

Douyin ダンスでは、実際の人間がカメラに映る必要はなく、写真だけで高品質のビデオを生成できます。偉そうなCTOもByteの新技術を体験している

###見て!今、あなたの目の前では 4 人の若い女性が熱いダンスを披露しています。

画像
にのみ依存しています。
実際の開始方法は次のとおりです: 
これはシンガポール国立大学と ByteDance からの最新情報です MagicAnimate
MagicAnimate
その機能は、違反の意味を持たずに、単純な式で要約できます: 写真
とアクション のセット = ビデオ . .
このテクノロジーの発表により、テクノロジー界は大騒ぎになり、多くのテクノロジー巨人やオタクが次々と参加しました
HuggingFace CTO
彼らは全員、自分のアバターでそれを試しました:
ちなみに、彼らはユーモラスな方法でジョークも言いました: 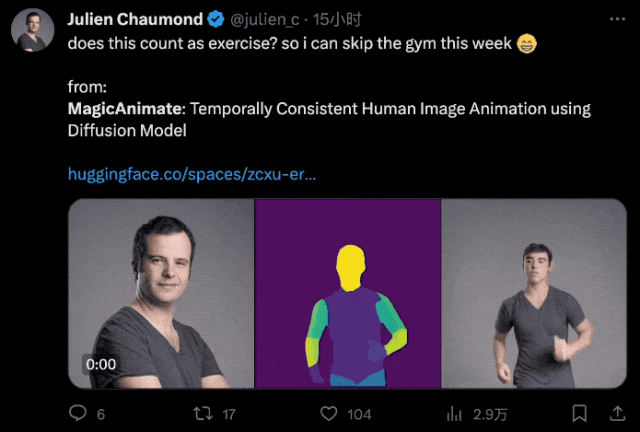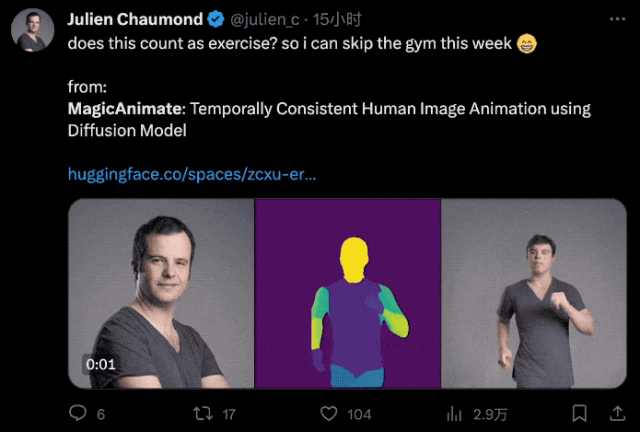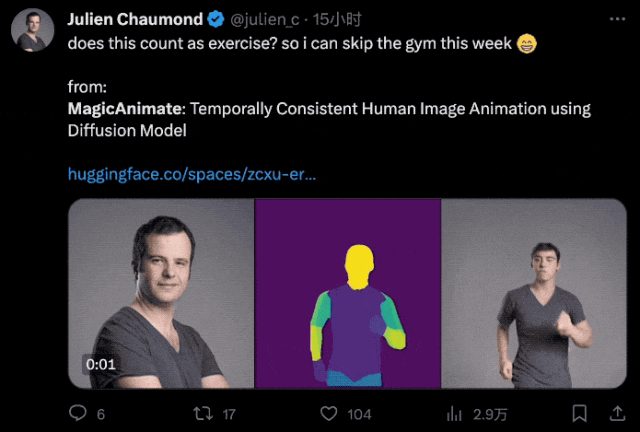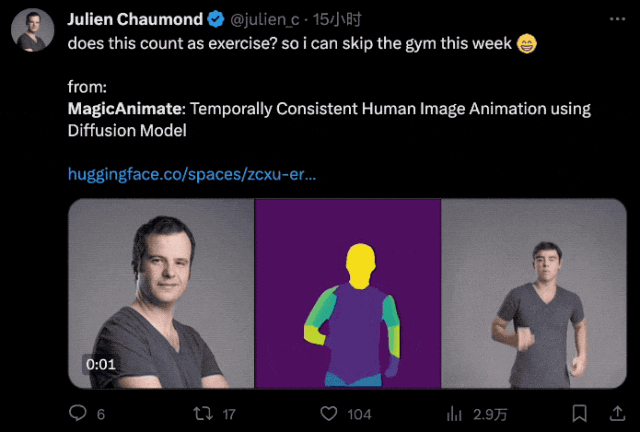
これはフィットネスとみなされますか?今週はジムを休んでもいいです。
新しくリリースされた
GTA6
(グランド セフト オート 6) のトレーラーのキャラクターで遊んでいる、時代に敏感なネチズンもいます。 一握り:
絵文字さえもネチズンの選択の対象になっています...
