PyTorch チームは、大規模モデルの推論を高速化する方法を個人的に教えます。
ここ 1 年で生成 AI は急速に発展し、その中でもテキスト生成は特に人気のある分野であり、以下のような多くのオープンソース プロジェクトが開発されています。 llama.cpp、vLLM、MLC-LLM などは、より良い結果を達成するために常に最適化されています。 機械学習コミュニティで最も人気のあるフレームワークの 1 つとして、PyTorch はこの新しい機会を自然に捉え、継続的に最適化してきました。これらのイノベーションを誰もがよりよく理解できるように、PyTorch チームは、純粋なネイティブ PyTorch を使用して生成 AI モデルを高速化する方法に焦点を当てた一連のブログを特別にセットアップしました。 
コード アドレス: https://github.com/pytorch-labs/gpt-fast PyTorch チームはブログで、純粋なネイティブ PyTorch のみを使用して Segment Anything (SAM) モデルを書き直す方法をデモンストレーションしました。これは、元の実装より 8 倍高速です。このブログでは、LLM 推論を高速化する方法という新しいことを紹介しています。
まずは結果を見てみましょう. チームは LLM を書き直したところ、精度を失うことなく推論速度がベースラインより 10 倍速くなり、使用した行数は 1000 行未満になりました純粋なネイティブ PyTorch コードです。
すべてのベンチマークは、330 W に制限されている A100-80GB で実行されました。 