

ディープラーニングにおけるコードデータの拡張: 5 年間の 89 件の研究のレビュー

ディープラーニングと大規模モデルの急速な発展に伴い、革新的なテクノロジーの追求はますます高まっています。このプロセスにおいて、データ拡張テクノロジーは無視できない価値を示しています。
最近、モナシュ大学、シンガポール管理大学、ファーウェイ ノアの方舟研究所、北京航空航天大学の研究者が、とオーストラリア国立大学は共同で過去 5 年間に 89 件の関連研究論文の調査を実施し、ディープ ラーニングにおけるコード データ拡張の適用に関する 包括的なレビュー を発表しました。

- 文書アドレス: https://arxiv.org/abs/2305.19915
- プロジェクト アドレス: https://github.com/terryyz/DataAug4Code
このレビューでは、コード データを詳しく調査するだけではありません。ディープラーニング分野における強化技術の応用も今後の発展性が期待されます。新しいデータを収集せずにトレーニング サンプルの多様性を高める手法として、コード データ拡張は機械学習研究で広く応用されるようになりました。これらの手法は、リソースが乏しい地域におけるデータ駆動型モデルのパフォーマンスを向上させるために非常に重要です。
#ただし、コード モデリングの分野では、このアプローチの可能性はまだ十分に活用されていません。コード モデリングは、機械学習とソフトウェア エンジニアリングが交わる新興分野であり、コード補完、コードの要約、欠陥検出などのさまざまなコーディング タスクを解決するための機械学習技術の適用が含まれます。コード データ (プログラミング言語と自然言語) のマルチモーダルな性質により、データ拡張方法のカスタマイズに特有の課題が生じます。
このレビュー レポートは、複数のトップ学術機関によって編集され、業界によって共同リリースされました。代理店。コードデータ拡張技術を詳細に明らかにするだけでなく、将来の研究や応用のための指針も提供します。このレビューにより、より多くの研究者が深層学習におけるコード データ拡張の応用に興味を持ち、この分野でのさらなる探索と開発が促進されると信じています。
背景の紹介
コード モデルの台頭と発展: コード モデルは、多数のソース コード コーパスに基づいてトレーニングされ、コード スニペットのコンテキストを正確にシミュレートできます。 LSTM や Seq2Seq などの深層学習アーキテクチャの初期の採用から、その後の事前トレーニング済み言語モデルの組み込みに至るまで、これらのモデルは複数のソースにわたる下流タスクで優れたパフォーマンスを示してきました。たとえば、一部のモデルは、事前トレーニング段階でプログラムのデータ フローを考慮します。これは、コードの意味レベルの構造であり、変数間の関係を把握するために使用されます。
#データ拡張テクノロジーの重要性: データ拡張テクノロジーは、データ合成を通じてトレーニング サンプルの多様性を高め、それによってモデル全体を改善します。パフォーマンスの側面(精度や堅牢性など)。たとえば、コンピュータ ビジョンの分野では、一般的に使用されるデータ拡張方法には、画像のトリミング、反転、色調整などがあります。自然言語処理では、データ拡張は、単語の置き換えや文の書き換えによってコンテキストを書き換えることができる言語モデルに大きく依存します。
