

pdfからxml形式へ

PDF を XML 形式に変換する方法: 1. Adobe Acrobat を使用する; 2. オンライン ツールを使用する; 3. プログラミング言語とライブラリを使用する; 4. OCR テクノロジを使用する。 PDF を XML 形式に変換すると、ドキュメント処理やデータ抽出が非常に便利になります。 XML 形式はより構造化されており、データ分析、検索エンジンの最適化、データ交換などのアプリケーションに適しています。 PDF を XML 形式に変換するには、ニーズやリソースに応じていくつかの方法が利用できますが、どの方法を選択する場合でも、変換結果が正確で期待どおりであることを確認する必要があります。

#PDF を XML 形式に変換すると、ドキュメント処理やデータ抽出が非常に便利になります。 XML 形式はより構造化されており、データ分析、検索エンジンの最適化、データ交換などのアプリケーションに適しています。 PDF を XML 形式に変換する方法は次のとおりです。
方法 1: Adobe Acrobat を使用する
Adobe Acrobat は、PDF を複数の形式に変換する機能を提供する人気の PDF 編集ツールです。 XML。 Adobe Acrobat を使用して変換する手順は次のとおりです:
1. PDF ファイルを開きます: Adobe Acrobat を使用して、変換する PDF ファイルを開きます。
2. [ファイル] > [別名で保存] > [XML] を選択します: メニューで [ファイル] を選択し、次に [別名で保存] を選択し、次に [XML] を選択します。
3. XML オプションの設定: ポップアップ ダイアログ ボックスで、要素タグやエンコード方法などの変換オプションを設定できます。必要に応じて設定します。
4. [保存] をクリックします: [保存] ボタンをクリックし、XML ファイルを保存する場所を選択し、保存を確認します。
5. 変換の完了: Adobe Acrobat は PDF ファイルから XML 形式への変換を開始します。変換が完了すると、指定した保存場所に XML ファイルが表示されます。
方法 2: オンライン ツールを使用する
PDF ファイルを XML 形式に変換できるオンライン ツールもあります。これらのツールは通常便利で、追加のソフトウェアをインストールする必要はありません。オンライン ツールを使用するための一般的な手順は次のとおりです:
1. オンライン ツール Web サイトを開きます: ILovePDF、Smallpdf、PDFTables などの信頼できるオンライン PDF to XML ツールを選択します。
2. PDF ファイルのアップロード: 通常、これらのツールには、変換する PDF ファイルをアップロードするためのアップロード ボタンまたはドラッグ アンド ドロップ領域が用意されています。
3. 変換の開始: アップロード後、[変換の開始] または対応するオプションを選択して、変換プロセスを開始します。このツールは PDF ファイルを自動的に処理し、XML に変換します。
4. XML ファイルをダウンロードする: 変換が完了すると、通常、ツールは生成された XML ファイルをダウンロードするためのリンクまたはボタンを提供します。リンクをクリックしてダウンロードします。
オンライン ツールを使用する場合、PDF ファイルがサードパーティのサーバーにアップロードされる可能性があることに注意してください。そのため、機密データを変換する場合は、信頼できるツールを選択し、適切なプライバシーとセキュリティ対策を講じてください。
方法 3: プログラミング言語とライブラリの使用
PDF から XML への大量のバッチ変換を実行する必要がある場合、または処理を自動化する必要がある場合は、プログラミング言語を使用できます。およびこのタスクを実行する関連ライブラリ。 Python と Python ライブラリ `pdf2xml` を使用した変換の例を次に示します。
# 安装 pdf2xml 库 # pip install pdf2xml import subprocess # 调用 pdf2xml 命令行工具将 PDF 转换为 XML pdf_file = "input.pdf" xml_file = "output.xml" subprocess.call(["pdf2xml", pdf_file, xml_file])
これは簡単な例であり、必要に応じて変換プロセスをさらにカスタマイズおよび拡張できます。 Java、C#、Ruby などの他のプログラミング言語も、同様の PDF から XML への変換ライブラリおよびツールを提供します。
方法 4: OCR テクノロジを使用する
PDF ドキュメントがスキャンされた画像または画像を含む PDF である場合は、OCR (光学文字認識) テクノロジを使用してテキストに変換する必要がある場合があります。次に、テキストを XML に変換します。一般的な手順は次のとおりです:
1. OCR ソフトウェアまたはライブラリを使用して、画像 PDF を検索可能な PDF (PDF/A) やプレーン テキストなどのテキスト形式に変換します。
2. 次に、テキスト処理ツール (Python の Beautiful Soup や正規表現など) を使用して、テキストから必要な情報を抽出し、XML 形式に編成します。
この方法は、スキャンしたドキュメントからテキストを抽出して構造化データに変換する必要がある状況に適しています。
注:
- 変換結果は、PDF ファイルの複雑さと形式によって異なる場合があります。 PDF によっては非常に正確に変換できるものもありますが、手動によるクリーニングと修復が必要な PDF もあります。
#- PDF ファイル内のテキストと構造が変換プロセス中に正しく保持されていることを確認する必要があります。これは、PDF ファイルの品質と元の作成方法によって異なります。#- 大規模な PDF または複雑な構造の場合、結果の XML データが期待どおりであることを確認するために、さらに多くの処理とクリーンアップが必要になる場合があります。
要約すると、ニーズとリソースに応じて、PDF を XML 形式に変換する方法がいくつかあります。データ抽出と分析のニーズに合わせて、デスクトップ アプリケーション、オンライン ツール、プログラミング言語、または OCR テクノロジーの使用を選択できます。どちらの方法を選択する場合でも、変換結果が正確で期待どおりであることを確認する必要があります。
以上がpdfからxml形式への詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

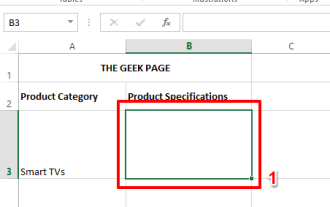 PDF ドキュメントを Excel ワークシートに埋め込む方法
May 28, 2023 am 09:17 AM
PDF ドキュメントを Excel ワークシートに埋め込む方法
May 28, 2023 am 09:17 AM
通常、PDF ドキュメントを Excel ワークシートに挿入する必要があります。会社のプロジェクトリストと同じように、Excel のセルにテキストや文字データを瞬時に追加できます。しかし、特定のプロジェクトのソリューション設計を対応するデータ行に添付したい場合はどうすればよいでしょうか?さて、人はよく立ち止まって考えることがあります。解決策が単純ではないために、考えてもうまくいかないこともあります。この記事をさらに詳しく読んで、特定のデータ行とともに複数の PDF ドキュメントを Excel ワークシートに簡単に挿入する方法を学びましょう。シナリオ例 この記事に示されている例には、各セルにプロジェクト名をリストする ProductCategory という列があります。別の列 ProductSpeci
 iPhoneでPDFを結合する方法
Feb 02, 2024 pm 04:05 PM
iPhoneでPDFを結合する方法
Feb 02, 2024 pm 04:05 PM
複数のドキュメントまたは同じドキュメントの複数ページを操作する場合、それらを 1 つのファイルに結合して他のユーザーと共有したい場合があります。共有を容易にするために、Apple では複数の PDF ファイルを 1 つのファイルに結合して、複数のファイルの送信を避けることができます。この記事では、iPhone で 2 つ以上の PDF を 1 つの PDF ファイルに結合するすべての方法を説明します。 iPhone で PDF を結合する方法 iOS では、ファイル アプリとショートカット アプリを使用する 2 つの方法で PDF ファイルを 1 つに結合できます。方法 1: ファイル アプリを使用する 2 つ以上の PDF を 1 つのファイルに結合する最も簡単な方法は、ファイル アプリを使用することです。 iPhoneで開く
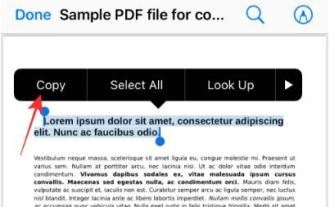 iPhoneでPDFからテキストを取得する3つの方法
Mar 16, 2024 pm 09:20 PM
iPhoneでPDFからテキストを取得する3つの方法
Mar 16, 2024 pm 09:20 PM
Apple の Live Text 機能は、写真やカメラ アプリ内のテキスト、手書きのメモ、数字を認識し、その情報を他のアプリに貼り付けることができます。しかし、PDF を操作していてそこからテキストを抽出したい場合はどうすればよいでしょうか?この記事では、iPhoneでPDFファイルからテキストを抽出する方法をすべて説明します。 iPhone で PDF ファイルからテキストを取得する方法 [3 つの方法] 方法 1: PDF 上にテキストをドラッグ PDF からテキストを抽出する最も簡単な方法は、テキストを含む他のアプリと同じように、テキストをコピーすることです。 1. テキストを抽出する PDF ファイルを開き、PDF 上の任意の場所を長押しして、コピーするテキストの部分のドラッグを開始します。 2
