

安定したビデオ拡散が登場、コードウェイトはオンラインに

AI描画で有名なStability AIが、ついにAI生成動画業界に参入しました。
今週火曜日、安定拡散に基づくビデオ生成モデルである安定ビデオ拡散が開始され、AI コミュニティはすぐに議論を開始しました
#「やっと待った」という声が多く聞かれました。
#今、既存の静止画像を使用して数秒のビデオを生成できます
Stability AI のオリジナルの Stable Diffusion グラフ モデルに基づいて、Stable Video Diffusion はオープン ソースまたは商用化されました。業界では数少ないビデオ生成モデル。


導入によると、Stable Video Propagation は、マルチビュー データセットを微調整することによる単一画像からのマルチビュー合成など、さまざまなダウンストリーム タスクに簡単に適応できます。 Stable AIは、Stable Proliferationを中心に構築されたエコシステムと同様に、この基盤を構築および拡張するさまざまなモデルを計画していると述べています


外部評価では、Stability AI がこれらのモデルを確認しました。ユーザー嗜好調査において主要なクローズドソース モデルを上回るパフォーマンス:


安定したビデオ伝送は、安定した AI オープンソース モデル ファミリーのメンバーです。現在、同社の製品は画像、言語、オーディオ、3D、コードなどの複数のモダリティをカバーしているようですが、これは人工知能の向上に対する同社の取り組みを完全に示しています
安定したビデオの普及技術レベル
高解像度ビデオの潜在的な普及モデルとしての安定したビデオ普及モデルは、テキストからビデオへ、または画像からビデオへの SOTA レベルに達しています。最近、2D 画像合成でトレーニングされた潜在拡散モデルは、時間レイヤーを挿入し、小規模な高品質ビデオ データセットを微調整することにより、生成ビデオ モデルに変換されました。ただし、トレーニング方法は文献によって大きく異なり、ビデオ データ キュレーションの統一戦略についてはまだこの分野で合意されていません。
論文「安定したビデオの普及」では、安定性 AI は成功したビデオを特定して評価します。トレーニング ビデオ 潜在拡散モデルの 3 つの異なる段階: テキストから画像への事前トレーニング、ビデオの事前トレーニング、および高品質ビデオの微調整。また、高品質のビデオを生成するために慎重に準備された事前トレーニング データセットの重要性を実証し、字幕やフィルタリング戦略を含む強力な基本モデルをトレーニングするための体系的なキュレーション プロセスについても説明します。
