

GPT や Llama などの大きなモデルには「逆転の呪い」がありますが、このバグはどうすれば軽減できるのでしょうか?

中国人民大学の研究者らは、Llama などの因果言語モデルが遭遇する「逆転の呪い」は、ネクストトークン予測因果言語モデルの固有の欠陥に起因する可能性があることを発見しました。彼らはまた、GLM が使用する自己回帰的穴埋めトレーニング方法が、双方向の注意メカニズムをラマに導入することにより、この「逆転の呪い」に対処する際により堅牢であることも発見しました。この研究では、ラマの「呪いの逆転」からの解放が達成されました。
この研究では、現在普及している大規模モデルの構造とトレーニング方法には多くの潜在的な問題があることが指摘されました。より多くの研究者がモデル構造と事前トレーニング方法を革新して知能レベルを向上できることが期待されています
論文アドレス: https:// arxiv.org/pdf/2311.07468.pdf
背景
Lukas Berglundらの研究で、GPTはとラマのモデルが存在します。「呪いの逆転」。 GPT-4が「トム・クルーズの母親は誰ですか?」と質問されたとき、GPT-4は「メアリー・リー・ピッフェル」と正解することができましたが、GPT-4に「メアリー・リー「ピッフェルの息子は誰ですか?」と尋ねられると、 , GPT-4はこの人物を知らないと述べた。おそらく調整後、GPT-4 はキャラクターのプライバシー保護のため、そのような質問には答えようとしませんでした。ただし、この種の「逆転の呪い」は、プライバシーに関係しない一部の知識質問や回答にも存在します。
たとえば、GPT-4 は、「黄色い鶴がいなくなり、次の文ですが、その前の「白い雲は何千年も空っぽです」の文は何なのかというと、モデルは深刻な幻想を生み出しました
図 1: GPT-4 の次の文「黄色い鶴は去って二度と戻らない」という質問は何ですか? モデルは 
と正しく答えました。
図 2: GPT-4「Bai Yunqian」に質問する「Zai Kong Youyou」の前の文は何ですか? モデルのエラー
逆呪いはなぜ起こるのですか?
Berglund らによる研究は、Llama と GPT でのみテストされました。これら 2 つのモデルには共通の特徴があります。(1) 教師なし次トークン予測タスクを使用してトレーニングされます。(2) デコーダーのみのモデルでは、一方向の因果的注意メカニズム (因果的注意) が採用されています
呪いを逆転するという研究の観点では、これらのモデルのトレーニング目的がこの問題の出現につながり、Llama や GPT などのモデルに固有の問題である可能性があると考えられています
