

この記事の主な焦点は、RAG の概念と理論です。次に、LangChain、OpenAI 言語モデル、および Weaviate ベクトル データベースを使用して、シンプルな RAG オーケストレーション システムを実装する方法を示します。
検索拡張生成 (RAG) の概念は、外部知識ソースを通じて LLM に追加情報を提供することを指します。これにより、LLM は幻覚を軽減しながら、より正確で状況に応じた回答を生成できます。
#コンテンツを書き換える場合、元の文章をそのまま中国語に書き直す必要があります。
#現時点でのベストLLM は大量のデータを使用してトレーニングされるため、大量の一般知識 (パラメーター メモリ) がニューラル ネットワークの重みに保存されます。ただし、プロンプトで LLM がトレーニング データ以外の知識 (新しい情報、独自のデータ、ドメイン固有の情報など) を必要とする結果を生成する必要がある場合、事実の不正確さが発生する可能性があります。以下のスクリーンショットに示すように、元の文なしで中国語に書き直されました (錯覚):
したがって、これは重要なのは、LLM の一般的な知識と追加のコンテキストを組み合わせて、幻覚を減らし、より正確で状況に応じた結果を生成することです。
ソリューション
従来、モデルを微調整してニューラル ネットワークを特定のドメインや独自情報に適応させることができました。このテクノロジーは効果的ではありますが、大規模なコンピューティング リソースを必要とし、高価であり、技術専門家のサポートが必要なため、変化する情報に迅速に適応することが困難になります。の論文「知識集約型 NLP タスクのための検索拡張生成」では、より柔軟なテクノロジである検索拡張生成 (RAG) が提案されています。この論文では、研究者らは生成モデルと、より簡単に更新できる外部知識ソースを使用して追加情報を提供できる検索モジュールを組み合わせました。
専門用語で言うと、LLM にとっての RAG は、人間にとってのオープンブック試験と同じです。オープンブック試験の場合、学生は教科書やノートなどの参考資料を持参して、質問に答えるための関連情報を見つけることができます。オープンブック試験の背後にある考え方は、試験では学生の特定の情報を記憶する能力ではなく、推論する能力に焦点を当てるというものです。
#同様に、事実に関する知識は LLM 推論機能とは異なり、簡単にアクセスして更新できる外部知識ソースに保存できます
パラメータ化された知識: トレーニング中に学習した知識は、ニューラル ネットワークの重みに暗黙的に保存されます。
書き換えられたコンテンツ: ワークフロー検索拡張生成 (RAG) の再構築用
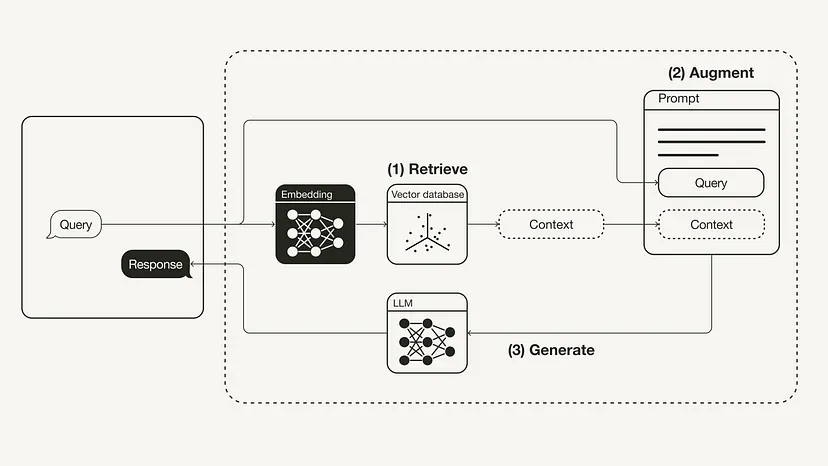
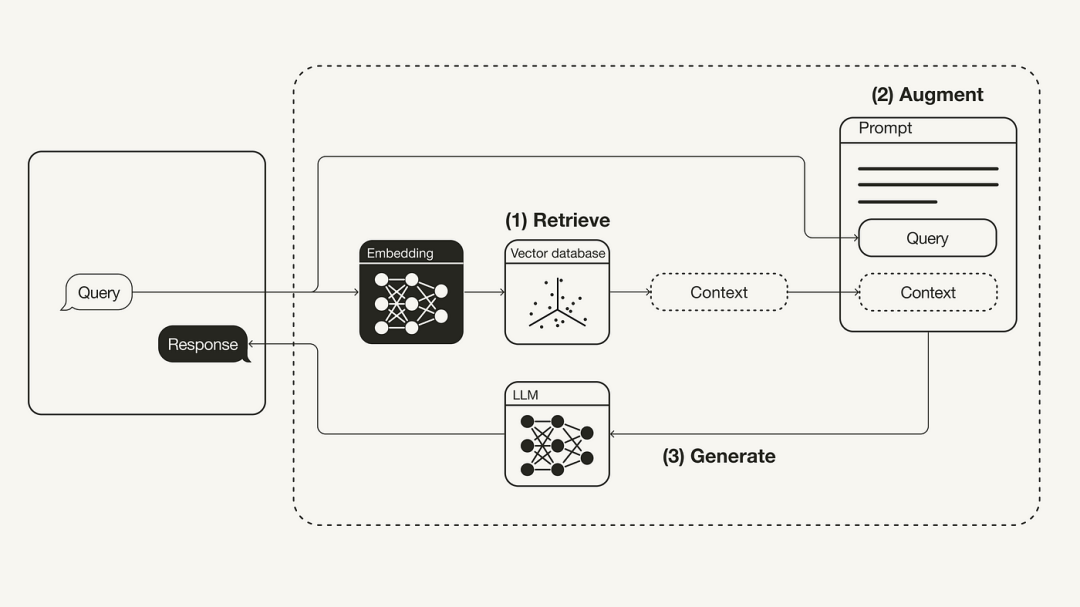
# 検索: ユーザー クエリを使用して、外部の知識ソースから関連するコンテキストを取得します。これを行うには、埋め込みモデルを使用して、ユーザー クエリをベクトル データベース内の追加のコンテキストとして同じベクトル空間に埋め込みます。これにより、類似性検索を実行し、このベクトル データベース内でユーザー クエリに最も近い k データ オブジェクトを返すことができます。
言い換えてください: 必須の前提条件
必要な Python パッケージがインストールされていることを確認してください:
#!pip install langchain openai weaviate-client
OPENAI_API_KEY="<your_openai_api_key>"</your_openai_api_key>
import dotenvdotenv.load_dotenv()
準備作業