Torch.compile: PyTorch モデル コンパイラーである PyTorch 2.0 には、1 行のコードで既存のモデルを高速化できる torch.compile () という新しい関数が追加されています; GPU 量子化: 計算精度を下げて、モデル;投機的デコーディング: 小さな「ドラフト」モデルを使用して大規模な「ターゲット」モデルの出力を予測する大規模なモデル推論高速化手法;Tensor Parallel: 複数のデバイスでモデルを実行することでモデル推論を高速化します。
次に、各ステップがどのように実装されるかを見てみましょう。 大規模モデルの推論を高速化するための 6 つの手順
研究では、最適化を行わないと次のことが示されています。 、大規模モデルの推論パフォーマンスは 25.5 tok/s で、効果はあまり良くありません: いくつかの調査の後、最終的に理由を見つけました: 過剰な CPU オーバーヘッド。次に、次の 6 段階の最適化プロセスがあります。
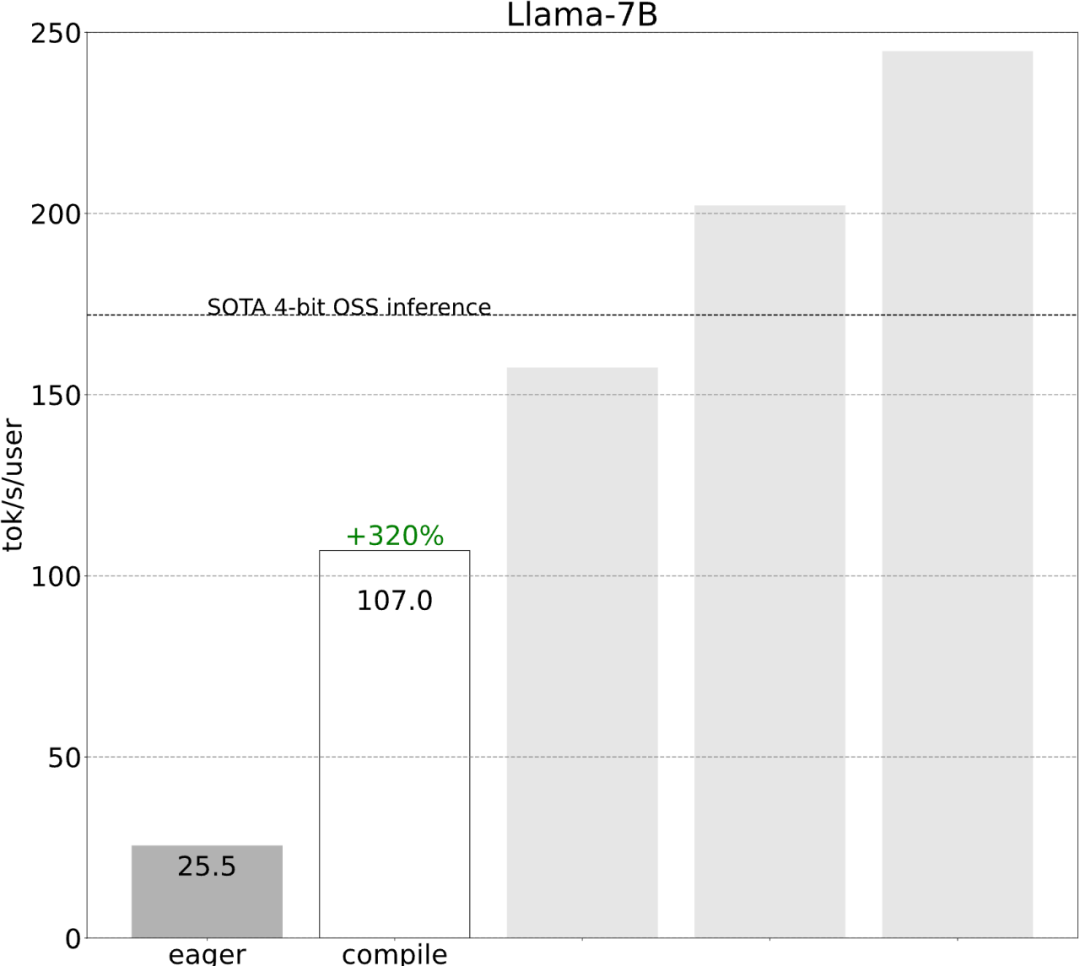
#ステップ 1: Torch.compile と静的 KV キャッシュを通じて CPU オーバーヘッドを削減し、107.0 TOK/S
torch.compile を使用すると、特に mode="reduce-overhead" (以下のコードを参照) の場合、ユーザーはより大きな領域を 1 つのコンパイル領域にキャプチャでき、この機能は CPU オーバーヘッドを削減するのに非常に役立ちます。さらに、この記事では、モデル内に「グラフの中断」(つまり、torch.compile がコンパイルできない部分) がないことを確認するために、 fullgraph=True も指定します。
#ただし、torch.compile の恩恵を受けても、まだいくつかの障害があります。
