

この記事を転載する許可を得るには、ソースに連絡してください。この記事は、自動運転ハートの公開アカウントによって公開されました。
More モーダル センサー フュージョンは、補完的で安定した安全な情報を意味し、長い間自動運転認識の重要な部分を占めてきました。しかし、不十分な情報利用、元のデータのノイズ、さまざまなセンサー間の不整合 (タイムスタンプの同期外れなど) により、融合パフォーマンスが制限されています。この記事では、ターゲット検出とセマンティック セグメンテーションに焦点を当て、LiDAR やカメラを含む既存のマルチモーダル自動運転認識アルゴリズムを包括的に調査し、50 を超えるドキュメントを分析します。融合アルゴリズムの従来の分類方法とは異なり、この論文では、この分野をさまざまな融合段階に基づいて 2 つの主要カテゴリと 4 つのサブカテゴリに分類します。さらに、この記事は現在の分野に存在する問題を分析し、将来の研究の方向性への参考を提供します。
これは、シングルモーダル認識アルゴリズムには固有の欠陥があるためです。たとえば、LIDAR は通常、カメラよりも高い位置に設置されますが、現実の複雑な運転シナリオでは、物体がフロントビュー カメラに遮られる場合がありますが、この場合、LIDAR を使用して行方不明の目標を捕捉することが可能です。ただし、LiDAR は機械構造の制限により、距離が異なると解像度が異なり、大雨などの非常に厳しい天候の影響を受けやすくなります。どちらのセンサーも単独で使用すると非常に優れた性能を発揮しますが、将来的には、LiDAR とカメラの補完的な情報により、自動運転が知覚レベルでより安全になるでしょう。
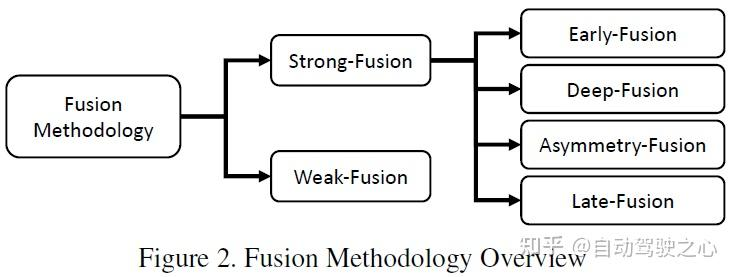
最近、自動運転のためのマルチモーダル認識アルゴリズムが大きく進歩しました。これらの進歩には、クロスモーダル特徴表現、より信頼性の高いモーダル センサー、より複雑で安定したマルチモーダル融合アルゴリズムと技術が含まれます。しかし、マルチモーダルフュージョンの方法論自体に焦点を当てているレビューは少数しかなく [15、81]、ほとんどの文献は伝統的な分類ルール、つまりフュージョン前、ディープ (フィーチャー) フュージョン、フュージョン後、に従って分類されています。データ レベル、機能レベル、提案レベルのいずれであっても、アルゴリズムにおける機能融合の段階に焦点を当てます。この分類ルールには 2 つの問題があります: 1 つ目は、各レベルのフィーチャ表現が明確に定義されていないこと、2 つ目は、LIDAR とカメラの 2 つのブランチを対称的な観点から扱うため、フィーチャ フュージョンとフィーチャ フュージョンの関係があいまいになることです。 LiDAR ブランチ: カメラ ブランチでのデータレベルの機能融合のケース。要約すると、従来の分類方法は直感的ですが、現在のマルチモーダル融合アルゴリズムの開発にはもはや適しておらず、研究者が体系的な観点から研究や分析を行うことがある程度妨げられています。 ##3 タスクとオープンな競争
