

主要なモデル会社はすべてコンテキスト ウィンドウをロールアップしています。 Llama-1 の標準構成はまだ 2k でしたが、今では 100k 未満の会社は恥ずかしくて外に出られません。
しかし、Goose による 極端なテストでは、ほとんどの人が AI を誤って使用しており、AI の本来の力を発揮できていないことが判明しました。
#AI は本当に何十万もの単語から重要な事実を正確に見つけることができるのでしょうか? 色が赤くなるほど、AI はより多くの間違いを犯します。
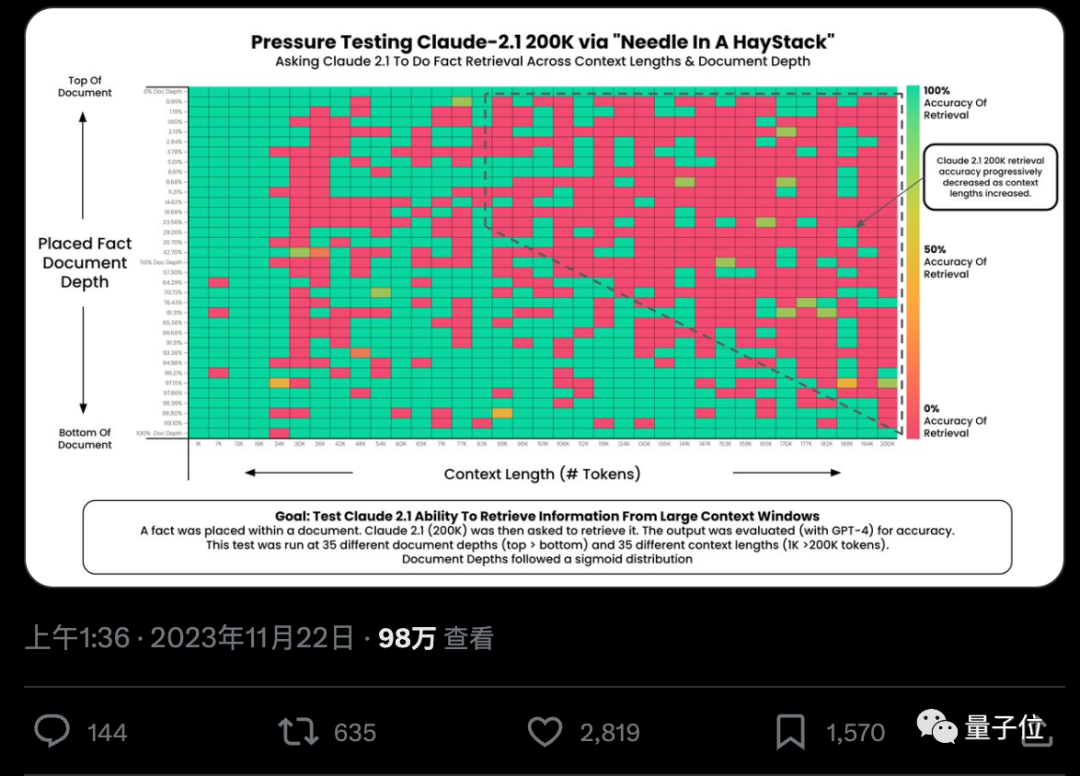
