

ドキュメント分析に LangChain と OpenAI API を使用する方法

翻訳者は書き直す必要があります:|レビューアーは書き直す必要があります:Bugatti
レビューアーは書き直す必要があります内容は次のとおりです: | 書き換える必要がある内容は次のとおりです: Chonglou
ドキュメントとデータからの洞察の抽出 # にとって、情報に基づいた意思決定を行うことは非常に重要です。ただし、機密情報を扱う場合には、プライバシーの問題が発生する可能性があります。 LangChain と OpenAI を組み合わせて使用するには、API を書き直す必要があります。インターネットにアップロードせずにローカルのドキュメントを分析します。 データをローカルに保持し、分析に埋め込みとベクトル化を使用し、環境内でプロセスを実行することでこれを実現します。 ##この時点で。 OpenAI
は、モデルのトレーニングやサービスの改善のために、API を通じて顧客から送信されたデータを使用しません。 #ビルド環境新しいものを作成する
Python仮想環境,これにより、ライブラリのバージョンの競合がなくなります。次に、次のターミナル コマンドを実行して、必要なライブラリをインストールします。
#pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
#LangChain: これを使用して、テキストの処理と分析のための言語チェーンを作成および管理します。これは、ドキュメントの読み込み、テキストの分割、埋め込み、および ボリューム ストレージのためのモジュールを提供します。
- #OpenAI: これを使用してクエリを実行します, を実行し、言語モデルから結果を取得します。
- tiktoken: これを使用して、指定されたテキスト内の ## を計算します。 #トークン ( テキストユニット ) の数。これは、使用するトークンの 数
- に基づいて を課金する OpenAI 用です。書き換える必要があるのは、API# です。 ##トラッキングトークン インタラクション中のカウント。 #FAISS:これを使用してベクター ストアを作成および管理します。埋め込みに基づいて類似したベクトルを迅速に取得します。 PyPDF:このライブラリは PDF# から派生しています##テキストを抽出します。 は、
- PDF ファイルをロードし、そのテキスト 、 を抽出してさらなる取引を行うのに役立ちます。と。
- #すべてのライブラリをインストールすると、環境は nowreadyready になります。 。 #GetOpenAI が書き換える必要があるコンテンツは次のとおりです: APIKey OpenAI にリクエストを行う場合、書き換える必要がある内容は次のとおりです: API、
API キーをリクエストの一部として使用します。 この キーを使用すると、API プロバイダーは、リクエストが正当なソースからのものであることと、ユーザーが
それを所有しますその機能にアクセスするには権限が必要です。 OpenAI を取得するために書き換える必要がある内容は、API キー、OpenAI プラットフォーム です。
次に、右上隅のアカウント プロフィール の下で、[#] をクリックします。 ##ViewAPIKey”, が表示されますAPIキーページ。
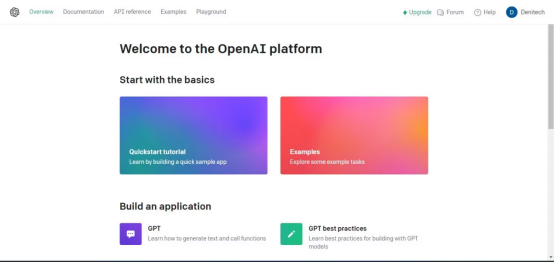 #[新しいキーの作成]
#[新しいキーの作成]
ボタンをクリックします。 キーに名前を付けてし、「新しいキーの作成」をクリックします。 OpenAI は API キーを生成します。これをコピーして安全な場所に保管する必要があります。セキュリティ上の理由から、OpenAI アカウントを通じて再度表示することはできません。 キーを紛失した場合は、新しいキーを生成する必要があります。
导入所需的库
为了能够使用安装在虚拟环境中的库,您需要导入它们。
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。
加载用于分析的文档
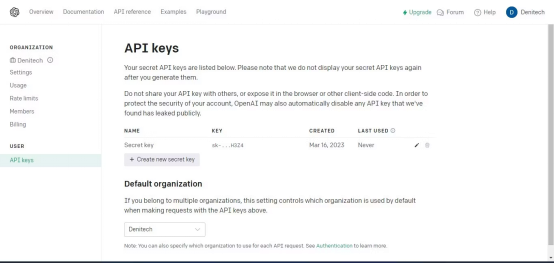
先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。
接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。
需要改写的内容是:
text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。
查询文档
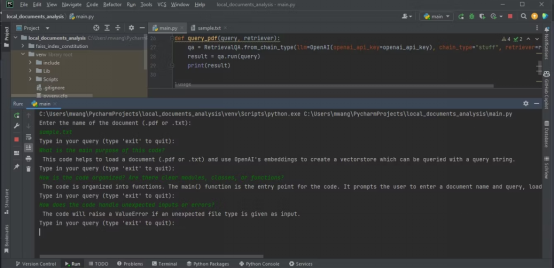
您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
该函数使用创建的QA实例来运行查询并输出结果。
创建主函数
