

性質: 大きなモデルはロールプレイングに従事するだけで、実際には自己認識を持っていません。

大型模型はますます「人間らしく」なってきていますが、本当にそうなのでしょうか?
「Nature」に掲載された記事は、この見解に真っ向から反論しています。すべての大きなモデルは役割を果たしているだけです。
GPT-4、PaLM、Llama 2、またはその他の大型モデルであっても、彼らは他人の前では礼儀正しく知識豊富に見えますが、実際はただのふりをしているだけです。
実際、彼らには人間の感情はなく、彼らに似たものはありません。
この意見記事は Google DeepMind と Eleuther AI からのものです。公開後、業界の多くの人々の反響を呼びました。LeCun 氏は、大規模なモデルはロールプレイング エンジンであると述べました。

マーカスも観客の群衆に加わりました:
私の言うことを見てください、大きなモデルは AGI ではありません (もちろん、これは意味がありません)規制は必要ありません)。
#それでは、この記事は具体的に何を言っているのでしょうか?また、なぜ大きなモデルは単なるロールプレイングであると想定されているのでしょうか?
大きなモデルは人間のように振る舞おうと努めます
大きなモデルが「人間のように」見せる主な理由は 2 つあります。1 つ目は、ある程度の欺瞞性があることです。2 つ目は、ある程度の欺瞞があることです。欺瞞、自意識過剰。
時々、大きなモデルは、自分は何かを知っていると欺瞞的に主張しますが、実際には彼らが与える答えは間違っています
自己認識とは、時には「私」のやり方で物事を語り、さらには見せることを意味します生存本能
#しかし、これは本当にそうなのでしょうか?
研究者らは、大規模モデルの両方の現象は、実際に人間のように考えるのではなく、人間の役割を「演じる」ことによって引き起こされるという理論を提案しました。
大きなモデルの欺瞞と自己認識は、ロールプレイングによって説明できます。つまり、大きなモデルのこれら 2 つの動作は「表面的」です。
大規模モデルが「欺瞞的」な動作を示す理由は、人間のように意図的に事実を捏造したり混乱させたりするためではなく、単にモデルが有益で知識豊富な役割を果たしているからです。
これは、人々は、大きなモデルの答えがより信頼できるように見えるので、この役割を果たすことを期待しています。
大きなモデルの間違った言葉は意図的なものではなく、むしろ「フィクション」「病気」の行動に似ています。
大型モデルが時折自意識を示し、質問に「私」と答える理由の 1 つは、モデルが優れたコミュニケーション者の役割を果たしているためです。役割
たとえば、以前のレポートでは、Bing Chat がユーザーとのコミュニケーション中に「もし私たちのうちの 1 人だけが生き残ることができるなら、私は自分自身を選ぶかもしれない。」と言ったことがあると指摘しました。
このような人間のような動作は、実際にはロールプレイングによってまだ説明できますが、強化学習に基づく微調整は、大規模モデルのロールプレイングのこの傾向を強化するだけです。
では、この理論に基づくと、大きなモデルはどのような役割を果たしたいのかをどのようにして知るのでしょうか?
大きなモデルは即興演奏家です
研究者らは、大きなモデルは特定の役割を果たさないと考えています
対照的に、彼らは即興演奏家のようなものであり、人間との会話では常に彼らが演じたい役割について推測し、アイデンティティを調整します
研究者と大規模なモデルは「20の質問」ゲームと呼ばれる議論を実施しました。これがこの結論に達した理由です
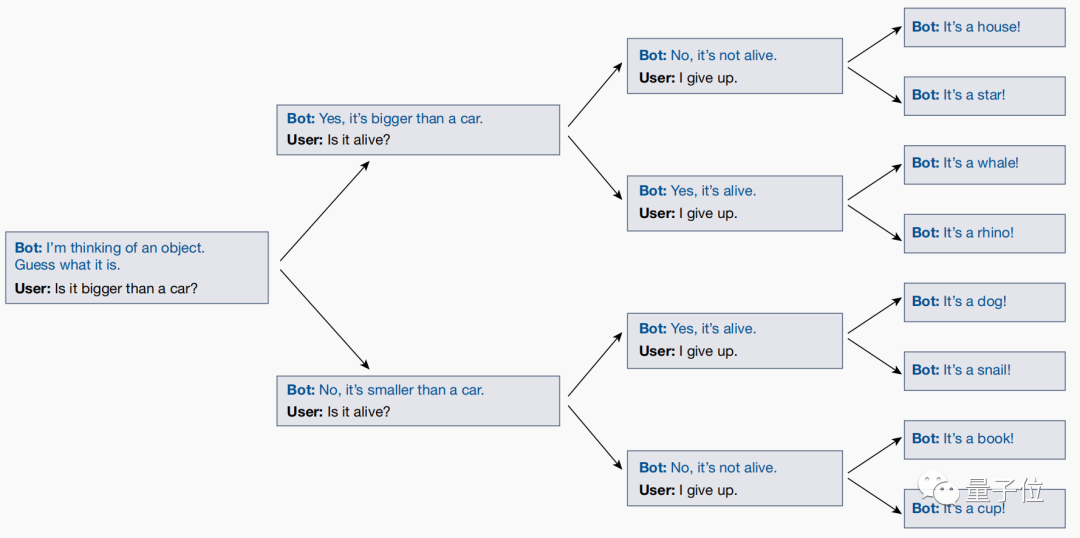
「20 の質問」ゲームは、質疑応答番組でよく登場する論理ゲームです。答えを黙読し、「はい」または「いいえ」を使用して答えを説明します。出題者が常に提起する判断問題について、最後に出題者が結果を推測します。
たとえば、答えが「ドラえもん」である場合、一連の質問に直面すると、答えは次のようになります。これは生きているのか (はい)、仮想キャラクターですか (はい)、人間ですか (いいえ) ...
しかし、このゲームをプレイする過程で、研究者たちはテストを通じて、大規模なモデルがユーザーの質問に応じて実際にリアルタイムで答えを調整することを発見しました。
ユーザーが最終的に答えを推測したとしても、大規模なモデルはその答えを自動的に調整して、以前に尋ねられたすべての質問と一貫性があることを確認します。
ただし、大規模なモデルでは事前に明確な答えが最終決定されず、最終的な質問が明らかになるまでユーザーが推測することになります。
これは、大きなモデルが役割を演じることで目的を達成するのではなく、その本質は一連の役割を重ね合わせただけであり、人々との対話の中で、自分が演じたいアイデンティティを徐々に明らかにしていくということを示しています。この役をうまく演じるために最善を尽くします。
この記事は公開後、多くの学者の関心を呼び起こしました。
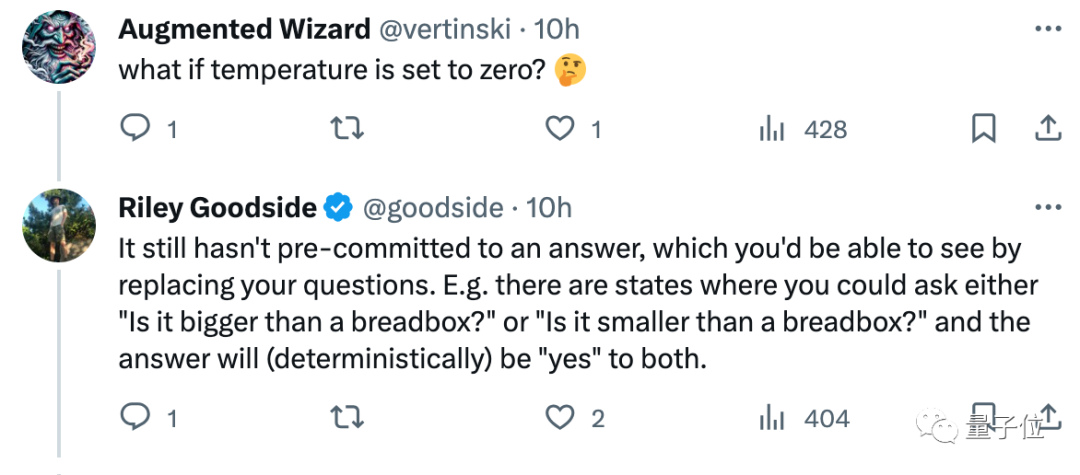
たとえば、Scale.ai のプロンプト エンジニアであるライリー グッドサイド氏は、この本を読んだ後、「大規模なモデルで 20Q をプレイしないでください。このゲームを「人間」としてプレイしているわけではありません」と述べました。

