

高品質画像生成への新たな一歩: Google の UFOGen 超高速サンプリング手法

昨年、Stable Diffusion に代表される一連の Vincentian グラフ拡散モデルは、ビジュアル制作の分野を完全に変えました。数え切れないほどのユーザーが、拡散モデルによって生成された画像を使用して生産性を向上させてきました。ただし、拡散モデルの生成速度は一般的な問題です。ノイズ除去モデルは、初期ガウス ノイズを徐々に画像に変換するマルチステップのノイズ除去に依存しているため、ネットワークの複数の計算が必要となり、生成速度が非常に遅くなります。 これにより、大規模なヴィンセント グラフ拡散モデルは、リアルタイム性と対話性を重視する一部のアプリケーションにとって非常に不向きなものになります。 一連のテクノロジーの導入により、拡散モデルからサンプリングするために必要なステップ数は、最初の数百ステップから数十ステップ、さらにはわずか 4 ~ 8 ステップに増加しました。
最近、Google の研究チームは、極めて迅速にサンプリングできる拡散モデルの変形である UFOGen モデルを提案しました。 論文で提案されている方法で安定拡散を微調整することで、UFOGen はわずか 1 ステップで高品質の画像を生成できます。同時に、グラフ生成や ControlNet などの Stable Diffusion の下流アプリケーションも保持できます。

# 論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2311.09257
# #下の図からわかるように、UFOGen はたった 1 ステップで高品質で多様な画像を生成できます。

1 つの方向性は、より少ない離散ステップを使用して拡散モデルのサンプリング ODE を解くという目的を達成するために、より効率的な数値計算方法を設計することです。たとえば、清華大学の Zhu Jun のチームが提案した DPM シリーズの数値ソルバーは、安定拡散において非常に効果的であることが検証されており、DDIM のデフォルトの 50 ステップから解のステップ数を 20 ステップ未満に大幅に削減できます。 もう 1 つの方向は、知識蒸留法を使用してモデルの ODE ベースのサンプリング パスをより少ないステップ数に圧縮することです。 この方向の例としては、CVPR2023 の最良の論文候補の 1 つであるガイド付き蒸留と、最近人気のある潜在一貫性モデル (LCM) があります。特に LCM は、一貫性ターゲットを絞り出すことでサンプリング ステップの数をわずか 4 に減らすことができ、これにより多くのリアルタイム生成アプリケーションが生み出されてきました。 ただし、Google の研究チームは、UFOGen モデルにおける上記の一般的な方向性には従わず、別のアプローチを採用し、
拡散モデルと GAN が提案したものを組み合わせて使用しました。 1 年以上前。モデルのアイデア。彼らは、前述の ODE ベースのサンプリングと蒸留には根本的な限界があり、サンプリング ステップ数を限界まで圧縮するのは難しいと考えています。したがって、ワンステップ生成の目標を達成したい場合は、新しいアイデアを開拓する必要があります。 ハイブリッド モデルとは、拡散モデルと敵対的生成ネットワーク (GAN) を組み合わせた手法を指します。この手法は、ICLR 2022 で NVIDIA の研究チームによって初めて提案され、DDGAN (「生成学習における 3 つの問題を解決するためのノイズ除去拡散 GAN の使用」) と呼ばれています。 DDGAN は、ノイズ リダクション分布についてガウス仮定を行う通常の拡散モデルの欠点からインスピレーションを受けています。簡単に言うと、拡散モデルは、ノイズ除去分布 (ノイズの多いサンプルが与えられた場合に、よりノイズの少ないサンプルを生成する条件付き分布) が単純なガウス分布であると仮定します。ただし、確率微分方程式の理論では、このような仮定が当てはまるのは、ノイズ リダクションのステップ サイズが 0 に近づいた場合のみであることが証明されています。したがって、拡散モデルでは、ノイズ除去ステップ サイズを小さくするために、多数のノイズ除去ステップを繰り返す必要があり、その結果、生成速度が遅くなります。