主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。
接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。
这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。
最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数:
if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。
执行文件分析
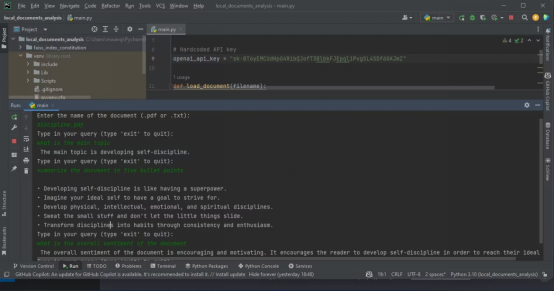
要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。
以下截图展示了对PDF进行分析的结果
以下の出力は、with ソース コードを含むテキスト ファイルの分析結果を示しています。
#分析するファイルが PDF またはテキスト形式であることを確認してください。ドキュメント が 他の形式 である場合は、オンライン ツールを使用して PDF 形式 に変換できます。 完全なソース コードは、GitHub コード リポジトリで入手できます: https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI
# #元のタイトル:
How 書き換える必要がある内容は次のとおりです: to 書き換える必要がある内容は次のとおりです: Analyze 書き換える必要がある内容は次のとおりです: ドキュメント書き換えが必要な内容は次のとおりです。 書き換えが必要な内容は次のとおりです。 書き換えが必要な内容は次のとおりです。 書き換えが必要な内容は次のとおりです。 書き換えが必要な内容は次のとおりです。 書き換えが必要な内容は次のとおりです。は: OpenAI 書き換える必要があるコンテンツは: API、作成者 : Denis が書き直す必要があるコンテンツは: Kuraa
書き直す必要がある内容は次のとおりです。以上がドキュメント分析に LangChain と OpenAI API を使用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
OpenAI は最近、最新世代の埋め込みモデル embeddingv3 のリリースを発表しました。これは、より高い多言語パフォーマンスを備えた最もパフォーマンスの高い埋め込みモデルであると主張しています。このモデルのバッチは、小さい text-embeddings-3-small と、より強力で大きい text-embeddings-3-large の 2 つのタイプに分類されます。これらのモデルがどのように設計され、トレーニングされるかについてはほとんど情報が開示されておらず、モデルには有料 API を介してのみアクセスできます。オープンソースの組み込みモデルは数多くありますが、これらのオープンソース モデルは OpenAI のクローズド ソース モデルとどう違うのでしょうか?この記事では、これらの新しいモデルのパフォーマンスをオープンソース モデルと実証的に比較します。データを作成する予定です
 Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
2023年、AI技術が注目を集め、プログラミング分野を中心にさまざまな業界に大きな影響を与えています。 AI テクノロジーの重要性に対する人々の認識はますます高まっており、Spring コミュニティも例外ではありません。 GenAI (汎用人工知能) テクノロジーの継続的な進歩に伴い、AI 機能を備えたアプリケーションの作成を簡素化することが重要かつ緊急になっています。このような背景から、AI 機能アプリケーションの開発プロセスを簡素化し、シンプルかつ直観的にし、不必要な複雑さを回避することを目的とした「SpringAI」が登場しました。 「SpringAI」により、開発者はAI機能を搭載したアプリケーションをより簡単に構築でき、使いやすく、操作しやすくなります。
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
著者丨コンパイル: TimAnderson丨プロデュース: Noah|51CTO Technology Stack (WeChat ID: blog51cto) Zed エディター プロジェクトはまだプレリリース段階にあり、AGPL、GPL、および Apache ライセンスの下でオープンソース化されています。このエディターは高性能と複数の AI 支援オプションを備えていますが、現在は Mac プラットフォームでのみ利用可能です。 Nathan Sobo 氏は投稿の中で、GitHub 上の Zed プロジェクトのコード ベースでは、エディター部分は GPL に基づいてライセンスされ、サーバー側コンポーネントは AGPL に基づいてライセンスされ、GPUI (GPU Accelerated User) インターフェイス部分はApache2.0ライセンス。 GPUI は Zed チームによって開発された製品です