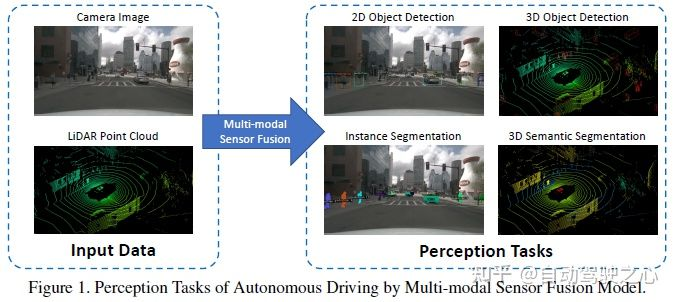
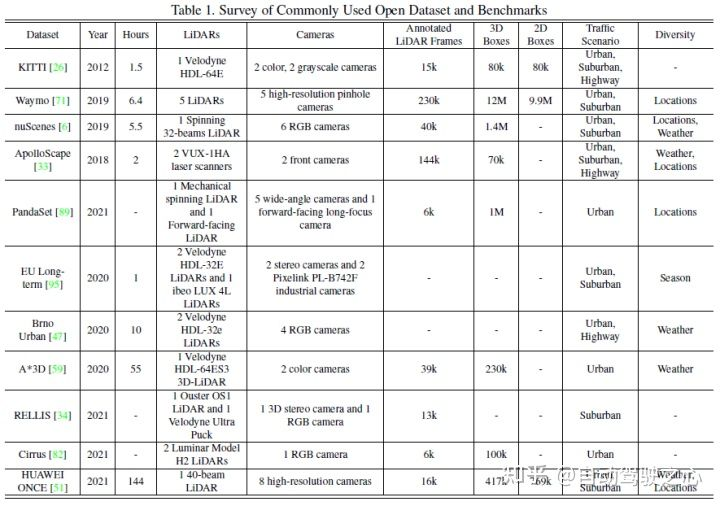
##一般的な認識タスクには、ターゲット検出、セマンティック セグメンテーション、深さの補完と予測などが含まれます。この記事では、障害物、信号機、交通標識の検出、車線境界線や空き領域のセグメンテーションなど、検出とセグメンテーションに焦点を当てます。自動運転認識タスクは次の図に示されています:一般的な公開データ セットには主に KITTI、Waymo、nuScenes が含まれます。次の図は自動運転に関連するデータ セットをまとめたものです知覚とその特徴
プレフュージョン (データレベルのフュージョン) は、さまざまなモダリティの生のセンサー データを直接融合することを指します。空間調整を通じて。
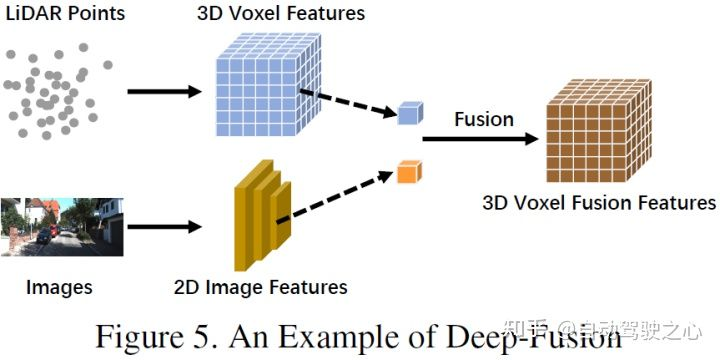
ディープ フュージョン (特徴レベルのフュージョン) は、カスケードまたは要素の乗算による特徴空間内のクロスモーダル データの融合を指します。
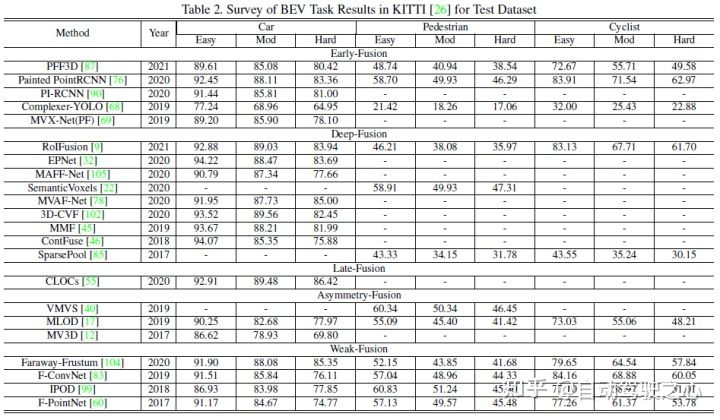
この記事では、KITTI の 3D 検出タスクと BEV 検出タスクを使用して、さまざまなマルチモーダル フュージョン アルゴリズムのパフォーマンスを水平に比較します。次の図は、BEV 検出テスト セットの結果です。 :
以下は 3D 検出テスト セットの結果の例です:
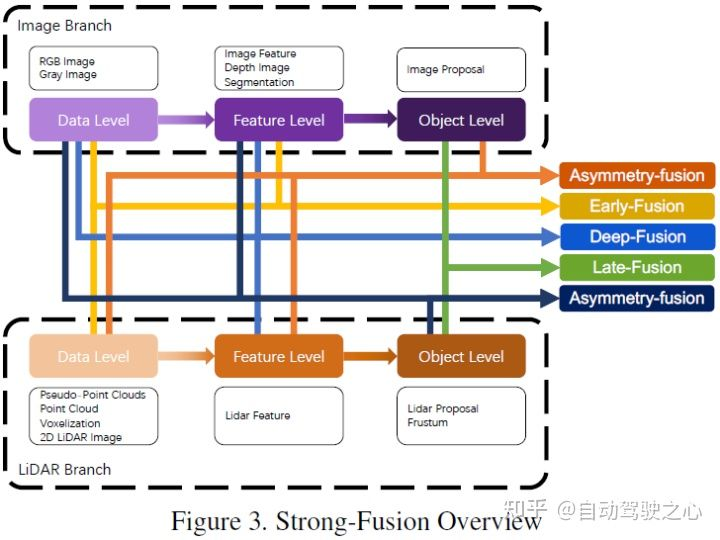
LIDAR とカメラのデータによって表されるさまざまな組み合わせ段階に従って、この記事では強核融合を次のように細分化します。 、深部融合、非対称融合、ポスト融合。上の図に示すように、強力な融合の各サブモジュールは、カメラ データではなく LIDAR 点群に大きく依存していることがわかります。
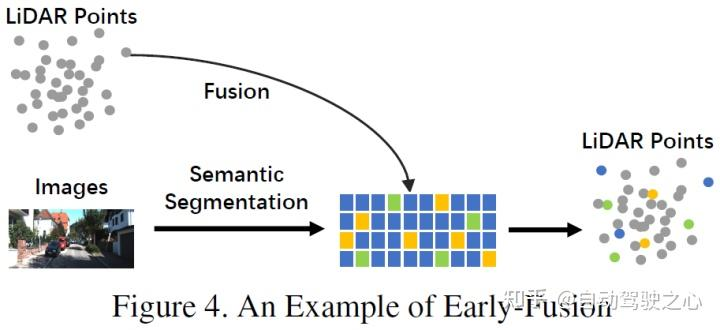
従来のデータレベルのフュージョン定義とは異なり、後者は、空間的な位置合わせと、元のデータレベルでの各モダリティデータの直接フュージョンです。投影 このアプローチでは、早期融合により、LiDAR データがデータ レベルで融合され、カメラ データがデータ レベルまたは機能レベルで融合されます。初期融合の例としては、図 4 のモデルが挙げられます。 書き直された内容: 従来のデータレベル融合定義とは異なり、元のデータレベルでの空間位置合わせと投影を通じて各モダリティデータを直接融合する方法です。早期融合とは、LiDAR データとカメラ データまたは機能レベルのデータをデータ レベルで融合することを指します。図 4 のモデルは、早期融合の例です。
