

AWS は生成 AI の実装のための包括的なソリューションを提供します

元の意味を変えずに、中国語に書き直す必要があります: 以前にアマゾン ウェブ サービス (AWS) が re:Invent 2023 で発表した、生成型人工知能の加速を目的とした一連の新テクノロジーを紹介しました。インテリジェンス関連技術の実用化に向けて

これらには、NVIDIA とのより深い戦略的パートナーシップの確立、GH200 スーパー チップをベースにした初のコンピューティング クラスター、新しい自社開発の汎用プロセッサーや AI 推論チップなどが含まれますが、これらに限定されません。

しかし、誰もが知っているように、生成 AI はハードウェアの強力なコンピューティング能力だけでなく、優れた AI モデルにも依存します。特に現在の技術背景では、開発者や企業ユーザーは多くの選択肢に直面することが多く、モデルごとに得意な生成カテゴリーが異なるため、モデルの合理的な選択、パラメータ設定、さらには効果の評価につながります。これは多くのユーザーにとって非常に面倒なことであり、生成 AI を実際のアプリケーション シナリオに適用することの難易度も大幅に増加しています。

では、生成 AI の実用化における困難を解決し、新しいテクノロジーの生産性を真に解放するにはどうすればよいでしょうか?北京時間2023年11月30日早朝、AWSは一連の回答を出した。
現在、より多くのモデルの選択肢が統合されています
まず、AWS は本日、Amazon Bedrock サービスのさらなる拡張を発表しました。以前、このサービスには、AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon など、業界をリードする複数の大規模言語モデル ソースがすでに含まれていました。このホスティング サービスを通じて、ユーザーは他のプラットフォームにアクセスすることなく、1 つのプラットフォームでさまざまな大規模な言語モデルの使用を簡単に選択できます。