#最初のハードルは kv キャッシュです。つまり、ユーザーがより多くのトークンを生成すると、kv キャッシュの「論理長」が増加します。この問題は 2 つの理由で発生します: 1 つは、キャッシュが増大するたびに kv キャッシュを再割り当て (およびコピー) するのは非常にコストがかかること、2 つ目は、この動的割り当てによりオーバーヘッドを削減することがより困難になることです。
この問題を解決するために、この記事では静的 KV キャッシュを使用し、KV キャッシュのサイズを静的に割り当て、アテンション内の未使用の値をマスクします。機構。
2 番目の障害はプレフィル段階です。 Transformer によるテキスト生成は、2 段階のプロセスとして見ることができます。 1. プロンプト全体を処理するプレフィル段階 2. トークンをデコードします。kv キャッシュは設定されていますが、静的化は完了しましたが、プレフィルフェーズではプロンプトの長さが可変であるため、さらに多くのダイナミクスが必要になります。したがって、これら 2 つのステージをコンパイルするには、別個のコンパイル戦略を使用する必要があります。
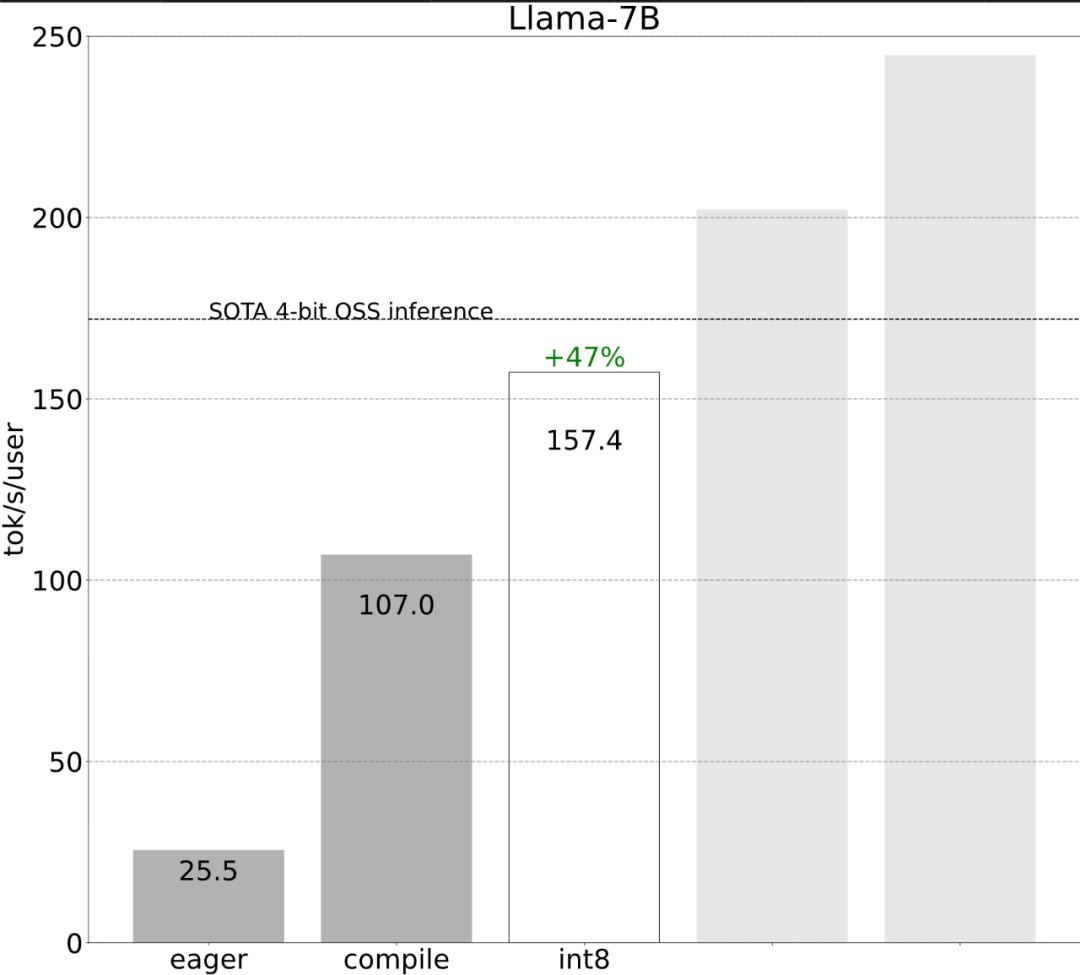
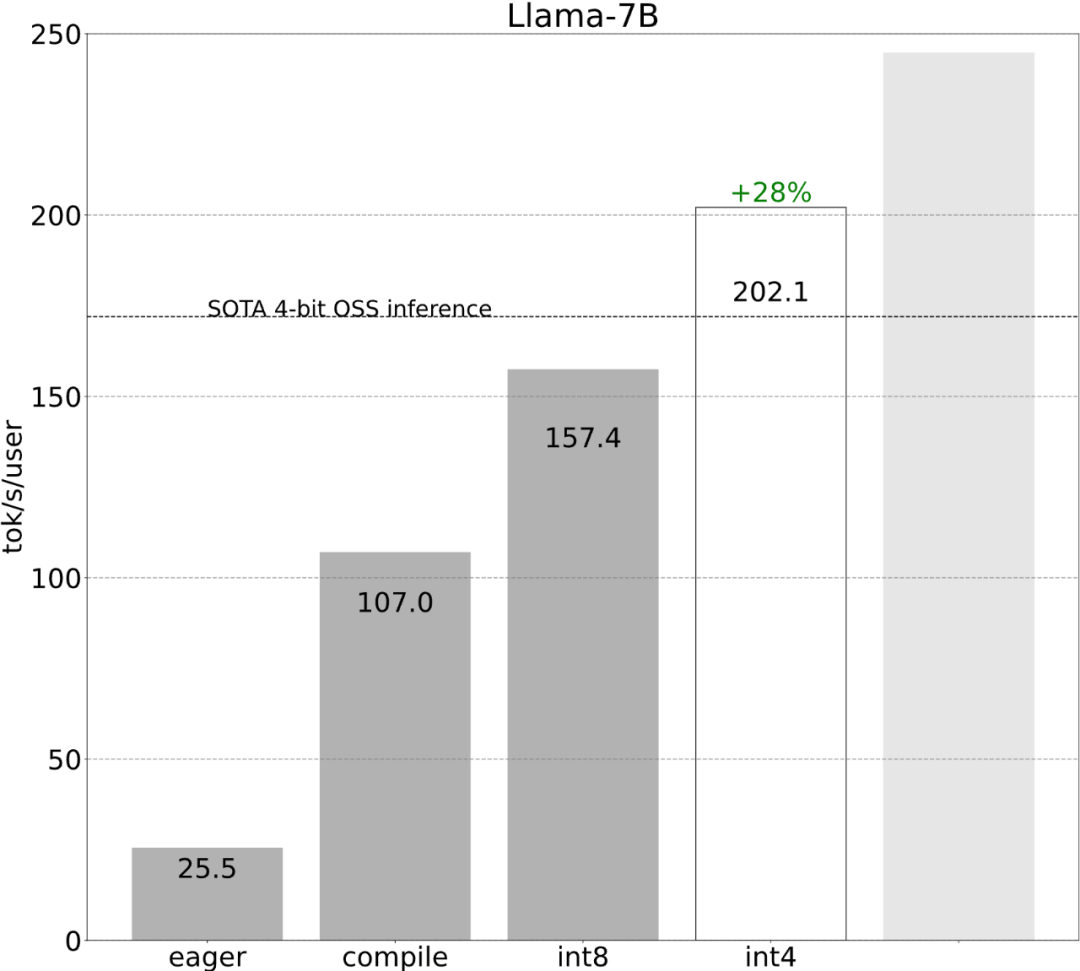
これらの詳細は少し難しいですが、実装は難しくなく、パフォーマンスが大幅に向上します。この操作の後、パフォーマンスは 25 tok/s から 107 tok/s に 4 倍以上向上しました。
#第 2 ステップ: int8 重み量子化を通じてメモリ帯域幅のボトルネックを軽減し、157.4 tok /s##上記を通じて、torch.compile、静的 kv キャッシュなどを適用することによってもたらされる大幅な高速化が見られましたが、PyTorch チームはこれに満足しておらず、最適化のための別の角度を見つけました。 彼らは、生成 AI トレーニングを高速化する際の最大のボトルネックは、GPU グローバル メモリからレジスタに重みを読み込むコストであると考えています。