示,作者團隊發現,只需要將在特定風格資料集上微調得到的「風格參數」 與經過潛在一致性蒸餾得到的「加速參數」 進行簡單的線性組合,就可以獲得兼具快速生成能力和特定風格的全新潛在一致性模型。這項發現為現有開源社群內已存在的大量開源模型提供了極強的助力,使得這些模型甚至可以在無需任何額外訓練的情況下享受潛在一致性模型帶來的加速效果。
展示了使用這種方法改善"剪紙畫風" 模型後產生的新模型生成的效果,如下圖所示
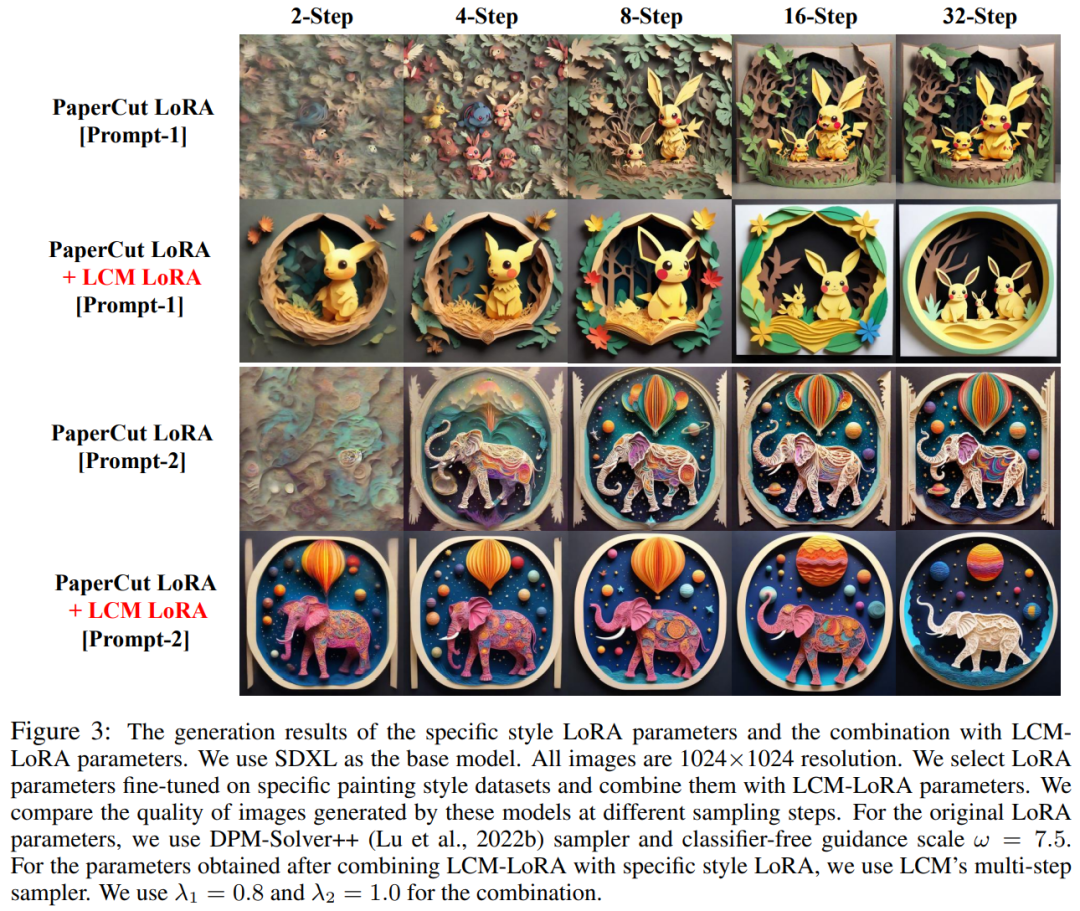
總之,LCM -LoRA是Stable-Diffusion(SD)模型的通用免訓練加速模組。它可以作為獨立且高效的基於神經網路的求解器模組來預測PF-ODE的解,從而能夠在各種微調的SD模型和SD LoRA上以最少的步驟進行快速推理。大量的文本到圖像生成實驗證明了LCM-LoRA強大的泛化能力和優越性
#團隊介紹
論文作者成員全部來自清華叉院,兩位共同一作分別是駱思勉,譚亦欽。
駱思勉是清華大學電腦科學與技術系二年級碩士生,指導教授是趙行教授。他本科畢業於復旦大學大數據學院。他的研究方向是多模態生成模型,對擴散模型、一致性模型和AIGC加速等感興趣,致力於開發下一代生成模型。此前,他以第一作者的身份在ICCV和NeurIPS等頂級會議上發表了多篇論文
譚亦欽是清華大學叉院二年級碩士生,他的導師是黃隆波老師。在本科階段,他就讀於清華大學電子工程系。他的研究方向主要涵蓋深度強化學習和擴散模型。在先前的研究中,他作為第一作者在ICLR等學術會議上發表了一些備受關注的論文,並進行了口頭報告
值得一提的是,兩位共一是在叉在院李建老師的高等電腦理論課上,提出了LCM的想法,並最後作為期末課程專案進行了展示。三位指導教師中,李建和黃隆波是清華交叉資訊院副教授,趙行是清華交叉資訊院助理教授。

之後上排配備「配備「左與右譚」):。第二排(左至右):黃隆波、李建、趙行。
#以上がリアルタイム画像速度が 5 ~ 10 倍に向上し、清華 LCM/LCM-LoRA が人気となり、100 万回以上の再生回数と 200,000 回以上のダウンロードを達成しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
これも Tusheng のビデオですが、PaintsUndo は別の道を歩んでいます。 ControlNet 作者 LvminZhang が再び生き始めました!今回は絵画の分野を目指します。新しいプロジェクト PaintsUndo は、開始されて間もなく 1.4kstar を獲得しました (まだ異常なほど上昇しています)。プロジェクトアドレス: https://github.com/lllyasviel/Paints-UNDO このプロジェクトを通じて、ユーザーが静止画像を入力すると、PaintsUndo が線画から完成品までのペイントプロセス全体のビデオを自動的に生成するのに役立ちます。 。描画プロセス中の線の変化は驚くべきもので、最終的なビデオ結果は元の画像と非常によく似ています。完成した描画を見てみましょう。
 RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 人工知能の開発プロセスにおいて、大規模言語モデル (LLM) の制御とガイダンスは常に中心的な課題の 1 つであり、これらのモデルが両方とも確実に機能することを目指しています。強力かつ安全に人類社会に貢献します。初期の取り組みは人間のフィードバックによる強化学習手法に焦点を当てていました (RL
 オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com この論文の著者は全員、イリノイ大学アーバナ シャンペーン校 (UIUC) の Zhang Lingming 教師のチームのメンバーです。博士課程4年、研究者
