

世界が注目する「被験者3」:メッシもアイアンマンも二次元女子も簡単に扱える

最近、手を振り、足を半分股にし、リズミカルな音楽に合わせて踊る「主題 3」を多かれ少なかれ聞いたことがあるかもしれません。このダンスの動きはインターネット全体で人気があります。真似してください。
同じようなダンスがAIによって生成されたらどうなるでしょうか?下の写真のように、現代人も紙人も画一的な動きをしています。想像できないかもしれませんが、これは写真に基づいて生成されたダンス ビデオです。

キャラクターの動きはより難しくなり、生成されたビデオも非常にスムーズです (右端):

メッシとアイアンマンを動かしても問題ありません:
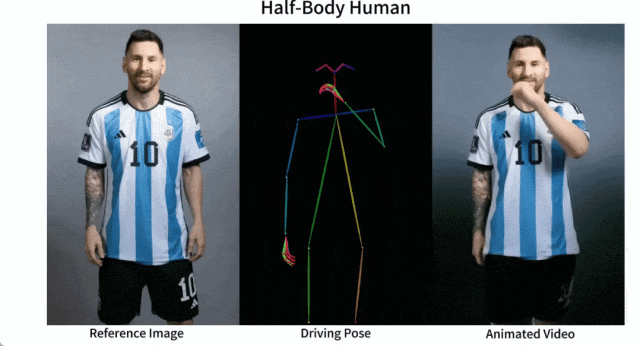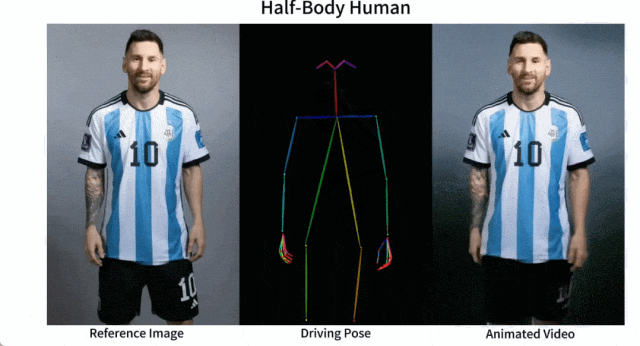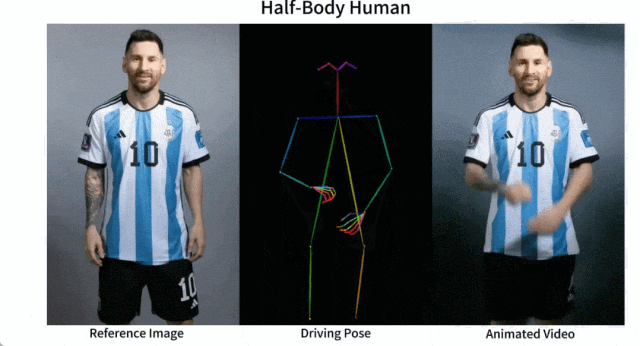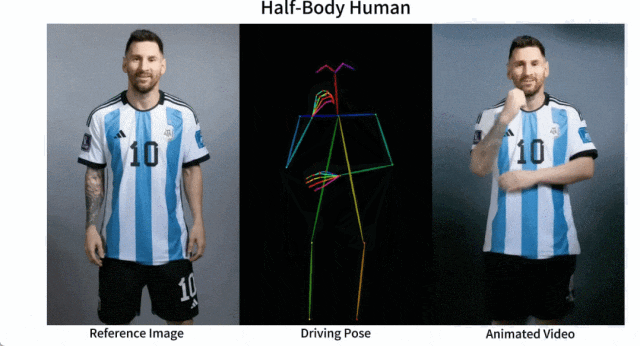
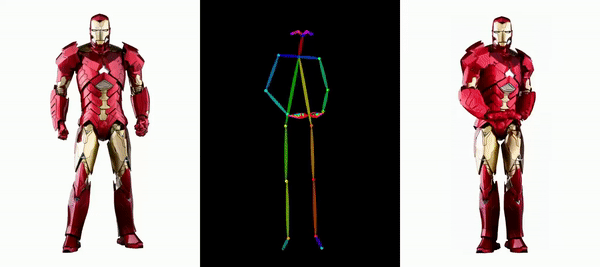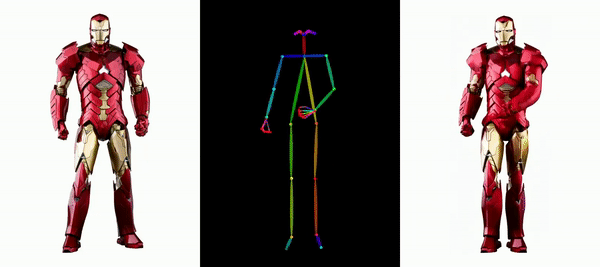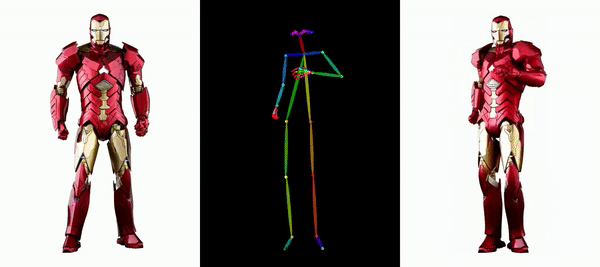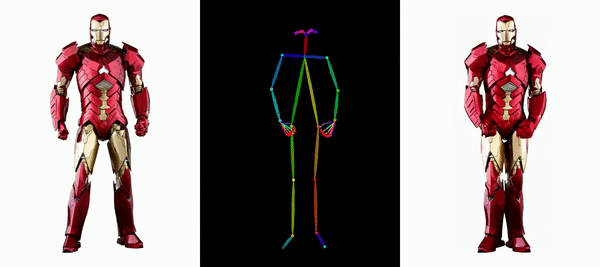
アニメ系の女性も色々あります。

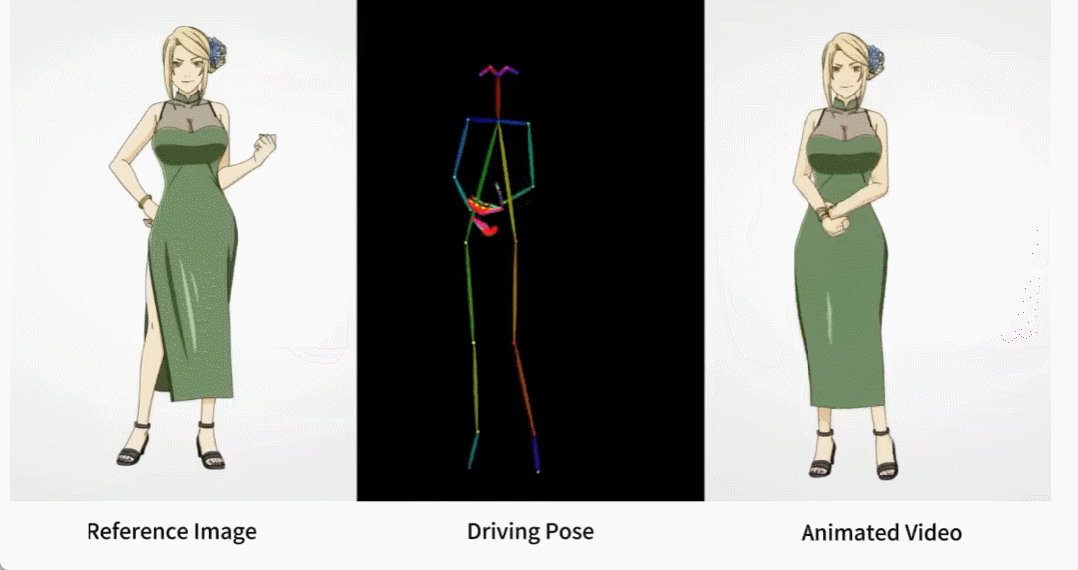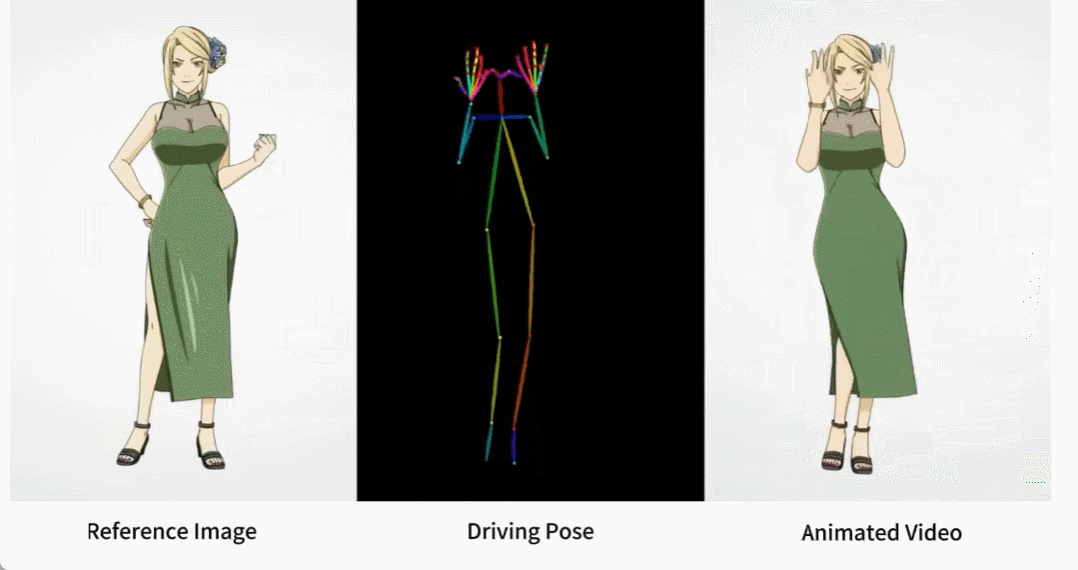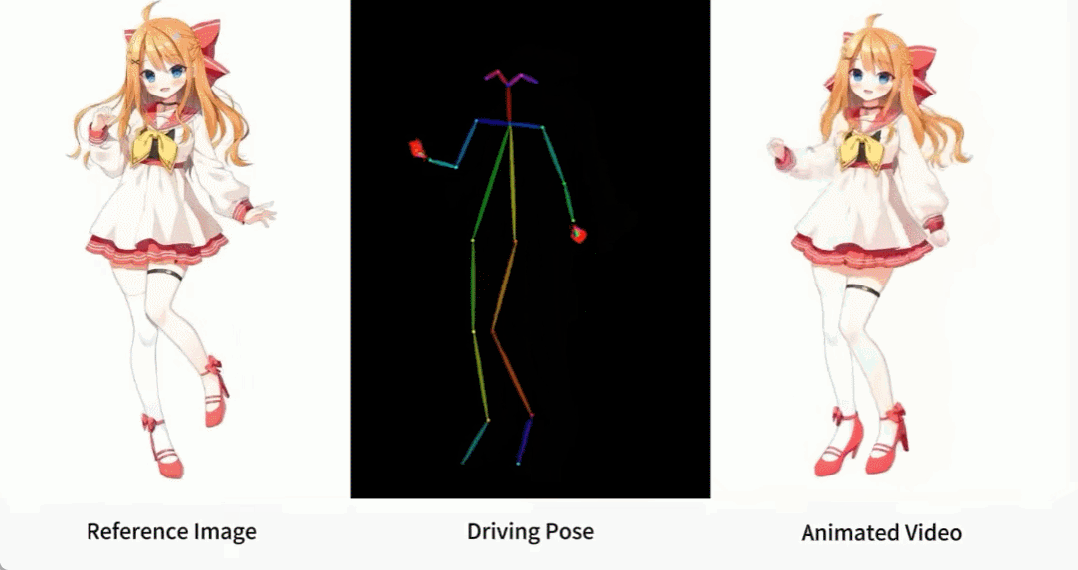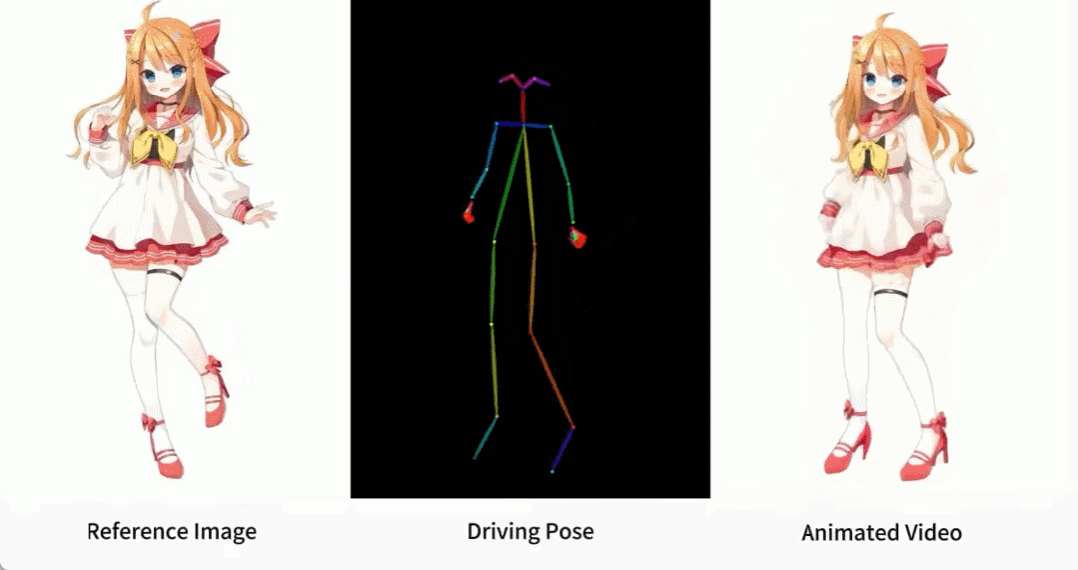
キャラクター アニメーションは、元のキャラクター画像を希望のポーズ シーケンスでリアルなビデオに変換するプロセスです。このタスクには、オンライン小売、エンターテイメント ビデオ、アート作成、仮想キャラクターなど、多くの潜在的な応用分野があります。
