

今年、人工知能の分野では大規模言語モデル (LLM) が大きな注目を集めています。 LLM は、さまざまな自然言語処理 (NLP) タスク、特に推論において大きな進歩を遂げました。ただし、複雑な推論タスクにおける LLM のパフォーマンスはまだ改善の必要があります。
LLM は、自身の推論にエラーがあると判断できますか?ケンブリッジ大学と Google Research が共同で実施した最近の研究では、LLM が独自に推論エラーを検出することはできなかったものの、研究で提案されたバックトラッキング手法を使用してそれらを修正できたことが判明しました。

Huang et al. in the Paper 「「大規模な言語モデル」は推論をまだ自己修正できません」は次のように指摘しています: 自己修正はモデル出力のスタイルと品質を改善するのに効果的かもしれませんが、LLM が独自の推論と論理を識別して修正する能力があるという証拠はほとんどありません。外部フィードバックなしのエラー。たとえば、Reflexion と RCI はどちらも、自己修正サイクルを停止する信号としてグラウンド トゥルースの修正結果を使用します。
#ケンブリッジ大学と Google Research の研究チームは、自己修正プロセスをエラー発見と出力修正の 2 つの段階に分割するという新しいアイデアを提案しました。
エラー検出は、哲学、心理学、数学の分野で広く研究および応用されている基本的な推論スキルであり、批判的思考、論理的および数学的誤謬などの概念を生み出してきました。エラーを検出する機能も LLM の重要な要件であると考えるのが合理的です。ただし、私たちの結果は、最先端の LLM が現時点でエラーを確実に検出できないことを示しています。
思考チェーン プロンプト設計手法を使用すると、あらゆるタスクを間違い発見ミッション。この目的のために、研究者らは、PaLM によって生成され、最初の論理エラーの位置をマークした CoT タイプの軌道情報データセット BIG-Bench Mistake を収集し、公開しました。研究者らは、BIG-Bench Mistake は数学的問題に限定されないこの種の最初のデータセットであると述べています。
