

DetZero: Waymo は 3D 検出リストで 1 位にランクされており、手動アノテーションに匹敵します。


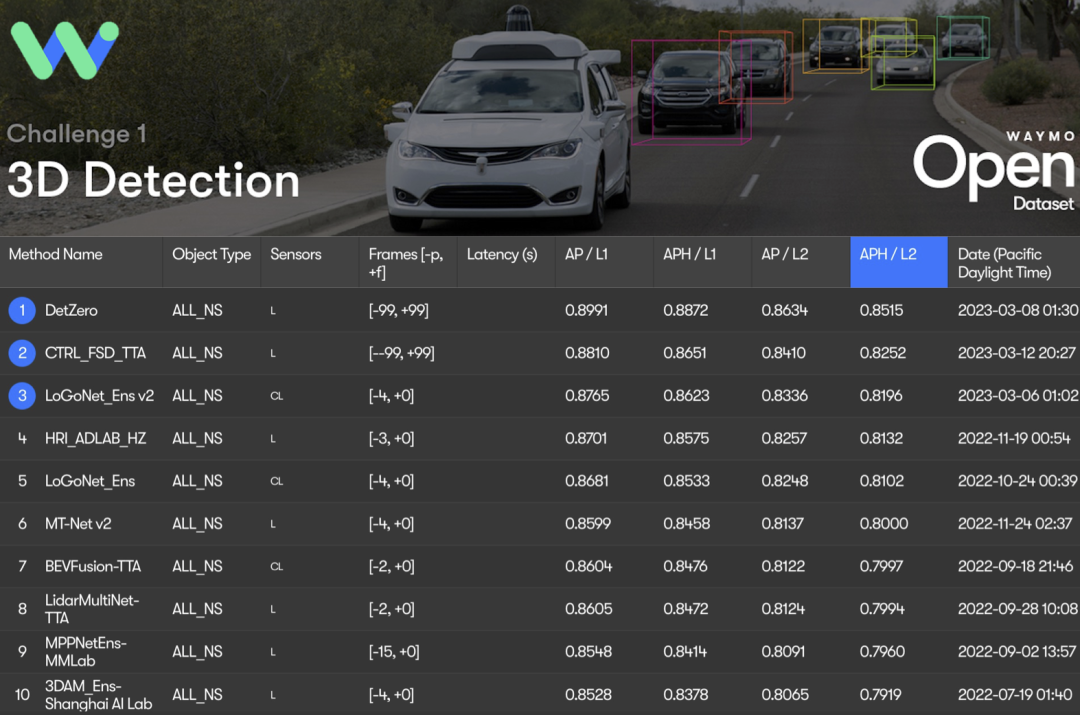
この記事では、オフライン 3D オブジェクト検出アルゴリズム フレームワーク DetZero のセットを提案します。Waymo の公開データセットの包括的な調査と評価を通じて、DetZero は連続的で完全なオブジェクトを生成できます。 、長期点群機能を最大限に活用して、知覚結果の品質を大幅に向上させます。同時に、85.15 mAPH (L2) の性能で WOD 3D 物体検出ランキングで 1 位にランクされました。さらに、DetZero はオンライン モデル トレーニングに高品質の自動ラベル付けを提供でき、その結果は手動ラベル付けのレベルに達するか、それを超えています。
これは論文のリンクです: https://arxiv.org/abs/2306.06023
書き直す必要がある内容は次のとおりです: コードのリンク: https://github.com/PJLab -ADG/ DetZero
ホームページのリンクにアクセスしてください: https://superkoma.github.io/detzero-page
1 はじめに
データアノテーションの効率を向上させるために、私たちは新しいアプローチを検討しました。この手法は深層学習と教師なし学習に基づいており、アノテーション付きデータを自動的に生成できます。大量のラベルなしデータを使用することで、道路上の物体を認識および検出する自動運転知覚モデルをトレーニングできます。この方法により、データのラベル付けコストを削減できるだけでなく、後処理の効率も向上します。実験では比較のためのベースラインとして Waymo のオフライン 3D オブジェクト検出手法 3DAL[] を使用しました。結果は、提案した手法の精度と効率が大幅に向上していることを示しています。この手法は将来の自動運転技術において重要な役割を果たすと考えています。
- 物体検出 (Detection): 少量の連続点群フレーム データを入力し、各フレームを出力します。 ;