GAN テクノロジーの出現以来、研究者は継続的に研究を行ってきました。 Depth 画像をアニメーションに変換し、ポーズの転送を完了するためのメソッド。ただし、生成された画像やビデオには、局所的な歪み、ぼやけた詳細、意味論的な不一致、時間的不安定性など、これらの方法の適用を妨げるいくつかの問題が依然として残っています。
Ali の研究著者らは、キャラクター画像を目的のポーズシーケンスに従うアニメーションビデオに変換する Animate Anybody と呼ばれる方法を提案しました。この調査では、安定拡散ネットワーク設計と事前トレーニングされた重みを採用し、マルチフレーム入力に対応するためにノイズ除去 UNet を変更しました

- #論文アドレス: https://arxiv.org/pdf/2311.17117.pdf
- プロジェクト アドレス: https://humanaigc.github.io/animate -anyone/
- 外観の一貫性を保つために、この調査では ReferenceNet が導入されました。このネットワークは対称 UNet 構造を採用しており、参照画像の空間詳細をキャプチャすることを目的としています。この研究では、対応する UNet ブロック層のそれぞれで空間注意メカニズムを使用して、ReferenceNet の機能をノイズ除去 UNet に統合します。このアーキテクチャにより、モデルは一貫した特徴空間で参照画像との関係を包括的に学習できます。
姿勢制御性を確保するために、この研究では、姿勢制御信号を効果的に統合する軽量の姿勢ガイダンス プロセッサを設計しました。ノイズ除去プロセスに入ります。時間的安定性を達成するために、この論文では、複数のフレーム間の関係をモデル化するための時間層を導入し、それにより、連続的で滑らかな時間的動きプロセスをシミュレートしながら、視覚的な品質の高解像度の詳細を保持します。
Animate Anybody は、図 1 に示すように、さまざまなキャラクターのアニメーション結果を示す、5K キャラクター ビデオ クリップの社内データセットでトレーニングされました。以前の方法と比較して、この記事の方法にはいくつかの明らかな利点があります。
- まず、ビデオ内のキャラクターの外観の空間的および時間的一貫性を効果的に維持します。