 PDFの署名を検証する方法
Feb 18, 2024 pm 05:33 PM
PDFの署名を検証する方法
Feb 18, 2024 pm 05:33 PM
私たちは通常、政府やその他の機関から PDF ファイルを受け取りますが、中にはデジタル署名が付いているものもあります。署名を検証すると、SignatureValid メッセージと緑色のチェック マークが表示されます。署名が検証されない場合、有効性は不明です。署名の検証は重要です。PDF で署名を検証する方法を見てみましょう。 PDF 形式の署名を検証する方法 PDF 形式で署名を検証すると、署名の信頼性が高まり、文書が受け入れられる可能性が高くなります。次の方法で PDF ドキュメントの署名を検証できます。 Adobe Reader で PDF を開きます。 署名を右クリックし、「署名プロパティの表示」を選択します。 「署名者証明書の表示」ボタンをクリックします。 「信頼」タブから信頼できる証明書リストに署名を追加します。 「署名の検証」をクリックして検証を完了します。
 PHPを使用してPDFファイルを処理する方法
Jun 19, 2023 pm 02:41 PM
PHPを使用してPDFファイルを処理する方法
Jun 19, 2023 pm 02:41 PM
PDF ファイルは汎用ファイル形式として、電子書籍、レポート、契約書などのさまざまなアプリケーション シナリオで広く使用されています。開発プロセスでは、PDF ファイルの生成、編集、読み取りなどの操作が必要になることがよくあります。 PHP はスクリプト言語として、これらのタスクを簡単に実行することもできます。この記事では、PHPを使用してPDFファイルを処理する方法を紹介します。 1. PDF ファイルを生成する PDF ファイルを生成するにはさまざまな方法がありますが、最も一般的な方法は PDF ライブラリを使用することです。 PDF ライブラリは、PDF ドキュメントを生成するツールです。
 pdgファイルをpdfに変換する方法
Nov 14, 2023 am 10:41 AM
pdgファイルをpdfに変換する方法
Nov 14, 2023 am 10:41 AM
方法には、1. 専門的なドキュメント変換ツールを使用する、2. オンライン変換ツールを使用する、3. 仮想プリンターを使用するなどがあります。
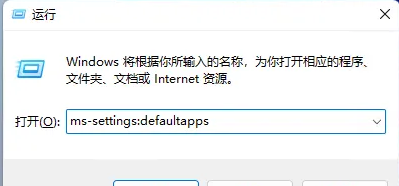 win11 で PDF のデフォルトの開き方を設定する方法 win11 で PDF のデフォルトの開き方を設定するチュートリアル
Feb 29, 2024 pm 09:01 PM
win11 で PDF のデフォルトの開き方を設定する方法 win11 で PDF のデフォルトの開き方を設定するチュートリアル
Feb 29, 2024 pm 09:01 PM
PDF ファイルを開くたびに開き方を選択するのが面倒で、よく使う開き方をデフォルトに設定したいユーザーもいますが、win11 でデフォルトの PDF 開き方を設定するにはどうすればよいでしょうか? win11でデフォルトのPDFを開く方法を設定するチュートリアルは、以下のエディターで詳しく紹介していますので、興味のある方はぜひご覧ください。 win11 で PDF のデフォルトの開き方を設定するチュートリアル 1. ショートカット キー「win+R」でファイルを開き、「ms-settings:defaultapps」コマンドを入力して Enter キーを押して開きます。 2. 新しいインターフェースに入ったら、上の検索ボックスに「.pdf」と入力し、検索アイコンをクリックして検索します。 3.これ
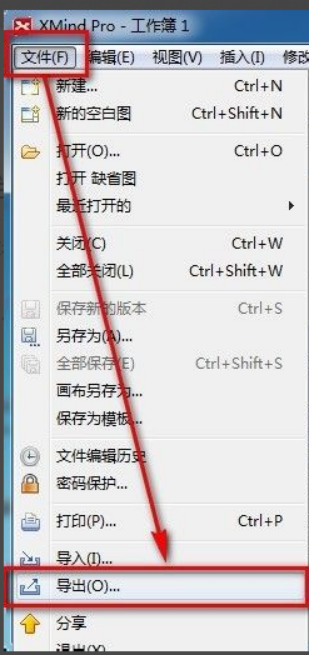 xmind ファイルを PDF ファイルにエクスポートする方法
Mar 20, 2024 am 10:30 AM
xmind ファイルを PDF ファイルにエクスポートする方法
Mar 20, 2024 am 10:30 AM
xmind は、非常に実用的なマインド マッピング ソフトウェアです。人々の思考とインスピレーションを使用して作成されたマップ形式です。xmind ファイルを作成した後、通常、誰もが配布して使用できるように、PDF ファイル形式に変換します。次に、xmind ファイルをエクスポートする方法PDFファイルに?以下に具体的な手順を示しますので、ご参照ください。 1. まず、マインド マップを PDF ドキュメントにエクスポートする方法を説明します。 [ファイル]-[エクスポート]機能ボタンを選択します。 2. 新しく表示されたインターフェースで[PDFドキュメント]を選択し、[次へ]ボタンをクリックします。 3. エクスポート インターフェイスで、用紙サイズ、方向、解像度、ドキュメントの保存場所などの設定を選択します。設定が完了したら、[完了]ボタンをクリックします。 4. [完了]ボタンをクリックした場合