

翻訳者| ##この記事では、「フューショット (Few-shot
)」に関連する概念を紹介します。そして、広く使用されているテキスト分類のSetFit 方法に焦点を当てます。
従来の機械学習 (ML) 監視下 (S
uppervised
Sentence Transformer の微調整(SetFit ) その前に、自然言語処理 (
自然言語処理、NLP) の重要な側面を簡単に復習する必要があります。それは「数回の学習」です。 # 少数ショット学習# 少数ショット学習とは、限られたトレーニング データ セットを使用することを意味します。モデルをトレーニングします。モデルは、サポート セットと呼ばれるこれらの小さなコレクションから知識を取得できます。このタイプの学習は、トレーニング データの類似点と相違点を認識するように少数ショット モデルを教えることを目的としています。たとえば、与えられた画像を猫か犬として分類するようにモデルに指示するのではなく、さまざまな動物間の共通点と相違点を把握するように指示します。見てわかるように、このアプローチは入力データの類似点と相違点を理解することに重点を置いています。したがって、メタ学習 (メタ学習 #) または学習から学習
) とも呼ばれることがよくあります。k から ( k -way)nサンプル (n ショット) 学習。このうち「k」はサポートセット内のカテゴリ数を表します。たとえば、二項分類では、
kは 2 と等しくなります。また、「n」は、サポート セット内の各カテゴリで利用可能なサンプルの数を示します。たとえば、肯定的な分類に 10 データ ポイントがあり、否定的な分類にも 10 データ ポイントがある場合、 n は 10 と同じです。要約すると、このサポート セットは双方向の 10 サンプル学習として説明できます。 少数ショット学習の基本を理解したので、SetFit を使用して進みましょう。テキスト分類を電子商取引データセットに適用します。 #SetFitアーキテクチャ
作成者## Intel Labs チームと共同開発された #Hugging Face#SetFit
は、少数サンプルの写真分類のためのオープンソース ツールです。 SetFit に関する包括的な情報は、プロジェクト ライブラリのリンク https://github.com/huggingface/setfit?ref=hackernoon.com で見つけることができます。はカスタマー レビュー (カスタマー レビュー、) のみを使用します。 CR) 感情分析データセット内の各カテゴリの 8 つの注釈付きの例。結果は、3,000 の例で構成される完全なトレーニング セットで調整された RoBERTa Large の結果と同じです。ボリュームの点で、わずかに最適化された RoBERTa モデルは
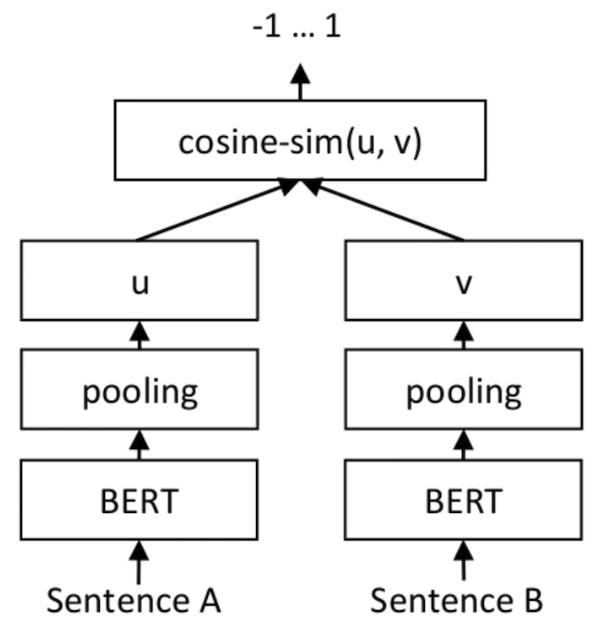
SetFit モデルよりも 3 倍大きいことを強調する価値があります。以下の図は SetFit アーキテクチャを示しています: ##画像ソース: https:/ / www.php.cn/link/2456b9cd2668fa69e3c7ecd6f51866bf#SetFit を使用して迅速な学習を実現します
SetFit のトレーニング速度は非常に速く、効率的です。 GPT-3 や T-FEW
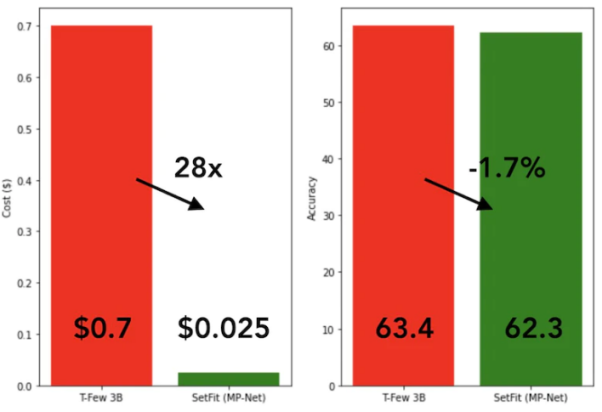 SetFit と T-Few 3B モデルの比較
SetFit と T-Few 3B モデルの比較
下図に示すように、SetFitサンプル学習のパフォーマンスは RoBERTa よりも優れています。
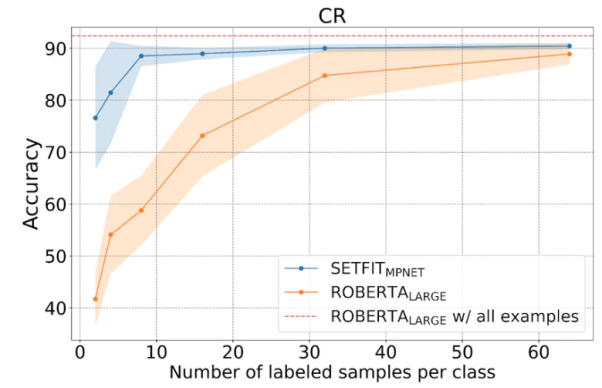
SetFit と RoBERT の比較、画像出典: https://www .php.cn/link/3ff4cea152080fd7d692a8286a587a67
以下、書籍、衣料品とアクセサリー、電子機器、家庭用家具の 4 つの異なるカテゴリで構成される独自の e コマース データ セットを使用します。このデータセットの主な目的は、電子商取引 Web サイトの商品説明を指定されたタグに分類することです。