- 第二に、生成される高解像度ビデオには時間のジッターやちらつきなどの問題がありません。
- 第三に、特定の分野に制限されることなく、任意のキャラクター画像をビデオにアニメーション化できます。
この論文は、2 つの特定のヒューマン ビデオ合成ベンチマーク (UBC ファッション ビデオ データセットと TikTok データセット) に基づいて評価されています。結果は、Animate Anybody が SOTA の結果を達成していることを示しています。さらに、この研究では、Animate Anybody メソッドと大規模データでトレーニングされた一般的な画像からビデオへのメソッドを比較し、Animate Anybody がキャラクター アニメーションにおいて優れた機能を実証していることを示しました。

Animate Anybody と他の方法の比較:

方法の紹介
##この記事の処理方法を図 2 に示します。ネットワークの元の入力はマルチフレーム ノイズで構成されています。ノイズ除去効果を達成するために、研究者らは、同じフレームワークとブロックユニットを使用し、SD からトレーニング重みを継承する SD 設計に基づく構成を採用しました。具体的には、このメソッドには 3 つの重要な部分が含まれています。 Pose Guider (姿勢ガイド)、制御可能なキャラクターの動きを実現するためにアクション制御信号をエンコードします;
- Temporal レイヤー (時間レイヤー)、キャラクターのアクションの連続性を保証するために時間的な関係をエンコードします。
- #ReferenceNet
ReferenceNet は参照画像の特徴抽出ですネットワーク、そのフレームワークはノイズ除去 UNet とほぼ同じですが、時間層のみが異なります。したがって、ReferenceNet はノイズ除去 UNet と同様に元の SD 重みを継承し、各重み更新は独立して実行されます。研究者らは、ReferenceNet の機能をノイズ除去 UNet に統合する方法を説明します。 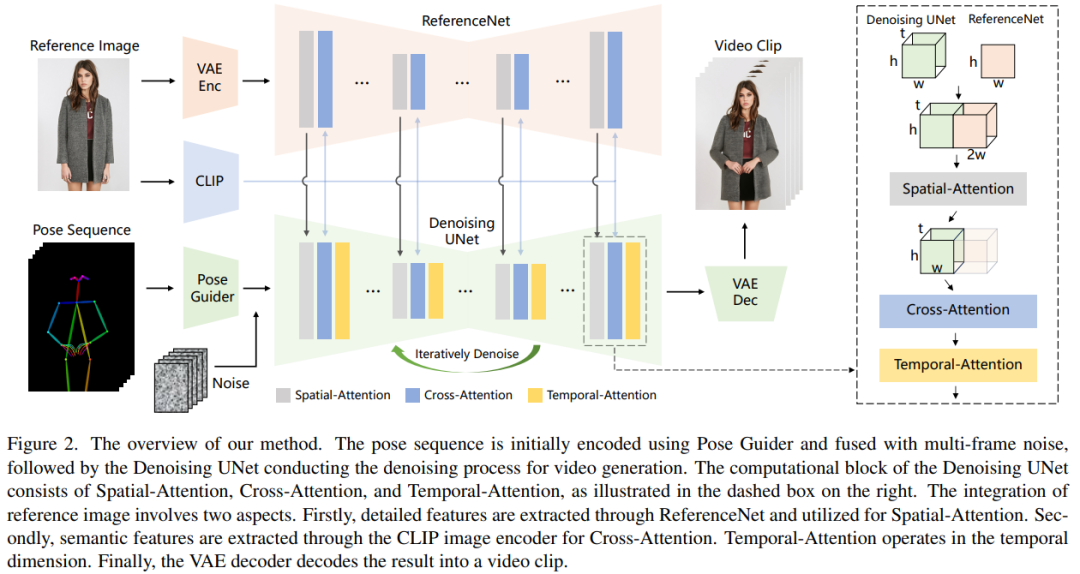
