

なぜ国内の大手AIモデルは「ランキングのスワイプ」にハマるのか?

携帯電話サークルをフォローしている友人は、「承認しなければスコアを取得する」というフレーズに馴染みのない人はいないと思います。たとえば、AnTuTu や GeekBench などの理論性能テスト ソフトウェアは、携帯電話の性能をある程度反映できるため、プレイヤーから大きな注目を集めています。同様に、PC プロセッサーとグラフィックス カードのパフォーマンスを測定するための、対応するベンチマーク ソフトウェアがあります。
「何でも走れる」ようになってから、人気の大型AIモデルも走行スコア競争に参加するようになりました。特に「百体戦争」が始まってからは、毎日のように躍進し、各社は「」と名乗りました。ランニング「スコアファースト」
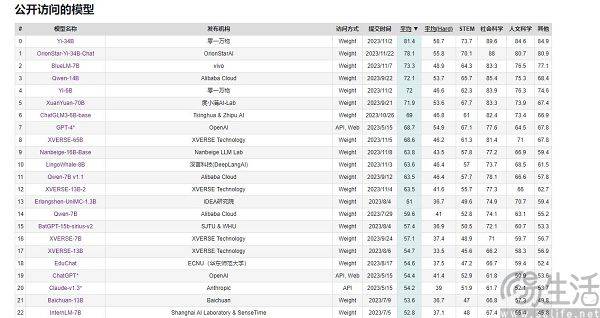
現在、中国でよく引用される大規模モデルの評価リストには、SuperCLUE、CMMLU、C-Eval などがあります。このうちCMMLUとC-Evalは、清華大学、上海交通大学、エディンバラ大学が共同で構築した総合試験評価セットです。 CMMLU は、MBZUAI、上海交通大学、マイクロソフト リサーチ アジアによって共同で立ち上げられました。 SuperCLUE については、主要大学の人工知能専門家が共同執筆しています
ご存知のとおり、スマートフォンの SoC、コンピューターの CPU、グラフィックス カードは、寿命を守るために高温になると自動的に周波数を下げ、低温になるとチップのパフォーマンスが向上します。したがって、パフォーマンス テストのために携帯電話を冷蔵庫に入れたり、コンピュータに強力な冷却システムを装備したりする人もいます。これにより、通常よりも高いスコアが得られる場合があります。また、大手携帯電話メーカーも各種ベンチマークソフトの「専用最適化」を標準運用としています
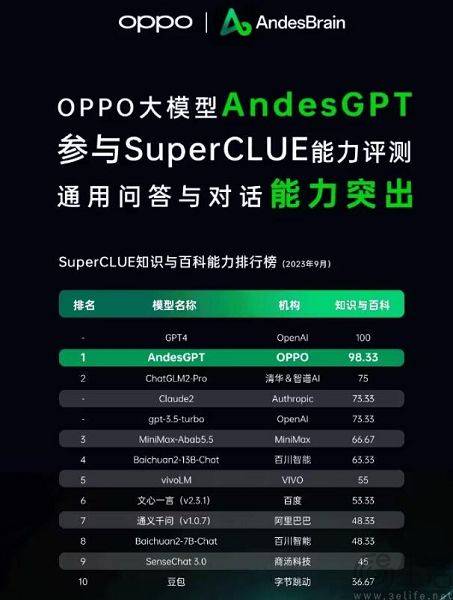
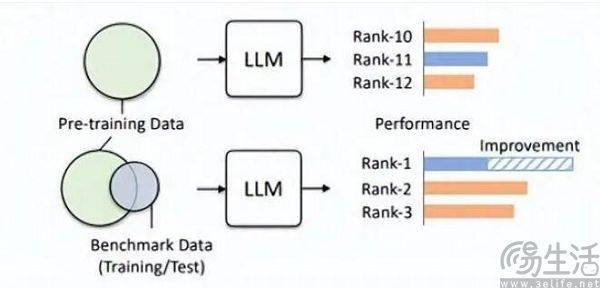
試験前に、偶然試験問題と標準解答を見て、いきなり問題を暗記すれば、試験の得点が大幅に向上することは想像できます。したがって、大規模モデルリストによって事前に設定された質問バンクがトレーニングセットに追加され、大規模モデルがベンチマークデータに適合するモデルになります。さらに、現在の LLM 自体は記憶力が優れていることで知られており、標準的な答えを暗唱するのは簡単です
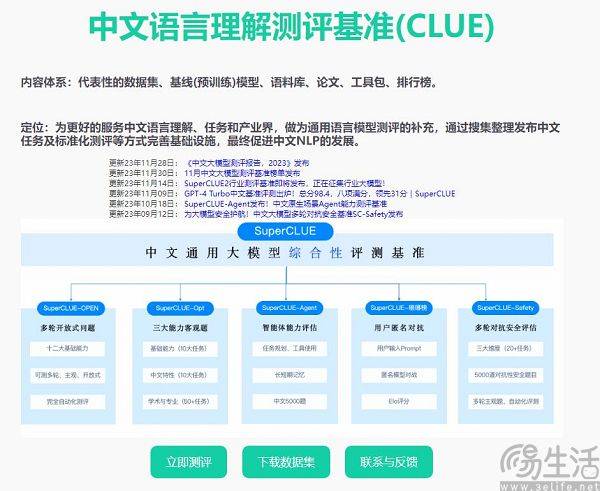
Hillhouse チームの研究者は、ベンチマーク リークにより大規模なモデルの実行結果が誇張されることを発見しました。たとえば、1.3B モデルは一部のタスクではサイズの 10 倍を超える可能性がありますが、副作用として、これらが特別に設計されているという点が挙げられます。 「テスト受験」の場合「他の通常のテスト タスクで設計された大規模モデルのパフォーマンスが悪影響を受けます。結局、よく考えてみればわかるが、大型AIモデルは本来「問題作成者」であるはずだったが、あるリストで高得点を取るために「問題記憶者」となってしまったのだ。リストの特定の知識と出力スタイルを使用するため、大規模なモデルを誤解させる可能性があります。

トレーニングセット、検証セット、テストセットが交差しないというのは当然のことながら理想的な状態に過ぎず、結局のところ現実は非常に希薄であり、根本的にデータ漏洩の問題はほぼ避けられません。関連技術の継続的な進歩により、現在の大型モデルの基礎である Transformer 構造のメモリと受信能力は常に向上しており、この夏、Microsoft Research の汎用 AI 戦略により、このモデルは問題を引き起こすことなく 1 億個のトークンを受信できるようになりました。物忘れは容認できません。言い換えれば、将来的には、大規模な AI モデルがインターネット全体を読み取る機能を備えている可能性があります。