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
LLM に因果連鎖を示すと、LLM は公理を学習します。 AI はすでに数学者や科学者の研究を支援しています。たとえば、有名な数学者のテレンス タオは、GPT などの AI ツールを活用した研究や探索の経験を繰り返し共有しています。 AI がこれらの分野で競争するには、強力で信頼性の高い因果推論能力が不可欠です。この記事で紹介する研究では、小さなグラフでの因果的推移性公理の実証でトレーニングされた Transformer モデルが、大きなグラフでの推移性公理に一般化できることがわかりました。言い換えれば、Transformer が単純な因果推論の実行を学習すると、より複雑な因果推論に使用できる可能性があります。チームが提案した公理的トレーニング フレームワークは、デモンストレーションのみで受動的データに基づいて因果推論を学習するための新しいパラダイムです。
 arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
乾杯!紙面でのディスカッションが言葉だけになると、どんな感じになるでしょうか?最近、スタンフォード大学の学生が、arXiv 論文のオープン ディスカッション フォーラムである alphaXiv を作成しました。このフォーラムでは、arXiv 論文に直接質問やコメントを投稿できます。 Web サイトのリンク: https://alphaxiv.org/ 実際、URL の arXiv を alphaXiv に変更するだけで、alphaXiv フォーラムの対応する論文を直接開くことができます。この Web サイトにアクセスする必要はありません。その中の段落を正確に見つけることができます。論文、文: 右側のディスカッション エリアでは、ユーザーは論文のアイデアや詳細について著者に尋ねる質問を投稿できます。たとえば、次のような論文の内容についてコメントすることもできます。
 リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
最近、2000年代の7大問題の一つとして知られるリーマン予想が新たなブレークスルーを達成した。リーマン予想は、数学における非常に重要な未解決の問題であり、素数の分布の正確な性質に関連しています (素数とは、1 とそれ自身でのみ割り切れる数であり、整数論において基本的な役割を果たします)。今日の数学文献には、リーマン予想 (またはその一般化された形式) の確立に基づいた 1,000 を超える数学的命題があります。言い換えれば、リーマン予想とその一般化された形式が証明されれば、これらの 1,000 を超える命題が定理として確立され、数学の分野に重大な影響を与えることになります。これらの命題の一部も有効性を失います。 MIT数学教授ラリー・ガスとオックスフォード大学から新たな進歩がもたらされる
 無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
現在、次のトークン予測パラダイムを使用した自己回帰大規模言語モデルが世界中で普及していると同時に、インターネット上の多数の合成画像やビデオがすでに拡散モデルの威力を示しています。最近、MITCSAIL の研究チーム (そのうちの 1 人は MIT の博士課程学生、Chen Boyuan です) は、全系列拡散モデルとネクスト トークン モデルの強力な機能を統合することに成功し、トレーニングおよびサンプリング パラダイムである拡散強制 (DF) を提案しました。 )。論文タイトル:DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion 論文アドレス:https:/
