

わずか 3 分で大規模な言語モデル AI ナレッジ ベースを迅速に構築

FastGPT
FastGPT は、LLM ラージ言語モデルを使用して構築されたナレッジ ベースの質問と回答システムであり、プラグ アンド プレイのデータ処理とモデル呼び出し機能を提供できます。同時に、複雑な質問と回答のシナリオを実現するための Flow ビジュアル ワークフロー オーケストレーションもサポートしています。
ナレッジ ベースのコア フローチャート
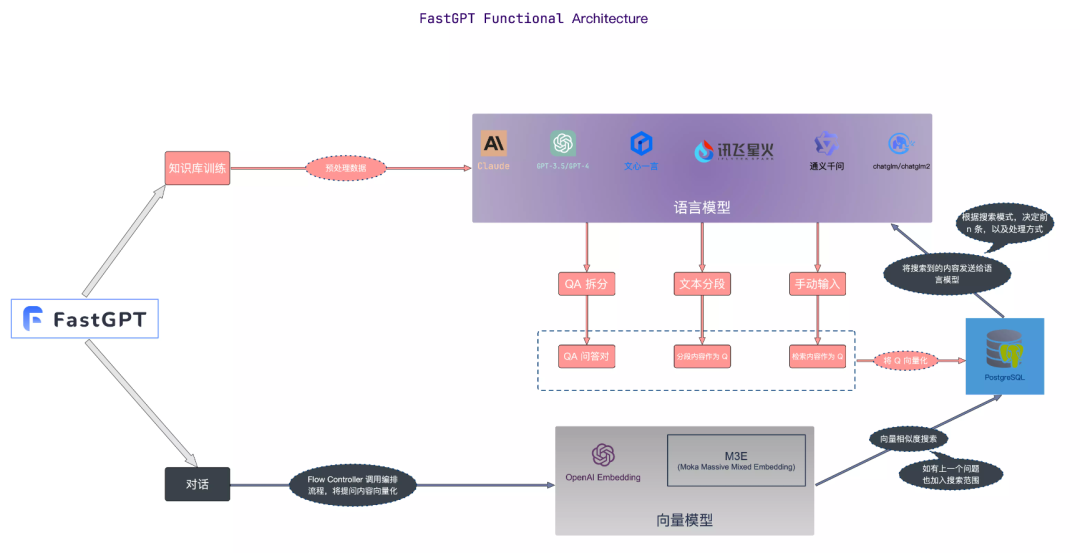 画像
画像
画像ソース: https://doc.fastgpt.in
プライベート デプロイメント
ここで Docker Compose を使用して、FastGPT プライベート化デプロイメントを迅速に実行します
1. Docker をインストールします
# 安装 Dockercurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyunsystemctl enable --now docker# 安装 docker-composecurl -L https://github.com/docker/compose/releases/download/2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-composechmod +x /usr/local/bin/docker-compose# 验证安装docker -vdocker-compose -v
すでにインストールされている場合は、直接スキップしてください
2. コンテナ オーケストレーション
ローカル ディレクトリを作成し、ディレクトリを入力します
mkdir tinywan-fastgptcd tinywan-fastgpt