- 動作分類動作分類) における 3D オブジェクトの境界ボックスとカテゴリ情報: オブジェクトの軌道特性に基づいて、オブジェクトの動作状態 (静止または移動) を決定します;
- オブジェクト中心の最適化 (オブジェクト中心のリファイニング): 前のモジュールによって予測された運動状態に基づいて、静止オブジェクトと移動オブジェクトの時間点群特徴がそれぞれ抽出され、正確な境界ボックスを予測します。最後に、最適化された 3D バウンディング ボックスは、ポーズ マトリックスを通じてオブジェクトが配置されている各フレームの座標系に戻されます。
- ただし、多くの主流のオンライン 3D オブジェクト検出方法は、点群の時間コンテキスト機能を利用することで、既存のオフライン 3D 検出方法よりも優れた結果を達成しています。ただし、これらの方法では、長いシーケンス点群の特性を効果的に利用できないことを認識しています。
- オブジェクト シーケンスの品質は、下流の最適化モデルに大きな影響を与えます
運動状態分類に基づく最適化モデルは、オブジェクトの特徴のタイミング。たとえば、剛体オブジェクトのサイズは時間が経過しても一定であり、さまざまな角度からデータをキャプチャすることでより正確なサイズ推定を達成できます。オブジェクトの運動軌跡は特定の運動学的制約に従う必要があり、これは軌跡の滑らかさに反映されます。 。以下の図 (a) に示すように、動的オブジェクトの場合、スライディング ウィンドウに基づく最適化メカニズムはオブジェクト ジオメトリの一貫性を考慮せず、複数の隣接するフレームの時系列点群情報を通じて境界ボックスを更新するだけです。予測された幾何学的サイズにずれが発生します。 (b) の例では、オブジェクトのすべての点群を集約することで、密な時系列点群特徴が得られ、バウンディング ボックスの正確な幾何学的サイズをフレームごとに予測できます。 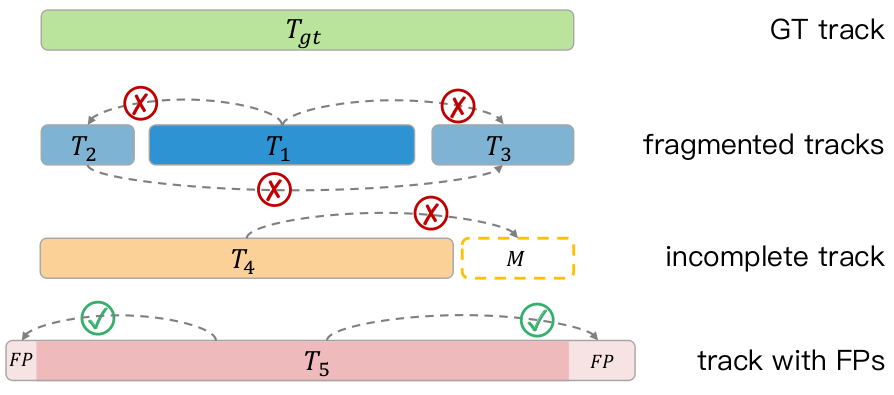