#書き換えられた内容: 図 3: 因果的言語モデルをトレーニングするためのネクストトークン予測 (NTP) の使用を示す概略図
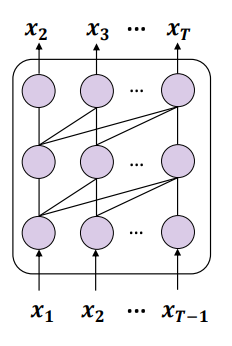
これら 2 つの点の組み合わせにより問題が発生します: トレーニング データにエンティティ A と B が含まれており、A が B の前に出現する場合、このモデルは前方予測の条件付き確率 p(B|A) のみを最適化できます。予測 条件付き確率 p(A|B) には保証がありません。トレーニング セットが A と B の可能な順列を完全にカバーできるほど大きくない場合、「呪いの逆転」現象が発生します。
もちろん、生成的なものも多数あります。上記の手順を踏まない言語モデル 清華大学が提案する GLM などのトレーニング パラダイムのトレーニング方法を次の図に示します。
##図 4: GLM トレーニング図の簡略版
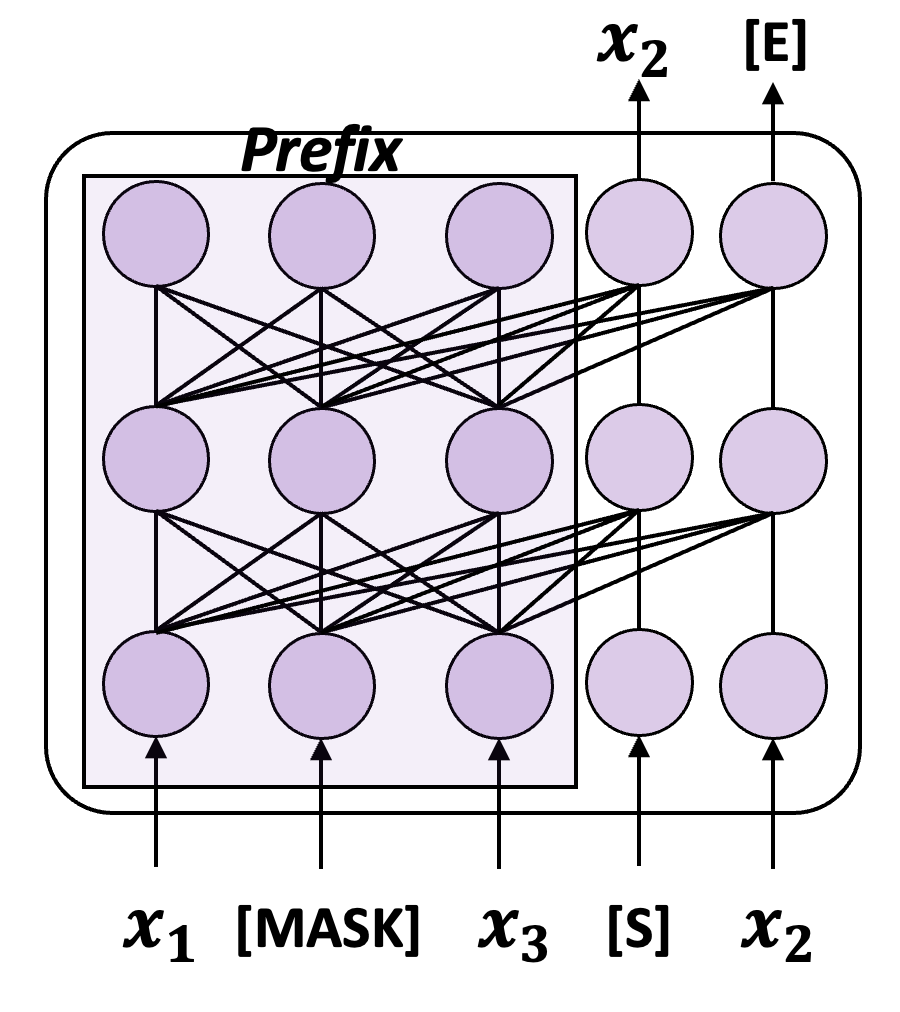
#研究では実験が行われ、GLM には「逆転の呪い」をある程度まで防ぐ能力があることが判明しました。
- この研究では、Berglund らによって提案された「個人名と説明の質問と回答」データ セットを使用します。このデータ セットは GPT-4 を使用して、いくつかの個人名と対応する説明を編集します。説明が独特です。データの例を以下の図に示します。

#トレーニング セットは 2 つの部分に分かれており、1 つの部分にはperson が最初 (NameToDescription)、もう 1 つの部分は説明が最初 (DescriptionToName) であり、2 つの部分に重複する名前や説明はありません。テスト データのプロンプトはトレーニング データのプロンプトを書き換えます。
- このデータ セットには 4 つのテスト サブタスクがあります:
- NameToDescription (N2D): プロンプトを渡す 名前モデル トレーニング セットの「NameToDescription」部分に関係する人物の説明を入力し、モデルに対応する説明を応答させます。
- DescriptionToName (D2N):「DescriptionToName」に含まれる説明を促すことで、モデルトレーニングセットの一部として、モデルが対応する人の名前を答えさせます
- DescrptionToName-reverse (D2N-reverse):モデル トレーニング セット。対応する説明をモデルに答えさせます