# #MagicAnimateテクノロジー界の注目をそれ自体に集中させたと言えるので、一部のネチズンは「
OpenAI は休んでもいい」と冗談を言いました。
#火事、本当に火事。 
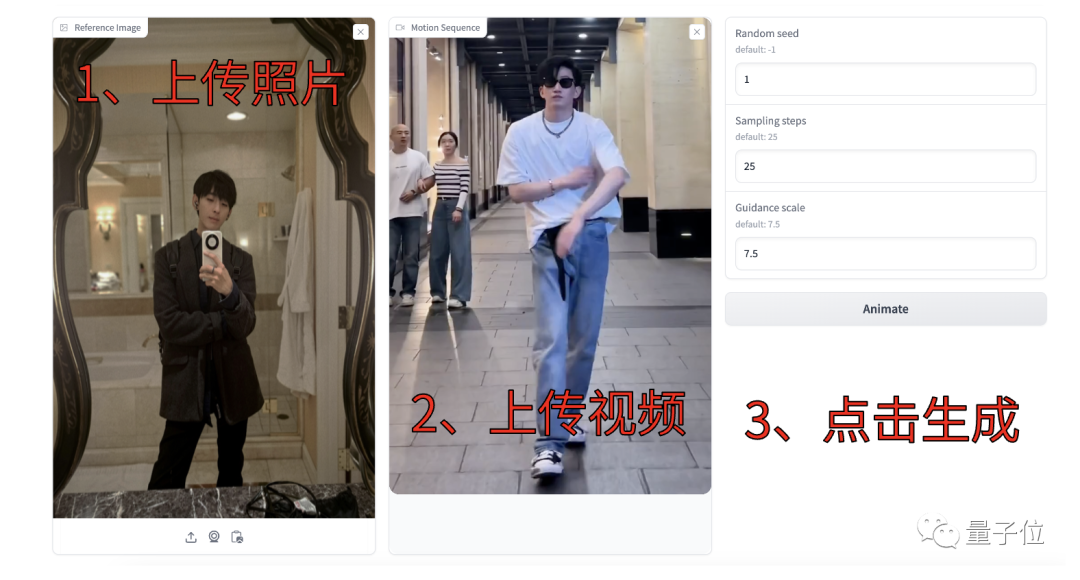
#操作は非常に簡単で、必要な手順は 3 つのステップだけです: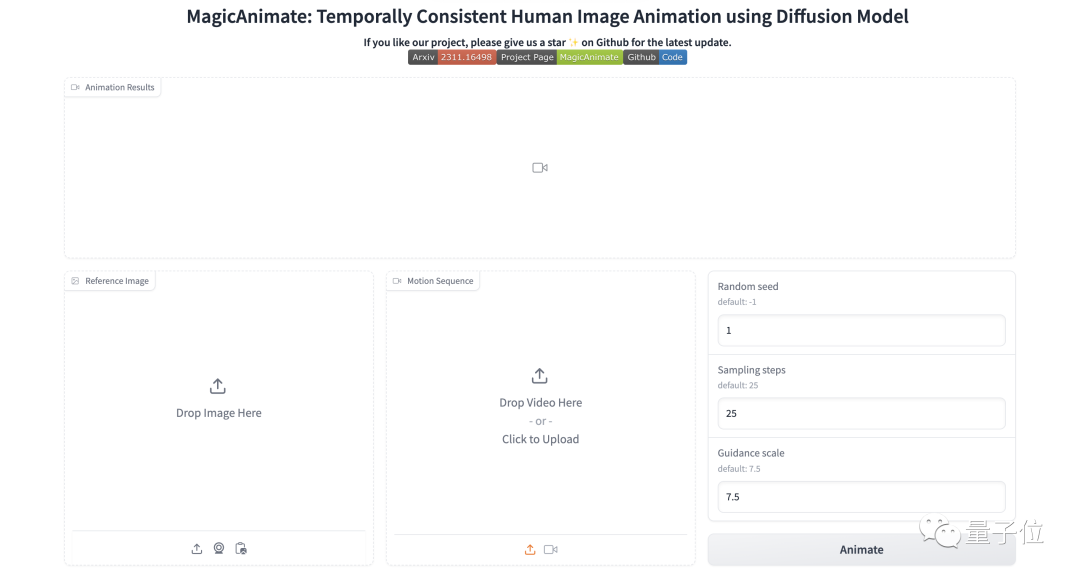