言い換えれば、各フォワードパスは GPU 上のすべてのパラメータに「触れる」必要があります。では、理論的にはモデル内のすべてのパラメーターにどれくらいの速さで「アクセス」できるのでしょうか? #これを測定するために、この記事ではモデル帯域幅使用率 (MBU) を使用します。これは次のように非常に簡単に計算できます。
たとえば、7B パラメータ モデルの場合、各パラメータは fp16 (パラメータあたり 2 バイト) に保存され、107 トークン/秒を達成できます。 A100-80GB の理論上のメモリ帯域幅は 2 TB/秒です。
下の図に示すように、上記の式を特定の値に代入すると、72% の MBU を得ることができます。多くの研究では 85% を突破することが困難であるため、この結果は非常に良好です。 しかし、PyTorch チームはこの値を増やしたいとも考えています。彼らは、モデル内のパラメータの数を変更することも、GPU のメモリ帯域幅を変更することもできないことを発見しました。しかし、各パラメータに保存されるバイト数を変更できることがわかりました。
つまり、彼らは int8 量子化を使用する予定です。
これは量子化された重みだけであり、計算自体は bf16 で行われることに注意してください。さらに、torch.compile を使用すると、int8 量子化用の効率的なコードを簡単に生成できます。
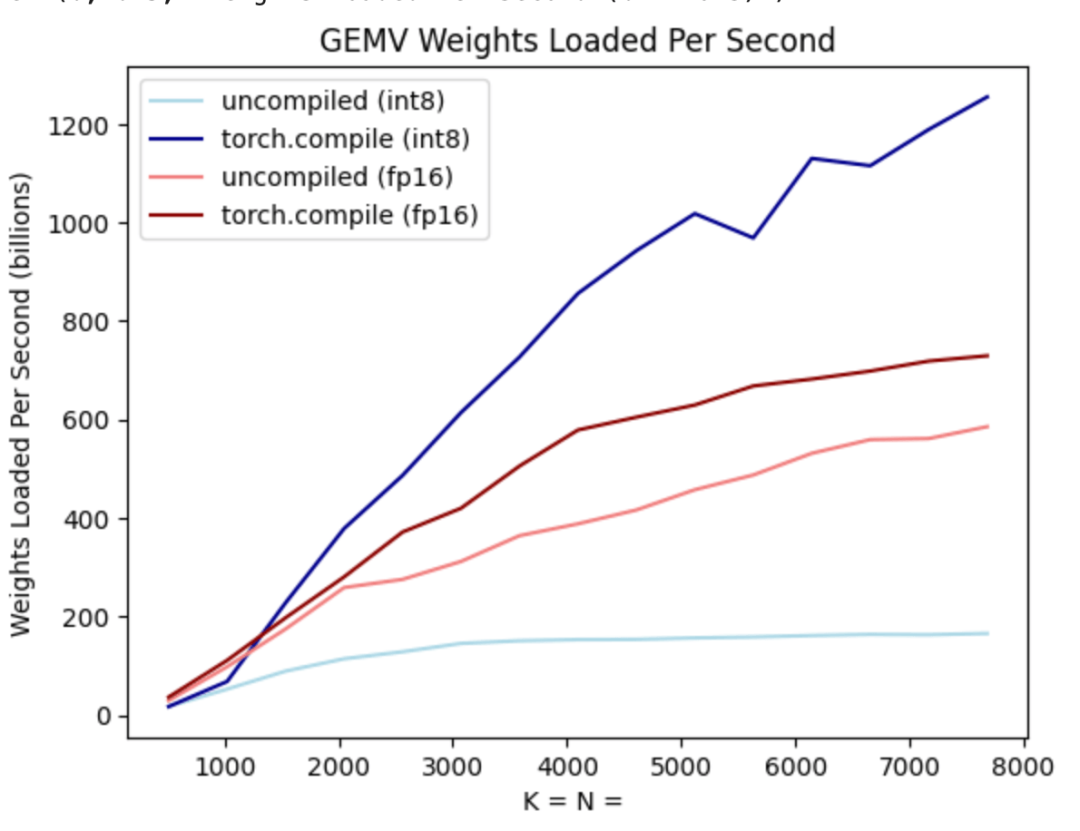
#上の図に示すように、濃い青色の線 (torch.compile int8) から torch を使用していることがわかります。重みのみの量子化が int8 の場合、パフォーマンスが大幅に向上します。