- 運動状態に基づく最適化モデルはオブジェクトのサイズを予測し (a)、幾何最適化モデルはさまざまな視点からすべての点群を集約した後にオブジェクトのサイズを予測します ( b)
- ローカル位置とグローバル位置の間の相互作用: オブジェクト シーケンス内の任意のボックスを原点としてランダムに選択し、他のすべてのボックスと対応するオブジェクト点群をこの座標系に転送し、各点とそれぞれの境界までの距離を計算します。フレームの中心点と 8 つの隅の点は、グローバル位置特徴のキーと値として機能します。オブジェクト シーケンス内の各サンプルは位置クエリとして使用され、現在の位置と他の位置の間の相対距離を決定するためにセルフ アテンション レイヤーに送信され、その後、クロス アテンション レイヤーに入力されて、コンテキスト関係をシミュレートします。ローカル位置からグローバル位置に変換し、この座標系を予測します。各初期中心点と真の中心点の間のオフセット、および機首角の差。
- 信頼の最適化: 分類ブランチは、オブジェクトが TP か FP かを分類するために使用されます。IoU 回帰ブランチは、幾何学的モデルと位置モデルによって最適化された後、オブジェクトとグラウンド トゥルース ボックスの間の IoU サイズを予測します。 。最終的な信頼スコアは、これら 2 つの分岐の幾何平均です。
2 方法
この論文では、DetZero と呼ばれる新しいオフライン 3D オブジェクト検出アルゴリズム フレームワークを提案します。このフレームワークには次の特徴があります: (1) マルチフレーム 3D 検出器とオフライン トラッカーを上流モジュールとして使用し、オブジェクト シーケンスの高い再現率 (トラック レベルの再現率) に焦点を当て、正確かつ完全なオブジェクト追跡を提供します。(2) 下流モジュールアテンション メカニズムに基づく最適化モデルが含まれており、長期的な点群特徴を使用して、洗練された幾何学的寸法、スムーズなモーション軌跡の位置、更新された信頼スコアなど、オブジェクトのさまざまな属性を学習および予測します。
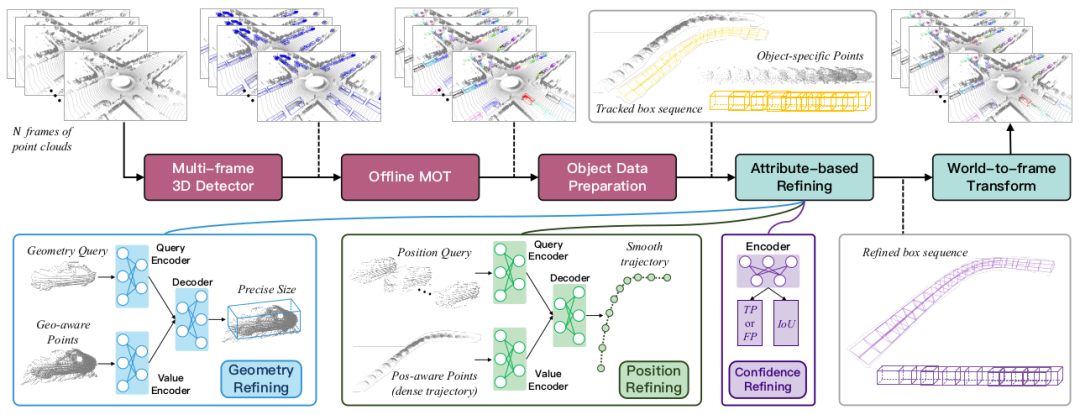
2.1 完全なオブジェクト シーケンスの生成