Stability AI は、論文の中で、高品質データに対するベース モデルの微調整の影響についても調査し、クローズドソースのビデオ生成に匹敵するテキストからビデオへのモデルをトレーニングします。このモデルは、画像からビデオの生成やカメラのモーション固有の LoRA モジュールへの適応性などの下流タスクに強力なモーション表現を提供します。さらに、このモデルは、マルチビュー拡散モデルの基礎として使用できる強力なマルチビュー 3D プリアを提供することもできます。モデルは、オブジェクトの複数のビューをフィードフォワード方式で生成します。必要な計算能力はわずかであり、パフォーマンスも画像ベースの方法よりも優れています。
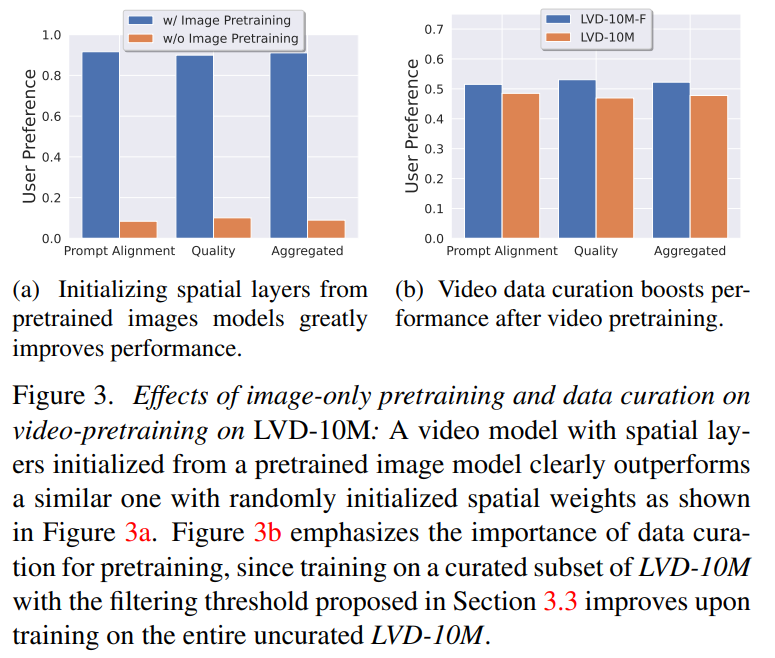
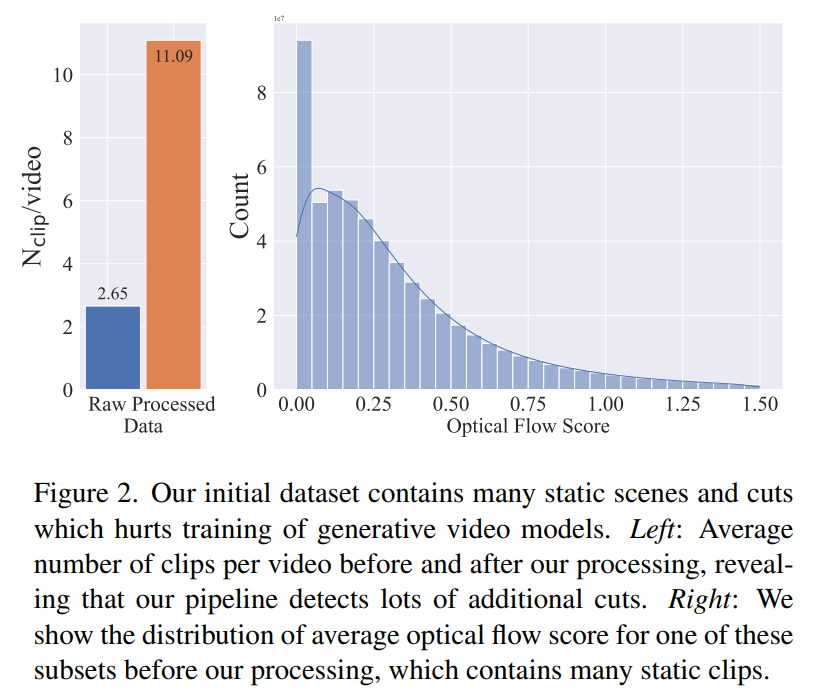
フェーズ 1: 画像の事前トレーニング。 この記事では、画像の事前トレーニングをトレーニング パイプラインの最初の段階とみなし、Stable Diffusion 2.1 上に初期モデルを構築して、ビデオ モデルに強力な視覚的表現を装備します。画像の事前トレーニングの効果を分析するために、この記事では 2 つの同一のビデオ モデルもトレーニングして比較します。図 3a の結果は、品質とキュー追跡の両方の点で、画像の事前トレーニングされたモデルが好ましいことを示しています。 この記事は、適切な事前トレーニング データセットを作成するためのシグナルとして人間の好みに依存しています。この記事で作成したデータセットは LVD (Large Video Dataset) で、5 億 8,000 万ペアの注釈付きビデオ クリップで構成されています。 さらなる調査により、生成されたデータセットには、最終的なビデオ モデルのパフォーマンスを低下させる可能性のある例がいくつか含まれていることが判明しました。したがって、この論文では、高密度オプティカル フローを使用してデータ セットに注釈を付けます
最終段階におけるビデオ事前トレーニングの影響を分析するために、この論文では、初期化のみが異なる 3 つのモデルを微調整します。図 4e に結果を示します。 
 #さらに、この論文では、光学式文字認識を適用して、大きなデータ セットを削除します。テキストクリッピングの数。最後に、CLIP 埋め込みを使用して、各クリップの最初、中間、最後のフレームに注釈を付けます。次の表は、LVD データセットの統計を示しています。
#さらに、この論文では、光学式文字認識を適用して、大きなデータ セットを削除します。テキストクリッピングの数。最後に、CLIP 埋め込みを使用して、各クリップの最初、中間、最後のフレームに注釈を付けます。次の表は、LVD データセットの統計を示しています。 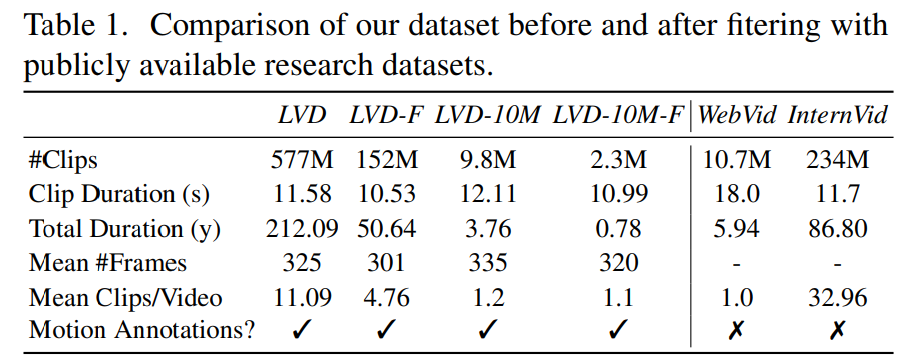
 これは良いスタートのようです。 AI を使用して直接ムービーを生成できるようになるのはいつですか?
これは良いスタートのようです。 AI を使用して直接ムービーを生成できるようになるのはいつですか?