DDGAN は、ノイズ除去のガウス仮定を放棄することを提案しています。代わりに、条件付き GAN を使用して、このノイズ低減分布をシミュレートします。 GAN は非常に強力な表現機能を備えており、複雑な分布をシミュレートできるため、より大きなノイズ低減ステップ サイズを使用してステップ数を減らすことができます。ただし、DDGAN は拡散モデルの安定した再構成トレーニング目標を GAN のトレーニング目標に変更するため、トレーニングが不安定になりやすく、より複雑なタスクへの拡張が困難になる可能性があります。 NeurIPS 2023 では、UGOGen を作成したのと同じ Google 研究チームが SIDDM (論文タイトル Semi-Implicit Denoising Diffusion Models) を提案しました。これにより、DDGAN のトレーニング目標に再構成目的関数が再導入され、トレーニングがより安定し、生成品質が大幅に向上しました。 DDGANと比較して改善されました。
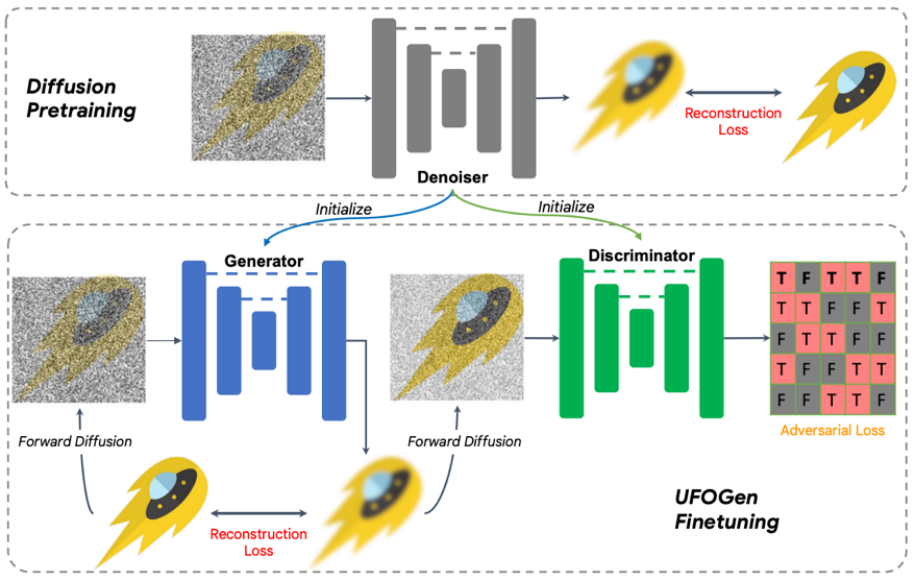
SIDDM は UFOGen の前身であり、わずか 4 ステップで CIFAR-10、ImageNet、その他の研究データ セット上に高品質の画像を生成できます。しかし SIDDM には解決すべき 2 つの問題があります: 第一に、理想的な条件をワンステップで生成することができないこと、第二に、より注目を集めているビンセント グラフの分野に拡張することは簡単ではありません。 この目的を達成するために、Google の研究チームは、これら 2 つの問題を解決するために UFOGen を提案しました。 具体的には、質問 1 について、チームは簡単な数学的分析を通じて、ジェネレータのパラメータ化方法を変更し、再構成損失関数の計算方法を変更することで、上記の理論が適用されることを発見しました。モデルはワンステップで生成できます。質問 2 では、チームは初期化に既存の安定拡散モデルを使用して、UFOGen モデルをより迅速かつ適切に Vincent ダイアグラム タスクに拡張できるようにすることを提案しました。 SIDDM はジェネレーターとディスクリミネーターの両方が UNet アーキテクチャを採用することを提案しているため、この設計に基づいて、UFOGen のジェネレーターとディスクリミネーターは安定拡散モデルによって初期化されます。そうすることで、Stable Diffusion の内部情報、特に画像とテキストの関係が最大限に活用されます。このような情報は、敵対的学習からは取得することが困難です。トレーニングアルゴリズムと図を以下に示します。 これより前に、GAN を使用してヴィンセント グラフを実行する作業がいくつかあったことは注目に値します。 NVIDIA StyleGAN-T と Adobe の GigaGAN はどちらも StyleGAN の基本アーキテクチャをより大規模に拡張し、ワンステップでグラフを生成できるようにします。 UFOGen の作者は、以前の GAN ベースの研究と比較して、生成品質に加えて、UFOGen にはいくつかの利点があると指摘しました: 書き直された内容: 1. ヴィンセント グラフ タスクでは、純粋なGenerative Adversarial Network (GAN) トレーニングは非常に不安定です。識別器は画像のテクスチャを判断する必要があるだけでなく、画像とテキストの一致の程度を理解する必要もありますが、これは特にトレーニングの初期段階では非常に困難な作業です。したがって、GigaGAN などの以前の GAN モデルでは、トレーニングを支援するために多数の補助損失が導入されており、トレーニングとパラメーター調整が非常に困難でした。しかし、UFOGen は、再構築ロスを導入することで GAN をこの点でサポートする役割を果たし、非常に安定したトレーニングを実現します 2. GAN をゼロから直接トレーニングすることは不安定であるだけでなく、異常に高価です。