##基本的な検出器としてパブリック CenterPoint[] を使用します。より多くの検出候補フレームを提供するために、3 つの側面で作業を進めます。強化: (1) 異なるフレームの点群の組み合わせを入力として使用し、パフォーマンスを低下させることなくパフォーマンスを最大化します; (2) 点群密度情報を使用して、元の点群の特徴とボクセルの特徴を 2 段階のモジュールに融合し、第 1 段階の境界結果を最適化します。 ; (3) 推論段階のデータ拡張 (TTA)、マルチモデル結果融合 (アンサンブル)、およびその他のテクノロジーを使用して、複雑な環境へのモデルの適応性を向上させますオフライン追跡では 2 段階の相関戦略が導入されています。モジュール 誤ったマッチングを減らすために、ボックスは信頼度に応じて高グループと低グループに分割され、高グループは既存の軌跡を更新するために関連付けられ、更新されていない軌跡は低グループに関連付けられます。同時に、オブジェクトの軌跡の長さはシーケンスの終わりまで続くことができるため、ID 切り替えの問題が回避されます。さらに、追跡アルゴリズムを逆に実行して、別の軌跡のセットを生成し、位置の類似性によってそれらを関連付け、最後に WBF 戦略を使用して、正常に一致した軌跡を融合して、シーケンスの最初と最後の整合性をさらに向上させます。最後に、微分されたオブジェクト シーケンスについては、各フレームの対応する点群が抽出されて保存され、更新されていない冗長ボックスといくつかの短いシーケンスは、ダウンストリームの最適化なしで最終出力に直接マージされます。2.2 属性予測に基づくオブジェクト最適化モジュール
以前のオブジェクト中心の最適化モデルは、幾何学的形状の一貫性や一貫性など、異なる運動状態にあるオブジェクト間の相関関係を無視していました。隣接する瞬間における物体の運動状態の変化。これらの観察に基づいて、従来のバウンディング ボックス回帰タスクを 3 つのモジュールに分解します。 オブジェクトの形状、位置、信頼度の属性をそれぞれ予測します。- #マルチビューの幾何学的相互作用: 複数のビューをステッチすることによるオブジェクト点群オブジェクトの外観と形状を完成させることができます。