#ReferenceNet の設計には 2 つの利点があります。まず、ReferenceNet は、生の SD の事前トレーニングされた画像特徴モデリング機能を利用して、適切に初期化された特徴を生成できます。第 2 に、ReferenceNet とノイズ除去 UNet は本質的に同じネットワーク構造と共有初期化重みを持っているため、ノイズ除去 UNet は同じ特徴空間に関連付けられた特徴を ReferenceNet から選択的に学習できます。
態度ガイド
書き直された内容は次のとおりです: この軽量の態度ガイドは 4 つの畳み込み層 (4 × 4 カーネル) を使用します。 、2 × 2 ストライド)、チャネル番号 16、32、64、128 を持ち、[56] の条件付きエンコーダと同様に、ジェスチャ画像を位置合わせするために使用されます。処理されたポーズ画像は潜在ノイズに追加され、処理のためにノイズ除去 UNet に入力されます。ポーズ ガイドはガウス重みで初期化され、最終マッピング レイヤー
時間レイヤー
でゼロ畳み込みを使用します。タイムレイヤーのデザインはAnimateDiffからインスピレーションを得ています。特徴マップ x∈R^b×t×h×w×c の場合、研究者はまずそれを x∈R^(b×h×w)×t×c に変形し、次に時間的注意を実行します。次元 t における自己注意。時間層の特徴は、残差接続を通じて元の特徴にマージされます。この設計は、以下の 2 段階のトレーニング方法と一致しています。時間レイヤーは、ノイズ除去 UNet の Res-Trans ブロック内でのみ使用されます。
#トレーニング戦略
トレーニング プロセスは 2 つの段階に分かれています。書き直された内容: トレーニングの最初の段階では、単一のビデオ フレームがトレーニングに使用されます。ノイズ除去 UNet モデルでは、研究者らは一時的に時間層を除外し、単一フレームのノイズを入力として受け取りました。同時に、参照ネットワークと姿勢ガイドも訓練されます。参照画像はビデオ クリップ全体からランダムに選択されます。彼らは、事前トレーニングされた重みを使用して、ノイズ除去 UNet モデルと ReferenceNet モデルを初期化しました。ポーズ ガイドは、ゼロ畳み込みを使用する最終投影レイヤーを除き、ガウス ウェイトで初期化されます。 VAE エンコーダとデコーダ、および CLIP 画像エンコーダの重みは変更されません。この段階の最適化目標は、参照画像とターゲット ポーズを指定して高品質のアニメーション画像を生成することです