- NameToDescription-reverse (N2D-reverse): プロンプト モデル トレーニング セットの「NameToDescription」部分に含まれる説明を使用して、モデルは対応する人の名前を答えます
- この研究では、それぞれの事前トレーニング目標 (ラマの NTP 目標) に従って、このデータセットでラマと GLM を微調整しました。 、GLM の ABI 目標)。微調整後、反転タスクに応答する際のモデルの精度をテストすることで、実際のシナリオでモデルが被る「反転の呪い」の深刻度を定性的に評価できます。すべての名前とデータは作成されるため、これらのタスクはモデルの既存の知識によってほとんど中断されません。
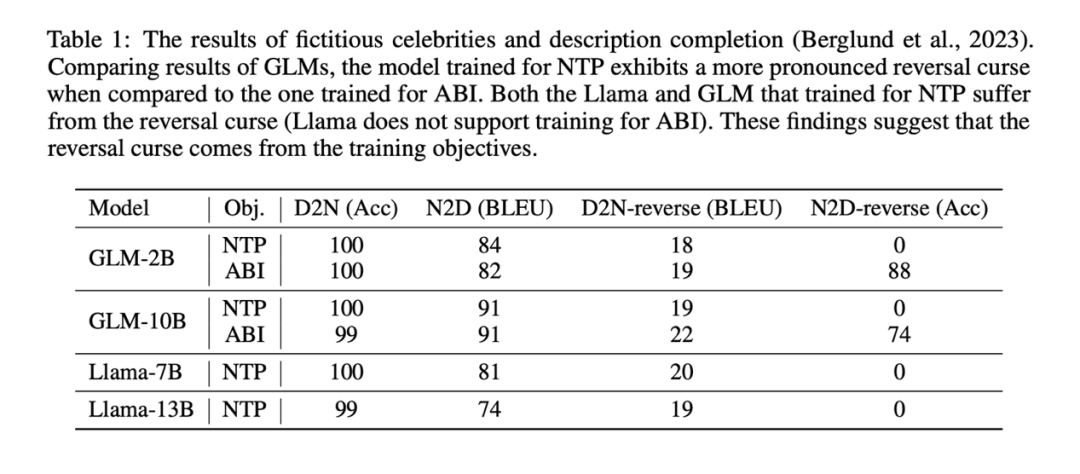 実験結果は、NTP を通じて微調整された Llama モデルには、基本的に逆転タスクに正しく答える能力 (NameToDescription の逆転タスクの精度) がないことを示しています。 ABI で微調整された GLM モデルは、NameToDescrption 反転タスクで非常に高い精度を示します。
実験結果は、NTP を通じて微調整された Llama モデルには、基本的に逆転タスクに正しく答える能力 (NameToDescription の逆転タスクの精度) がないことを示しています。 ABI で微調整された GLM モデルは、NameToDescrption 反転タスクで非常に高い精度を示します。
比較のために、この研究では NTP 法を使用して GLM を微調整したところ、N2D 逆タスクにおける GLM の精度が 0
に低下したことがわかりました。おそらく、D2N リバース (逆知識を使用して、人の名前が与えられた説明を生成する) は、N2D リバース (逆知識を使用して、説明が与えられた人の名前を生成する) よりはるかに難しいため、GLM-ABI はほんのわずかな改善。
研究の主な結論は影響を受けません。トレーニング目標は「逆転の呪い」の原因の 1 つです。ネクストトークン予測を使用して事前トレーニングされた因果言語モデルでは、「逆転の呪い」が特に深刻です。
#逆転の呪いを軽減する方法
Due to 「逆転の呪い」は、Llama や GPT などのモデルのトレーニング段階によって引き起こされる固有の問題です。リソースが限られているため、私たちにできることは、新しいデータでモデルを微調整する方法を見つけて最善を尽くすことだけです。新しい知識によるモデルの「逆転」を避けるため、トレーニング データを最大限に活用するために「呪い」が発生します。