従来の分類方法で定義されるプレフュージョンとは異なり、この記事で定義されるプレフュージョンとは、空間的位置合わせと空間的調整による各モーダル データの直接融合を指します。元のデータ レベルでの投影法であり、前者の融合はデータ レベルでの LiDAR データの融合を指し、データ レベルまたは特徴レベルでの画像データの融合を指します。概略図は次のとおりです。
 #LiDAR ブランチでは、点群反射マップ、ボクセル化テンソル、正面図/距離図/BEV ビュー、擬似点群など、多くの表現方法があります。これらのデータは、疑似点群 [79] を除き、バックボーン ネットワークごとに異なる固有の特性を持っていますが、ほとんどのデータは特定のルール処理を通じて生成されます。また、これらのLiDARデータは、特徴空間埋め込みに比べて解釈性が高く、直接可視化することができますが、画像ブランチにおいては、厳密な意味でのデータレベルの定義はRGBやグレー画像を指しますが、この定義には普遍性や合理性が欠けています。したがって、この論文では、融合前の段階での画像データのデータレベルの定義を、データレベルと特徴レベルのデータを含むように拡張します。なお、本稿ではセマンティックセグメンテーションの予測結果もプレフュージョン(画像の特徴レベル)の一種として捉えており、3Dターゲットの検出に役立つ一方で、セマンティック セグメンテーションの「ターゲット レベル」の機能。機能は、タスク全体の最終的なターゲット レベルの提案とは異なります。
#LiDAR ブランチでは、点群反射マップ、ボクセル化テンソル、正面図/距離図/BEV ビュー、擬似点群など、多くの表現方法があります。これらのデータは、疑似点群 [79] を除き、バックボーン ネットワークごとに異なる固有の特性を持っていますが、ほとんどのデータは特定のルール処理を通じて生成されます。また、これらのLiDARデータは、特徴空間埋め込みに比べて解釈性が高く、直接可視化することができますが、画像ブランチにおいては、厳密な意味でのデータレベルの定義はRGBやグレー画像を指しますが、この定義には普遍性や合理性が欠けています。したがって、この論文では、融合前の段階での画像データのデータレベルの定義を、データレベルと特徴レベルのデータを含むように拡張します。なお、本稿ではセマンティックセグメンテーションの予測結果もプレフュージョン(画像の特徴レベル)の一種として捉えており、3Dターゲットの検出に役立つ一方で、セマンティック セグメンテーションの「ターゲット レベル」の機能。機能は、タスク全体の最終的なターゲット レベルの提案とは異なります。