上で作成したディレクトリ パスは /d/Tinywan/GPT/tinywan-fastgpt
docker-compose.yml 設定ファイル
version: '3.3'services:pg:image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云container_name: pgrestart: alwaysports: # 生产环境建议不要暴露- 5432:5432networks:- fastgptenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- POSTGRES_USER=username- POSTGRES_PASSWORD=password- POSTGRES_DB=postgresvolumes:- ./pg/data:/var/lib/postgresql/datamongo:image: mongo:5.0.18# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云container_name: mongorestart: alwaysports: # 生产环境建议不要暴露- 27017:27017networks:- fastgptenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- MONGO_INITDB_ROOT_USERNAME=username- MONGO_INITDB_ROOT_PASSWORD=passwordvolumes:- ./mongo/data:/data/dbfastgpt:container_name: fastgptimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云ports:- 3000:3000networks:- fastgptdepends_on:- mongo- pgrestart: alwaysenvironment:# root 密码,用户名为: root- DEFAULT_ROOT_PSW=123465# 中转地址,如果是用官方号,不需要管- OPENAI_BASE_URL=https://api.openai.com/v1- CHAT_API_KEY=sb-xxx- DB_MAX_LINK=5 # database max link- TOKEN_KEY=any- ROOT_KEY=root_key- FILE_TOKEN_KEY=filetoken# mongo 配置,不需要改. 如果连不上,可能需要去掉 ?authSource=admin- MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin# pg配置. 不需要改- PG_URL=postgresql://username:password@pg:5432/postgresvolumes:- ./config.json:/app/data/config.jsonnetworks:fastgpt:
注: 値を入力してくださいCHAT_API_KEYに対応します。
config.json 構成ファイル
{"SystemParams": {"pluginBaseUrl": "","vectorMaxProcess": 15,"qaMaxProcess": 15,"pgHNSWEfSearch": 100},"ChatModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","price": 0,"maxContext": 16000,"maxResponse": 4000,"quoteMaxToken": 2000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0,"quoteMaxToken": 