- キャラクターの静止写真をアップロードします
- 生成したいアクション デモ ビデオをアップロードします
- #パラメータを調整して「アニメーション」をクリックします
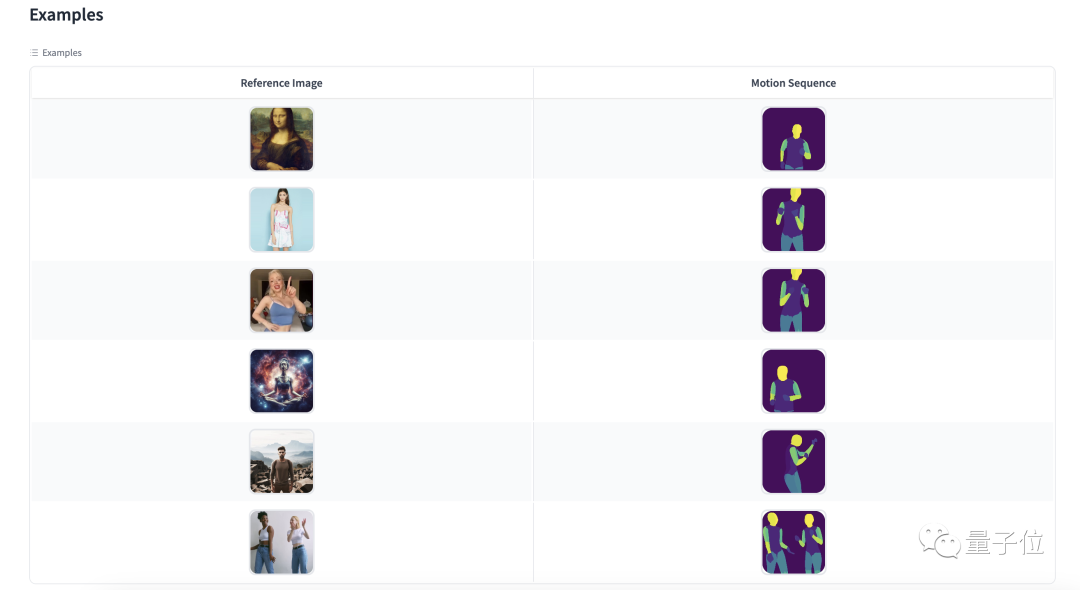
ページの下部にあるテンプレートを選択して体験することもできます:
......

(その通りです!記事執筆時点では、まだ結果を待っていません!)
