

行き止まりのないオールラウンドなオープンソース、Xingbo チームの LLM360 は大規模モデルを真に透過的にします

オープンソース モデルはその旺盛な活力を示しており、その数が増加しているだけでなく、パフォーマンスもますます向上しています。チューリング賞受賞者のヤン・ルカン氏も「オープンソースの人工知能モデルは独自モデルを超えようとしている。」
独自モデルは技術的性能と革新性において、大きな可能性を示していると嘆いた。多くの機能を備えていますが、非オープンソースの特性により、LLM の開発が妨げられます。一部のオープンソース モデルは実践者や研究者に多様な選択肢を提供していますが、ほとんどは最終的なモデルの重みまたは推論コードのみを公開しており、技術レポートの範囲がトップレベルの設計と表面統計に限定されているものが増えています。このクローズドソース戦略は、オープンソース モデルの開発を制限するだけでなく、LLM 研究分野全体の進歩を大幅に妨げます。これは、これらのモデルがより包括的であり、トレーニング データも含めて徹底的に共有される必要があることを意味します。 、アルゴリズムの詳細、実装上の課題、パフォーマンス評価の詳細。
Cerebras、Petuum、MBZUAI の研究者は共同で LLM360 を提案しました。これは、トレーニング コードとデータ、モデル チェックポイント、中間結果など、LLM トレーニングに関連するすべてのものをコミュニティに提供することを提唱する、包括的なオープンソース LLM イニシアチブです。 LLM360 の目標は、LLM トレーニング プロセスを透明性があり、誰にとっても再現可能にし、それによってオープンで協力的な人工知能研究の開発を促進することです。

#論文アドレス: https://arxiv.org/pdf/2312.06550 .pdf
- プロジェクト Web ページ: https://www.llm360.ai/
- ブログ: https://www.llm360.ai/blog/introducing-llm360- fully-transparent-open-source-llms.html
- 研究者私たちは、LLM360 の設計原則と完全にオープンソースであるための理論的根拠に焦点を当てて、LLM360 のアーキテクチャを開発しました。これらは、データセット、コードと構成、モデルのチェックポイント、メトリクスなどの特定の詳細を含む、LLM360 フレームワークのコンポーネントを指定します。 LLM360 は、現在および将来のオープン ソース モデルの透明性の例を示します。