#準備フェーズでは、外部知識としてベクトルデータベースを準備する必要がありますソース。すべての追加情報を保存するために使用されます。このベクトル データベースの構築には、次の手順が含まれます。
元のドキュメントのアドレス: https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/ state_of_the_union.txt
import requestsfrom langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"res = requests.get(url)with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')documents = loader.load()
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Weaviateimport weaviatefrom weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions())vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False)
ステップ 1: 取得
ベクター データベースにデータを書き込んだ後、次のことができます。これは、ユーザー クエリと埋め込みブロックの間の意味論的な類似性に基づいて追加のコンテキストを取得できる取得コンポーネントとして定義されています。retriever = vectorstore.as_retriever()
ステップ 2: 強化 from langchain.prompts import ChatPromptTemplatetemplate = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: {question} Context: {context} Answer:"""prompt = ChatPromptTemplate.from_template(template)print(prompt)
ステップ 3: 生成
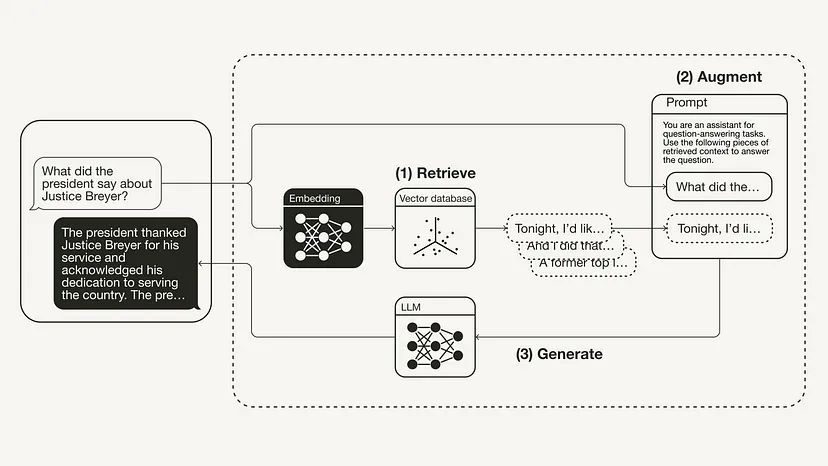
最後に、思考チェーンを構築してリンクします。レトリーバー、プロンプト テンプレート、LLM を組み合わせます。 RAG チェーンが定義されると、それを呼び出すことができます。from langchain.chat_models import ChatOpenAIfrom langchain.schema.runnable import RunnablePassthroughfrom langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": retriever,"question": RunnablePassthrough()} | prompt | llm| StrOutputParser() )query = "What did the president say about Justice Breyer"rag_chain.invoke(query)"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country. The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."
以上がPython コードを実装して大規模モデルの検索機能を強化するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