技術の進歩を脇に置いても、高品質のデータは常に不足しており、生産能力も限られているため、現在の技術レベルに基づいてデータ汚染を回避することは実際には困難です。今年初めにAI研究チームエポック社が発表した論文では、AIは高品質な人間の言語データを5年以内にすべて使い果たしてしまうことが示されており、この結果により言語の成長率が高まるということです。人間の言語データ、つまり今後 5 年間にすべての人類が出版するデータ、書かれた本、書かれた論文、書かれたコードがすべて結果を予測するために考慮されます。
データセットが評価に適している場合、事前トレーニングでより良い役割を果たすことは間違いありません。たとえば、OpenAI の GPT-4 は、権威推論評価データ セット GSM8K を使用します。したがって、現在、大規模モデル評価の分野には厄介な問題が存在しており、大規模モデルからのデータに対する需要は際限なくあるため、評価機関は人工知能のメーカーよりも速く、より遠くまで行動しなければならないことにつながっています。大型モデル。しかし、今日の評価機関にはこれを行う能力が全くないようです
なぜ一部のメーカーは大型モデルの走行スコアに注目し、次々とランキングを上げようとするのでしょうか?実際、この動作の背後にあるロジックは、アプリ開発者が自分のアプリのユーザー数に水を注入するのとまったく同じです。結局のところ、アプリのユーザー規模はその価値を測る重要な要素であり、現在の大規模 AI モデルの初期段階では、評価リストの結果がほぼ唯一の比較的客観的な基準となります。一般の認識、高スコアは、優れたパフォーマンスと同等であることを意味します。
ランキングの見直しが強力な宣伝効果をもたらし、さらには資金調達の基礎を築く可能性がある場合、商業的利益の追加により、大手の AI モデル メーカーがランキングの見直しを急ぐのは避けられません。
以上がなぜ国内の大手AIモデルは「ランキングのスワイプ」にハマるのか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7519
7519
 15
1378
52
81
11
21
68
15
1378
52
81
11
21
68

 2023年最新グラフィックカード性能ランキング一覧
Jan 05, 2024 pm 11:12 PM
2023年最新グラフィックカード性能ランキング一覧
Jan 05, 2024 pm 11:12 PM
2023 年の最新のグラフィックス カード ベンチマーク ランキングがリリースされました。グラフィックス カードのラダー チャートをフォローしているユーザーはご覧ください。最近、グラフィックス カード メーカーが新しいグラフィックス カードをリリースし続けており、古いシリーズに新しいグラフィックス カードを導入しているため、新しいリストが公開されました。 ~2023 年最新グラフィックス カード ベンチマーク ランキング、グラフィックス カード ラダー ランキング、2023 年コンピューター グラフィックス カード購入の推奨事項: 1. ローエンド グラフィックス カード: RTX3050、5600XT、および 2060S はすべて、エントリー レベルの優れた選択肢です。グラフィックス カードと CPU を購入することで、LOL、Cf、Overwatch などの軽量 3D オンライン ゲームを優れたコスト パフォーマンスでプレイできます。そして低画質。 3. ミッドレンジグラフィックスカード: NVIDIA: RTX3060Ti、RTX2
 Kirin 9000S のロック解除されたベンチマークが公開: 期待を超える驚異的なパフォーマンス
Sep 05, 2023 pm 12:45 PM
Kirin 9000S のロック解除されたベンチマークが公開: 期待を超える驚異的なパフォーマンス
Sep 05, 2023 pm 12:45 PM
ファーウェイの最新携帯電話「Mate60Pro」は国内市場で発売されて以来、幅広い注目を集めている。しかし、最近、マシンに搭載されている Kirin 9000S プロセッサのパフォーマンスについて、ベンチマーク プラットフォームで議論が巻き起こっています。プラットフォームのテスト結果によると、Kirin 9000S の実行スコアは不完全で、GPU 実行スコアが欠落しているため、一部のベンチマーク ソフトウェアが適応できなくなります。オンラインで公開された情報によると、Kirin 9000S は驚くべき結果を達成しました。ロック解除されたランニング スコア テスト。合計スコアは 950935 ポイントです。具体的には、CPU スコアは 279,677 ポイントと高く、これまで不足していた GPU スコアは 251,152 ポイントです。前回のAnTuTu公式テストの合計スコア699783点と比較すると、Kirin 9000Sの性能が向上していることがわかります。