研究者らは、LLM360 のオープンソース フレームワークの下で最初から事前トレーニングされた 2 つの大規模な言語モデル、AMBER と CRYSTALCODER をリリースしました。 AMBER は、1.3T トークンに基づいて事前トレーニングされた 7B 英語モデルです。 CRYSTALCODER は、1.4T トークンに基づいて事前トレーニングされた 7B 英語およびコード言語モデルです。この記事では、研究者らがこれら 2 つのモデルの開発詳細、予備評価結果、観察、経験と教訓をまとめています。特に、リリース時点では、AMBER と CRYSTALCODER はトレーニング中にそれぞれ 360 個と 143 個のモデル チェックポイントを保存しました。
#それでは、記事の詳細を見ていきましょう
LLM360 のフレームワークは、LLM の事前トレーニング プロセス中に収集する必要があるデータとコードの標準を提供し、既存の作業をより適切に循環および共有できるようにします。地域社会・共同体 。これには主に次の部分が含まれます:
1. トレーニング データ セットとデータ処理コード
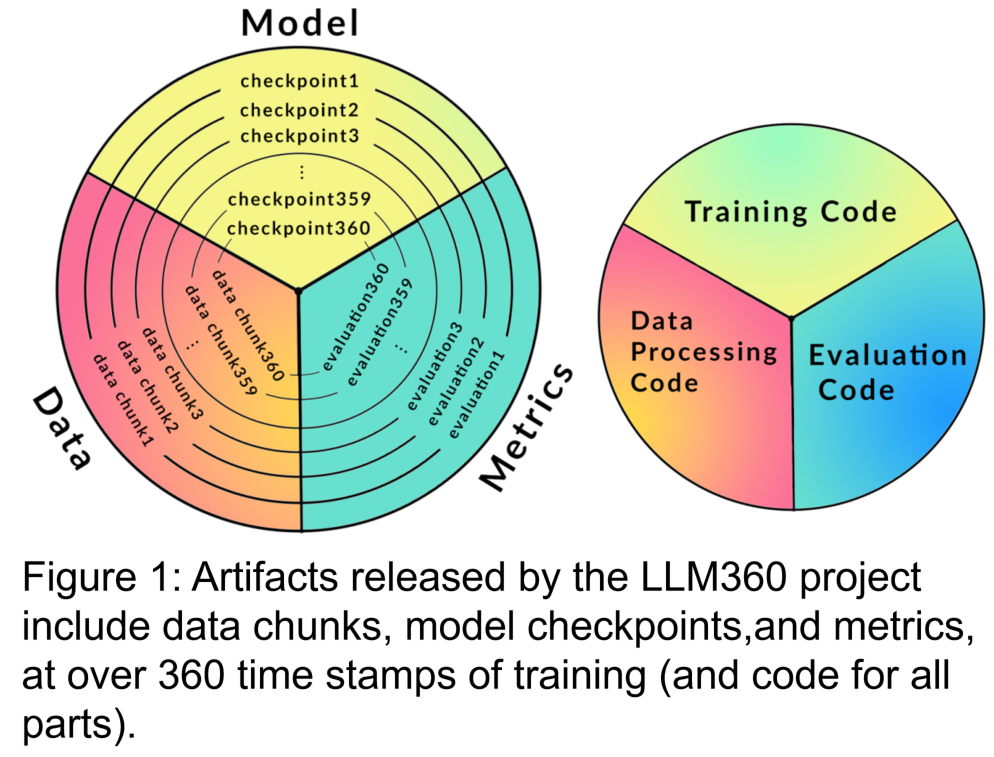
事前トレーニング データセットは、大規模な言語モデルのパフォーマンスにとって重要です。したがって、潜在的な行動上の問題とバイアスを評価するには、トレーニング前のデータセットを理解することが重要です。さらに、公開されている事前トレーニング データセットは、後で微調整してさまざまなドメインに適応させる際に、LLM のスケーラビリティを向上させるのに役立ちます。最近の研究では、繰り返しデータをトレーニングすると、モデルの最終的なパフォーマンスが過度に低下することが示されています。したがって、元の事前トレーニング データを公開すると、ダウンストリームを微調整したり、特定のドメインで事前トレーニングを継続したりするときに重複データの使用を回避できます。上記の理由に基づいて、LLM360 は大規模な言語モデルの生データ セットの開示を主張します。必要に応じて、データのフィルタリング、処理、トレーニング シーケンスの詳細も開示する必要があります。
書き直す必要がある内容は次のとおりです: 2. トレーニング コード、ハイパーパラメーター、構成
トレーニング コード、ハイパーパラメーター、および構成は、LLM トレーニングのパフォーマンスと品質に大きな影響を与えますが、常に公開されているわけではありません。 LLM360 では、研究者はすべてのトレーニング コード、トレーニング パラメーター、および事前トレーニング フレームワークのシステム構成をオープンソースにしています。
3. モデル チェックポイントは次のように書き換えられます: 3. モデル チェックポイント
定期的に保存されたモデル チェックポイントも非常に便利です。これらのチェックポイントは、トレーニング中の障害回復に重要であるだけでなく、トレーニング後の研究にも役立ちます。これらのチェックポイントにより、後続の研究者は、最初からトレーニングすることなく、複数の開始点からモデルのトレーニングを続けることができ、再現性が向上します。深層研究。
