

Meta は最近、Audiobox と呼ばれる AI サウンド生成モデルを発売しました。このモデルは音声とテキストの両方の入力を受け取ることができ、ユーザーは音声とテキストの説明を通じて必要な音声を生成できます。
このモデルは、Meta が今年 6 月に発表した Voicebox AI モデルをベースにしていると報告されており、Audiobox はさまざまな環境音や自然な会話音声を生成でき、オーディオの生成と編集機能を統合しているため、ユーザーは必要なものを自由に生成します。
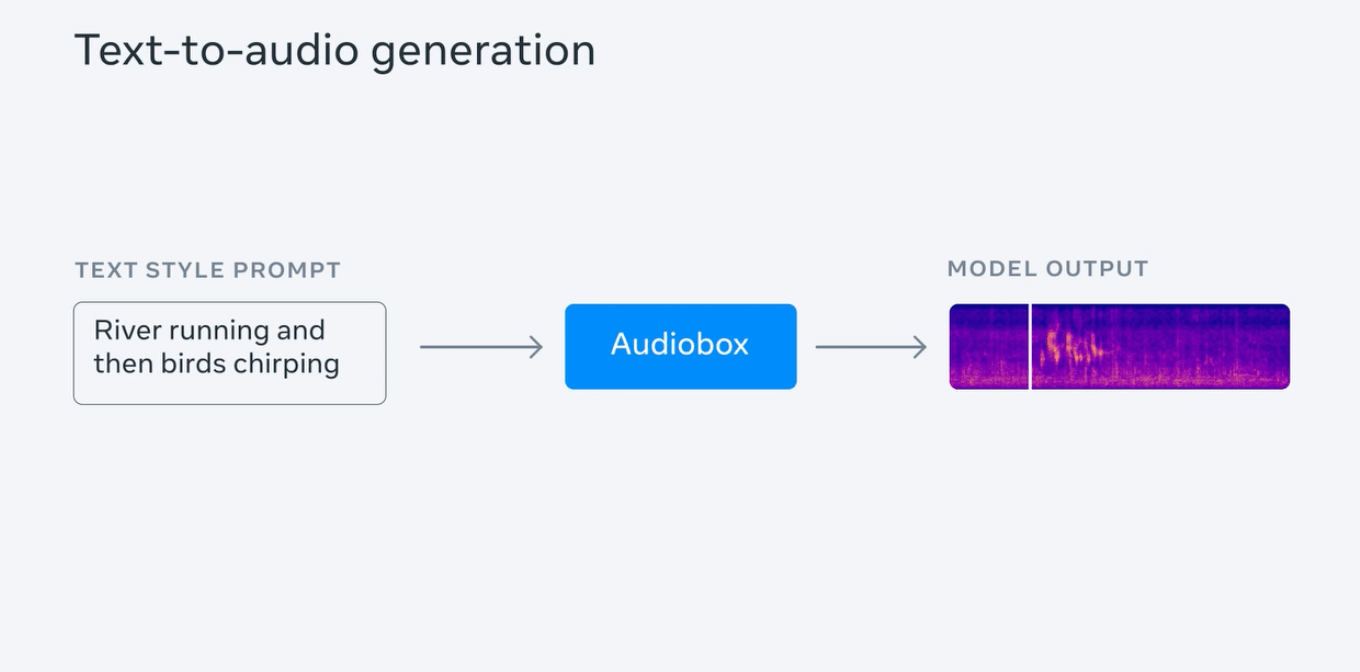