まず、ローカル座標変換を実行して、オブジェクト点群をさまざまな位置のローカル フレームに位置合わせし、各点の境界ボックスの 6 つの表面への投影距離を計算して、境界ボックスの情報表現を強化します。異なるフレームのすべての点群をマージします。 マルチビューの幾何学的特徴のキーと値として、t 個のサンプルが単一ビューの幾何学的特徴のクエリとしてオブジェクト シーケンスからランダムに選択されます。幾何学的クエリは自己注意レイヤーに送信されて互いの違いが確認され、次に相互注意レイヤーに送信されて必要なパースペクティブの特徴を補完し、正確な幾何学的サイズを予測します。
3 実験
3.1 主なパフォーマンス
DetZero は 85.15 mAPH (L2) を達成し、最高の結果を達成しました。 DetZero は、長期点群を処理する方法と比較しても、最先端のマルチモーダル フュージョン 3D 検出器と比較しても、パフォーマンスに大きな利点があることを示しました。Waymo 3D 検出ランキング結果は、すべての結果で使用されています。 TTA またはアンサンブル テクノロジー、† はオフライン モデルを指します、‡ は点群画像融合モデルを指します、* は匿名の提出結果を示します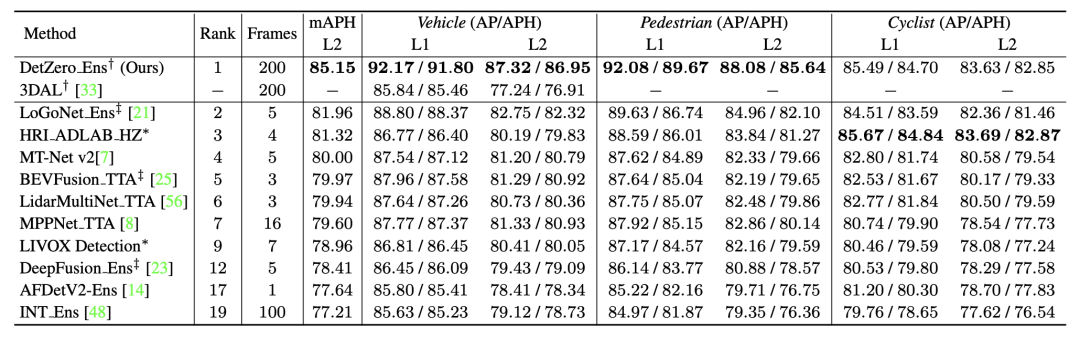
Waymo 3D 追跡ランキング、* 結果の匿名送信を示します
3.2 アブレーション実験
提案した各モジュールの役割をより適切に検証するために、Waymo 検証セットでアブレーション実験を実施し、より厳しい IoU しきい値を採用しました。測定基準
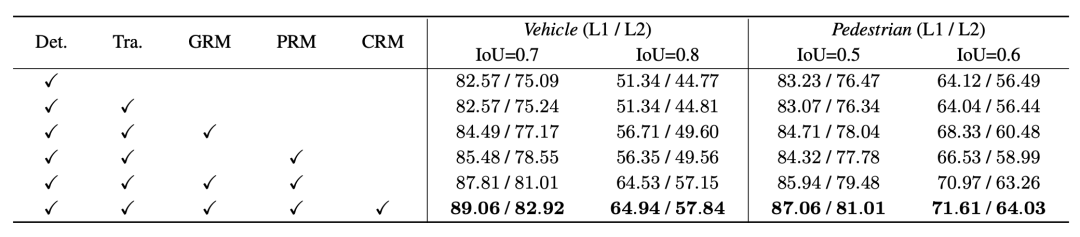 Waymo検証セットの車両と歩行者で実施され、IoUしきい値はそれぞれ標準値(0.7 & 0.5)と厳密値(0.8 & 0.6)を選択しました
Waymo検証セットの車両と歩行者で実施され、IoUしきい値はそれぞれ標準値(0.7 & 0.5)と厳密値(0.8 & 0.6)を選択しました