int8 量子化を Llama-7B モデルに適用すると、パフォーマンスが約 50% 向上し、157.4 トークン/秒に達します。
#ステップ 3: 投機的デコードを使用する
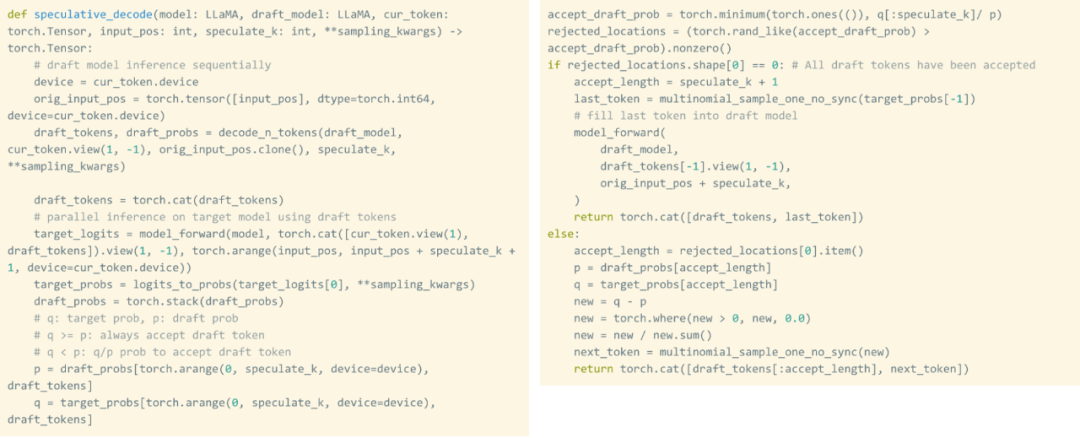
After int8 を使用した後でも量子化やその他のテクノロジーを利用しても、チームは依然として別の問題に直面していました。それは、100 個のトークンを生成するには、重みを 100 回ロードする必要があるということです。 重みが量子化されていても、重みを何度もロードすることは避けられません。投機的デコードを活用すると、この厳密なシリアル依存関係が解消され、速度が向上することがわかりました。
この調査では、ドラフト モデルを使用して 8 個のトークンを生成し、次にバリデーター モデルを使用してそれらを並列処理し、一致しないトークンを破棄します。このプロセスにより、シリアルの依存関係が解消されます。実装全体には約 50 行のネイティブ PyTorch コードが必要です。
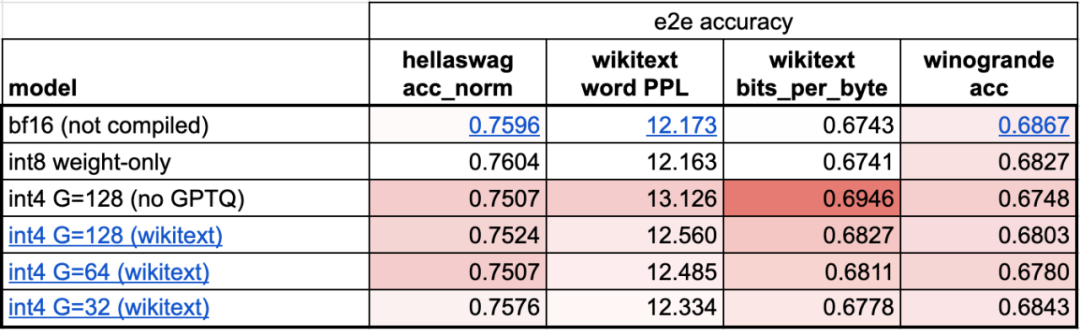
ステップ 4: int4 量子化と GPTQ メソッドを使用して重みをさらに削減し、202.1 tok/sこの記事では、重みが 4 ビットになるとモデルの精度が低下し始めることがわかりました。
この問題を解決するために、この記事では 2 つの手法を使用して問題を解決します。1 つ目は、よりきめの細かいスケーリング係数を使用することです。もう 1 つは、より高度な量子化戦略。これらの操作を組み合わせると、次のようになります。
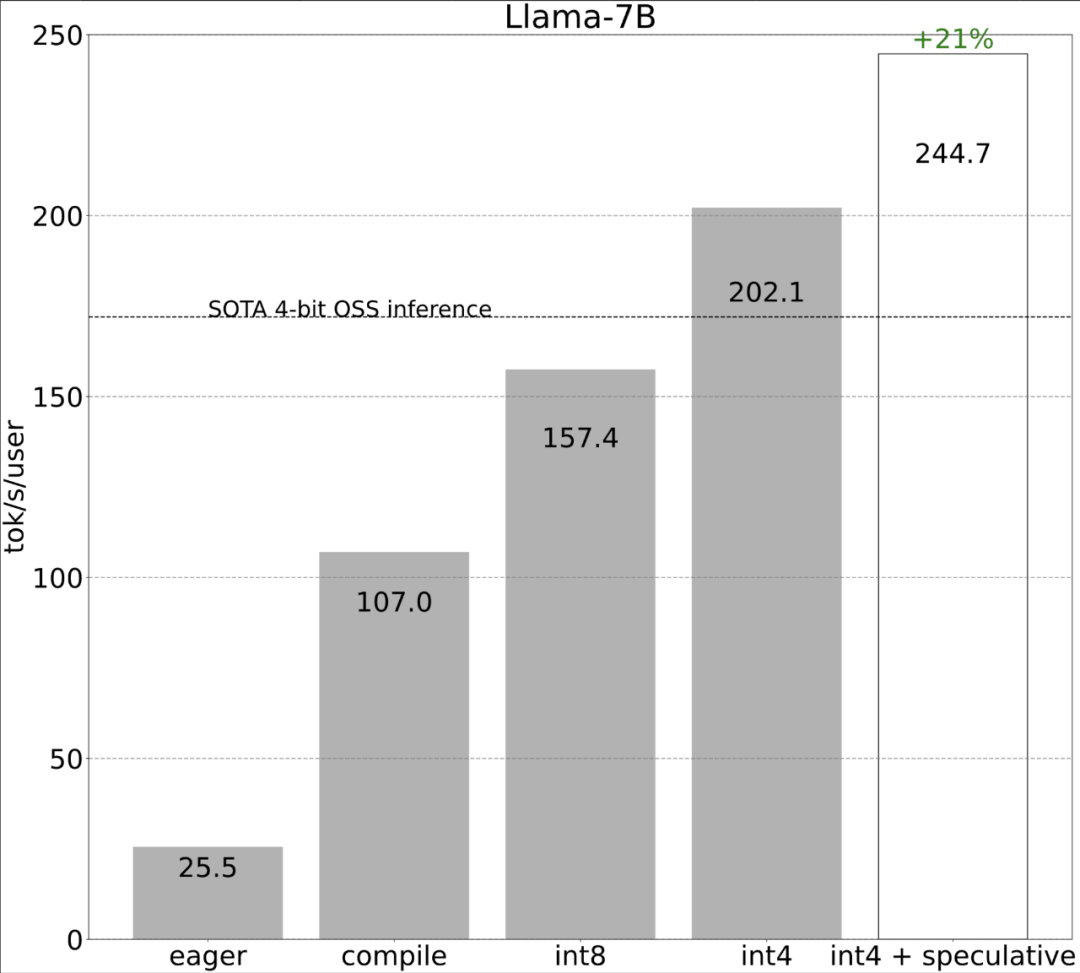
# ステップ 5: すべてを組み合わせると、244.7 tok/s # になります。
##最後に、すべてのテクニックを組み合わせてパフォーマンスを向上させると、244.7 tok/s が得られます。