8000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"quoteMaxToken": 4000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4-vision-preview","name": "GPT4-Vision","maxContext": 128000,"maxResponse": 4000,"price": 0,"quoteMaxToken": 100000,"maxTemperature": 1.2,"censor": false,"vision": true,"defaultSystemChatPrompt": ""}],"QAModels": [{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0}],"CQModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"functionCall": true,"functionPrompt": ""}],"ExtractModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""}],"QGModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 1600,"maxResponse": 4000,"price": 0}],"VectorModels": [{"model": "text-embedding-ada-002","name": "Embedding-2","price": 0.2,"defaultToken": 700,"maxToken": 3000}],"AudioSpeechModels": [{"model": "tts-1","name": "OpenAI TTS1","price": 0,"voices": [{"label": "Alloy","value": "alloy","bufferId": "openai-Alloy"},{"label": "Echo","value": "echo","bufferId": "openai-Echo"},{"label": "Fable","value": "fable","bufferId": "openai-Fable"},{"label": "Onyx","value": "onyx","bufferId": "openai-Onyx"},{"label": "Nova","value": "nova","bufferId": "openai-Nova"},{"label": "Shimmer","value": "shimmer","bufferId": "openai-Shimmer"}]}],"WhisperModel": {"model": "whisper-1","name": "Whisper1","price": 0}}3. コンテナーを開始します
コマンド docker-compose pull を使用してイメージの更新バージョンを取得します
 図
図
コマンド docker-compose up -d
 を使用してコンテナーを起動します。図
を使用してコンテナーを起動します。図
コンテナの起動ステータスの表示
 ##図
##図
##現在、IP:3000 経由の直接アクセスが利用可能です。これはローカル展開であるため、http://127.0.0.1:3000 を通じて直接アクセスできます。
デプロイは成功しました。次のページにアクセスできます:Picture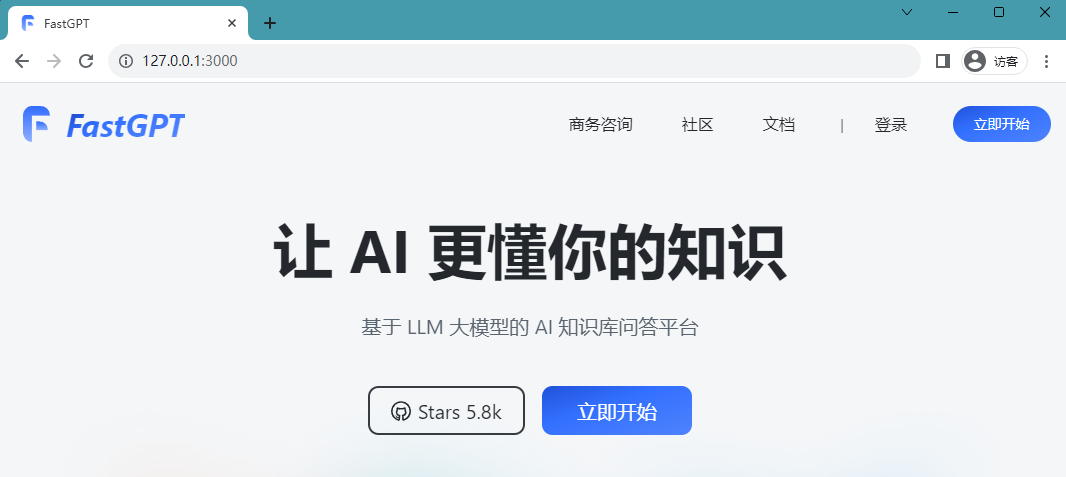 ログイン ユーザー名は次のとおりです。 root であり、パスワードは docker-compose.yml 環境変数に設定された DEFAULT_ROOT_PSW です。