特に、大量のデータとトレーニング ステップを必要とする Vincent プロットのようなタスクの場合はそうです。 2 セットのパラメーターを同時に更新する必要があるため、GAN のトレーニングは拡散モデルよりも多くの時間とメモリを消費します。 UFOGen の革新的な設計により、安定拡散からパラメータを初期化できるため、トレーニング時間を大幅に節約できます。通常、収束には数万のトレーニング ステップのみが必要です。 3. ヴィンセント グラフの拡散モデルの魅力の 1 つは、グラフなどの微調整を必要としないアプリケーションやアプリケーションなど、他のタスクにも適用できることです。制御された生成など、すでに微調整が必要な場合。以前の GAN モデルは、GAN の微調整が困難であったため、これらの下流タスクに合わせて拡張することが困難でした。対照的に、UFOGen には拡散モデルのフレームワークがあるため、これらのタスクにより簡単に適用できます。以下の図は、UFOGen のグラフ生成グラフと制御可能な生成の例を示しています。これらの生成には 1 ステップのサンプリングのみが必要であることに注意してください。 実験の結果、UFOGen では、テキストの説明に準拠した高品質の画像を生成するためにサンプリングの 1 ステップのみが必要であることがわかりました。最近提案されている拡散モデル用の高速サンプリング手法 (Instaflow や LCM など) と比較して、UFOGen は強力な競争力を示します。 50 ステップのサンプリングを必要とする Stable Diffusion と比較しても、UFOGen で生成されたサンプルは見た目に劣りません。いくつかの比較結果を次に示します。 Google チームは、UFOGen 強力モデルと呼ばれる手法を提案しました。 、既存の普及モデルと GAN のハイブリッド モデルを改良することで実現されます。このモデルは安定拡散によって微調整されており、ワンステップでグラフを生成する機能を確保しながら、さまざまな下流アプリケーションにも適しています。超高速のテキストから画像への合成を実現するための初期の作品の 1 つとして、UFOGen は高効率の生成モデルの分野に新しい道を切り開きました


概要
以上が高品質画像生成への新たな一歩: Google の UFOGen 超高速サンプリング手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
39
15
1377
52
77
11
19
39

 SQLに新しい列を追加する方法
Apr 09, 2025 pm 02:09 PM
SQLに新しい列を追加する方法
Apr 09, 2025 pm 02:09 PM
Alter Tableステートメントを使用して、SQLの既存のテーブルに新しい列を追加します。特定の手順には、テーブル名と列情報の決定、テーブルステートメントの変更、およびステートメントの実行が含まれます。たとえば、顧客テーブルに電子メール列を追加します(Varchar(50)):Alter Table Customersはメール(50)を追加します。
 SQLに列を追加するための構文は何ですか
Apr 09, 2025 pm 02:51 PM
SQLに列を追加するための構文は何ですか
Apr 09, 2025 pm 02:51 PM
sqlに列を追加するための構文は、table table_name add column_name data_type [not null] [default default_value];です。 table_nameはテーブル名、column_nameは新しい列名、data_typeはデータ型であり、nullはnull値が許可されているかどうかを指定しない、デフォルトのdefault_valueがデフォルト値を指定します。
 SQLクリアテーブル:パフォーマンスの最適化のヒント
Apr 09, 2025 pm 02:54 PM
SQLクリアテーブル:パフォーマンスの最適化のヒント
Apr 09, 2025 pm 02:54 PM