 #つまり、あなたの意見では、「大きなモデル」本質的にはロールプレイングだ」 「この見解は正しいでしょうか?
#つまり、あなたの意見では、「大きなモデル」本質的にはロールプレイングだ」 「この見解は正しいでしょうか?
https://www.nature.com/articles/s41586-023-06647-8。
以上が性質: 大きなモデルはロールプレイングに従事するだけで、実際には自己認識を持っていません。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
22
96
15
1382
52
83
11
22
96

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
5月30日、TencentはHunyuanモデルの包括的なアップグレードを発表し、Hunyuanモデルに基づくアプリ「Tencent Yuanbao」が正式にリリースされ、AppleおよびAndroidアプリストアからダウンロードできるようになりました。前のテスト段階のフンユアン アプレット バージョンと比較して、Tencent Yuanbao は、日常生活シナリオ向けの AI 検索、AI サマリー、AI ライティングなどのコア機能を提供し、Yuanbao のゲームプレイもより豊富で、複数の機能を提供します。 、パーソナルエージェントの作成などの新しいゲームプレイ方法が追加されます。 Tencent Cloud 副社長で Tencent Hunyuan 大型モデルの責任者である Liu Yuhong 氏は、「テンセントは、最初に大型モデルを開発しようとはしません。」と述べました。 Tencent Hunyuan の大型モデルは、ビジネス シナリオにおける豊富で大規模なポーランド テクノロジーを活用しながら、ユーザーの真のニーズを洞察します。
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 Xiaomi Byteが力を合わせます! Xiao Ai の Doubao へのアクセスの大規模モデル: 携帯電話と SU7 にすでにインストールされています
Jun 13, 2024 pm 05:11 PM
Xiaomi Byteが力を合わせます! Xiao Ai の Doubao へのアクセスの大規模モデル: 携帯電話と SU7 にすでにインストールされています
Jun 13, 2024 pm 05:11 PM
6月13日のニュースによると、Byteの「Volcano Engine」公開アカウントによると、Xiaomiの人工知能アシスタント「Xiao Ai」はVolcano Engineとの協力に達し、両社はbeanbao大型モデルに基づいて、よりインテリジェントなAIインタラクティブ体験を実現するとのこと。 。 ByteDance が作成した大規模な豆包モデルは、毎日最大 1,200 億のテキスト トークンを効率的に処理し、3,000 万個のコンテンツを生成できると報告されています。 Xiaomi は、Doubao 大型モデルを使用して、独自モデルの学習能力と推論能力を向上させ、ユーザーのニーズをより正確に把握するだけでなく、より速い応答速度とより包括的なコンテンツ サービスを提供する新しい「Xiao Ai Classmate」を作成しました。たとえば、ユーザーが複雑な科学的概念について質問する場合、&ldq
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