ログイン ユーザー名は次のとおりです。 root であり、パスワードは docker-compose.yml 環境変数に設定された DEFAULT_ROOT_PSW です。
ログインに成功すると、次のページにリダイレクトされます:
Picture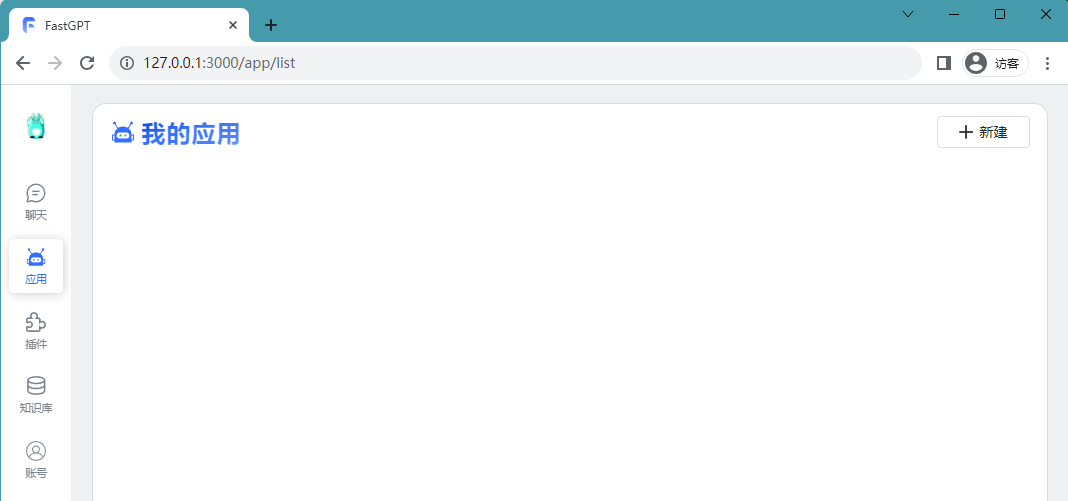 Build Knowledge Base
Build Knowledge Base
ナレッジ ベースの作成
ログインに成功したら、新しいナレッジ ベースを作成し、Open Source Technology Stack
Picture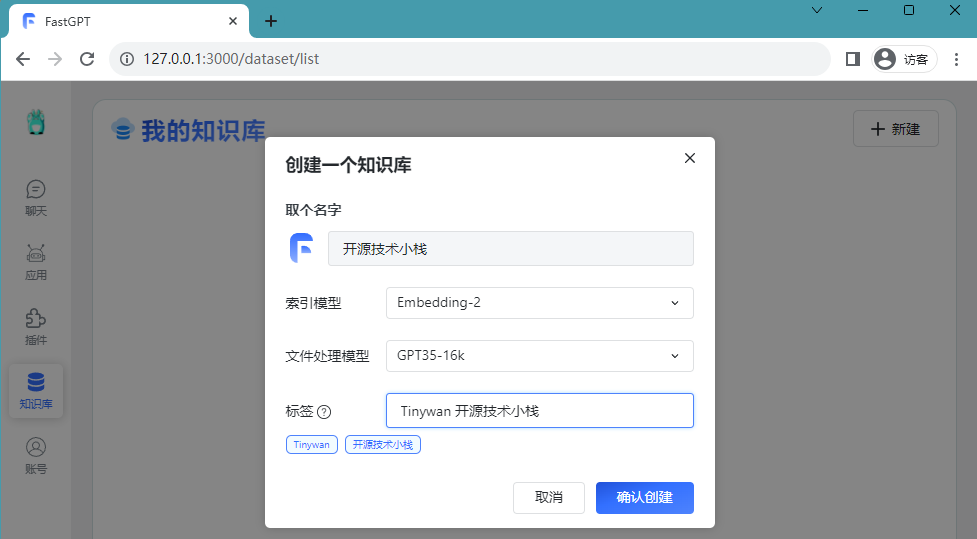 という名前を付けることができます。個人的な経験をナレッジ ベースにインポートする方法は、ファイル
という名前を付けることができます。個人的な経験をナレッジ ベースにインポートする方法は、ファイル
を使用することです。書き換える必要があるコンテンツは [新規/インポート] [ファイル インポート] です。 書き換え内容:[作成/インポート][ファイルインポート]
画像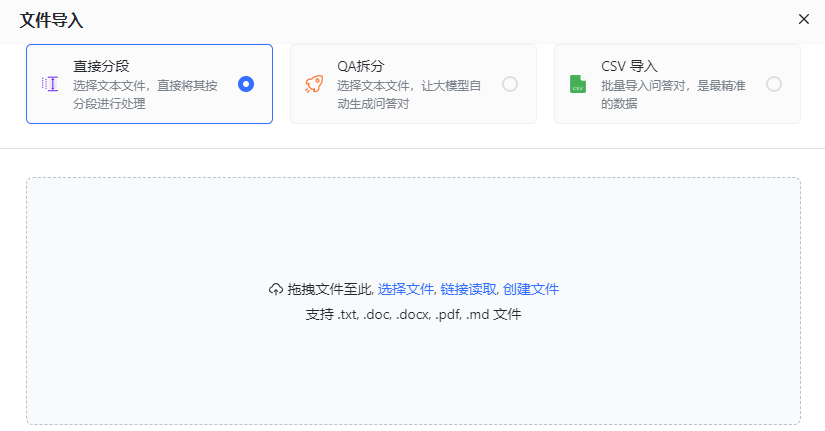 確認後、現在のデータからベクターデータへの変換を開始します
確認後、現在のデータからベクターデータへの変換を開始します
Picture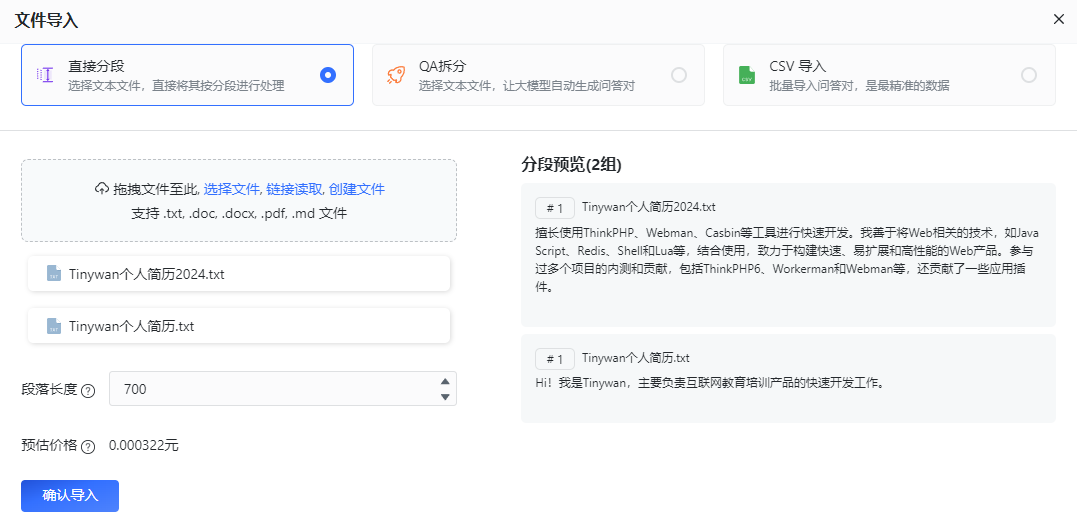 インポートするファイルを選択するときに、直接セグメンテーション プランを選択できます。直接セグメンテーションでは、文セグメンタを使用してテキストを特定の長さに分割し、最終的に複数の q のグループに分割します。ダイレクト セグメンテーション ソリューションを選択した場合、アプリケーションで参照プロンプト ワードを設定するときに、一般的なテンプレートを使用することをお勧めします。質問と回答のテンプレートを選択する必要はありません