#コード データ拡張の特殊性#: 画像やプレーン テキストとは異なり、ソース コードはプログラミング言語の厳密な構文規則によって制限されます。強化された柔軟性は低いです。コードのデータ拡張メソッドのほとんどは、元のコード スニペットの機能と構文を維持するために、特定の変換ルールに従う必要があります。一般的な方法は、パーサーを使用してソース コードの具体的な構文ツリーを構築し、それを抽象構文ツリーに変換して、識別子や制御フロー ステートメントなどの重要な情報を保持しながら表現を簡素化することです。これらの変換はルールベースのデータ拡張手法の基礎であり、現実世界でより多様なコード表現をシミュレートするのに役立ち、拡張データでトレーニングされたコード モデルの堅牢性が向上します。 コード データ拡張手法の詳細な探索
コード データ拡張の世界の詳細な探索において、著者は次のように分けています。これらのテクノロジーは、ルールベースの技法、モデルベースの技法、およびサンプル補間技法の 3 つの主要なカテゴリに分類されます。これらのさまざまなブランチについては、以下で簡単に説明します。
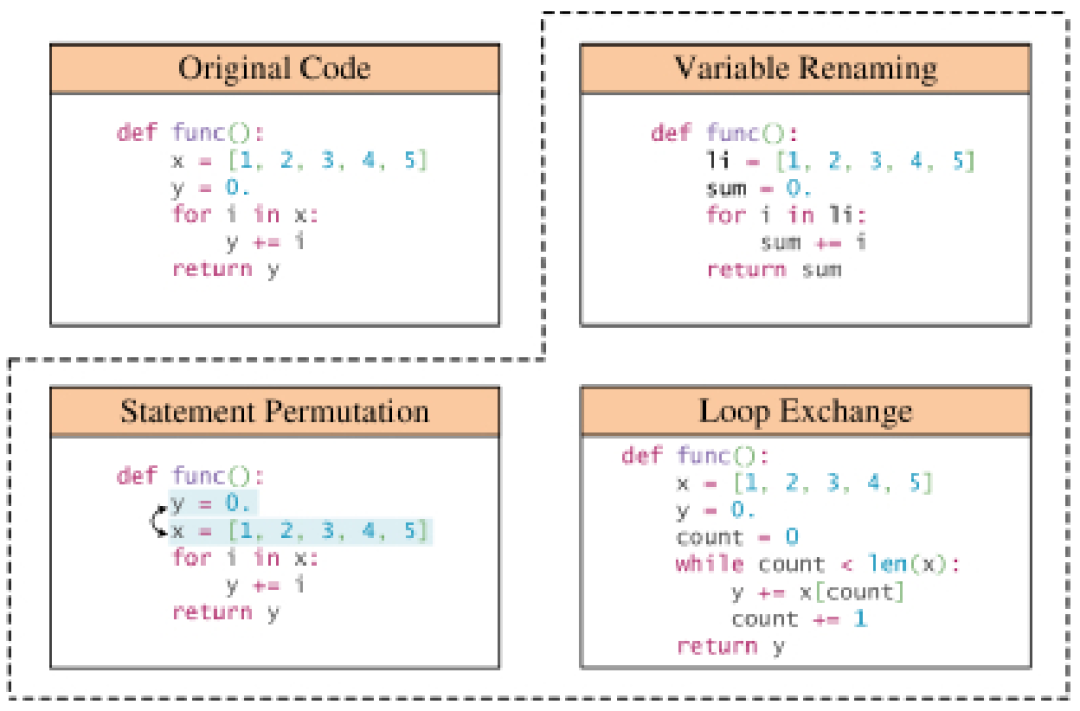
ルールベースのテクノロジ: 多くのデータ拡張手法は、文法ルールやセマンティクスが違反されないようにしながら、事前に決定されたルールを利用してプログラムを変換します。これらの変換には、変数名の置換、メソッド名の変更、無効なコードの挿入などの操作が含まれます。基本的なプログラム構文に加えて、一部の変換では、制御フロー グラフや使用定義チェーンなどのより深い構造情報も考慮されます。ルールベースのデータ拡張技術のサブセットは、docstring やコメントなどのコード スニペット内の自然言語コンテキストの拡張に重点を置いています。
モデルベースの手法 : トレーニング用に設計されたコード モデルの一連のデータ拡張手法データを強化するためのさまざまなモデル。たとえば、一部の研究では、補助分類生成敵対的ネットワーク (ACGAN) を利用して拡張を生成しています。他の研究では、コード生成とコード検索の両方の機能を向上させるために、敵対的生成ネットワークを訓練しました。これらのメソッドは主にコード モデル専用に設計されており、さまざまな方法でコードの表現とコンテキストの理解を強化することを目的としています。
補間手法の例: このタイプのデータ拡張手法は、入力と 2 つ以上の値を補間する Mixup に由来します。より多くの実際のサンプルを操作するためのラベルです。たとえば、コンピューター ビジョンのバイナリ分類タスクと犬と猫の 2 つの画像が与えられた場合、これらのデータ拡張手法は、ランダムに選択された重みに従って 2 つの画像の入力と対応するラベルをブレンドできます。ただし、コードの世界では、これらのメソッドの適用は、独自のプログラム構文と機能によって制限されます。表面レベルの内挿と比較して、ほとんどの例の内挿データ拡張手法は、モデルの埋め込みを通じて複数の実例を 1 つの入力に融合します。たとえば、ルールベースの手法と Mixup を組み合わせて、元のコード スニペットとその変換された表現を混合する研究があります。

##実際のアプリケーションでは、コード モデルのデータ拡張手法の設計と有効性は、計算コスト、サンプルの多様性、モデルの堅牢性などの複数の要因の影響を受けます。このセクションでは、これらの要因に焦点を当て、適切なデータ拡張方法を設計および最適化するための洞察とヒントを提供します。
メソッドスタッキング
: 前の議論では、モデルを強化する目的で、単一の作業で多くのデータ拡張戦略が同時に提案されました。パフォーマンス。通常、この組み合わせには、同じタイプのデータ拡張または異なるデータ拡張方法の混合の 2 つのタイプが含まれます。前者は通常、ルールベースのデータ拡張技術に適用されます。その出発点は、単一のコード変換では現実世界の多様なコーディング スタイルと実装を完全に表現できないことです。いくつかの研究では、複数の種類のデータ拡張技術を融合することでコード モデルのパフォーマンスを向上できることが実証されています。たとえば、ルールベースのトランスコーディング スキームとモデルベースのデータ拡張を組み合わせて、モデル トレーニング用の強化されたコーパスを作成します。ルールベースの非キーワード抽出とモデルベースの非キーワード置換という 2 つのデータ拡張技術を含む、プログラミング言語に関する他の研究も強化されています。