IT House は、この Audiobox モデルが、ターゲット オーディオの生成を容易にする Voicebox の「ガイド サウンド」メカニズムに基づいており、「フロー マッチング」拡散モデル生成手法と連携して「サウンド フィリング (オーディオ インフィリング)」を実現していることを発見しました。マルチレイヤーオーディオを生成する機能。
メタ テストは、雷雨の音を含む雨の音声を生成し、「鳥のさえずりを伴う水の流れる音」、「甲高く速いリズムで話す若い女性」など、デモンストレーション用の一連のプロンプト センテンスを入力します。 、など; 同時に、このテストでは、人間の声とテキスト プロンプトを入力して、感情 (「悲しくて遅い」) と背景音 (教会にいるとき) を含む音声を生成します。
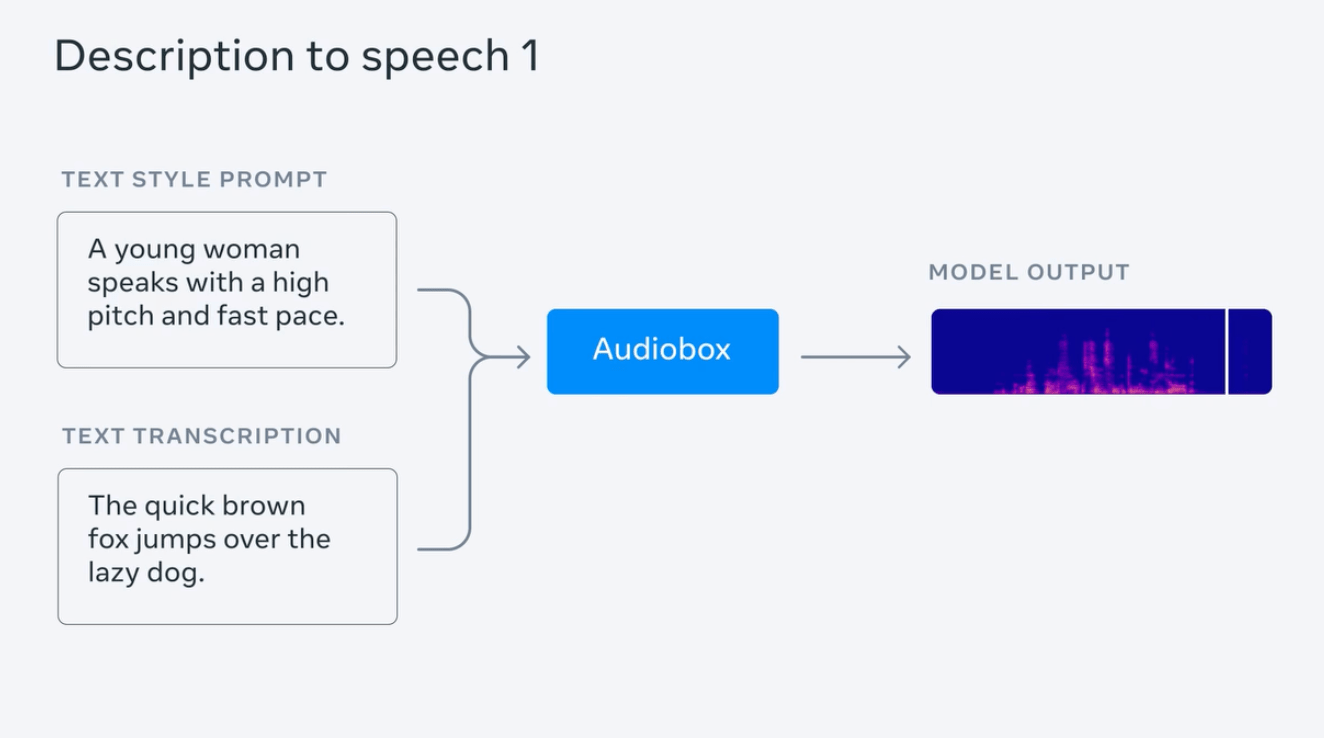
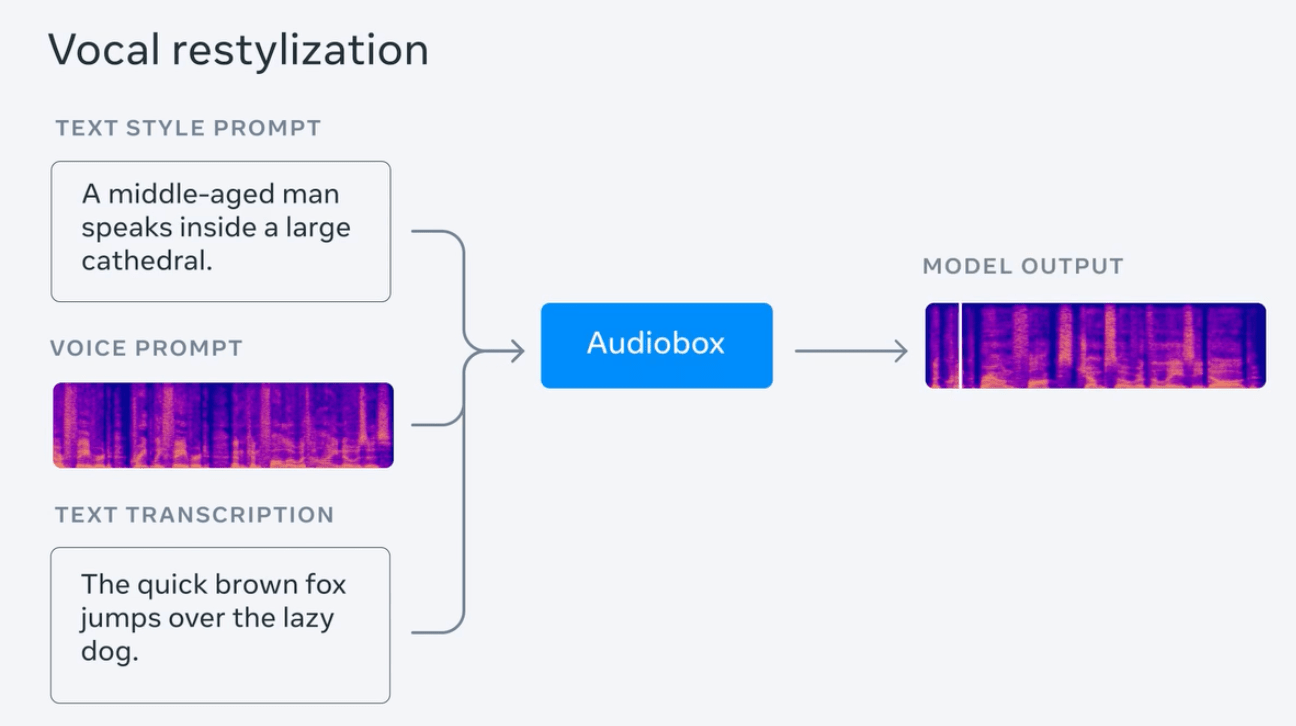
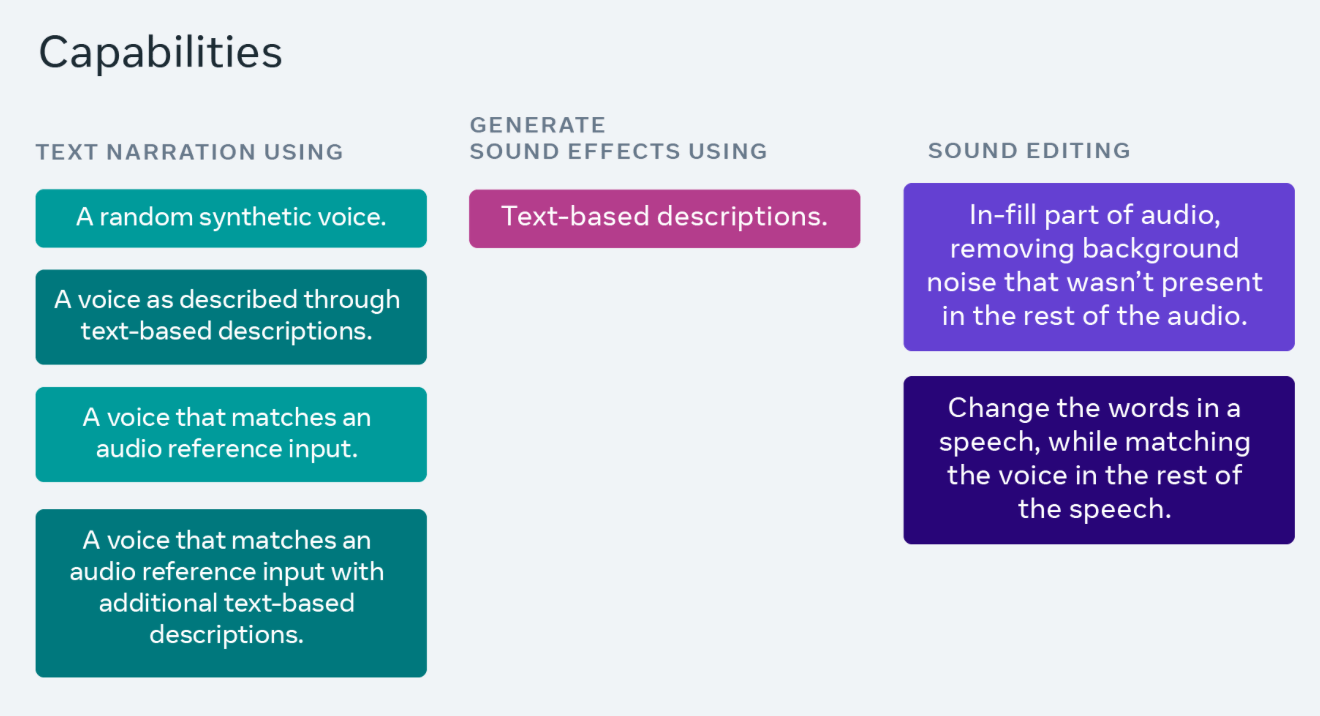
以上がMeta が音声とテキストの同時入力をサポートする AI オーディオ モデル Audiobox を発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