同時に、同じ一連の検出結果に対して、クロスコンビネーション検証のために 3DAL と DetZero のトラッカーと最適化モデルを選択しました。結果は、DetZero のトラッカーとオプティマイザーのパフォーマンスが優れており、この 2 つを組み合わせるとより効果的であることをさらに証明しました。利点。
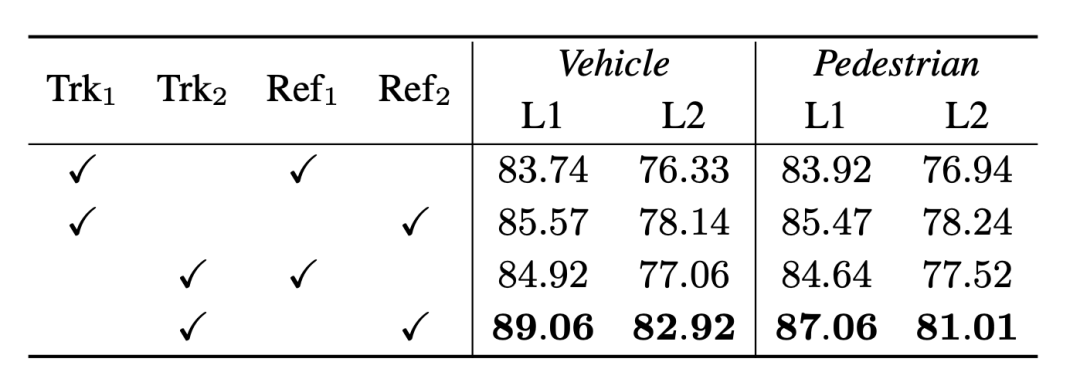 さまざまな上流モジュールと下流モジュールの組み合わせの相互検証実験。下付き文字 1 と 2 はそれぞれ 3DAL と DetZero を表し、インジケーターは 3D APHです。
さまざまな上流モジュールと下流モジュールの組み合わせの相互検証実験。下付き文字 1 と 2 はそれぞれ 3DAL と DetZero を表し、インジケーターは 3D APHです。
当社のオフライン トラッカーはより注目を集めていますオブジェクト シーケンスの完全性については、両者の MOTA パフォーマンスの差は非常に小さいですが、Recall@track のパフォーマンスが最終的な最適化パフォーマンスに大きな差をもたらす理由の 1 つです。
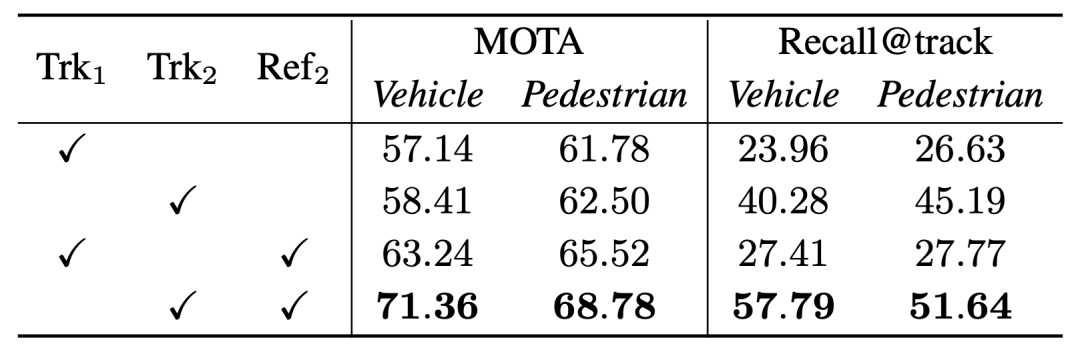 オフライン トラッカー (Trk2) ) と 3DAL トラッカー (Trk1) MOTA と Recall@track のパフォーマンス比較
オフライン トラッカー (Trk2) ) と 3DAL トラッカー (Trk1) MOTA と Recall@track のパフォーマンス比較
さらに、他の最先端トラッカーとの比較もポイントを証明します
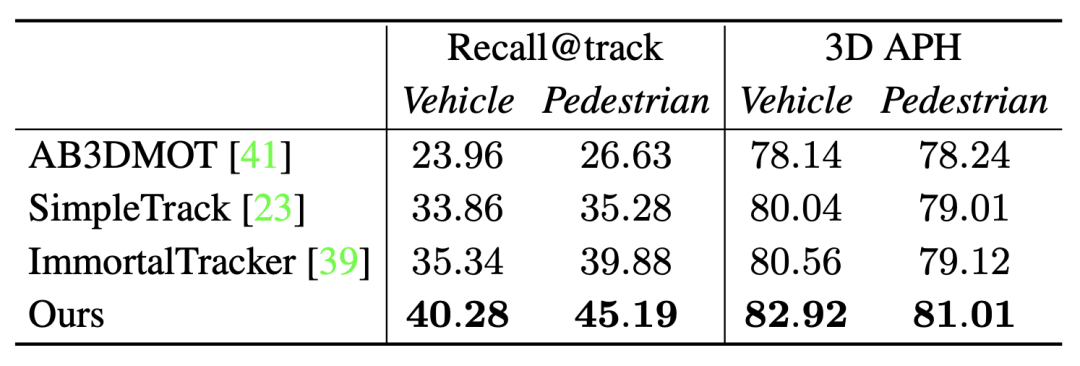 Recall@track追跡アルゴリズムによる処理後のシーケンス リコール、3D APH は同じ最適化モデルによる処理後の最終パフォーマンス
Recall@track追跡アルゴリズムによる処理後のシーケンス リコール、3D APH は同じ最適化モデルによる処理後の最終パフォーマンス
3.3 一般化パフォーマンス