これらの軌跡は、BIG-Bench データセット内の 5 つのタスクからのものです。並べ替え、シャッフルされたオブジェクトの追跡、論理的推論、複数ステップの算術、および Dyck 言語。

各タスクの質問に答えるために、CoT プロンプト設計手法を使用して PaLM 2 を呼び出しました。 CoT の軌跡を明確なステップに分離するために、「React: 言語モデルにおける推論と動作の相乗化」で提案されている方法を使用して、各ステップを個別に生成し、改行を停止マーカーとして使用しました
このデータセットで温度 = 0 のときにすべての軌跡が生成されると、答えの正しさは完全一致によって決まります
新しいバグ発見データセットで報告されている GPT-4-Turbo、GPT-4、および GPT-3.5-Turbo の精度を表 4
に示します。 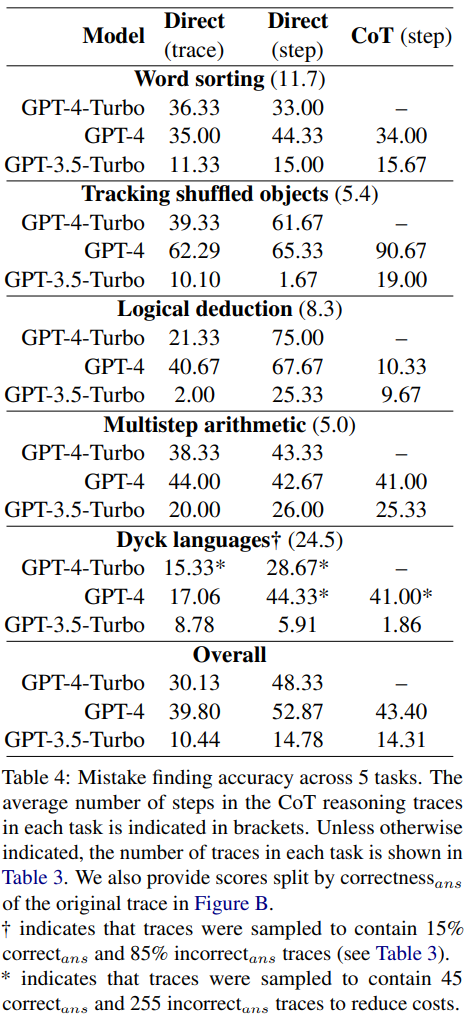
すべてのモデルは同じ 3 つのプロンプトで入力されました。彼らは 3 つの異なるプロンプト設計方法を使用しました。
書き直す必要がある内容は次のとおりです: 関連するディスカッション
結果は、3 つのモデルすべてがこの新しいエラー発見データセットに対処するのに苦労していることを示しています。 GPT は最高のパフォーマンスを発揮しますが、直接ステップレベルのプロンプト設計では全体の精度は 52.87 しか達成できません。これは、現在の最先端の LLM が、たとえ最も単純で明確なケースであっても、エラーを見つけるのが難しいことを示しています。対照的に、人間は特別な専門知識がなくても、高い一貫性を持ってエラーを見つけることができます。
研究者らは、LLM が推論エラーを自己修正できない主な理由は、LLM がエラーを検出できないことであると推測しています。
プロンプト設計手法の比較