4. パフォーマンス指標
LLM のトレーニングには、多くの場合、数週間から数か月かかります。トレーニング中の進化の傾向は貴重な情報を提供する可能性があります。しかし、トレーニングの詳細なログや中間指標は、現時点ではトレーニングを経験した人しか入手できないため、LLM に関する包括的な研究の妨げとなっています。これらの統計には、検出が難しい重要な洞察が含まれていることがよくあります。これらの尺度の分散計算などの単純な分析でも、重要な発見が明らかになる可能性があります。たとえば、GLM 研究チームは、勾配仕様の動作を分析することで損失スパイクと NaN 損失を効果的に処理する勾配収縮アルゴリズムを提案しました。
Amber
AMBER は、LLM360 "ファミリー" の最初のメンバーであり、その微調整バージョンである AMBERCHAT および AMBERSAFE もリリースされています。

##書き直す必要があるもの: データとモデルの詳細
#表 2 は、1.26 個の T マーカーを含む AMBER の事前トレーニング データセットの詳細を示しています。これらには、データの前処理方法、形式、データ混合率に加え、アーキテクチャの詳細や AMBER モデルの特定の事前トレーニング ハイパーパラメーターが含まれます。詳細については、LLM360 コードベースのプロジェクト ホームページを参照してください。
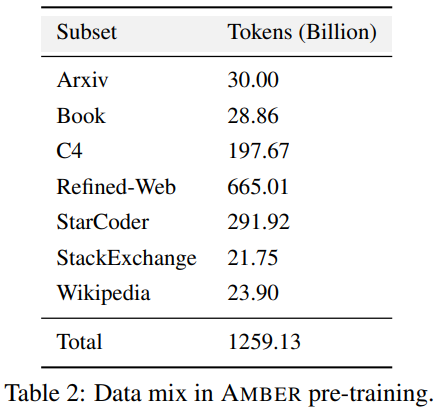 AMBER は、LLaMA 7B4 と同じモデル構造を採用しています。 , 表 3 LLM の詳細な構造構成をまとめたもの トレーニングハイパーパラメータ。 AMBER は AdamW オプティマイザを使用してトレーニングされ、ハイパーパラメータは β1=0.9、β2=0.95 です。さらに、研究者は AMBER のいくつかの微調整バージョン、AMBERCHAT と AMBERSAFE をリリースしました。 AMBERCHAT は、WizardLM の指導トレーニング データセットに基づいて微調整されています。パラメータの詳細については、原文を参照してください。
AMBER は、LLaMA 7B4 と同じモデル構造を採用しています。 , 表 3 LLM の詳細な構造構成をまとめたもの トレーニングハイパーパラメータ。 AMBER は AdamW オプティマイザを使用してトレーニングされ、ハイパーパラメータは β1=0.9、β2=0.95 です。さらに、研究者は AMBER のいくつかの微調整バージョン、AMBERCHAT と AMBERSAFE をリリースしました。 AMBERCHAT は、WizardLM の指導トレーニング データセットに基づいて微調整されています。パラメータの詳細については、原文を参照してください。