最適化を検証するためモデル 上流の結果の特定のセットへの適合を修正できるかどうか、異なるパフォーマンスを持つ上流の検出追跡結果を入力として選択しました。結果は、パフォーマンスが大幅に向上したことを示しており、上流モジュールがより多くの完全なオブジェクト シーケンスを呼び出すことができる限り、オプティマイザーは最適化のために時系列点群の特性を効果的に利用できることをさらに証明しています。
Waymo 検証セットでの一般化パフォーマンス検証、指標は 3D APH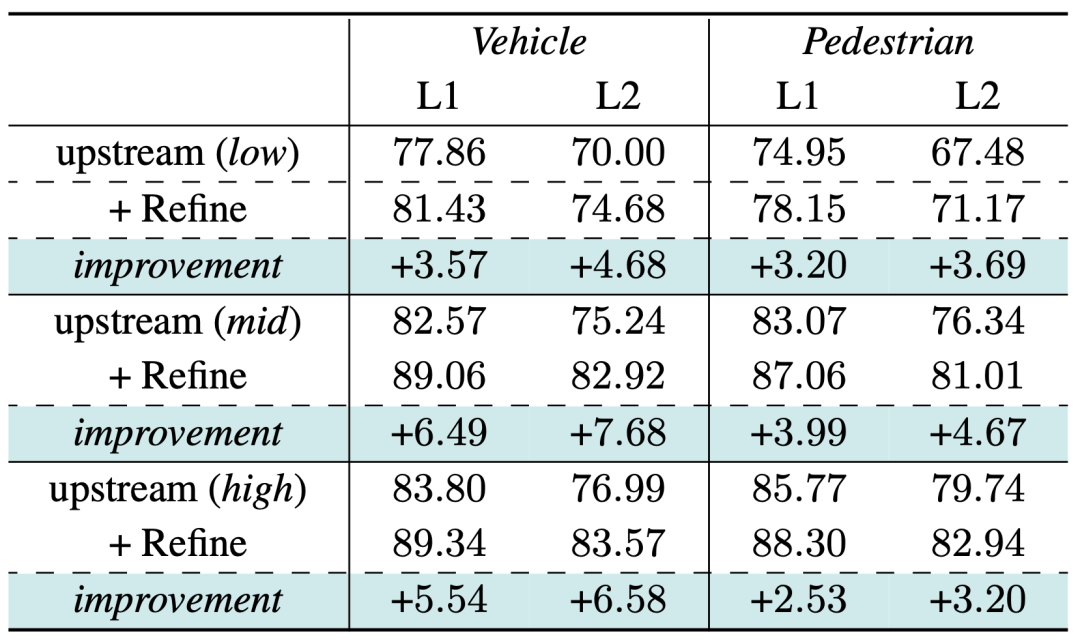
3DAL の実験設定を使用して、比較 5 つの指定されたシーケンスに対する DetZero の AP パフォーマンスをレポートします。単一フレームベースの再アノテーション結果と元のグラウンド トゥルース アノテーション結果の一貫性を比較することで人間のパフォーマンスを測定します。 3DAL や人間と比較して、DetZero はさまざまなパフォーマンス指標で利点を示しています。
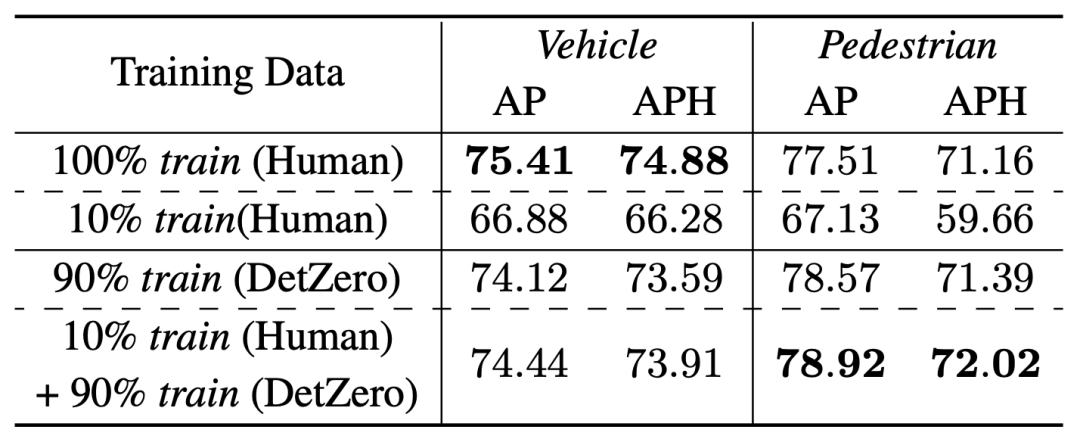
車両カテゴリのさまざまな IoU しきい値の下での 3D AP と BEV AP のパフォーマンスの比較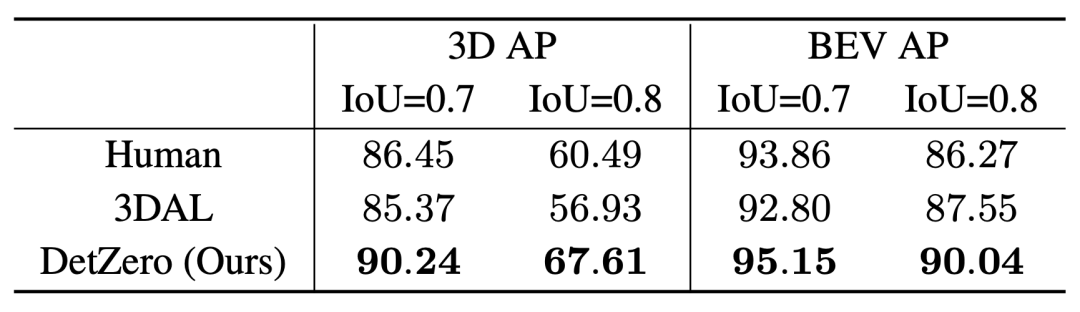 - 高品質の自動アノテーション結果は、オンライン モデル トレーニングの手動アノテーション結果を置き換えることができるため、Waymo 検証セットで半教師あり学習検証を実施しました。教師モデル (DetZero) のトレーニング データとしてトレーニング データの 10% をランダムに選択し、残りの 90% のデータに対して推論を実行して、自動アノテーションの結果を取得しました。この結果は、生徒モデルのラベルとして使用されます。学生モデルとしてシングルフレーム CenterPoint を選択しました。車両カテゴリでは、90% の自動ラベルと 10% の真のラベルを使用したトレーニングの結果は、100% の真のラベルを使用したトレーニングの結果に近いですが、歩行者カテゴリでは、自動ラベルでトレーニングされたモデルの結果がすでに優れています。自動ラベル付けがオンライン モデル トレーニングに使用できることを示す結果