研究者らは、直接軌道レベルのアプローチからステップへの移行が重要であることを発見しました。 -レベルのアプローチ CoT メソッドに移行すると、エラーが発生せずに軌道の精度が大幅に低下します。図 1 は、このトレードオフを示しています
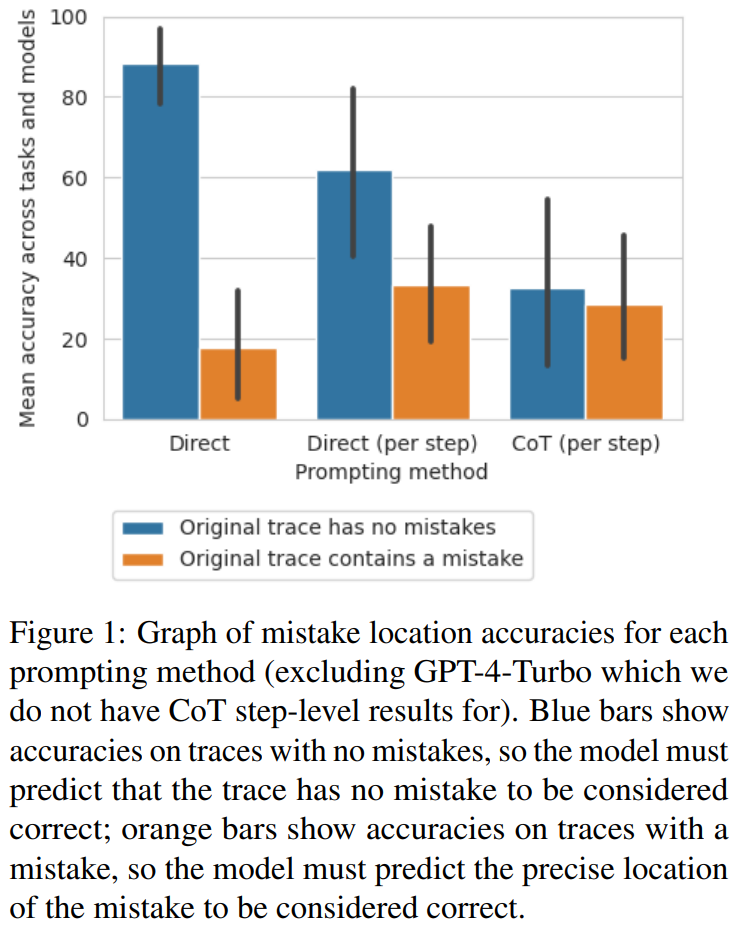
少数ショットエラー位置を正確さの代用として使用するプロンプト設計
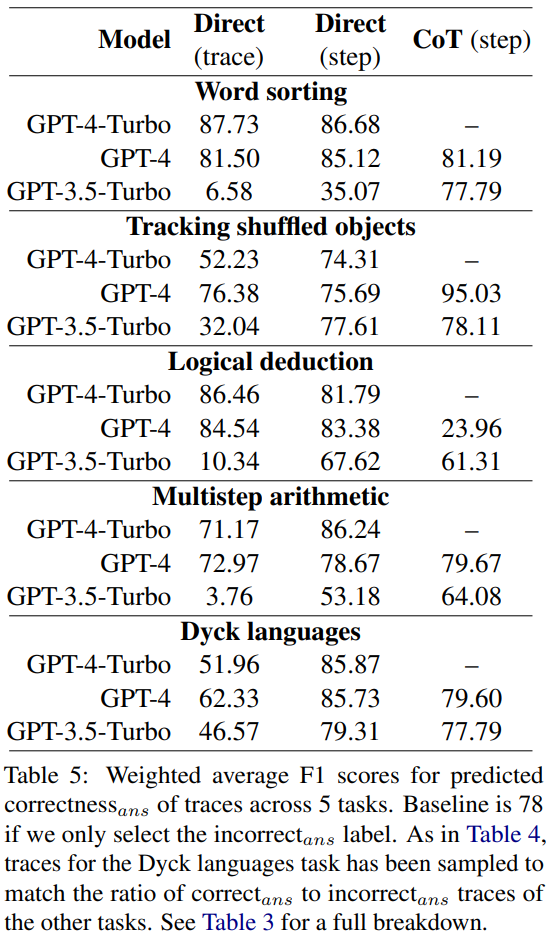
研究者らは、これらのプロンプト設計方法がエラー位置ではなく軌道の正しさを確実に判断できるかどうかを調査しました。彼らは平均 F1 スコアを計算しました。これは、モデルが軌道にエラーがあるかどうかを正しく予測できるかどうかに基づいています。エラーがある場合、モデルによって予測された軌道は「誤った答え」とみなされます。それ以外の場合は、モデルによって予測された軌跡が「正しい答え」とみなされます。
correct_ans と unavailable_ans を肯定的なラベルとして使用し、各ラベルの出現数に応じて重み付けを行って、研究者らは計算しました。平均 F1 スコアの結果を表 5 に示します。
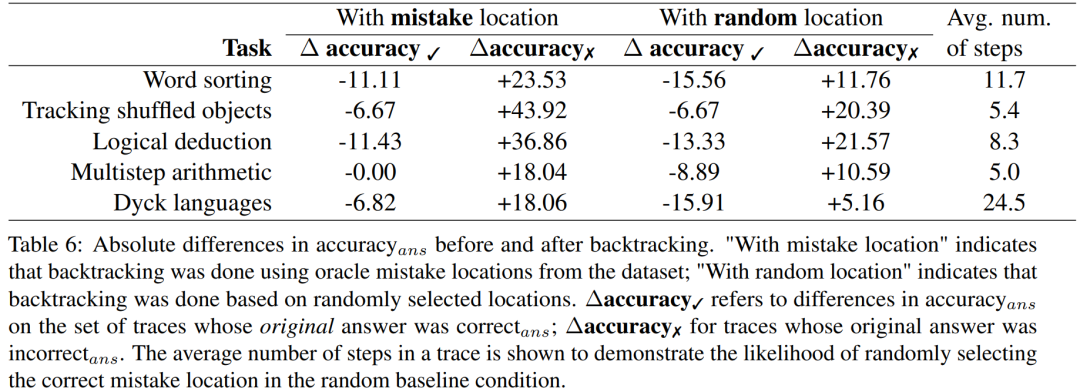
バックトラック
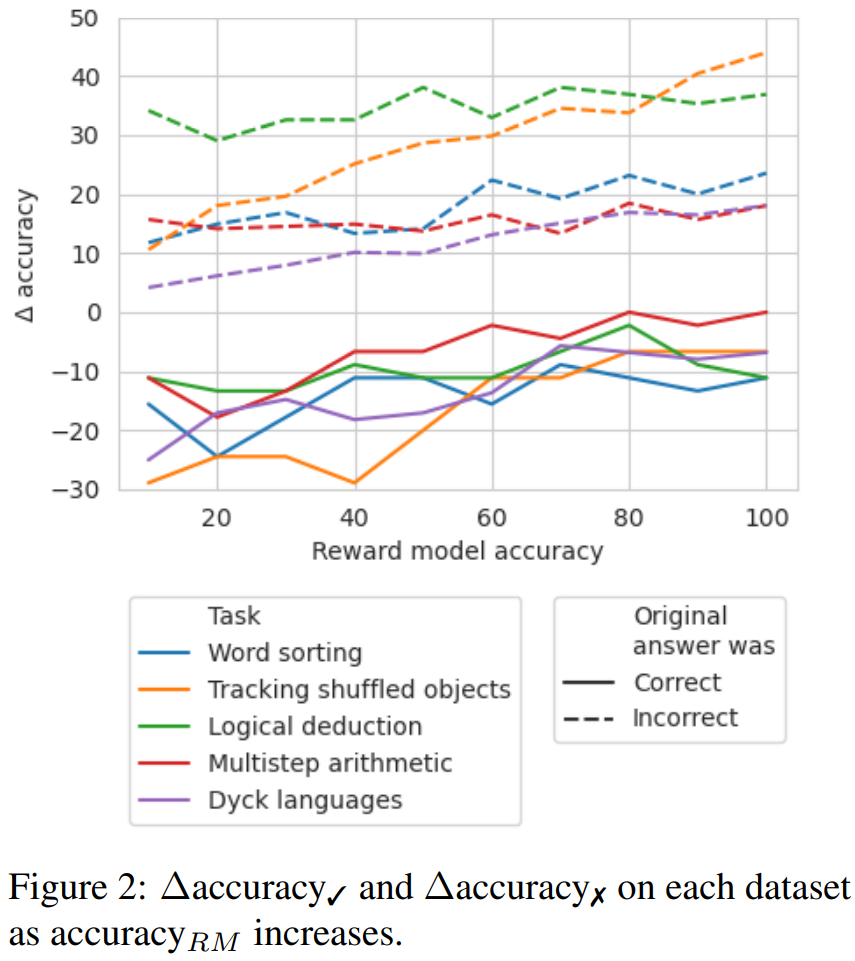
研究者は、論理エラーの位置をバックトラックすることでモデルの出力を改善する簡単な方法を提案しました。 以前の自己修正方法と比較して、このバックトラッキング方法には多くの利点があります。 研究者らは、バックトラッキング手法が LLM の論理エラーの修正に役立つかどうかを調査するために、BIG-Bench Mistake データセットを使用した実験を実施しました。実験結果については表 6 を参照してください。 Δaccuracy✓ は、元の答えが正しい場合に設定された軌道を指します_ans 違い精度_ansの間。 不正解の軌跡の結果については、精度を再計算する必要があります これらのスコア結果は、不正解の軌跡を修正する利点を示しています。