#第 2 段階では、研究者は、事前にトレーニングされたモデルに時間層を導入し、 AnimateDiff で事前にトレーニングされた重みを使用して初期化します。モデルへの入力は 24 フレームのビデオ クリップで構成されます。この段階では、時間層のみがトレーニングされ、ネットワークの他の部分の重みは固定されます。
実験と結果
定性的結果: 図 3 に示すように、この記事の方法では、完全なアニメーションを含むあらゆるキャラクターのアニメーションを生成できます。 - 体のポートレートと半身ポートレート、漫画のキャラクターと人型のキャラクター。この方法では、高解像度でリアルな人間の詳細を生成できます。参照画像との時間的一貫性を維持し、大きな動きが存在する場合でもフレーム間の時間的連続性を示します。

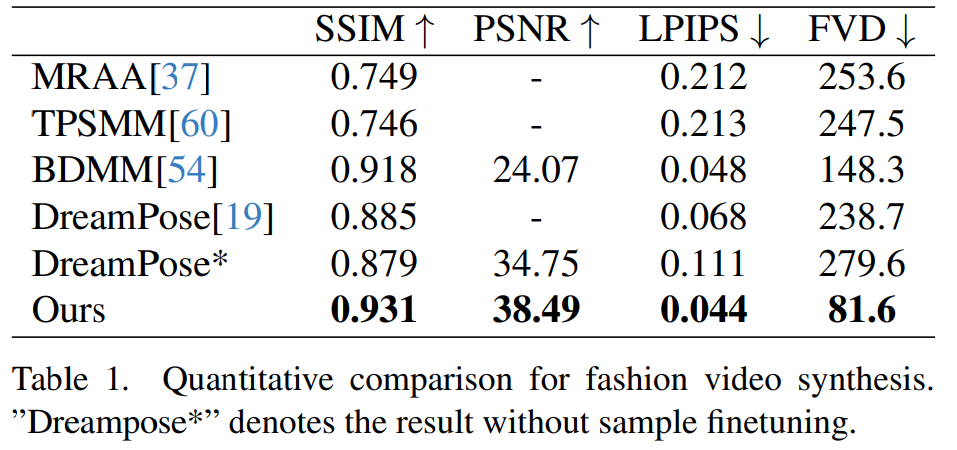
ファッションビデオ合成。ファッション ビデオ合成の目標は、駆動ポーズ シーケンスを使用して、ファッション写真をリアルなアニメーション ビデオに変換することです。実験は、UBC ファッション ビデオ データセットで行われます。このデータセットは、それぞれ約 350 フレームを含む 500 のトレーニング ビデオと 100 のテスト ビデオで構成されます。定量的な比較を表 1 に示します。結果から、この論文の方法が他の方法より優れていることがわかり、特にビデオ測定指標において明確なリードを示しています。
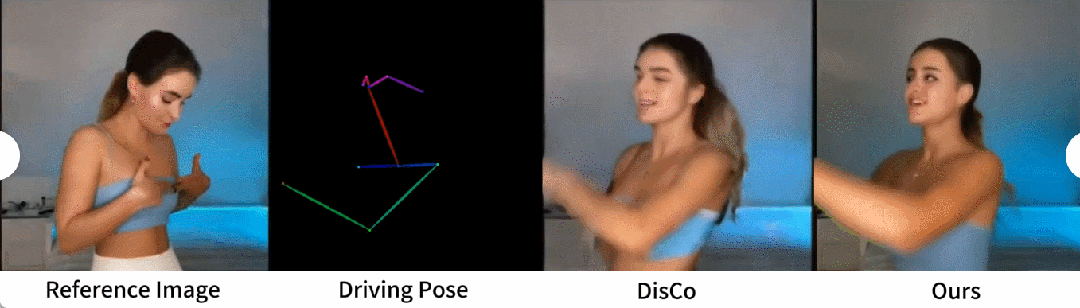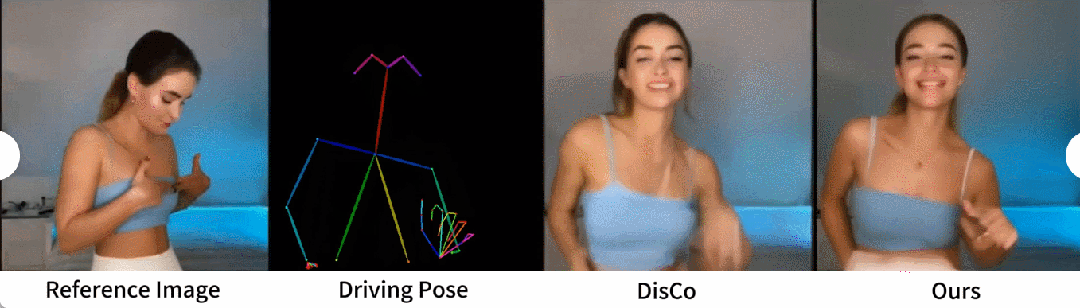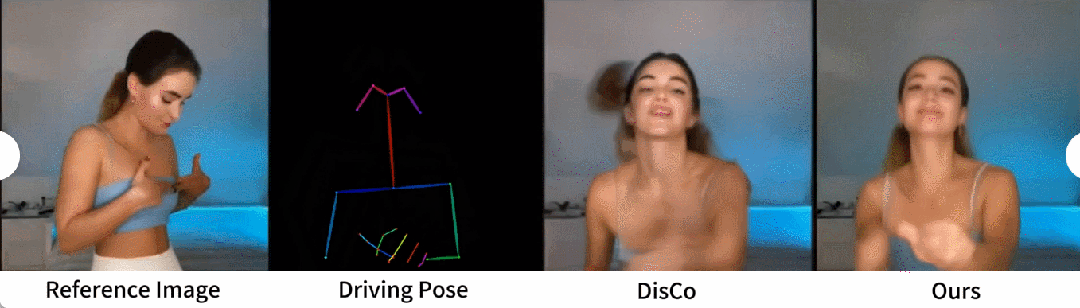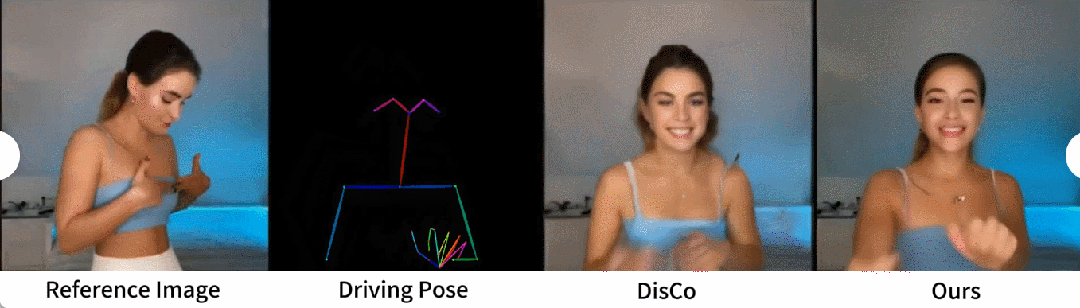