最適化: 堅牢性の強化や計算コストの最小化など、特定のシナリオでは、特定の強化されたサンプル候補を選択することが重要です。著者らは、この目標指向の候補選択をデータ拡張における最適化と呼んでいます。この記事では主に、確率的選択、モデルベースの選択、ルールベースの選択という 3 つの戦略を紹介します。確率的選択では確率分布からサンプリングすることで最適化が行われますが、モデルベースの選択ではモデルに基づいて最適な例が選択されます。ルールベースの選択では、特定の事前に決定されたルールまたはヒューリスティックを使用して、最も適切な例が選択されます。
確率的選択: 著者は、MHM、QMDP、BUGLAB-Aug を含む 3 つの代表的な確率的選択戦略を具体的に選択しました。 MHM は、メトロポリス・ヘイスティングスの確率的サンプリング法、つまり識別子置換による敵対的な例を選択するためのマルコフ連鎖モンテカルロ手法を採用しています。 QMDP は、Q 学習手法を使用して、ルールベースの構造変換を戦略的に選択して実行します。
モデルベースの選択: この戦略を採用する一部のデータ拡張手法では、モデルの勾配情報を使用して拡張サンプルの選択をガイドします。代表的な方法は、モデルの損失に基づいて最適化し、変数の名前変更を通じて敵対的な例を選択して生成するデータ拡張 MP 方法です。 SPACE は、プログラミング言語の意味論的および構文上の正確さを維持しながら、モデルのパフォーマンスへの影響を最大化することを目的として、勾配上昇を介してコード識別子の埋め込みを選択および摂動します。
ルールベースの選択 : ルールベースの選択は、事前に決定された適合度関数またはルールを使用する強力な方法です。このアプローチは多くの場合、意思決定指標に依存します。たとえば、IRGen は、遺伝的アルゴリズムに基づく最適化手法と、IR 類似性に基づく適合関数を使用します。一方、ACCENT と RA データ拡張 R は、それぞれ BLEU や CodeBLEU などの評価メトリクスを使用して、敵対的な影響を最大化するための選択と置換のプロセスをガイドします。
#アプリケーション シナリオ
データ拡張手法は、いくつかの一般的なコード シナリオに直接適用できます
堅牢性に対する敵対的な例: 堅牢性は、ソフトウェア エンジニアリングにおいて重要かつ複雑な側面です。コード モデルの脆弱性を特定して軽減するために敵対的な例を生成する効果的なデータ拡張手法を設計することは、近年の研究のホットスポットになっています。複数の研究により、さまざまなデータ拡張手法を使用してモデルの堅牢性をテストおよび強化することにより、コード モデルの堅牢性がさらに強化されました。
リソースが少ない分野: ソフトウェア エンジニアリングの分野では、プログラミング言語のリソースが著しく不均衡になっています。 Python や Java などの人気のあるプログラミング言語は、オープン ソース リポジトリで主要な役割を果たしていますが、Rust などの多くの言語はリソースが非常に不足しています。コード モデルはオープン ソース リポジトリやフォーラムに基づいてトレーニングされることが多く、プログラミング言語リソースの不均衡は、リソースが不足しているプログラミング言語ではパフォーマンスに悪影響を与える可能性があります。低リソース領域でのデータ拡張手法の適用は、繰り返し行われるテーマです。