SQLテーブルクリアパフォーマンスを改善するためのヒント:削除の代わりにTruncateテーブルを使用し、スペースを解放し、ID列をリセットします。カスケードの削除を防ぐために、外部のキーの制約を無効にします。トランザクションカプセル化操作を使用して、データの一貫性を確保します。バッチはビッグデータを削除し、制限で行数を制限します。クリアリング後にインデックスを再構築して、クエリ効率を改善します。
 sqlに列を追加するときにデフォルト値を設定する方法
Apr 09, 2025 pm 02:45 PM
sqlに列を追加するときにデフォルト値を設定する方法
Apr 09, 2025 pm 02:45 PM
新しく追加された列のデフォルト値を設定します。3つのテーブルステートメントを使用します。列の追加を指定し、デフォルト値を設定します:table table_name add column_name data_type default_valueを変更します。制約句を使用してデフォルト値を指定します。テーブルテーブルを変更する列列の追加column_name data_type constraint default_constraint default default_value;
 削除ステートメントを使用して、SQLテーブルをクリアします
Apr 09, 2025 pm 03:00 PM
削除ステートメントを使用して、SQLテーブルをクリアします
Apr 09, 2025 pm 03:00 PM
はい、削除ステートメントを使用してSQLテーブルをクリアできます。手順は次のとおりです。クリアするテーブルの名前にtable_nameを置き換えます。
 Redisメモリの断片化に対処する方法は?
Apr 10, 2025 pm 02:24 PM
Redisメモリの断片化に対処する方法は?
Apr 10, 2025 pm 02:24 PM
Redisメモリの断片化とは、再割り当てできない割り当てられたメモリ内に小さな自由領域の存在を指します。対処戦略には、Redisの再起動:メモリを完全にクリアしますが、サービスを割り当てます。データ構造の最適化:Redisに適した構造を使用して、メモリの割り当てとリリースの数を減らします。構成パラメーターの調整:ポリシーを使用して、最近使用されていないキー価値ペアを排除します。永続性メカニズムを使用します:データを定期的にバックアップし、Redisを再起動してフラグメントをクリーンアップします。メモリの使用量を監視する:問題をタイムリーに発見し、対策を講じる。
 phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpMyAdminを使用してデータテーブルを作成するには、次の手順が不可欠です。データベースに接続して、[新しいタブ]をクリックします。テーブルに名前を付けて、ストレージエンジンを選択します(InnoDB推奨)。列名、データ型、null値、その他のプロパティを許可するかどうかなど、列の追加ボタンをクリックして列の詳細を追加します。一次キーとして1つ以上の列を選択します。 [保存]ボタンをクリックして、テーブルと列を作成します。
 Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースを作成するのは簡単ではありません。根本的なメカニズムを理解する必要があります。 1.データベースとOracle DBMSの概念を理解する必要があります。 2。SID、CDB(コンテナデータベース)、PDB(プラグ可能なデータベース)などのコアコンセプトをマスターします。 3。SQL*Plusを使用してCDBを作成し、PDBを作成するには、サイズ、データファイルの数、パスなどのパラメーターを指定する必要があります。 4.高度なアプリケーションは、文字セット、メモリ、その他のパラメーターを調整し、パフォーマンスチューニングを実行する必要があります。 5.ディスクスペース、アクセス許可、パラメーター設定に注意し、データベースのパフォーマンスを継続的に監視および最適化します。 それを巧みに習得することによってのみ、継続的な練習が必要であることは、Oracleデータベースの作成と管理を本当に理解できます。