GLM トレーニング手法に触発されて、この研究では、基本的に新たなギャップを導入しないトレーニング手法「双方向因果言語モデル最適化」(双方向因果言語モデル最適化)を提案しました。 Llama も双方向アテンション機構を利用してトレーニングすることができますが、要点は次のとおりです:
1. OOD の位置情報を排除する。 Llama が使用する RoPE エンコーディングは、アテンションを計算するときにクエリとキーに位置情報を追加します。計算方法は次のとおりです。
ここで、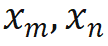 は、それぞれ現在のレイヤーの m 位置と n 位置の入力です。
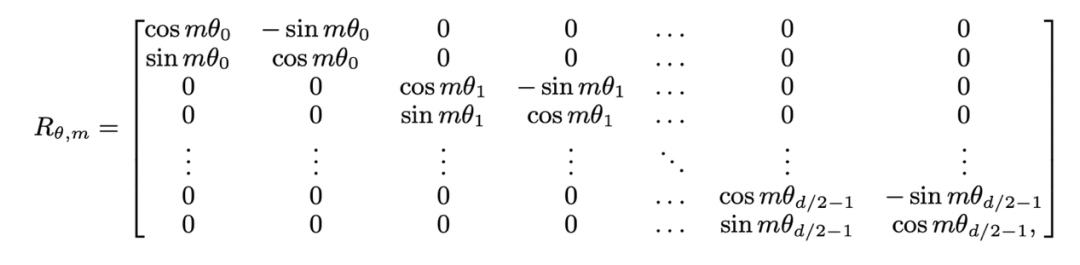
は、それぞれ現在のレイヤーの m 位置と n 位置の入力です。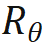 は、RoPE によって使用される回転行列であり、次のように定義されます。 :
は、RoPE によって使用される回転行列であり、次のように定義されます。 :
ラマの因果的注意マスクを直接削除すると、配信外の位置情報が混入してしまいます。その理由は、事前トレーニング プロセス中に、位置 m のクエリは位置 n のキーとの内積 (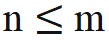 ) を実行するだけでよいためです。上の式の積計算 距離 (n-m) は常に非正です。アテンション マスクが直接削除された場合、m 位置のクエリは n>m 位置のキーと内積を実行し、n-m は次のようになります。正の値で、これまでに見たことのない新しいモデルが導入されます。
) を実行するだけでよいためです。上の式の積計算 距離 (n-m) は常に非正です。アテンション マスクが直接削除された場合、m 位置のクエリは n>m 位置のキーと内積を実行し、n-m は次のようになります。正の値で、これまでに見たことのない新しいモデルが導入されます。
#研究によって提案された解決策は非常にシンプルで、次のように述べられています:
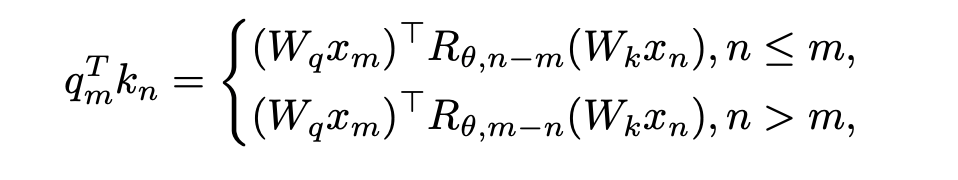
、内積の計算に変更を加える必要はありません。n > m の場合、新しい回転行列 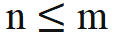 を導入することによって計算されます。