インポートするファイルを選択するときに、直接セグメンテーション プランを選択できます。直接セグメンテーションでは、文セグメンタを使用してテキストを特定の長さに分割し、最終的に複数の q のグループに分割します。ダイレクト セグメンテーション ソリューションを選択した場合、アプリケーションで参照プロンプト ワードを設定するときに、一般的なテンプレートを使用することをお勧めします。質問と回答のテンプレートを選択する必要はありません
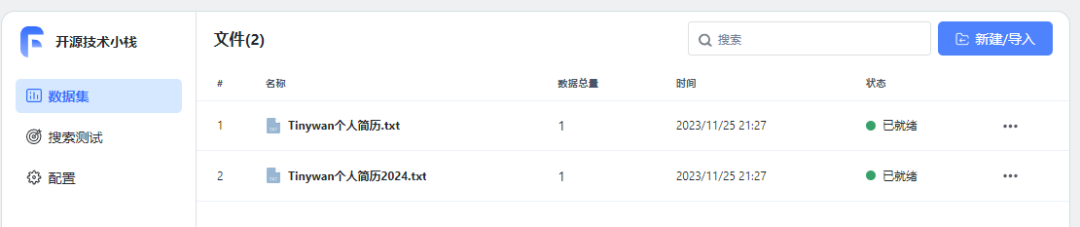
インポートは成功しました
 图片
图片
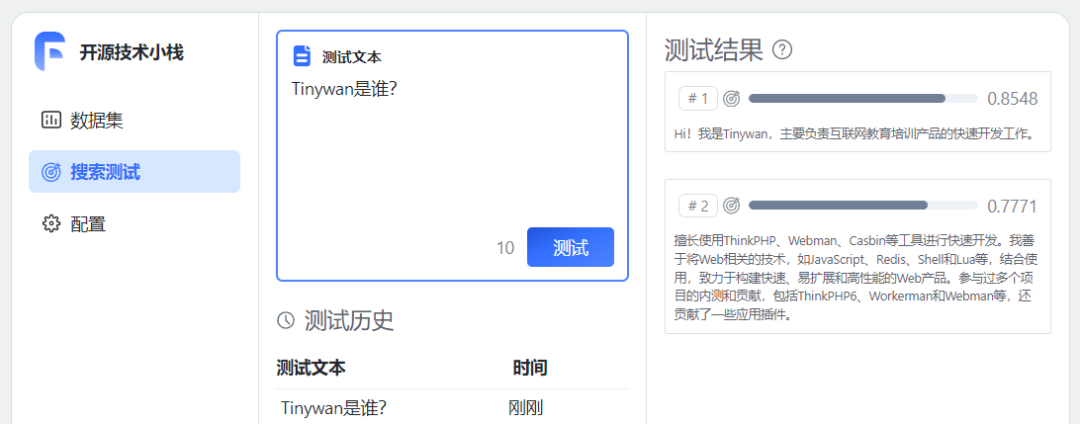
至此,个人知识库已经建好了。尝试进行测试问答
 图片
图片
重新书写后的内容:重新连接训练数据
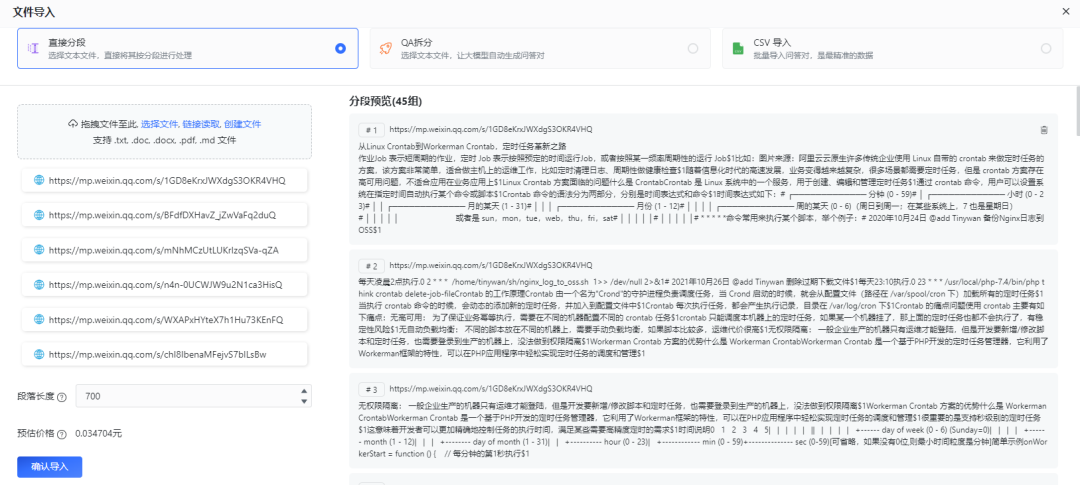
https://mp.weixin.qq.com/s/1GD8eKrxJWXdgS3OKR4VHQhttps://mp.weixin.qq.com/s/BFdfDXHavZ_jZwVaFq2duQhttps://mp.weixin.qq.com/s/mNhMCzUtLUKrIzqSVa-qZAhttps://mp.weixin.qq.com/s/n4n-0UCWJW9u2N1ca3HisQhttps://mp.weixin.qq.com/s/WXAPxHYteX7h1Hu73KEnFQhttps://mp.weixin.qq.com/s/chI8IbenaMFejvS7blLsBw
 图片
图片
等待所有数据准备就绪
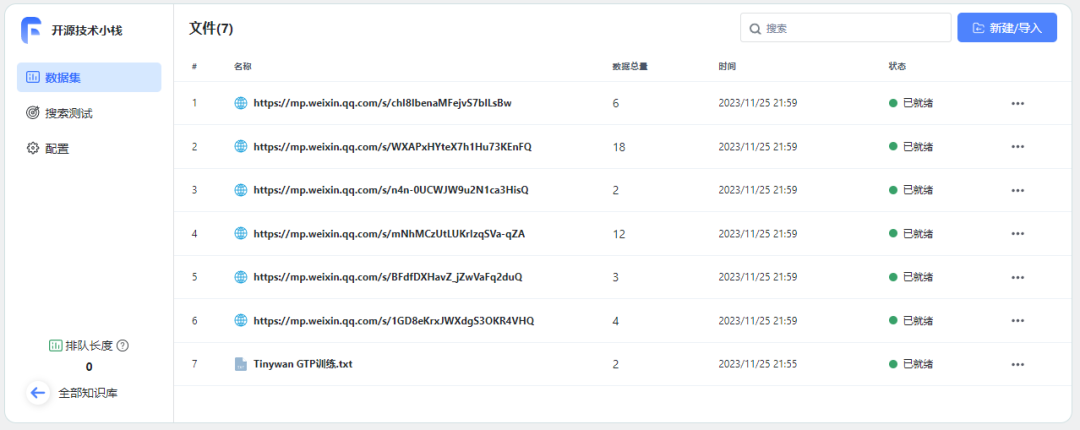 图片