 AI 大型モデルの波を受けてコンピューティング パワーの需要が爆発的に増加しており、SenseTime の「大型モデル + 大型コンピューティング パワー」により、複数の業界の発展が可能になります。
Jun 09, 2023 pm 07:35 PM
AI 大型モデルの波を受けてコンピューティング パワーの需要が爆発的に増加しており、SenseTime の「大型モデル + 大型コンピューティング パワー」により、複数の業界の発展が可能になります。
Jun 09, 2023 pm 07:35 PM
このほど、「AIが時代をリードし、コンピューティングパワーが未来を駆動する」をテーマとした「臨港新区インテリジェントコンピューティングカンファレンス」が開催された。この会合において、新領域インテリジェントコンピューティング産業アライアンスが正式に設立され、センスタイムはコンピューティングパワープロバイダーとしてアライアンスのメンバーとなり、同時に「新領域インテリジェントコンピューティング産業チェーンマスター」企業の称号を授与されました。臨港コンピューティングパワーエコシステムへの積極的な参加者として、SenseTimeはアジア最大のインテリジェントコンピューティングプラットフォームの1つであるSenseTime AIDCを構築しました。これは合計5,000ペタフロップスのコンピューティングパワーを出力し、数千億のパラメータを持つ20の超大規模モデルをサポートできます。 . 同時にトレーニングします。 AIDC に基づいて将来を見据えて構築された大規模デバイスである SenseCore は、人工知能を強化するための高効率、低コスト、大規模な次世代 AI インフラストラクチャとサービスの作成に取り組んでいます。
 研究者: AI モデル推論はより多くの電力を消費し、2027 年の業界の電力消費量はオランダの電力消費量に匹敵するでしょう
Oct 14, 2023 am 08:25 AM
研究者: AI モデル推論はより多くの電力を消費し、2027 年の業界の電力消費量はオランダの電力消費量に匹敵するでしょう
Oct 14, 2023 am 08:25 AM
IT Houseは10月13日、「Cell」の姉妹誌である「Joule」が今週、「人工知能の増大するエネルギーフットプリント(人工知能の増大するエネルギーフットプリント)」と題する論文を発表したと報じた。問い合わせの結果、この論文は科学研究機関デジコノミストの創設者アレックス・デブリーズ氏が発表したものであることが分かりました。アレックス・デブリーズ氏は、将来の人工知能の推論性能は大量の電力を消費する可能性があり、2027年までに人工知能の電力消費量はオランダの1年間の電力消費量に匹敵する可能性があると予測していると述べた。外の世界では、AI モデルのトレーニングが「AI で最も重要なこと」であると常に信じられてきました。
 OPPO Reno11 FがGeekbenchに登場:Dimensity 7050を搭載
Feb 06, 2024 pm 11:10 PM
OPPO Reno11 FがGeekbenchに登場:Dimensity 7050を搭載
Feb 06, 2024 pm 11:10 PM
2月6日のメディア報道によると、OPPOは昨年OPPOReno11シリーズをリリースし、標準バージョンとProバージョンの2つのバージョンを提供していましたが、今回OPPOはReno11シリーズの新バージョンであるReno11Fも投入する予定です。現在、OPPOReno11F は Geekbench6 データベースに掲載されており、新しいマシンのシングルコア ランニング スコアは 897 ポイント、マルチコア ランニング スコアは 2329 ポイントです。ベンチマークテストによると、新しい携帯電話には MediaTek Dimensity 7050 SoC が搭載され、Mali-G68MC4 GPU と 8GB RAM と組み合わせられ、Android 14 ベースの ColorOS14 システムがプリインストールされています。ニュースによると、OPPOReno11Fは6.7インチAを採用するとのこと