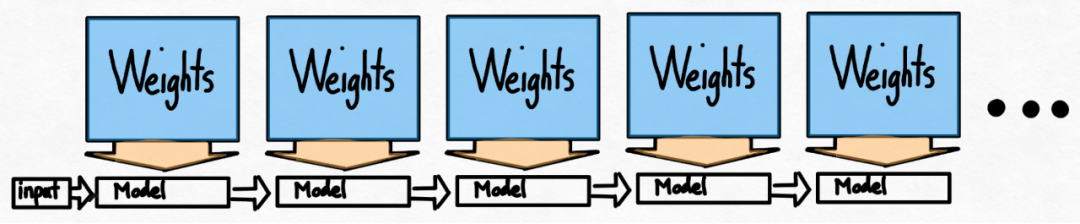
ステップ 6: テンソル並列処理
これまでのこの記事の目的は、単一の GPU での遅延を最小限に抑えます。実際には、複数の GPU を使用することも可能であり、レイテンシはさらに改善されます。
幸いなことに、PyTorch チームは、150 行のコードのみを必要とし、モデルの変更を必要としない、テンソル並列処理用の低レベル ツールを提供しています。 前述のすべての最適化は引き続きテンソル並列処理と組み合わせることができ、これらを組み合わせると、Llama-70B モデルで 55 トークン/秒を達成できます。 int8 量子化を提供します。
#最後に、記事の主な内容を簡単にまとめます。この記事では、Llama-7B で「compile int4 quant speculative decoding」の組み合わせを使用して 240 tok/s を達成しています。この論文では、Llama-70B で、SOTA パフォーマンスに近いかそれを超える約 80 tok/s を達成するテンソル並列処理も導入しています。
#元のリンク: https://pytorch.org/blog/accelerated-generative-ai-2/以上がPyTorch チームは 1,000 行未満のコードで Llama 7B を 10 倍高速化しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



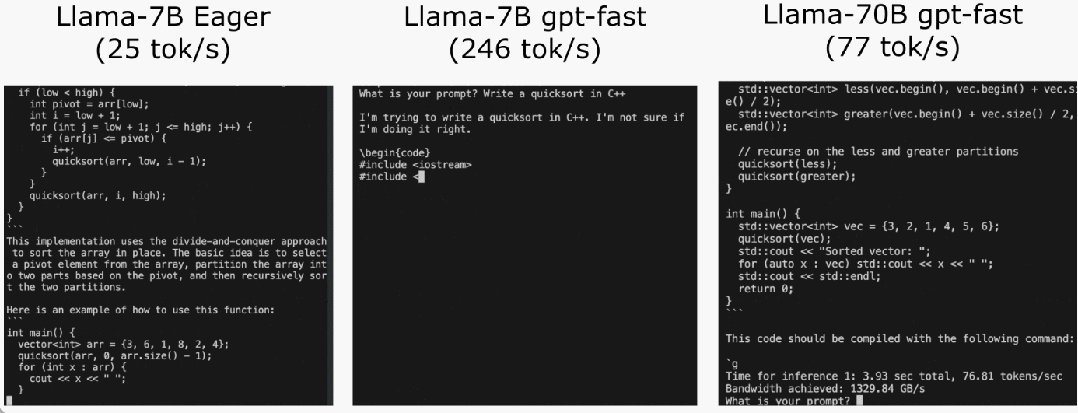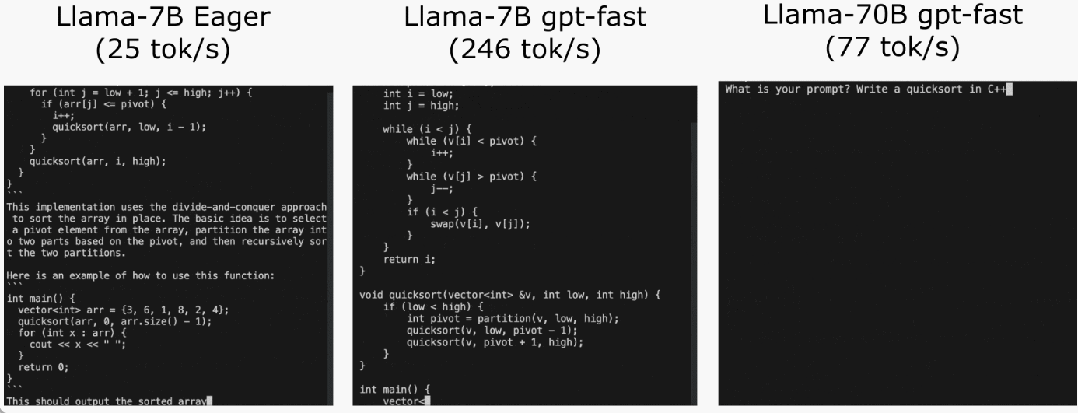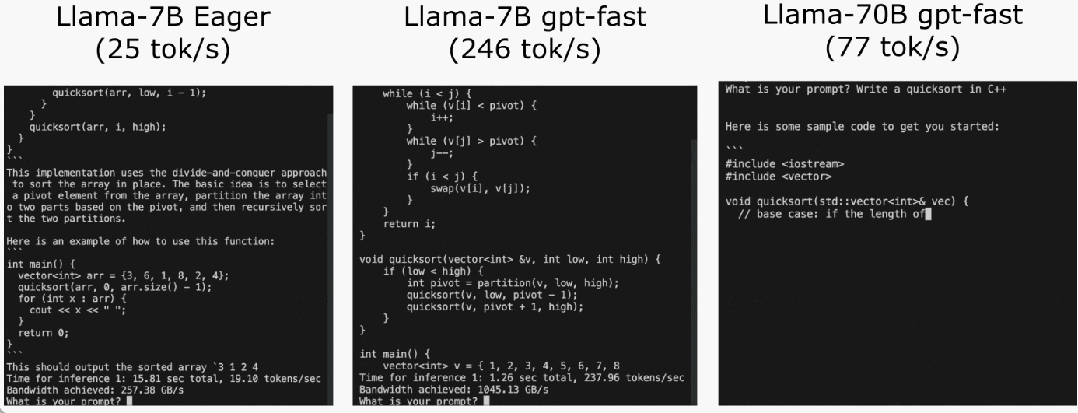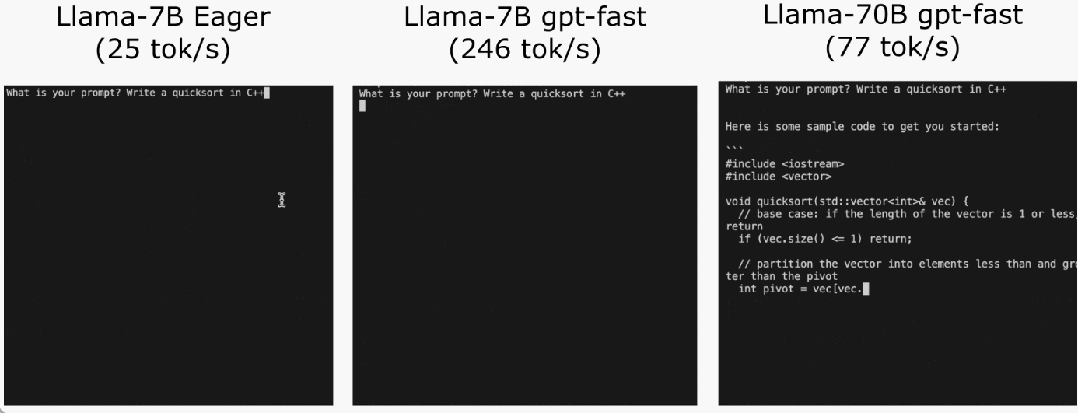