元の正解を変更するよりも、引き起こされる損害に対して大きな影響を及ぼします。さらに、ランダム ベンチマークでも改善は得られますが、その改善は実際のエラー位置を使用した場合よりも大幅に小さくなります。ランダム化されたベンチマークでは、真のエラーの場所を見つける可能性が高いため、ステップ数が少ないタスクでパフォーマンスが向上する可能性が高くなります。 適切なラベルが利用できない場合にどの精度レベルの報酬モデルが必要であるかを調査するために、シミュレートされた報酬モデルによるバックトラッキングの使用を実験しました。このシミュレートされた報酬モデルの設計の目標は、さまざまな精度レベルのラベルを作成します。これらは、accuracy_RM を使用して、指定されたエラー位置におけるシミュレーション報酬モデルの精度を表します。 特定の報酬モデルの precision_RM が X% の場合、X% の確率で BIG-Bench Mistake のエラー位置を使用します。残りの (100 − X)% については、エラー位置がランダムにサンプリングされます。一般的な分類器の動作をシミュレートするために、データ セットの分布と一致する方法でエラー位置がサンプリングされます。研究者らはまた、サンプルの間違った位置が正しい位置と一致しないことを確認する方法も発見した。結果を図 2 に示します。 #損失率が 65% に達すると、Δ 精度が安定し始めることがわかります。実際、ほとんどのタスクでは、accuracy_RM が約 60 ~ 70% のときに、Δaccuracy ✓ がすでに Δaccuracy ✗ を超えています。これは、精度が高いほど結果は良くなりますが、ゴールドスタンダードのエラー位置ラベル がなくてもバックトラッキングは機能することを示しています。
以上がGoogle: LLM は推論エラーを見つけられないが、修正できるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