検索強化: 自然言語処理とコーディングの分野では、検索強化のデータ強化アプリケーションがますます注目を集めています。 。これらのコード モデルの検索強化フレームワークには、コード モデルの事前トレーニングまたは微調整時にトレーニング セットからの検索強化サンプルが組み込まれており、この強化方法によりモデルのパラメーター効率が向上します。
対比学習: 対比学習は、データ拡張手法がコード シナリオに導入されるもう 1 つのアプリケーション分野です。これにより、モデルは、類似したサンプルが互いに近く、異なるサンプルが離れている埋め込み空間を学習できます。データ拡張手法は、欠陥検出、クローン検出、コード検索などのタスクにおけるモデルのパフォーマンスを向上させるために、陽性サンプルに類似したサンプルを構築するために使用されます。
次の記事では、クローン検出、欠陥検出と修復、コード要約、コード検索、コード生成など、いくつかの一般的なコーディング タスクと、評価データ セットに対するデータ拡張作業の適用について説明します。
#課題と機会コード データの強化に関して、著者は多くの重要な課題があると考えています。しかし、この分野に新たな可能性とエキサイティングな機会をもたらすのは、これらの課題です。
理論的議論: 現在、明らかなギャップがあります。コードでのデータ拡張方法の詳細な調査と理論的理解において。既存の研究のほとんどは画像処理と自然言語の分野に焦点を当てており、データ拡張をデータまたはタスクの不変性に関する既存の知識を適用する方法として見ています。コードに目を向けると、以前の研究では新しい方法が導入されたり、データ拡張技術がどのように効果的であるかを実証したりしましたが、特に数学的な観点から、その理由と方法が見落とされることがよくありました。コードの離散的な性質により、理論的な議論がさらに重要になります。理論的な議論により、実験結果だけでなく、より広い観点から誰もがデータ拡張を理解できるようになります。
事前トレーニング済みモデルに関するさらなる研究: 近年、事前トレーニング済みコード モデルがコード分野で広く使用されています。大規模コーパスの自己監修により豊富な知見が蓄積されている。多くの研究ではデータ拡張に事前トレーニングされたコード モデルが利用されていますが、ほとんどの試みは依然としてマスク トークンの置換または微調整後の直接生成に限定されています。大規模言語モデルのデータ拡張の可能性を活用することは、コーディングの世界における新たな研究の機会です。 データ強化で事前トレーニング済みモデルを使用するこれまでの方法とは異なり、これらの取り組みは「ヒントベースのデータ強化」の時代を切り開きました。ただし、ヒントベースのデータ拡張探索は、コードの世界では依然として比較的手つかずの研究領域です。
書き直された内容: データ強化で事前トレーニング済みモデルを使用する以前の方法とは異なり、これらの作品は「ヒントベースのデータ強化」の時代の到来を告げます。ただし、コーディング ドメインにおけるヒントベースのデータ拡張に関する研究はまだ比較的少ないです。 ドメイン固有のデータの処理: 著者中心調査 コード内の一般的な下流タスクのためのデータ拡張手法。しかし、著者らは、コーディング領域における他のタスク固有のデータに関する研究がまだ少量であることを認識しています。たとえば、API の推奨や API シーケンスの生成はコーディング タスクの一部と考えることができます。著者らは、これら 2 つの異なるレベル間のデータ拡張技術のギャップを観察し、今後の研究に検討の機会を提供しました。 プロジェクト レベルのコードと低リソース プログラミング言語のさらなる調査: 関数レベルのコード スニペットと共通の観点からの既存のアプローチプログラミング言語 十分な進歩が見られました。同時に、低リソース言語の拡張方法は、需要は高いにもかかわらず、比較的不足しています。