 同時に、有名な大規模言語モデル Llama 2 も、最大 700 億パラメータのスケールを持つ新しいバージョンを Amazon Bedrock に導入しました。 Meta の次世代の大規模言語モデルである Llama 2 には、前世代よりも 40% 多くのトレーニング データが含まれており、コンテキストの長さは 2 倍になっています。最新バージョンでは、指示のデータセットと 100 万を超える人間による注釈によって微調整され、会話のユースケース向けに最適化されています。
同時に、有名な大規模言語モデル Llama 2 も、最大 700 億パラメータのスケールを持つ新しいバージョンを Amazon Bedrock に導入しました。 Meta の次世代の大規模言語モデルである Llama 2 には、前世代よりも 40% 多くのトレーニング データが含まれており、コンテキストの長さは 2 倍になっています。最新バージョンでは、指示のデータセットと 100 万を超える人間による注釈によって微調整され、会話のユースケース向けに最適化されています。
 さらに重要なことは、AWS が以前に独自の AI 大規模言語モデル Titan の開発に成功していることです。以前にリリースされたテキスト生成用の Amazon Titan Text Embeddings と Amazon Titan Text モデルに加えて、画像生成に焦点を当てた Amazon Titan Image Generator と Amazon Titan Multimodal Embeddings も本日正式に発表されました。従来の生成画像モデルと比較して、AWS 独自のモデルには著作権保護のための独自のテクノロジーも埋め込まれており、将来的にはより正確な検索結果を生成するためにデータベースへの画像およびテキスト情報の埋め込みもサポートされています。
さらに重要なことは、AWS が以前に独自の AI 大規模言語モデル Titan の開発に成功していることです。以前にリリースされたテキスト生成用の Amazon Titan Text Embeddings と Amazon Titan Text モデルに加えて、画像生成に焦点を当てた Amazon Titan Image Generator と Amazon Titan Multimodal Embeddings も本日正式に発表されました。従来の生成画像モデルと比較して、AWS 独自のモデルには著作権保護のための独自のテクノロジーも埋め込まれており、将来的にはより正確な検索結果を生成するためにデータベースへの画像およびテキスト情報の埋め込みもサポートされています。
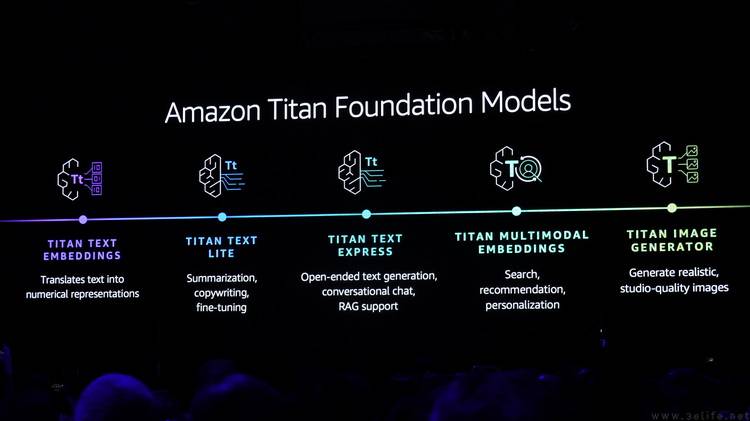 さらに、AWS は、大規模なモデルによって生成されたコンテンツに対する著作権補償ポリシーも革新的に提案しました。つまり、AWS は、一般に入手可能な Amazon Titan モデルまたはその出力がサードパーティの著作権を侵害しているという告発に対して顧客を補償します。
さらに、AWS は、大規模なモデルによって生成されたコンテンツに対する著作権補償ポリシーも革新的に提案しました。つまり、AWS は、一般に入手可能な Amazon Titan モデルまたはその出力がサードパーティの著作権を侵害しているという告発に対して顧客を補償します。
従来のユースケースでは、企業は、自社に最適なモデルを選択する前に、ベンチマークの決定、評価ツールのセットアップ、豊富な専門知識に基づいたさまざまなモデルの評価に長い時間を費やす必要がある場合があります。
しかし、Amazon Bedrock のモデル評価機能を使用すると、上記のすべてのトラブルを回避できます。ユーザーは、コンソールで事前に設定された評価基準 (精度、堅牢性など) を選択し、独自のテスト データ セットをアップロードするか、事前に設定されたデータ量から選択するだけで完全な自動化を実行できます。大規模モデルの評価プロセス。

手動評価が必要な場合でも、AWS の専門家チームは、お客様が定義した指標 (関連性、スタイル、ブランドイメージなど) に基づいて詳細な評価レポートを提供できます。時間を大幅に節約すると同時に、企業が生成 AI を使用するための技術的な敷居を大幅に下げます。

それだけでなく、Amazon Bedrock では、Cohere Command、Meta Llama 2、Amazon Titan、将来適応される Anthropic Claude 2.1 を含む複数の大規模な言語モデルにより、ユーザーが独自の言語に合わせて微調整できるようになります。ニーズ。さらに、Amazon Bedrock ナレッジベース機能を使用すると、大規模なモデルを企業独自のデータソースに接続できるようになり、チャットボットや質疑応答システムなどのユースケースに対して、より正確で企業固有の応答が提供されます。

同時に、生成 AI の使用における保護メカニズムに関して、Amazon Bedrock の Guardrails により、企業は生成 AI の言語原則をカスタマイズできるようになります。どのトピックを拒否するかを設定したり、ヘイトスピーチ、侮辱、性的言葉、暴力のしきい値を設定して、有害なコンテンツを希望のレベルまでフィルタリングすることができます。将来的には、Guardrails for Amazon Bedrock にもワードフィルター機能が導入され、複数の異なるモデルのユースケースにわたって同じまたは異なるガードレベルが使用される予定です。
多くのユーザーの信頼を得たAWSは、生成AIの導入を本格的に推進します
新しいテクノロジーを通じて生成 AI の選択と使用のプロセスを劇的に簡素化することに加えて、AWS の高く評価されている Amazon SageMaker サービスは現在、Hugging Face、Perplexity、Salesforce、Stability AI、Vanguard などの顧客によって継続的なトレーニングと強化のために使用されています。彼らの大規模な言語モデル。自社のコンピューティング機器を使用する場合と比較して、AWS のハードウェアの大きな利点と柔軟なビジネス モデルにより、「大規模モデル」の進化がより迅速かつ簡単になります。