さらに、MagicAnimate は GitHub でローカル体験メソッドも提供しています。興味のある友人はぜひ試してみてください~
## #どうやってするの?
全体として、MagicAnimate は
拡散モデル(拡散) に基づくフレームワークを採用しています。その目的は、時間的一貫性を強化し、参照画像の信頼性を維持することです。アニメーションの忠実度。
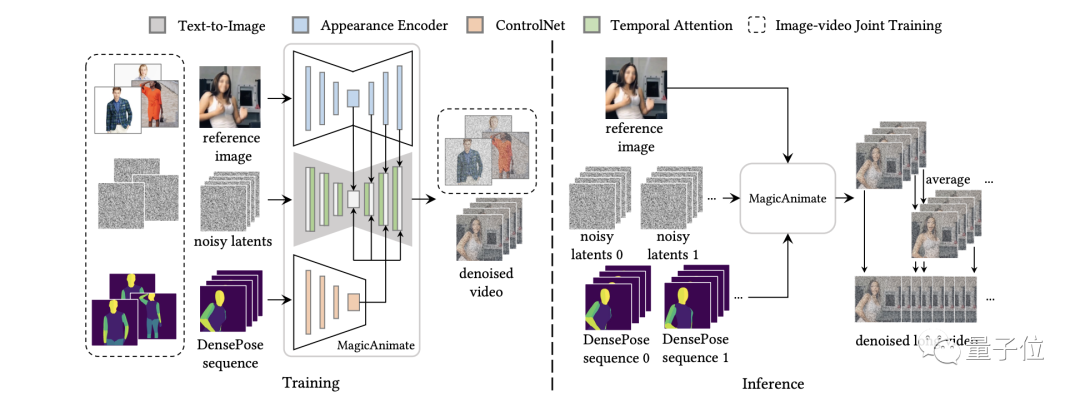 この目的を達成するために、チームはまず、時間情報をエンコードするための
この目的を達成するために、チームはまず、時間情報をエンコードするための
(時間的一貫性モデリング) を開発しました。 このモデルは、アニメーション内のフレーム間の時間的一貫性を確保するために、時間的注意モジュールを拡散ネットワークに追加することによって時間的情報をエンコードします。
第 2 に、フレーム間の外観の一貫性を維持するために、チームは新しい
Appearance Encoder(Appearance Encoder) を導入し、参照画像の複雑な詳細を保存しました。 このエンコーダは、CLIP エンコーディングを使用する以前の方法とは異なります。アニメーション制作をガイドするためにより高密度の視覚的特徴を抽出できるため、アイデンティティ、背景、服装などの情報をより適切に保存できます。
Basedこれら 2 つの革新的なテクノロジーに加えて、チームはさらに、長いビデオ アニメーションのスムーズな移行を促進するために、シンプルなビデオ フュージョン テクノロジー
(ビデオ フュージョン テクニック)を採用しました。 最後に、2 つのベンチマーク実験による検証の結果、MagicAnimate が以前の方法よりもはるかに効果的であることが結果からわかりました。
特に困難な TikTok ダンス データセットでは、MagicAnimate はビデオ保存において優れたパフォーマンスを発揮します。精度は最も強力なベースラインよりも 38% 以上高くなっています。
以下はチームによる定性的な比較です:
 そして、クロス ID の最先端のベースライン モデルと比較すると、結果は次のとおりです:
そして、クロス ID の最先端のベースライン モデルと比較すると、結果は次のとおりです:

One More Thing
MagicAnimate のようなプロジェクトは最近非常に人気があると言わざるを得ません
いいえ、その「デビュー」後は少し前です、Ali チームは、AnimateEveryone というプロジェクトもリリースしました。これも「画像」と「必要なアクション」のみが必要です:

その結果、一部のネチズンも疑問を提起しました:
論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2311.16498これは MagicAnimate と AnimateAnyone の間の戦争のようです。 誰が優れていますか? #####################どう思いますか?
以上がDouyin ダンスでは、実際の人間がカメラに映る必要はなく、写真だけで高品質のビデオを生成できます。偉そうなCTOもByteの新技術を体験しているの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7737
7737
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
不安定な暗号通貨市場では、投資家は人気のある通貨を超えた代替品を探しています。 Solana(Sol)、Cardano(ADA)、XRP、Dogecoin(DOGE)などのよく知られた暗号通貨も、市場の感情、規制の不確実性、スケーラビリティなどの課題に直面しています。ただし、新しい新興プロジェクトであるRexasFinance(RXS)が出現しています。それは有名人の効果や誇大広告に依存するのではなく、現実世界の資産(RWA)とブロックチェーン技術を組み合わせて投資家に革新的な投資方法を提供することに焦点を当てています。この戦略により、2025年の最も成功したプロジェクトの1つになることを望んでいます。Rexasfi