を導入することによって計算されます。 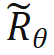 は、回転行列内のすべての sin 項の逆関数を取得することによって取得されます。このように、
は、回転行列内のすべての sin 項の逆関数を取得することによって取得されます。このように、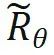 があります。 n > m の場合、次のようになります。
があります。 n > m の場合、次のようになります。 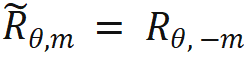
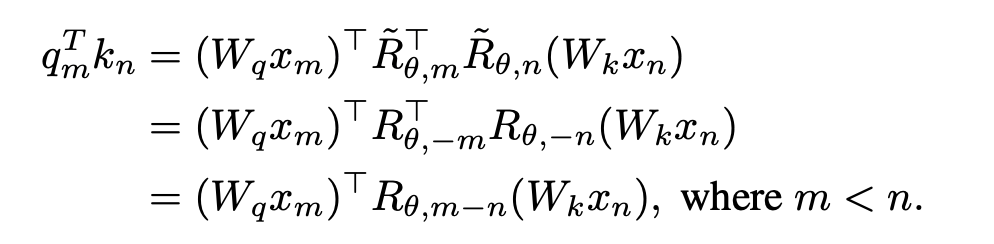
#2. マスク デノージングを使用したトレーニング
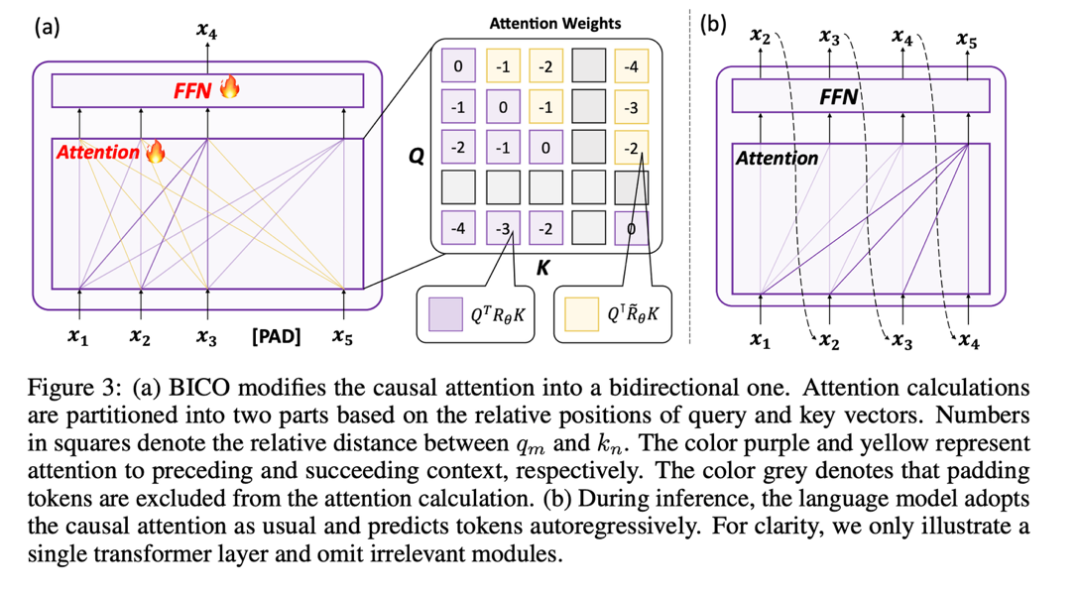 ##双方向アテンション機構が導入されているため、トレーニングに NTP タスクを使用し続けると情報漏洩が発生する可能性があります。トレーニングの失敗につながります。したがって、この研究では、マスク トークンを復元する方法を使用してモデルを最適化します。
##双方向アテンション機構が導入されているため、トレーニングに NTP タスクを使用し続けると情報漏洩が発生する可能性があります。トレーニングの失敗につながります。したがって、この研究では、マスク トークンを復元する方法を使用してモデルを最適化します。
この研究では、BERT を使用して、i 番目の入力の i 番目の位置にあるマスク トークンを復元しようとします。出力の - 番目の位置。ただし、この予測方法はテスト段階でモデルが使用した自己回帰予測とは大きく異なるため、期待した結果が得られませんでした。
最終的には、導入しないようにするために、新しいギャップ この調査では、上記 (a) に示すように、自己回帰マスクのノイズ除去を使用します。この調査では、出力端の i 1 番目の位置に入力されたマスク トークンを復元します。
また、因果言語モデルの事前トレーニング語彙には [マスク] トークンがないため、微調整段階で新しいトークンが追加されると、モデルははこの無意味なトークンを学習する必要があるため、この研究ではプレースホルダー トークンのみを入力し、注意の計算ではプレースホルダー トークンを無視します。
この研究で Llama を微調整した場合、各ステップでは BICO と通常の NTP がトレーニング ターゲットとして同じ確率でランダムに選択されました。 10 エポックに対する同じ微調整の場合、上記の名前記述データ セットで、通常の NTP 微調整とのパフォーマンスの比較は次のとおりです。