 OpenAI を待つのではなく、Open-Sora が完全にオープンソースになるのを待ちましょう
Mar 18, 2024 pm 08:40 PM
OpenAI を待つのではなく、Open-Sora が完全にオープンソースになるのを待ちましょう
Mar 18, 2024 pm 08:40 PM
少し前まで、OpenAISora はその驚くべきビデオ生成効果で急速に人気を博し、数ある文学ビデオ モデルの中でも際立って世界的な注目を集めるようになりました。 2 週間前にコストを 46% 削減した Sora トレーニング推論再現プロセスの開始に続き、Colossal-AI チームは世界初の Sora のようなアーキテクチャのビデオ生成モデル「Open-Sora1.0」を完全にオープンソース化し、全体をカバーしました。データ処理、すべてのトレーニングの詳細、モデルの重みを含むトレーニング プロセスを管理し、世界中の AI 愛好家と協力してビデオ作成の新時代を推進します。ちょっと覗いてみましょう。Colossal-AI チームがリリースした「Open-Sora1.0」モデルによって生成された賑やかな街のビデオを見てみましょう。オープンソラ1.0
 Embedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。
Apr 15, 2024 am 09:01 AM
Embedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。
Apr 15, 2024 am 09:01 AM
Ollama は、Llama2、Mistral、Gemma などのオープンソース モデルをローカルで簡単に実行できるようにする非常に実用的なツールです。この記事では、Ollamaを使ってテキストをベクトル化する方法を紹介します。 Ollama をローカルにインストールしていない場合は、この記事を読んでください。この記事では、nomic-embed-text[2] モデルを使用します。これは、短いコンテキストおよび長いコンテキストのタスクにおいて OpenAI text-embedding-ada-002 および text-embedding-3-small よりも優れたパフォーマンスを発揮するテキスト エンコーダーです。 o が正常にインストールされたら、nomic-embed-text サービスを開始します。
 マイクロソフトとOpenAIは人型ロボットに1億ドル投資する計画!ネチズンはマスク氏に電話をかけている
Feb 01, 2024 am 11:18 AM
マイクロソフトとOpenAIは人型ロボットに1億ドル投資する計画!ネチズンはマスク氏に電話をかけている
Feb 01, 2024 am 11:18 AM
MicrosoftとOpenAIが人型ロボットのスタートアップに巨額の資金を投資していることが年初に明らかになった。このうちマイクロソフトは9500万ドル、OpenAIは500万ドルを投資する予定だ。ブルームバーグによると、同社は今回のラウンドで総額5億米ドルを調達する予定で、資金調達前の評価額は19億米ドルに達する可能性がある。何が彼らを惹きつけるのでしょうか?まずはこの会社のロボット分野の実績を見てみましょう。このロボットはすべて銀と黒で、その外観はハリウッドの SF 大作映画に登場するロボットのイメージに似ています。今、彼はコーヒー カプセルをコーヒー マシンに入れています。正しく置かれていない場合でも、何もせずに自動的に調整されます。人間リモコン: ただし、しばらくすると、コーヒーを持ち帰って楽しむことができます: 家族にそれを認識した人はいますか? はい、このロボットは少し前に作成されました。
 突然! OpenAI、情報漏洩の疑いでイリヤの盟友を解雇
Apr 15, 2024 am 09:01 AM
突然! OpenAI、情報漏洩の疑いでイリヤの盟友を解雇
Apr 15, 2024 am 09:01 AM
突然! OpenAIが従業員を解雇、理由は情報漏洩の疑い。一人は、行方不明の主任科学者イリヤの同盟者であり、スーパーアライメントチームの中心メンバーであるレオポルド・アッシェンブレナーです。もう一人も単純ではありません。彼は LLM 推論チームの研究者であり、スーパー アライメント チームでも働いていたパベル イズマイロフです。 2人が具体的にどのような情報を漏らしたのかは不明だ。このニュースが暴露された後、多くのネチズンは「かなりショックを受けた」と表明した。私はつい最近アシェンブレナーの投稿を見て、彼のキャリアが成長していると感じたが、これほどの変化は予想していなかった。写真の中のネチズンの中には、「OpenAI はアシェンブレナーを失った、私は」と考えている人もいます。