- 高品質の自動アノテーション結果は、オンライン モデル トレーニングの手動アノテーション結果を置き換えることができるため、Waymo 検証セットで半教師あり学習検証を実施しました。教師モデル (DetZero) のトレーニング データとしてトレーニング データの 10% をランダムに選択し、残りの 90% のデータに対して推論を実行して、自動アノテーションの結果を取得しました。この結果は、生徒モデルのラベルとして使用されます。学生モデルとしてシングルフレーム CenterPoint を選択しました。車両カテゴリでは、90% の自動ラベルと 10% の真のラベルを使用したトレーニングの結果は、100% の真のラベルを使用したトレーニングの結果に近いですが、歩行者カテゴリでは、自動ラベルでトレーニングされたモデルの結果がすでに優れています。自動ラベル付けがオンライン モデル トレーニングに使用できることを示す結果
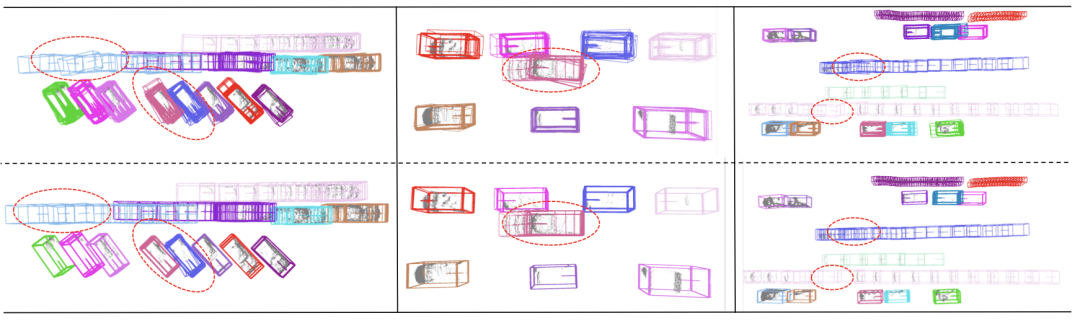
赤いボックスは上流の入力結果を表し、青いボックスは最適化モデルの出力結果を表します。
最初の行は上流の入力結果を表します。 2 行目は最適化モデルの出力結果を表し、点線内のオブジェクトは最適化前後で明らかな違いがある位置を表します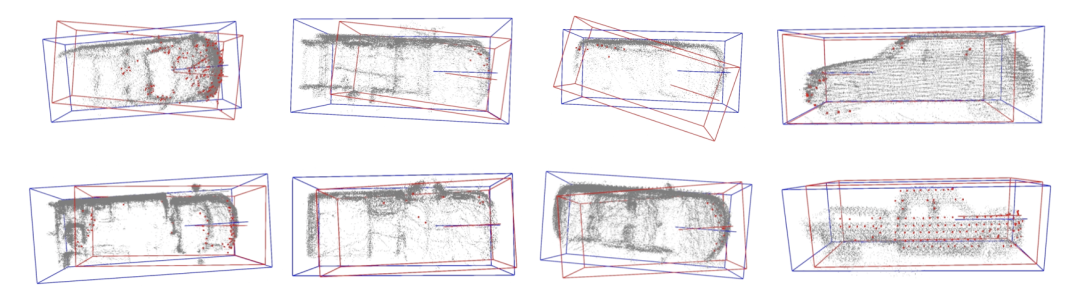
元のリンク: https://mp.weixin.qq.com/s/HklBecJfMOUCC8gclo-t7Q
以上がDetZero: Waymo は 3D 検出リストで 1 位にランクされており、手動アノテーションに匹敵します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7566
7566
 15
1386
52
87
11
28
106
15
1386
52
87
11
28
106

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