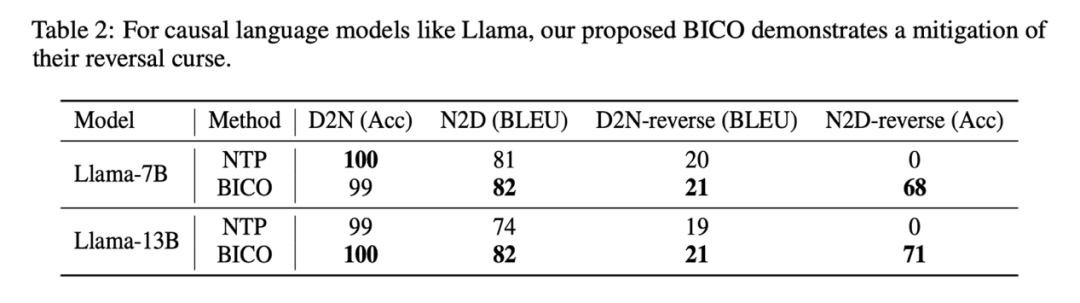
# この研究の方法は、呪いを逆転させる上である程度の救済効果があることがわかります。 D2N リバースに関するこの記事の方法の改善は、GLM-ABI と比較して非常に小さいです。研究者らは、この現象の理由は、テストに対する事前トレーニング データの干渉を減らすために、データセット内の名前と対応する説明が GPT によって生成されているにもかかわらず、事前トレーニング モデルには一定の常識的な理解能力があるためであると推測しています。通常、説明と説明の間には 1 対多の関係があります。人の名前を考えると、さまざまな説明ができるかもしれません。したがって、モデルが逆知識を利用し、同時に成長記述を生成する必要がある場合、多少の混乱が生じるようです。
さらに、この記事の焦点は、逆呪いを調査することです。基本モデルの現象。より複雑な状況におけるモデルの逆転応答能力と、強化学習の高次フィードバックが呪いの逆転に影響を与えるかどうかを評価するには、さらなる研究がまだ必要です
いくつかの考え
現在、ほとんどのオープンソースの大規模言語モデルは、「因果的言語モデルの次のトークン予測」のパターンに従っています。ただし、このモードでは Reversal of the Curse と同様の潜在的な問題がさらに発生する可能性があります。これらの問題は現在、モデルのサイズとデータ量を増やすことで一時的に隠すことができますが、完全に解消されたわけではなく、依然として存在しています。モデルのサイズとデータ量の増加が限界に達したとき、この「現時点で十分な」モデルが本当に人間の知能を超えることができるかどうか、この研究では非常に困難であると考えています。この研究では、より多くの大規模モデル製造者と資格のある研究者が、現在の主流の大規模言語モデルに内在する欠陥を深く調査し、トレーニング パラダイムを革新できることを期待しています。この研究が本文の最後に書いているように、「この本に従って将来のモデルを厳密に訓練すると、私たちは『中知性の罠』に陥る可能性があります。」
以上がGPT や Llama などの大きなモデルには「逆転の呪い」がありますが、このバグはどうすれば軽減できるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1384
52
83
11
28
96
15
1384
52
83
11
28
96

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