元の意味を変えないという目的を達成するには、内容を中国語に書き直す必要があります。以下は「実験と結果」を書き直したものです。 実験と結果分析の実施
CRYSTALCODER
LLM360「ビッグファミリー」の 2 番目のメンバーは、クリスタルコーダー。
CrystalCoder は、1.4 T トークンでトレーニングされた 7B 言語モデルで、コーディング機能と言語機能のバランスを実現します。以前のほとんどのコード LLM とは異なり、CrystalCoder はテキスト データとコード データを慎重に組み合わせてトレーニングされ、両方のドメインでの有用性を最大化します。 Code Llama 2 と比較して、CrystalCoder のコード データは、事前トレーニング プロセスの早い段階で導入されます。さらに、研究者らは、CrystalCoder を Python および Web プログラミング言語でトレーニングし、プログラミング アシスタントとしての有用性を向上させました。
モデル アーキテクチャを再構築する
CrystalCoder は、LLaMA 7B と非常によく似たアーキテクチャを採用し、最大の更新パラメーター Chemistry を追加します。 (ミューP)。この特定のパラメータ化に加えて、研究者らはいくつかの変更も加えました。さらに、CG-1 アーキテクチャは LayerNorm の効率的な計算をサポートしているため、研究者らは RMSNorm の代わりに LayerNorm も使用しました。
#元の意味を変えないという目的を達成するには、内容を中国語に書き直す必要があります。以下は「実験と結果」を書き直したものです。 実験と結果分析の実施
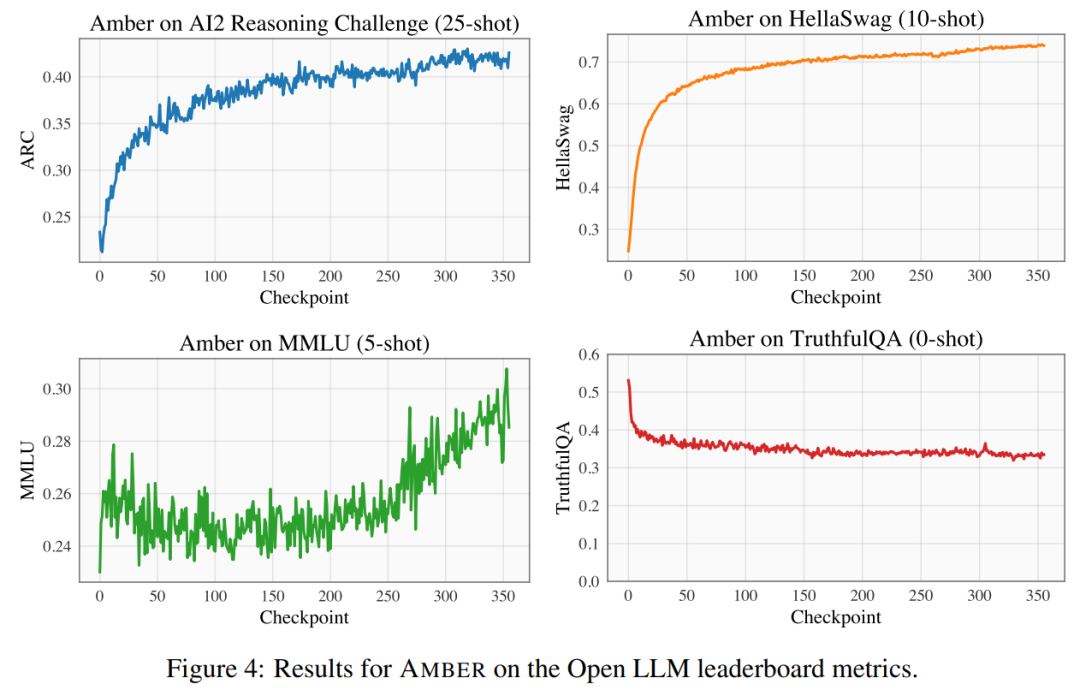
#Open LLM Leaderboard で、研究者は 4 つのベンチマーク データ セットと 1 つのコーディング ベンチマーク データ セットを含むモデルのベンチマーク テストを実施しました。図 6
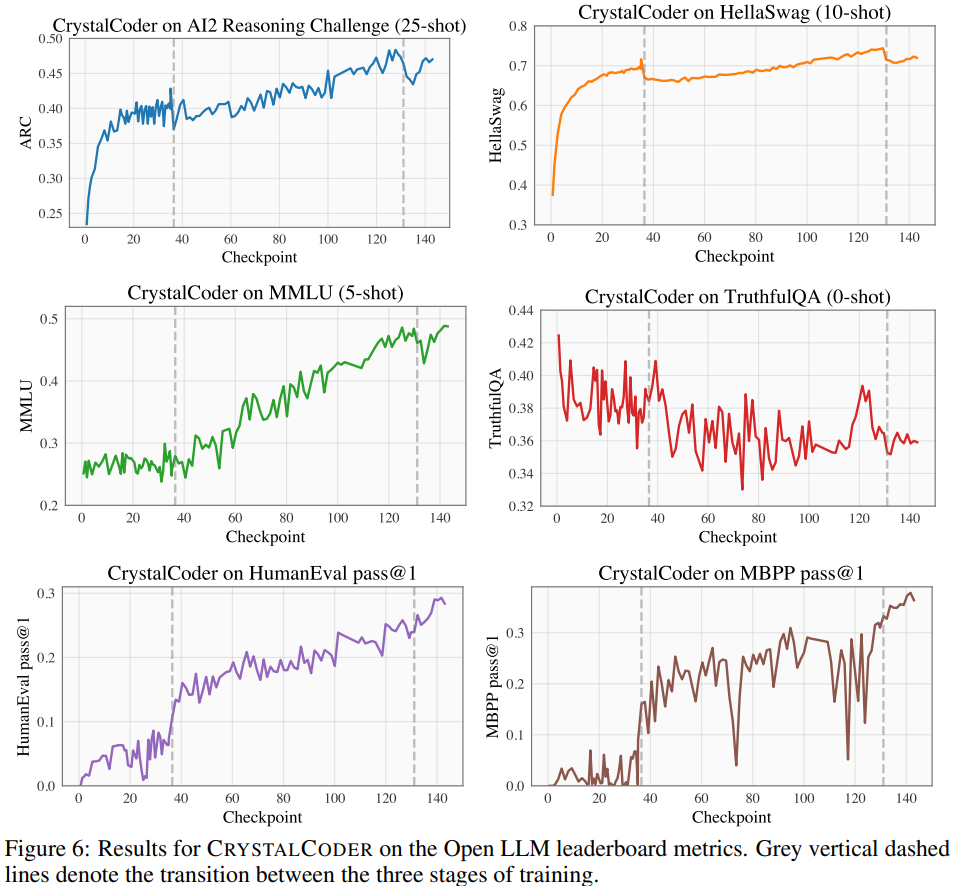
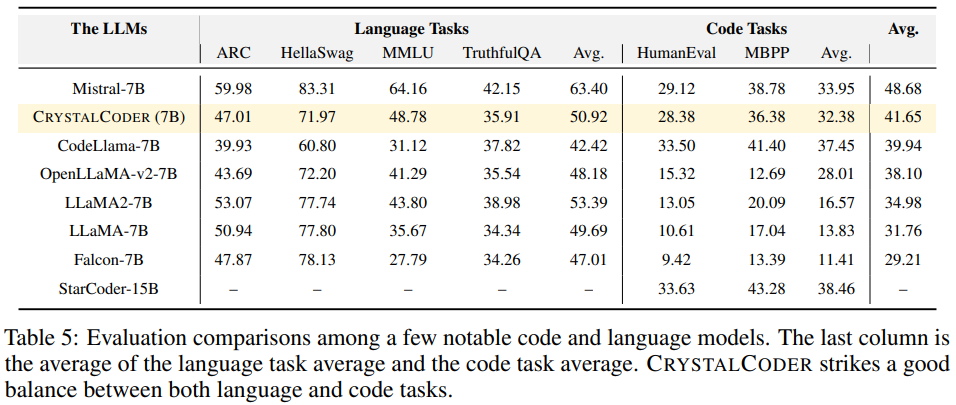
表 5 を参照すると、CrystalCoder が言語タスクとコード タスクの間で適切なバランスを実現していることがわかります。
ANALYSIS360