それだけでなく、Alida、Automation Anywhere、Blueshift、BMW Group、Clariant、Coinbase、Cox Automotive、dentsu、Druva、Genesys、Gilead、GoDaddy、Hellmann Worldwide Logistics、KONE、LexisNexis Legal & Professional、A などが含まれていることがわかります。 Lonely Planet や NatWest などの一連の企業は、データの漏洩や他の競合他社による使用を心配することなく、AWS にデータを置き、このデータを使用して独自の生成 AI サービスをプライベートに「カスタマイズ」することを選択しました。また、「Amazon Bedrock の入力または出力は基本モデルのトレーニングには使用されないため、これは AWS の自己保証であるだけでなく、AWS がサードパーティの大規模モデルプロバイダーに課した技術的制約でもあります。

実際、今日の基調講演に登場した AWS の関連パートナーを列挙すると、AWS でのトレーニングとイテレーションを加速するための基本的なモデルの選択など、今日の生成 AI の業界チェーン リンクのほぼすべてをカバーしていることがわかります。 ; モデルサービスプロバイダーは、より多くのユーザーにリーチするために AWS でサービスをホストしており、プラットフォームにより AI テクノロジーの使用が大幅に簡素化され、サービス品質と業務運営効率が向上するため、大規模モデルのユーザーも AWS の関連支払いを好みます。優れたコストパフォーマンスと極めて高い信頼性を実現。