以上が安定したビデオ拡散が登場、コードウェイトはオンラインにの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLで条項ごとに注文をマスターする:効果的にデータを並べ替える
Apr 08, 2025 pm 07:03 PM
SQLORDERBY句の詳細な説明:Data OrderBY句の効率的なソートは、クエリ結果セットをソートするために使用されるSQLの重要なステートメントです。単一の列または複数の列で昇順(ASC)または下降順序(DESC)で配置でき、データの読みやすさと分析効率を大幅に改善できます。 Orderby Syntax SelectColumn1、column2、... fromTable_nameOrderByColumn_name [asc | desc]; column_name:列ごとに並べ替えます。 ASC:昇順の注文ソート(デフォルト)。 DESC:降順で並べ替えます。 Orderbyの主な機能:マルチコラムソート:複数の列のソートをサポートし、列の順序によりソートの優先度が決まります。以来
 Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
データベースに接続するときの一般的なエラーとソリューション:ユーザー名またはパスワード(エラー1045)ファイアウォールブロック接続(エラー2003)接続タイムアウト(エラー10060)ソケット接続を使用できません(エラー1042)SSL接続エラー(エラー10055)接続の試みが多すぎると、ホストがブロックされます(エラー1129)データベースは存在しません(エラー1049)
 SQL挿入ステートメントに最新のチュートリアルを書く方法
Apr 09, 2025 pm 01:48 PM
SQL挿入ステートメントに最新のチュートリアルを書く方法
Apr 09, 2025 pm 01:48 PM
SQL挿入ステートメントは、データベーステーブルに新しい行を追加するために使用され、その構文は次のとおりです。Table_name(column1、column2、...、columnn)values(value1、value2、... ...、valuen);。このステートメントは、複数の値の挿入をサポートし、ヌル値を列に挿入できるようにしますが、挿入された値が列のデータ型と互換性があることを確認して、一意性の制約に違反しないようにする必要があります。
 SQLに新しい列を追加する方法
Apr 09, 2025 pm 02:09 PM
SQLに新しい列を追加する方法
Apr 09, 2025 pm 02:09 PM
Alter Tableステートメントを使用して、SQLの既存のテーブルに新しい列を追加します。特定の手順には、テーブル名と列情報の決定、テーブルステートメントの変更、およびステートメントの実行が含まれます。たとえば、顧客テーブルに電子メール列を追加します(Varchar(50)):Alter Table Customersはメール(50)を追加します。