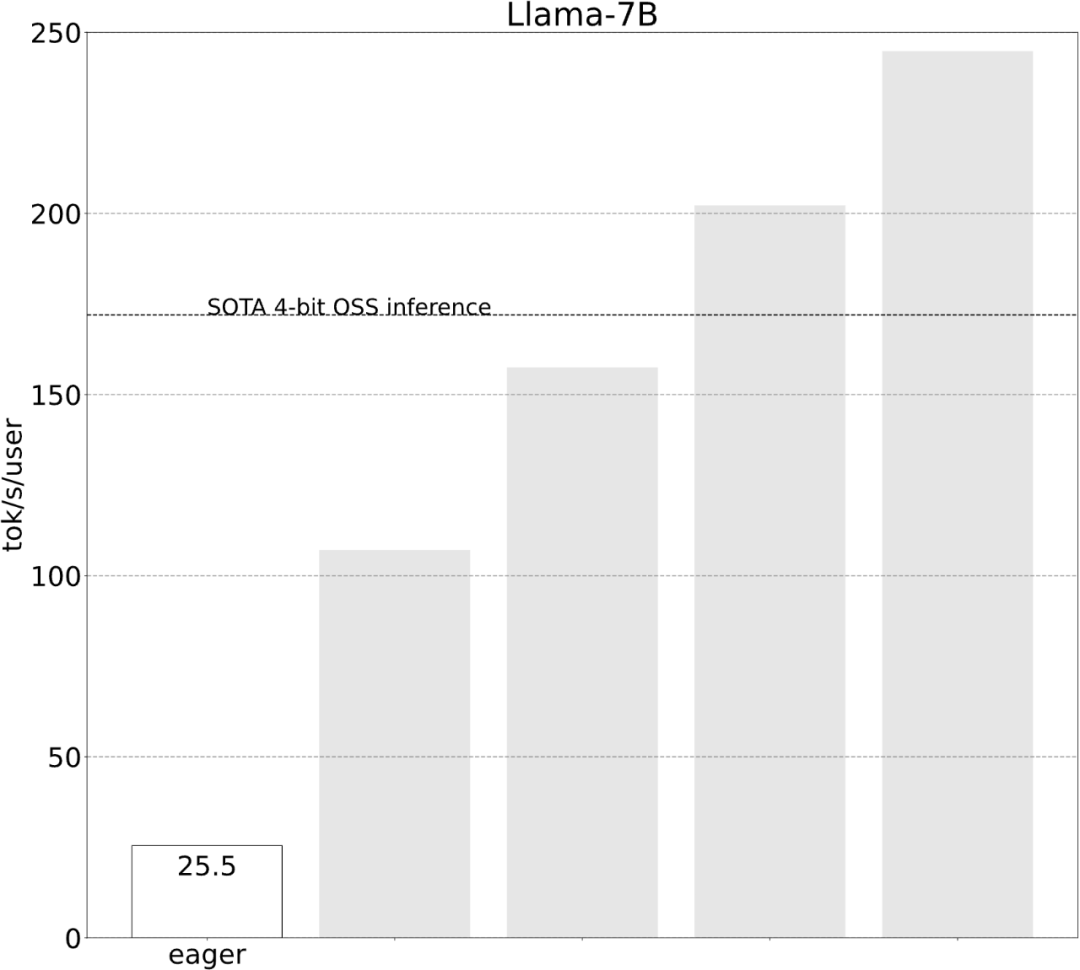 いくつかの調査の後、最終的に理由を見つけました: 過剰な CPU オーバーヘッド。次に、次の 6 段階の最適化プロセスがあります。
いくつかの調査の後、最終的に理由を見つけました: 過剰な CPU オーバーヘッド。次に、次の 6 段階の最適化プロセスがあります。  #ステップ 1: Torch.compile と静的 KV キャッシュを通じて CPU オーバーヘッドを削減し、107.0 TOK/S
#ステップ 1: Torch.compile と静的 KV キャッシュを通じて CPU オーバーヘッドを削減し、107.0 TOK/S

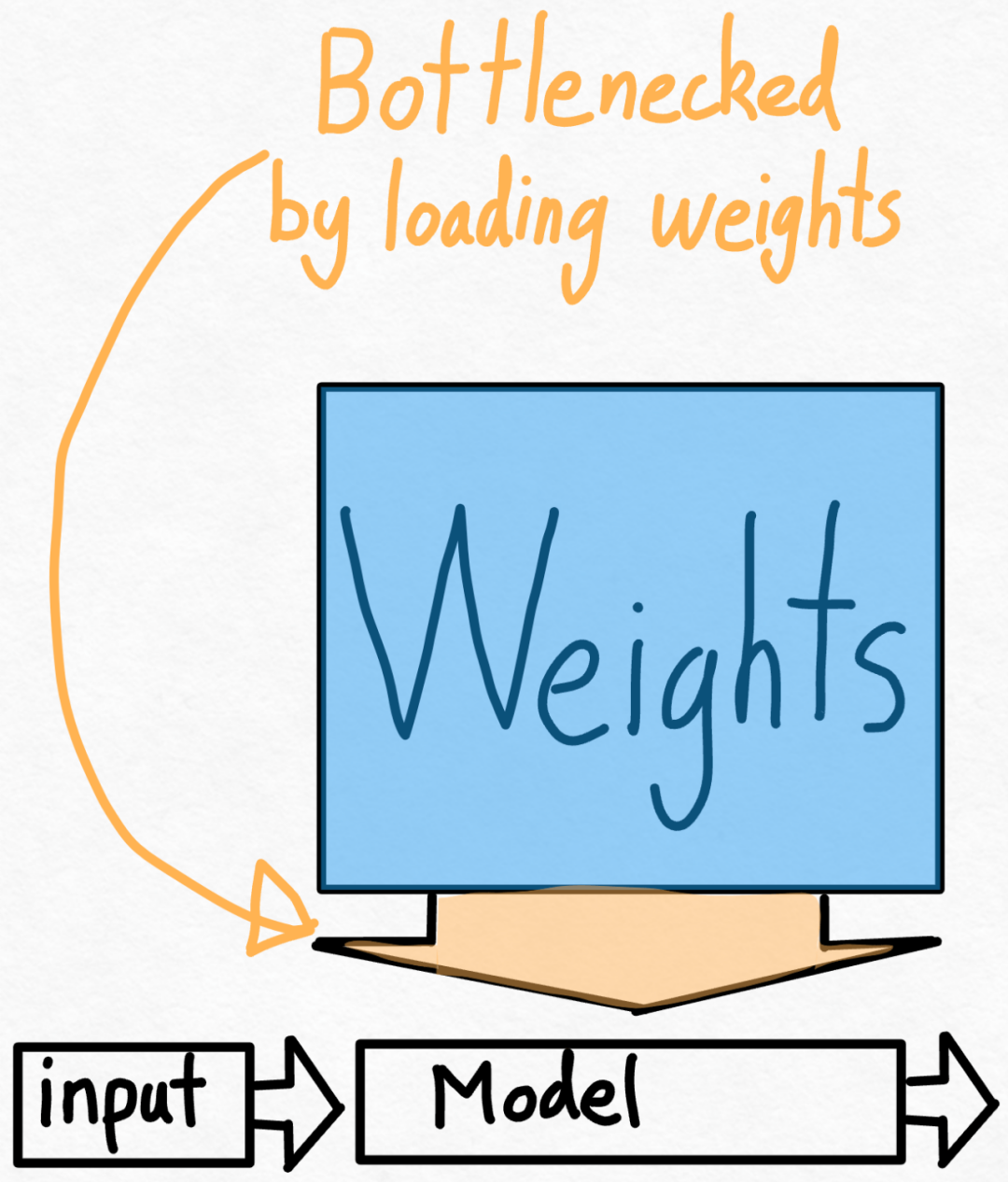 #これを測定するために、この記事ではモデル帯域幅使用率 (MBU) を使用します。これは次のように非常に簡単に計算できます。
#これを測定するために、この記事ではモデル帯域幅使用率 (MBU) を使用します。これは次のように非常に簡単に計算できます。  たとえば、7B パラメータ モデルの場合、各パラメータは fp16 (パラメータあたり 2 バイト) に保存され、107 トークン/秒を達成できます。 A100-80GB の理論上のメモリ帯域幅は 2 TB/秒です。
たとえば、7B パラメータ モデルの場合、各パラメータは fp16 (パラメータあたり 2 バイト) に保存され、107 トークン/秒を達成できます。 A100-80GB の理論上のメモリ帯域幅は 2 TB/秒です。 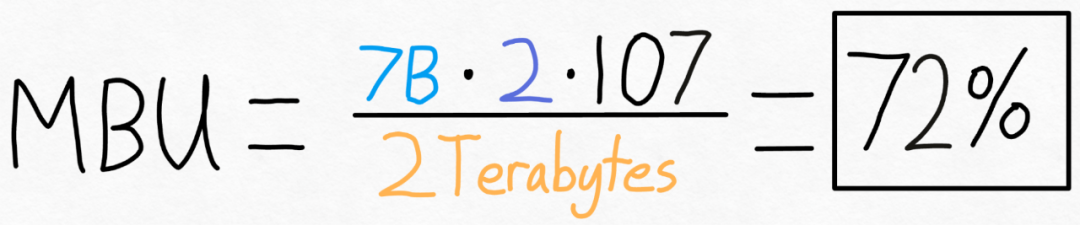 しかし、PyTorch チームはこの値を増やしたいとも考えています。彼らは、モデル内のパラメータの数を変更することも、GPU のメモリ帯域幅を変更することもできないことを発見しました。しかし、各パラメータに保存されるバイト数を変更できることがわかりました。