先行研究に基づいて、中間チェックポイントを分析することで詳細な研究を実行できます。モデル。研究者らは、LLM360 がコミュニティに有用な参考文献や研究リソースを提供することを期待しています。この目的を達成するために、彼らは、モデルの特性や下流の評価結果を含むモデルの動作の多面的な分析を整理したリポジトリである ANALYSIS360 プロジェクトの初期バージョンをリリースしました。一連のモデル チェックポイント 研究者らは、LLM におけるメモ化に関する予備研究を実施しました。最近の研究では、LLM がトレーニング データの大部分を記憶しており、このデータは適切なプロンプトで取得できることが示されています。このメモ化にはプライベート トレーニング データの漏洩という問題があるだけでなく、トレーニング データに繰り返しや特異性が含まれている場合、LLM のパフォーマンスが低下する可能性もあります。研究者らは、トレーニング段階全体にわたる暗記の包括的な分析を実行できるように、すべてのチェックポイントとデータを公開しました。長さ k の後に長さ l のトークンが続くプロンプトの精度。具体的なメモリスコアの設定については、元の記事を参照してください。
#選択した 10 個のチェックポイントの記憶スコアの分布を図 7
に示します。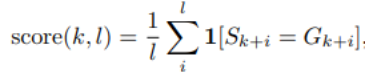
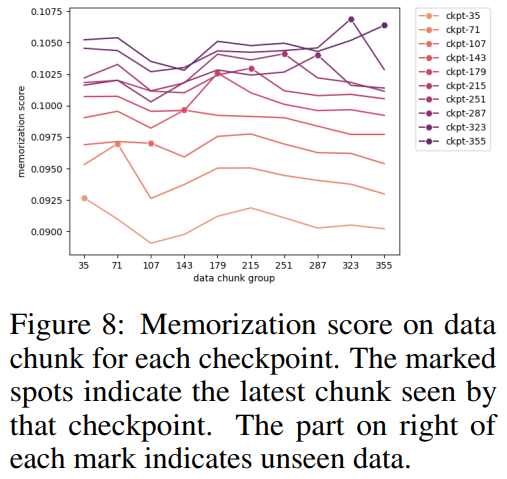
研究者らは、選択したチェックポイントに従ってデータ ブロックをグループ化し、各チェックポイントの各データ ブロックを図 8 にプロットしました。グループのメモ化されたスコア。彼らは、AMBER チェックポイントが以前のデータよりも最新のデータをよりよく記憶していることを発見しました。さらに、各データ ブロックでは、追加のトレーニング後にメモ化スコアがわずかに減少しますが、その後は増加し続けます。
 図 9 は、メモ化スコアのシーケンスと抽出可能な k 値の間の相関を示しています。チェックポイント間には強い相関関係があることがわかります。
図 9 は、メモ化スコアのシーケンスと抽出可能な k 値の間の相関を示しています。チェックポイント間には強い相関関係があることがわかります。
 概要
概要
研究者は、AMBER と CRYSTALCODER の観察といくつかの意味を要約しました。彼らは、事前トレーニングは計算集約的なタスクであり、多くの学術研究室や小規模な機関では余裕がないと述べています。彼らは、LLM360 が包括的な知識を提供し、ユーザーが自分で行うことなく LLM の事前トレーニング中に何が起こるかを理解できるようにしたいと考えています。
詳細については原文をご覧ください
以上が行き止まりのないオールラウンドなオープンソース、Xingbo チームの LLM360 は大規模モデルを真に透過的にしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
80
11
21
67
15
1378
52
80
11
21
67

 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