少数サンプルのトレーニング方法の使用を容易にするために、4 つのカテゴリのそれぞれから 8 つのサンプルを選択し、合計 # 個のサンプルを選択します。 ##32 トレーニング サンプル。残りのサンプルはテスト目的で保存されます。つまり、ここで使用するサポート セットは、8 の例から学習する 4 です。次の図は、カスタム e コマース データ セットの例を示しています。
 # カスタム e コマース データ セットのサンプル
# カスタム e コマース データ セットのサンプル
「all-mpnet-base-v2」という名前の Sentence Transformers の事前トレーニング済みモデルを使用して、テキスト データをさまざまなベクトル埋め込みに変換します。このモデルは、入力テキストに対して次元 768 のベクトル埋め込みを生成できます。
次のコマンドに示すように、conda 環境 (オープン ソース ソフトウェア) を使用します。パッケージ管理システムと環境管理システム) を使用して、SetFit の実装を開始します。
!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
ソフトウェア パッケージをインストールした後、次のコードを通じてデータ セットをロードできます。
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})以下の図を参照して、トレーニング サンプルとテスト サンプルの数を確認してみましょう。
#トレーニングとテスト データ 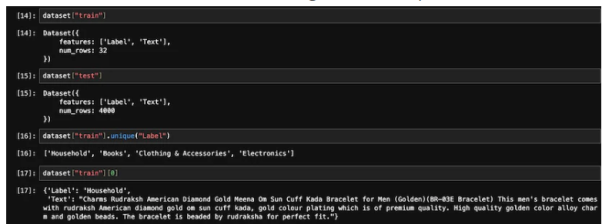
#sklearn# を使用しますパッケージ内の #LabelEncoder は、テキスト ラベルをエンコードされたラベルに変換します。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
LabelEncoder を通じて、トレーニング データ セットとテスト データ セットをエンコードし、ラベルが追加されますデータセットの「ラベル」列に追加します。以下のコードを参照してください:
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)SetFit モデルと文コンバーターを初期化します (sentence-トランス)モデル。
from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})
trainer.train()
2 トレーニング ラウンド (エポック) が完了したら、 eval_dataset、トレーニングされたモデルを評価します。
trainer.evaluate()
87.5% でした。 87.5% の精度は高くありませんが、結局のところ、私たちのモデルはトレーニングに 32 サンプルのみを使用しました。言い換えれば、データ セットの限られたサイズを考慮すると、テスト データ セットで 87.5% の精度を達成することは、実際には非常に素晴らしいことです。 さらに、
SetFit は、後で使用するためにトレーニングされたモデルをローカル ストレージに保存することもできます。未来の予測。 #trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
値は「Clothing and Accessories」であることがわかります。従来の AI モデルは、安定したレベルの出力を生成するために大量のトレーニング リソース (時間とデータを含む) を必要とします。対照的に、私たちのモデルは正確かつ効率的です。
この時点で、「少数ショット学習」の概念と、テキスト分類やその他のアプリケーションで SetFit を使用する方法を基本的に習得したと思います。もちろん、より深い理解を得るために、実際のシナリオを選択し、データセットを作成し、対応するコードを記述し、プロセスをゼロショット学習とシングルショット学習に拡張することを強くお勧めします。
#原題:
##Mastering Few-Shot Learning with SetFit for Textclassification、著者: Shyamガネーシュ S)
以上が少数ショット学習では、テキスト分類に SetFit を使用しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