图片
使用知识库
创建应用
使用知识库必须要创建一个应用
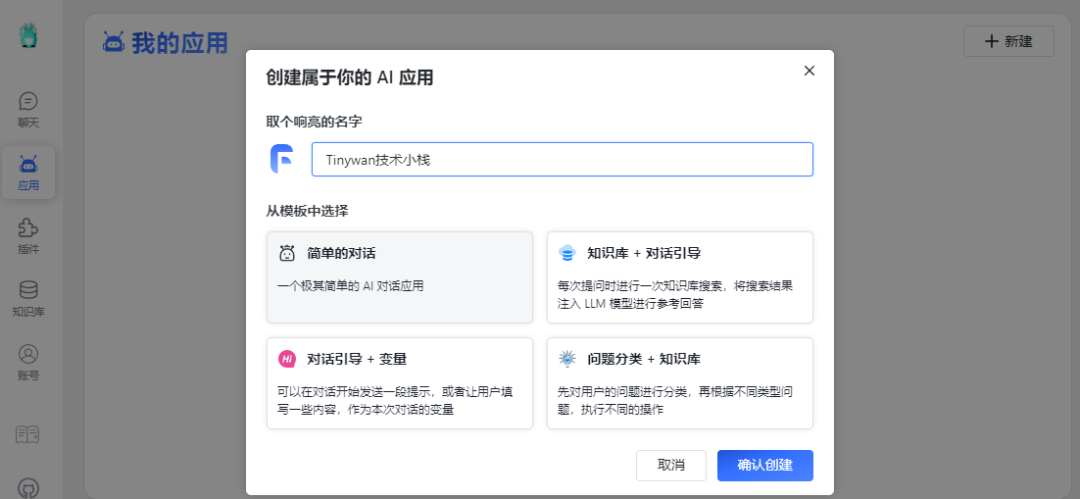 图片
图片
关联知识库
已添加开场白并选择绑定相应的知识库开源技术堆栈
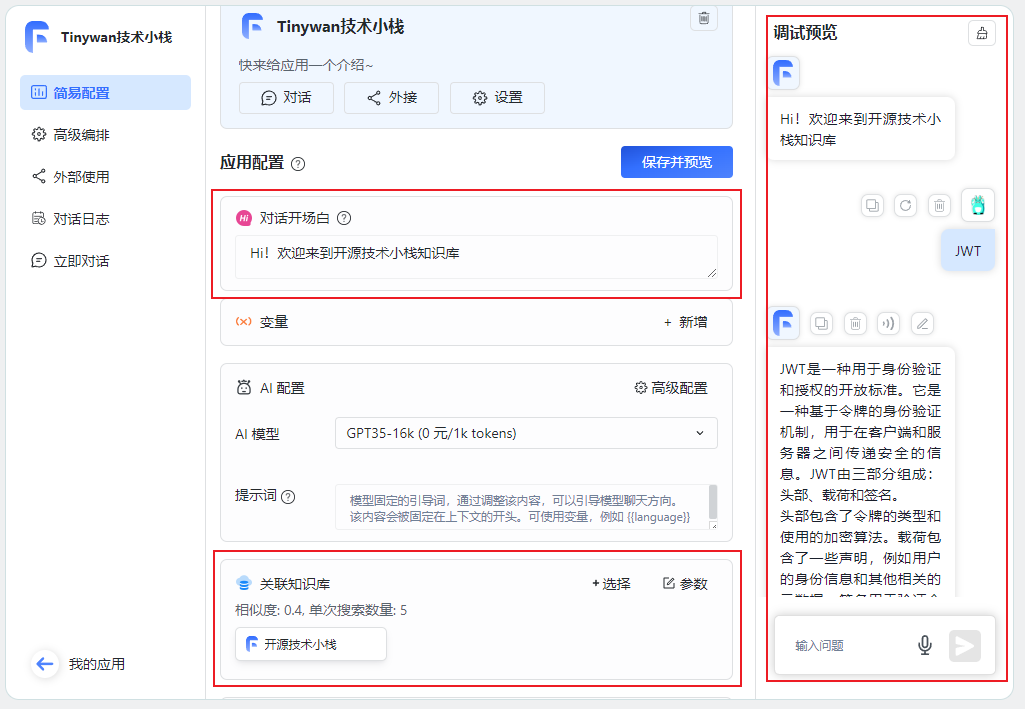 图片
图片
点击保存预留后,可以直接在右边调试预览框预览对话进行文档内容测试。
开始对话
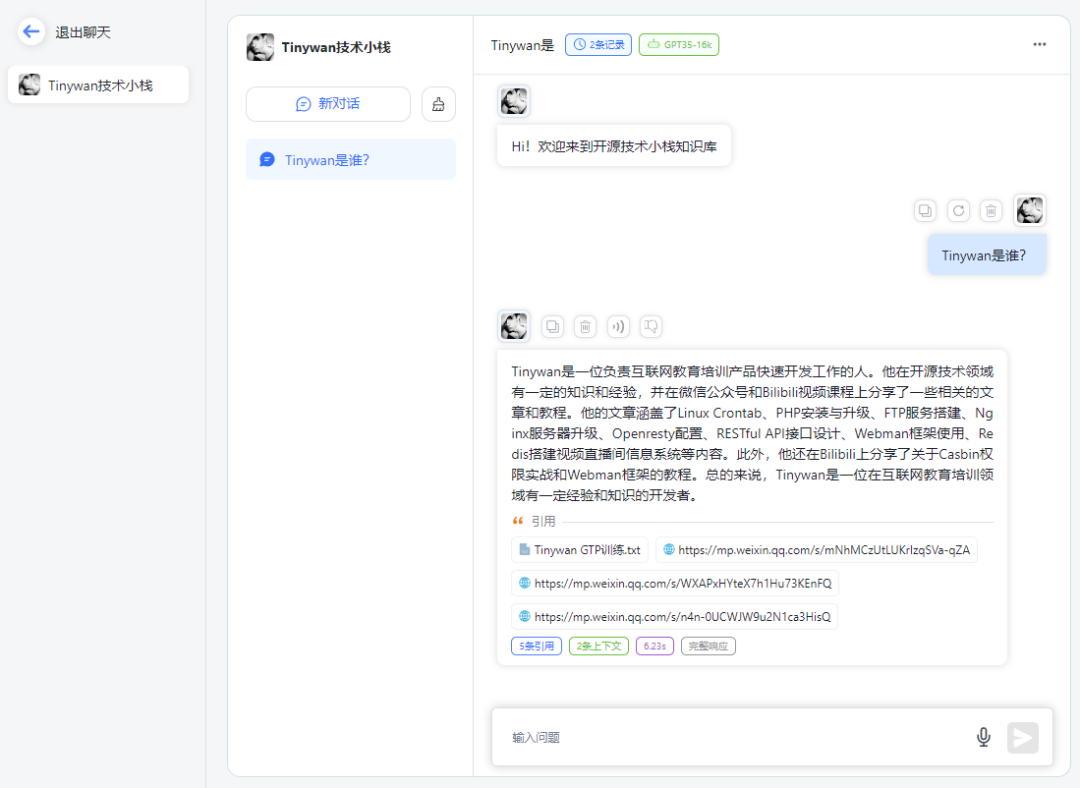 图片
图片
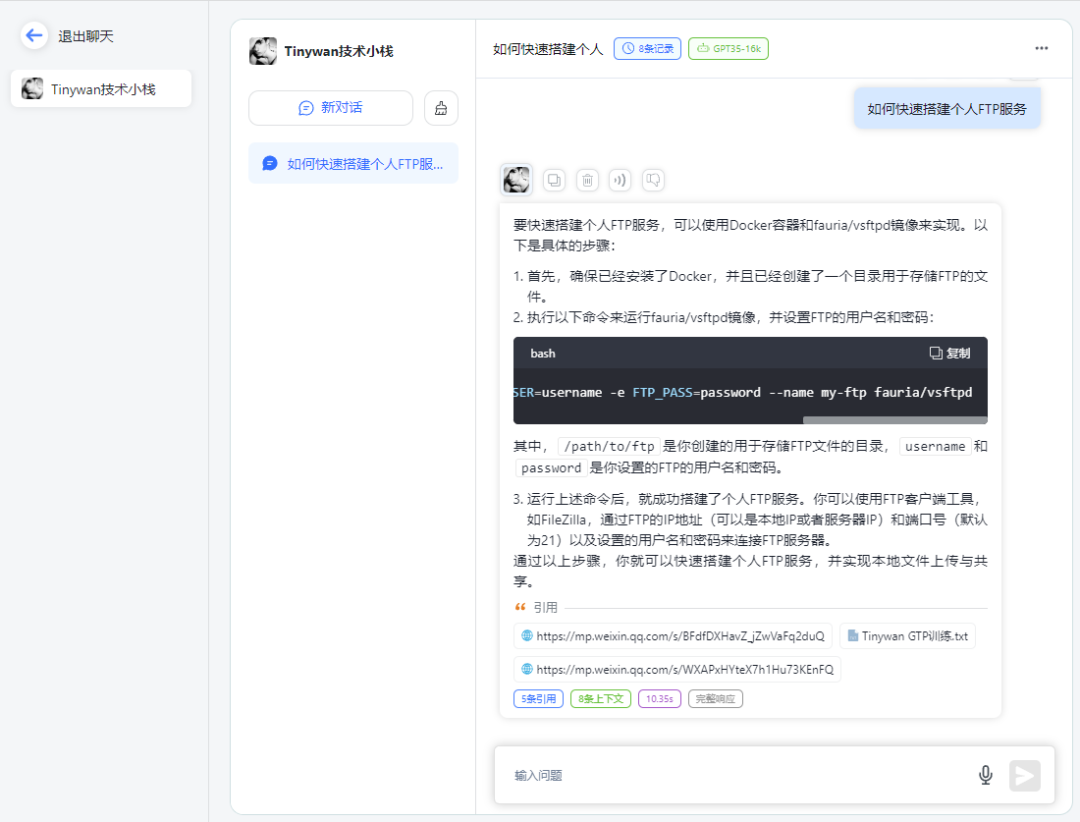 图片
图片
请点击链接查看知识库引用
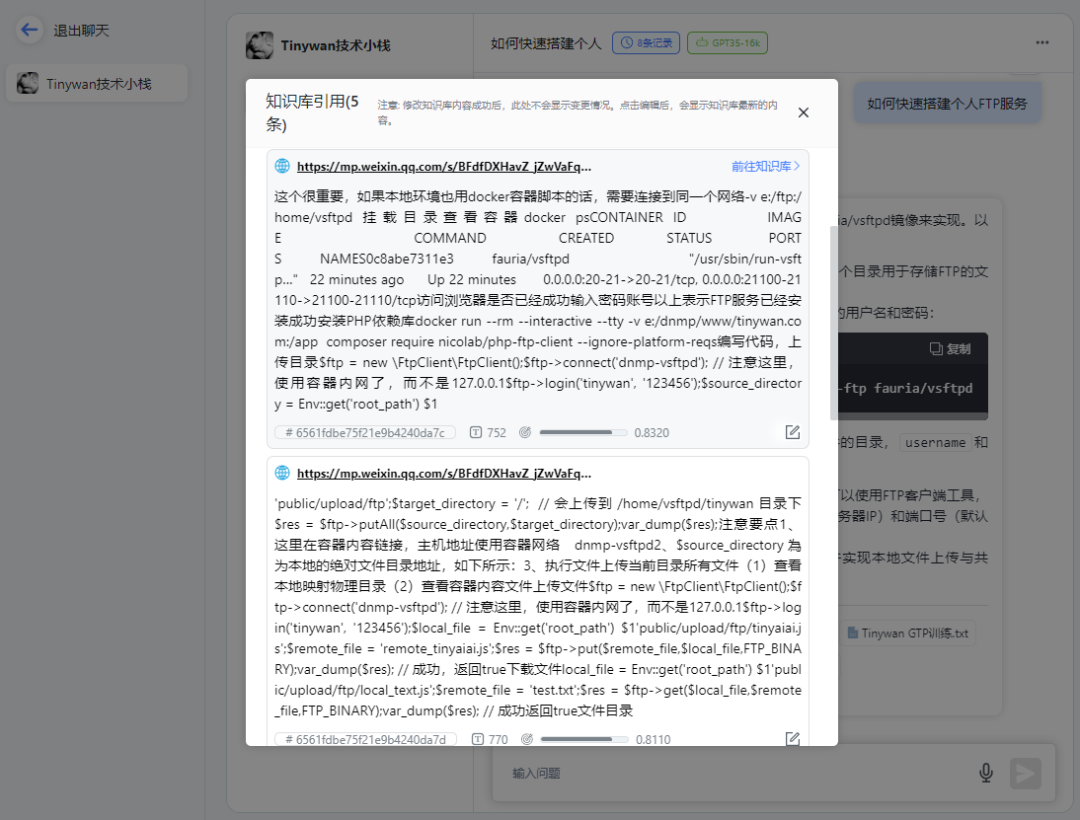 图片
图片
打开对应链接可以直接跳转到微信公众号文章地址
总结
构建私有数据训练服务,针对问题提供精准回答。可以通过AI服务训练自有数据,形成AI知识库,然后创建不同的机器人针对用户问题提供精准回答。并且可以通过API接口很方便整合到自己的产品服务中。
以上がわずか 3 分で大規模な言語モデル AI ナレッジ ベースを迅速に構築の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
CENTOSシステムでGitLabログを表示するための完全なガイドこの記事では、メインログ、例外ログ、その他の関連ログなど、CentosシステムでさまざまなGitLabログを表示する方法をガイドします。ログファイルパスは、gitlabバージョンとインストール方法によって異なる場合があることに注意してください。次のパスが存在しない場合は、gitlabインストールディレクトリと構成ファイルを確認してください。 1.メインGitLabログの表示
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