 # ヒューマンダンス生成は、リアルなダンスシーンのダンス画像をアニメーション化することで人間を生成することを目的とした研究です。研究者らは、340 のトレーニング ビデオと 100 のテスト ビデオを含む TikTok データ セットを使用しました。彼らは、DisCo のデータセット分割方法に従って、10 個の TikTok スタイルのビデオを含む同じテスト セットを使用して定量的な比較を実行しました。表 2 からわかるように、この記事の方法では最良の結果が得られます。モデルの汎化能力を強化するために、DisCo は人間属性の事前トレーニングを組み合わせ、モデルの事前トレーニングに多数の画像ペアを使用します。対照的に、他の研究者は TikTok データセットのみでトレーニングしましたが、それでも結果は DisCo よりも優れていました。 DisCo との比較を図 5 に示します。シーンの複雑さを考慮すると、DisCo の方法では人間の前景マスクを生成するために SAM を追加で使用する必要があります。対照的に、私たちの方法は、明示的な人間のマスク学習がなくても、事前の人間のセグメンテーションなしで、モデルが被験者の動きから前景と背景の関係を把握できることを示しています。さらに、複雑なダンス シーケンスでは、このモデルはアクション全体を通して視覚的な連続性を維持することに優れ、さまざまなキャラクターの外観を処理する際に優れた堅牢性を示します。
# ヒューマンダンス生成は、リアルなダンスシーンのダンス画像をアニメーション化することで人間を生成することを目的とした研究です。研究者らは、340 のトレーニング ビデオと 100 のテスト ビデオを含む TikTok データ セットを使用しました。彼らは、DisCo のデータセット分割方法に従って、10 個の TikTok スタイルのビデオを含む同じテスト セットを使用して定量的な比較を実行しました。表 2 からわかるように、この記事の方法では最良の結果が得られます。モデルの汎化能力を強化するために、DisCo は人間属性の事前トレーニングを組み合わせ、モデルの事前トレーニングに多数の画像ペアを使用します。対照的に、他の研究者は TikTok データセットのみでトレーニングしましたが、それでも結果は DisCo よりも優れていました。 DisCo との比較を図 5 に示します。シーンの複雑さを考慮すると、DisCo の方法では人間の前景マスクを生成するために SAM を追加で使用する必要があります。