数か月前、誰もが「生成型人工知能」を実際の企業やユーザーに真に適用し、メリットをもたらすにはどうすればよいかを考えていたかもしれません。しかし、今日の AWS re:Invent 2023 基調講演の後、答えは明らかです
以上がAWS は生成 AI の実装のための包括的なソリューションを提供しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 「人間 + RPA」から「人間 + 生成 AI + RPA」へ、LLM は RPA と人間とコンピューターのインタラクションにどのような影響を与えるのでしょうか?
Jun 05, 2023 pm 12:30 PM
「人間 + RPA」から「人間 + 生成 AI + RPA」へ、LLM は RPA と人間とコンピューターのインタラクションにどのような影響を与えるのでしょうか?
Jun 05, 2023 pm 12:30 PM
画像出典@visualchinesewen|Wang Jiwei 「人間 + RPA」から「人間 + 生成 AI + RPA」へ、LLM は RPA の人間とコンピューターのインタラクションにどのような影響を与えますか?別の観点から見ると、人間とコンピューターの相互作用の観点から、LLM は RPA にどのような影響を与えるのでしょうか?プログラム開発やプロセス自動化における人間とコンピューターの対話に影響を与える RPA も、LLM によって変更される予定ですか? LLM は人間とコンピューターの相互作用にどのような影響を与えますか?生成 AI は RPA と人間とコンピューターのインタラクションをどのように変えるのでしょうか?詳細については、次の記事をご覧ください: 大規模モデルの時代が到来し、LLM に基づく生成 AI が RPA の人間とコンピューターのインタラクションを急速に変革しています。生成 AI は人間とコンピューターのインタラクションを再定義し、LLM は RPA ソフトウェア アーキテクチャの変化に影響を与えています。 RPA がプログラム開発と自動化にどのような貢献をしているかを尋ねると、答えの 1 つは人間とコンピューターの相互作用 (HCI、h) を変えたことです。
 なぜ生成 AI はさまざまな業界で求められているのでしょうか?
Mar 30, 2024 pm 07:36 PM
なぜ生成 AI はさまざまな業界で求められているのでしょうか?
Mar 30, 2024 pm 07:36 PM
生成 AI は、テキスト、画像、音声、合成データなどのさまざまな種類のコンテンツを生成できる人間の人工知能テクノロジーの一種です。では、人工知能とは何でしょうか?人工知能と機械学習の違いは何ですか?人工知能は、コンピューター サイエンスの一分野であり、自律的に推論し、学習し、アクションを実行できるシステムであるインテリジェント エージェントの作成を研究する学問です。人工知能の核心は、人間のように考え、人間のように行動する機械を構築する理論と方法に関係しています。この分野では、機械学習 ML は人工知能の分野です。入力データに基づいてモデルをトレーニングするプログラムまたはシステムです。トレーニングされたモデルは、モデルがトレーニングされた統合データから派生した新しいデータまたは未確認のデータから有用な予測を行うことができます。
 一文でレンダリングを生成するデザイン ソフトウェアに別れを告げる、28 の人気ツールを備えた生成 AI が装飾と装飾の分野を破壊します
Jun 10, 2023 pm 03:33 PM
一文でレンダリングを生成するデザイン ソフトウェアに別れを告げる、28 の人気ツールを備えた生成 AI が装飾と装飾の分野を破壊します
Jun 10, 2023 pm 03:33 PM
▲この写真はAIによって生成されたもので、九家楽、三味家、東宜日生などがすでに行動を起こしており、装飾・装飾業界チェーンはAIGCを大規模に導入している・装飾・装飾分野における生成AIの応用は何なのか?それはデザイナーにどのような影響を与えますか?レンダリングを生成するためのさまざまなデザイン ソフトウェアを 1 つの文で理解して別れを告げるための 1 つの記事です。ジェネレーティブ AI は、装飾と装飾の分野を破壊しています。人工知能を使用して機能を強化し、デザインの効率を向上させます。ジェネレーティブ AI は、装飾と装飾業界に革命をもたらしています。生成 AI は装飾および装飾業界に影響を与えますか?今後の開発動向はどうなるのでしょうか? LLM が装飾と装飾にどのような革命をもたらしているかを理解するための記事 1 つ. これらの 28 の人気の生成 AI 装飾デザイン ツールは試してみる価値があります. 記事/Wang Jiwei 装飾と装飾の分野では、最近 AIGC に関連するニュースがたくさんあります。 Colov が AI を活用した生成デザイン ツール Colov を発表
 視聴: 生成 AI をネットワーク自動化に適用するとどのような可能性がありますか?
Aug 17, 2023 pm 07:57 PM
視聴: 生成 AI をネットワーク自動化に適用するとどのような可能性がありますか?
Aug 17, 2023 pm 07:57 PM