これら 2 つの方向の探求はまだ限られており、著者らはこれらが有望な方向である可能性があると信じています。 社会的偏見の軽減: コード モデルがソフトウェア開発で進歩するにつれて、コード モデルは次のような人間中心のアプリケーション プログラムの開発に使用される可能性があります。人事と教育では、偏った手続きが過小評価された人々にとって不公平で非倫理的な決定につながる可能性があります。 NLP におけるソーシャル バイアスは十分に研究されており、データ拡張によって軽減できますが、コードにおけるソーシャル バイアスはまだ注目されていません。 小規模サンプル学習: 小規模サンプル シナリオでは、モデルは従来の機械学習モデルと同等のパフォーマンスを達成する必要がありますが、トレーニングはデータは非常に限られています。データ拡張手法は、この問題に対する直接的な解決策を提供します。ただし、小規模なサンプル シナリオでのデータ拡張手法の採用に関する取り組みは限られています。いくつかのサンプル シナリオにおいて、著者は、高品質の拡張データを生成することによって、モデルに迅速な一般化と問題解決機能をどのように提供するかという興味深い問題であると感じています。 マルチモーダル アプリケーション: 関数レベルのコード スニペットのみに焦点を当てると、実際のプログラミング状況を正確に表すことができないことに注意することが重要です。複雑さとニュアンス。この場合、開発者は通常、複数のファイルとフォルダーを同時に作業します。これらのマルチモーダル アプリケーションはますます人気が高まっていますが、データ拡張手法を適用した研究はありません。課題の 1 つは、コード モデル内の各モダリティの埋め込み表現を効果的に橋渡しすることであり、これは視覚と言語のマルチモーダル タスクで研究されています。 均一性の欠如: 現在のコード データ拡張に関する文献では、最も一般的なアプローチが補助的なものとして特徴付けられているという困難な状況が提示されています。いくつかの実証研究では、コード モデルのデータ拡張方法を比較することが試みられています。ただし、これらの作業は、既存の高度なデータ拡張手法のほとんどを活用していません。コンピューター ビジョン (PyTorch のデフォルトの拡張ライブラリなど) や NLP (NL-Augmenter など) には十分に確立されたデータ拡張フレームワークが存在しますが、コード モデルの汎用データ拡張技術に対応するライブラリが著しく不足しています。さらに、既存のデータ拡張手法はさまざまなデータセットを使用して評価されることが多いため、その有効性を判断することが困難です。したがって、標準化・統一されたベンチマークタスクや、異なる拡張手法の有効性を比較・評価するためのデータセットを確立することで、データ拡張研究の進展が大きく促進されると著者らは考えている。これにより、これらの方法の長所と限界をより体系的かつ比較的に理解するための道が開かれます。
以上がディープラーニングにおけるコードデータの拡張: 5 年間の 89 件の研究のレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
CENTOSシステムでGitLabログを表示するための完全なガイドこの記事では、メインログ、例外ログ、その他の関連ログなど、CentosシステムでさまざまなGitLabログを表示する方法をガイドします。ログファイルパスは、gitlabバージョンとインストール方法によって異なる場合があることに注意してください。次のパスが存在しない場合は、gitlabインストールディレクトリと構成ファイルを確認してください。 1.メインGitLabログの表示
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