対照的に、私たちの方法は、明示的な人間のマスク学習がなくても、事前の人間のセグメンテーションなしで、モデルが被験者の動きから前景と背景の関係を把握できることを示しています。さらに、複雑なダンス シーケンスでは、このモデルはアクション全体を通して視覚的な連続性を維持することに優れ、さまざまなキャラクターの外観を処理する際に優れた堅牢性を示します。
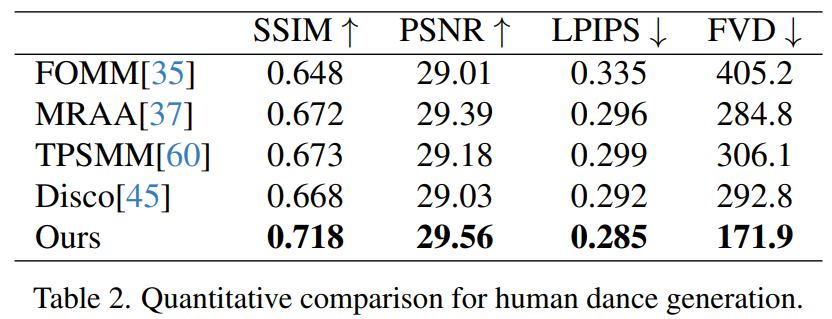
Image - ビデオの一般的なメソッド。現在、大規模なトレーニング データに基づいた強力な生成機能を備えたビデオ拡散モデルが多くの研究で提案されています。研究者らは、最もよく知られ最も効果的な画像ビデオ手法のうち、AnimateDiff と Gen2 の 2 つを比較対象として選択しました。これら 2 つの方法は姿勢制御を実行しないため、研究者らは参照画像の外観の忠実性を維持する能力のみを比較しました。図 6 に示すように、現在の画像からビデオへのアプローチは、多数のキャラクターのアクションを生成するという課題に直面しており、ビデオ間で長期的な外観の一貫性を維持するのに苦労しているため、一貫したキャラクター アニメーションの効果的なサポートが妨げられています。

詳細については、元の論文を参照してください
以上が世界が注目する「被験者3」:メッシもアイアンマンも二次元女子も簡単に扱えるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。
人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7542
7542
 15
1381
52
83
11
21
87
15
1381
52
83
11
21
87

 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian OpenSSLでデジタル署名検証を実行する方法
Apr 13, 2025 am 11:09 AM
Debian OpenSSLでデジタル署名検証を実行する方法
Apr 13, 2025 am 11:09 AM