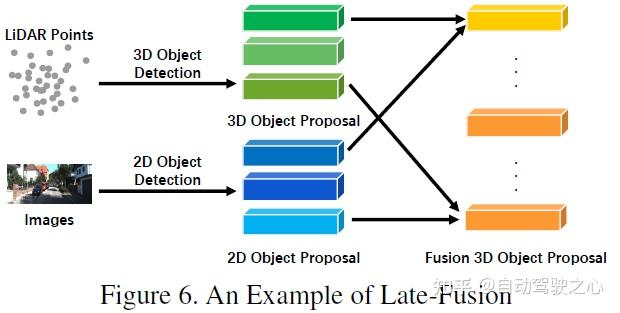
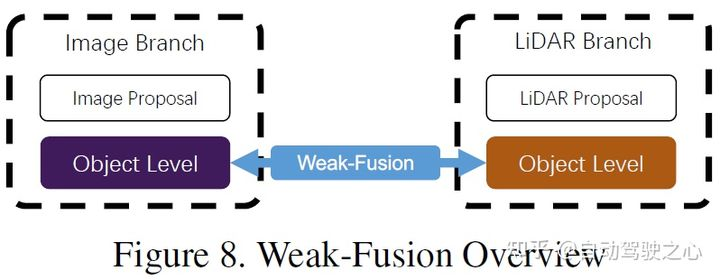
と強い融合の違いは、弱い融合手法では、マルチモーダル ブランチからのデータ、特徴、またはターゲットを直接融合するのではなく、データを次の方法で処理することです。他の形態も。以下の図は、弱融合アルゴリズムの基本的な枠組みを示しています。弱融合に基づく方法は、通常、特定のルールベースの方法を使用して、あるモダリティからのデータを監視信号として利用し、別のモダリティの相互作用をガイドします。たとえば、画像ブランチ内の CNN からの 2D プロポーザルは、元の LiDAR 点群で切り捨てを引き起こす可能性があり、弱い融合は、元の LiDAR 点群を LiDAR バックボーンに直接入力して、最終プロポーザルを出力します。
上記のパラダイムのいずれにも属さない作品もあります。 [39] では、ディープフュージョンとポストフュージョンを組み合わせた [39] や、フロントフロントフュージョンを組み合わせた [77] など、さまざまなフュージョン手法が使用されています。これらの手法は融合アルゴリズム設計の主流ではないため、この記事では他の融合手法に分類します。
近年、自動運転知覚タスクのためのマルチモーダル融合手法は、より高いレベルの機能から始めて急速に進歩しています。より複雑な深層学習モデルへの表現。しかしながら、解決すべきいくつかの未解決の課題も残されており、本稿では、今後の改善の方向性をいくつかまとめて以下に示します。
現在の融合モデルには、位置ずれと情報損失の問題があります [13、67、98]。さらに、フラット フュージョン操作も、知覚タスクのパフォーマンスのさらなる向上を妨げます。要約は次のとおりです。
前向きの単一フレーム画像は、自動運転の知覚タスクの典型的なシナリオです。ただし、ほとんどのフレームワークは限られた情報しか利用できず、運転シナリオの理解を容易にするための補助タスクを詳細に設計していません。要約は次のとおりです。
実際のシナリオとセンサーの高さは、ドメインのバイアスと解像度に影響を与える可能性があります。これらの欠点は、自動運転用の深層学習モデルの大規模なトレーニングとリアルタイム操作を妨げます。
[1] https://zhuanlan.zhihu.com/p/470588787
[2] マルチモーダル センサー フュージョン自動運転の認識: 調査

元のリンク: https://mp.weixin.qq.com/s/usAQRL18vww9YwMXRvEwLw
以上が自動運転におけるマルチモーダル融合知覚アルゴリズムの応用に関する詳細な議論の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