しかし、PyTorch チームはこの値を増やしたいとも考えています。彼らは、モデル内のパラメータの数を変更することも、GPU のメモリ帯域幅を変更することもできないことを発見しました。しかし、各パラメータに保存されるバイト数を変更できることがわかりました。  つまり、彼らは int8 量子化を使用する予定です。
つまり、彼らは int8 量子化を使用する予定です。 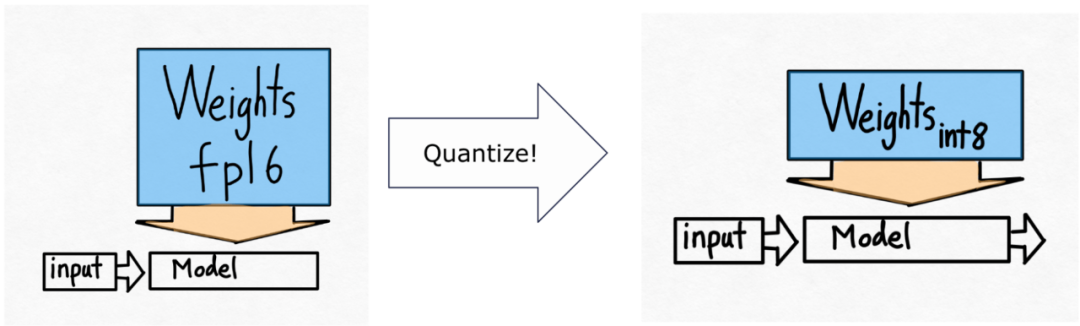 これは量子化された重みだけであり、計算自体は bf16 で行われることに注意してください。さらに、torch.compile を使用すると、int8 量子化用の効率的なコードを簡単に生成できます。
これは量子化された重みだけであり、計算自体は bf16 で行われることに注意してください。さらに、torch.compile を使用すると、int8 量子化用の効率的なコードを簡単に生成できます。 
 前述のすべての最適化は引き続きテンソル並列処理と組み合わせることができ、これらを組み合わせると、Llama-70B モデルで 55 トークン/秒を達成できます。 int8 量子化を提供します。
前述のすべての最適化は引き続きテンソル並列処理と組み合わせることができ、これらを組み合わせると、Llama-70B モデルで 55 トークン/秒を達成できます。 int8 量子化を提供します。 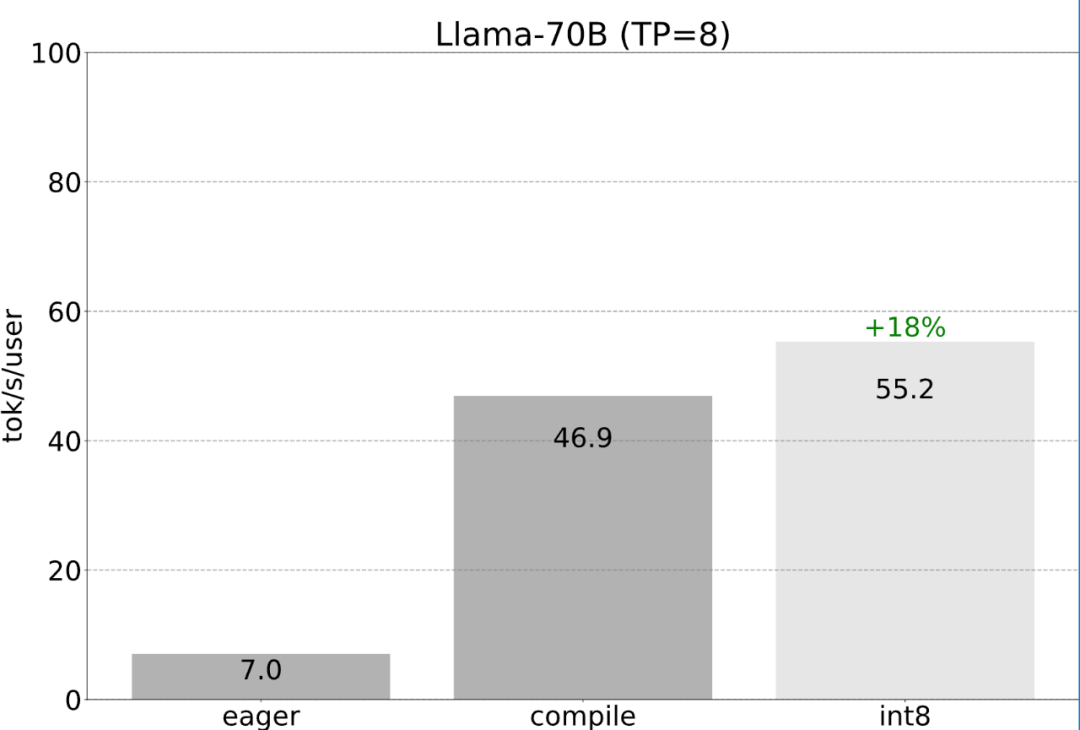




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