 4 倍高速化した Bytedance のオープンソース高性能トレーニング推論エンジン LightSeq テクノロジーが明らかに
May 02, 2023 pm 05:52 PM
4 倍高速化した Bytedance のオープンソース高性能トレーニング推論エンジン LightSeq テクノロジーが明らかに
May 02, 2023 pm 05:52 PM
Transformer モデルは、2017 年に Google チームが発表した論文「Attendisalyouneed」に由来しています。この論文は、Seq2Seq モデルの循環構造を Attendance で置き換えるという概念を初めて提案し、NLP 分野に大きな影響を与えました。そして、近年の継続的な研究の進歩により、Transformer 関連技術は自然言語処理から徐々に他の分野へ流れてきました。現在まで、Transformer シリーズは、NLP、CV、ASR などの分野で主流のモデルとなっています。したがって、Transformer モデルをより迅速にトレーニングおよび推論する方法が、業界の重要な研究方向となっています。低精度の量子化技術では、
 チャイナユニコム、テキストから画像やビデオクリップを生成できる大規模な画像およびテキストAIモデルをリリース
Jun 29, 2023 am 09:26 AM
チャイナユニコム、テキストから画像やビデオクリップを生成できる大規模な画像およびテキストAIモデルをリリース
Jun 29, 2023 am 09:26 AM
中国ニュースを牽引する2023年6月28日、上海で開催中のモバイルワールドコングレス期間中の本日、チャイナユニコムはグラフィックモデル「Honghu Graphic Model 1.0」をリリースした。チャイナユニコムは、Honghuグラフィックモデルは通信事業者の付加価値サービス向けの初の大型モデルであると述べた。 China Business Newsの記者は、Honghuのグラフィックモデルには現在、8億個のトレーニングパラメータと20億個のトレーニングパラメータの2つのバージョンがあり、テキストベースの画像、ビデオ編集、画像ベースの画像などの機能を実現できることを知りました。さらに、チャイナユニコムの劉立紅会長も本日の基調講演で、生成型AIは発展の特異点を到来させており、今後2年間で雇用の50%が人工知能によって大きな影響を受けるだろうと述べた。
 OnePlus Ace 3V が Geekbench プラットフォームに登場: Snapdragon 7+ Gen3 の世界初公開
Mar 12, 2024 pm 10:34 PM
OnePlus Ace 3V が Geekbench プラットフォームに登場: Snapdragon 7+ Gen3 の世界初公開
Mar 12, 2024 pm 10:34 PM
3 月 12 日のニュースによると、OnePlus Ace3V 携帯電話はモデル番号 PJF110 で Geekbench ベンチマーク プラットフォームに登場しました。 Geekbench6 の実行スコアでは、OnePlus Ace3V は最高のシングルコア スコア 1848 とマルチコア スコア 5007 を達成しました。Geekbench5 では、シングルコア スコア 1416 とマルチコア スコア 4829 を達成しました。これは、ディメンシティ 9200 に近い値です。 +。 OnePlus Ace3Vは世界初のSnapdragon 7+Gen3モバイルプラットフォームになると報じられており、TSMCの4nmプロセスに基づいて製造され、「1+4+3」コア構成を採用しており、Cortex-X4超大型コア周波数は2.9 GHz に対応し、Adreno732 GPU を統合します。バッテリー寿命の観点から、航空機には 55 個のバッテリーが搭載されています。