Debianシステムでのデジタル署名検証にOpenSSLを使用すると、次の手順に従うことができます。OpenSSL:Debianシステムがインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoaptupdatesudoaptinInstallopensslslに公開キーを取得できます。デジタル署名検証には、署名者の公開キーが必要です。通常、公開キーは、public_key.peなどのファイルの形で提供されます
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
DebianでHadoopログを管理すると、次の手順とベストプラクティスに従うことができます。ログ集約を有効にするログ集約を有効にします。Yarn.log-Aggregation-set yarn-site.xmlファイルでは、ログ集約を有効にします。ログ保持ポリシーの構成:yarn.log-aggregation.retain-secondsを設定して、172800秒(2日)などのログの保持時間を定義します。ログストレージパスを指定:Yarn.Nを介して
 ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
ソニーは、PS5 Proで特別なGPUを使用してAMDを使用してAIを開発する可能性を確認しています
Apr 13, 2025 pm 11:45 PM
Sony InteractiveEntertainmentのチーフアーキテクト(SIE、Sony Interactive Entertainment)のMark Cernyは、パフォーマンスアップグレードAMDRDNA2.xアーキテクチャGPU、およびAMDとの機械学習/人工知能プログラムコードノームの「Amethylst」を含む、次世代ホストPlayStation5Pro(PS5PRO)のハードウェアの詳細をリリースしました。 PS5PROパフォーマンスの改善の焦点は、より強力なGPU、高度なレイトレース、AI搭載のPSSRスーパー解像度関数を含む3つの柱に依然としてあります。 GPUは、SonyがRDNA2.xと名付けたカスタマイズされたAMDRDNA2アーキテクチャを採用しており、RDNA3アーキテクチャがあります。