市場調査会社オムディアの新しいレポートによると、生成人工知能(GenAI)は2023年までに魅力的な技術トレンドとなり、教育を含む企業や個人に重要な応用をもたらすと予想されている。通信分野では、GenAI のユース ケースは主に、パーソナライズされたマーケティング コンテンツの配信や、顧客エクスペリエンスを向上させるためのより洗練された仮想アシスタントのサポートに焦点を当てています。ネットワーク運用における生成 AI の適用は明らかではありませんが、EnterpriseWeb は興味深いコンセプトを開発しました。現場での生成 AI の可能性、ネットワーク オートメーションにおける生成 AI の機能と限界の実証 ネットワーク運用における生成 AI の初期の応用例の 1 つは、ネットワーク要素のインストールを支援するエンジニアリング マニュアルに代わる対話型ガイダンスの使用でした。
 ハイアールとシーメンスの生成 AI イノベーションを支えているのはどのテクノロジー巨人ですか?
Nov 21, 2023 am 09:02 AM
ハイアールとシーメンスの生成 AI イノベーションを支えているのはどのテクノロジー巨人ですか?
Nov 21, 2023 am 09:02 AM
Amazon Cloud Technology Greater China 戦略事業開発部ゼネラルマネージャー、Gu Fan 氏 2023 年には、大規模言語モデルと生成 AI が世界市場で「急増」し、AI における「圧倒的な」後続を引き起こすだけでなく、クラウドコンピューティング業界だけでなく、製造大手の業界への参入も精力的に誘致しています。ハイアール イノベーション デザイン センターは、国内初の AIGC 工業デザイン ソリューションを作成し、設計サイクルを大幅に短縮し、概念設計コストを削減しました。全体の概念設計が 83% 高速化されただけでなく、統合レンダリング効率が約 90% 向上しました。問題の解決には、人件費が高く、設計段階でのコンセプトの成果と承認の効率が低いことが含まれます。シーメンス中国のインテリジェント知識ベースと独自モデルに基づくインテリジェント会話ロボット「Xiaoyu」は、自然言語処理、知識ベース検索、データによるビッグ言語トレーニングを備えています
 Go での AWS の使用: 完全ガイド
Jun 17, 2023 pm 09:51 PM
Go での AWS の使用: 完全ガイド
Jun 17, 2023 pm 09:51 PM
Go (または Golang) は、近年開発者の間で広く普及している最新の高性能プログラミング言語です。 AWS (アマゾン ウェブ サービス) は、業界をリードするクラウド コンピューティング サービス プロバイダーの 1 つであり、開発者に豊富なクラウド コンピューティング製品と API インターフェイスを提供しています。この記事では、Go 言語で AWS を使用して高パフォーマンスのクラウド アプリケーションを構築する方法を紹介します。この記事では次のトピックについて説明します: AWS SDK for Go をインストールして AWS ストレージ データに接続する
 Tencent Hunyuan がモデル マトリックスをアップグレードし、256,000 の長い記事モデルをクラウド上で開始
Jun 01, 2024 pm 01:46 PM
Tencent Hunyuan がモデル マトリックスをアップグレードし、256,000 の長い記事モデルをクラウド上で開始
Jun 01, 2024 pm 01:46 PM
大型モデルの実装が加速しており、「産業上の実用性」が開発のコンセンサスとなっています。 2024 年 5 月 17 日、Tencent Cloud Generative AI Industry Application Summit が北京で開催され、大規模モデル開発とアプリケーション製品における一連の進歩が発表されました。 Tencent の Hunyuan ラージ モデル機能はアップグレードを続けており、モデル hunyuan-pro、hunyuan-standard、および hunyuan-lite の複数のバージョンが Tencent Cloud を通じて外部に公開されており、さまざまなシナリオで企業顧客や開発者のモデル ニーズを満たし、実装されています。最適なコスト効率の高いモデル ソリューション。 Tencent Cloud は、大規模モデル用のナレッジ エンジン、画像作成エンジン、ビデオ作成エンジンの 3 つの主要ツールをリリースし、大規模モデル時代のネイティブ ツール チェーンを作成し、PaaS サービスを通じてデータ アクセス、モデルの微調整、およびアプリケーション開発プロセスを簡素化します。企業を助けるために
 Go での AWS CloudWatch の使用: 完全ガイド
Jun 17, 2023 am 10:46 AM
Go での AWS CloudWatch の使用: 完全ガイド
Jun 17, 2023 am 10:46 AM
AWS CloudWatch は、アプリケーション、システム、サービスのパフォーマンスと健全性を理解するのに役立つモニタリング、ログ管理、メトリクス収集サービスです。 AWS が提供するフル機能のサービスである AWS CloudWatch は、ユーザーによる AWS リソースの監視と管理、およびアプリケーションとサービスの監視を支援します。 Go で AWS CloudWatch を使用すると、アプリケーションを簡単に監視し、パフォーマンスの問題が発見されたらすぐに解決できます。この記事