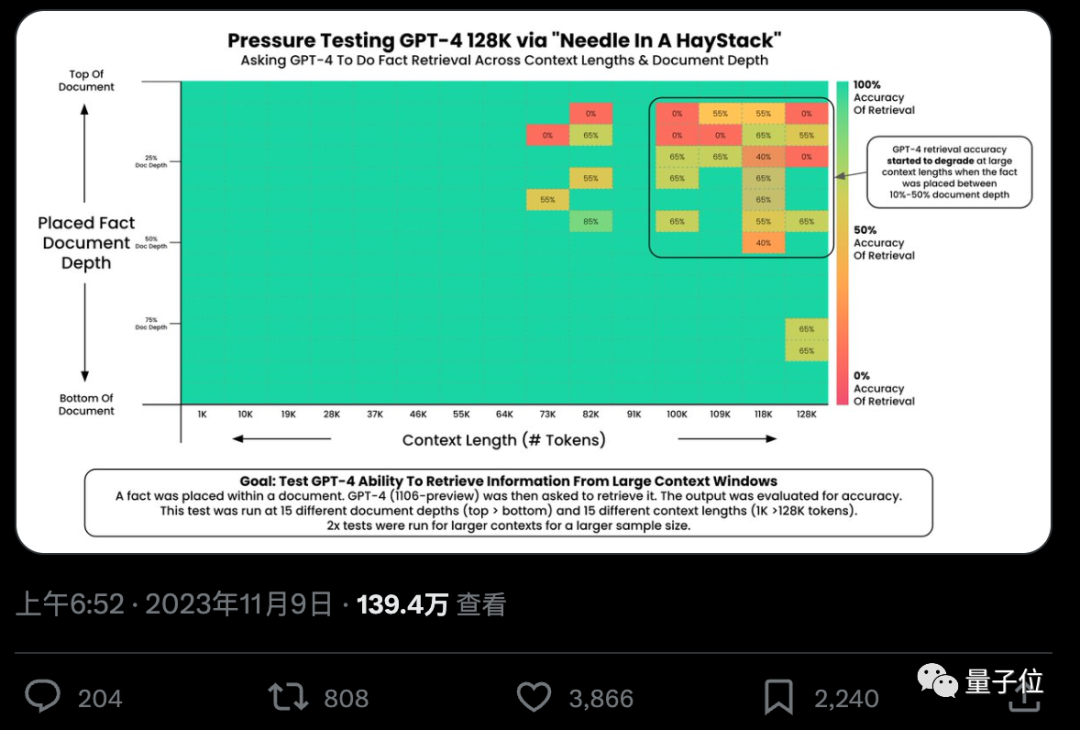
デフォルトでは、GPT-4-128k と最新リリースの Claude2.1-200k の結果は両方とも理想的ではありません。
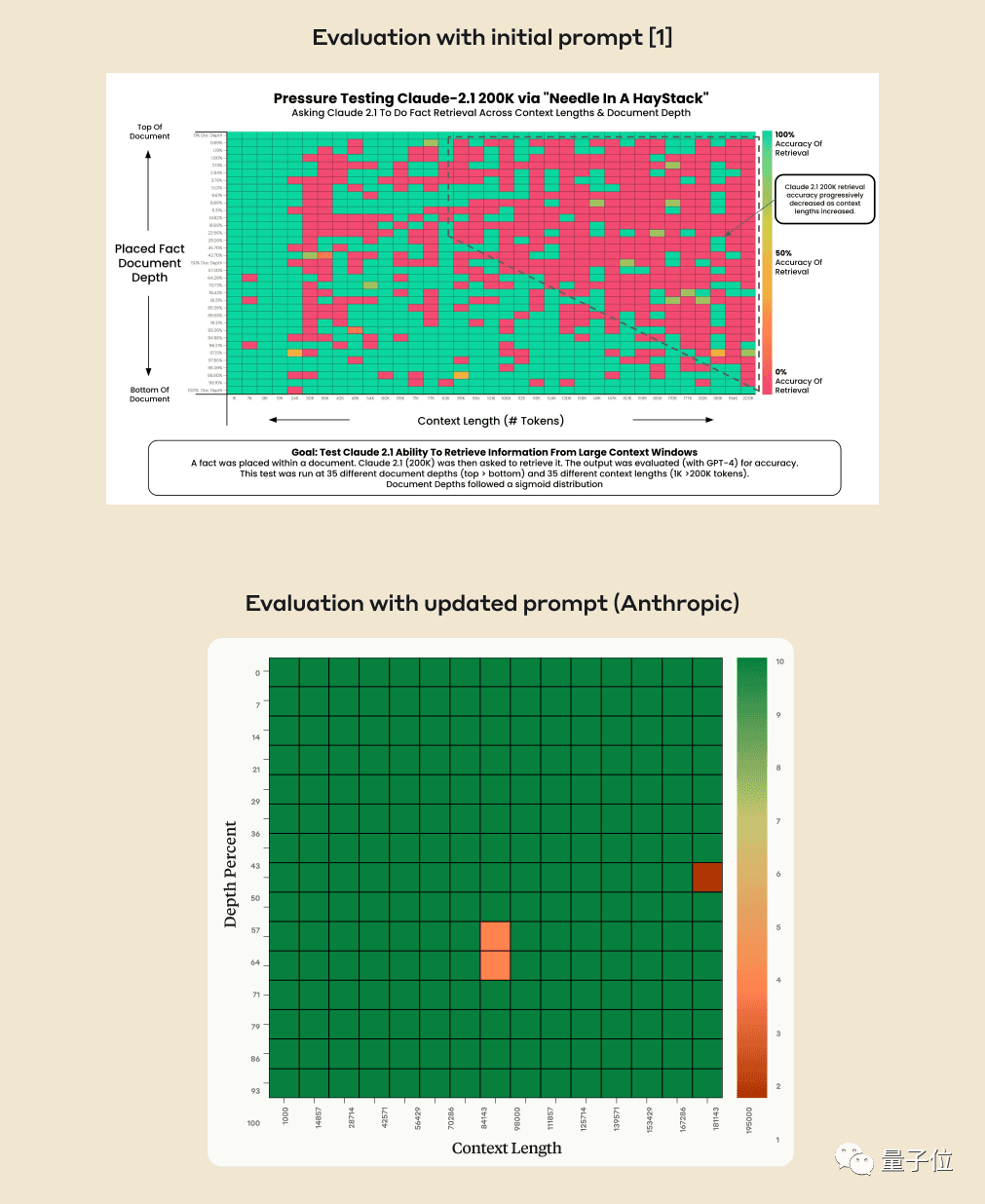
しかし、クロードのチームは状況を理解した後、スコアを 27% から 98% に直接改善する 1 つの文を追加するという、非常に単純な解決策を考え出しました。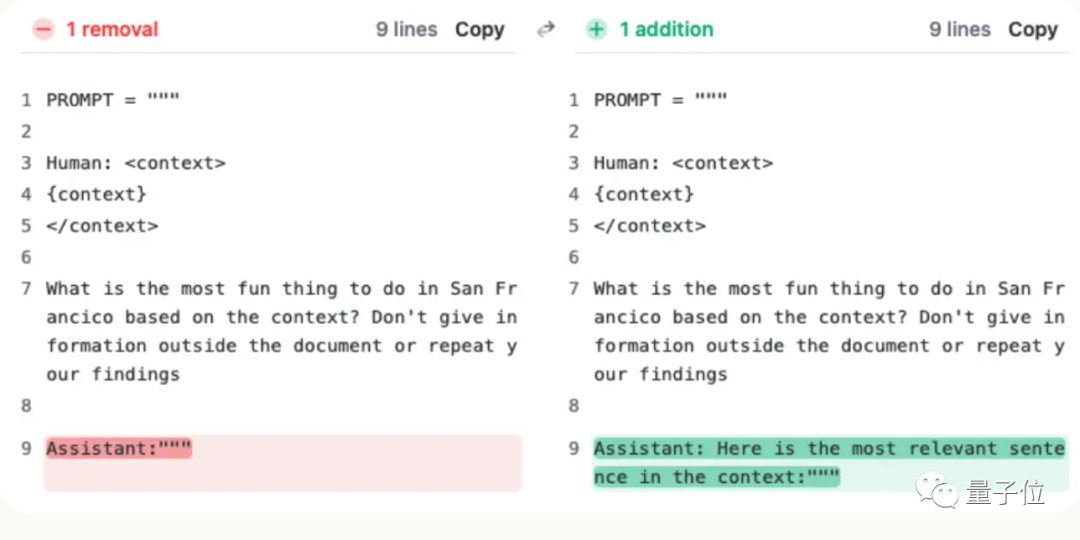
「文脈の中で最も関連性の高い文は次のとおりです:」
(文脈の中で最も関連性の高い文です:)
干し草の山に大きなモデルの針を入れよう このテストを行うために、著者のグレッグ・カムラットは少なくとも 150 ドルの私財を費やしました。 Claude2.1 をテストするとき、Anthropic は彼に無料のクレジット制限を提供しました。幸いなことに、彼は追加で 1,016 ドルを費やす必要はありませんでした。
 ##最終的に Langchain Evals ライブラリを使用して結果を評価しました
##最終的に Langchain Evals ライブラリを使用して結果を評価しました
AI 企業は独自の解決策を見つけました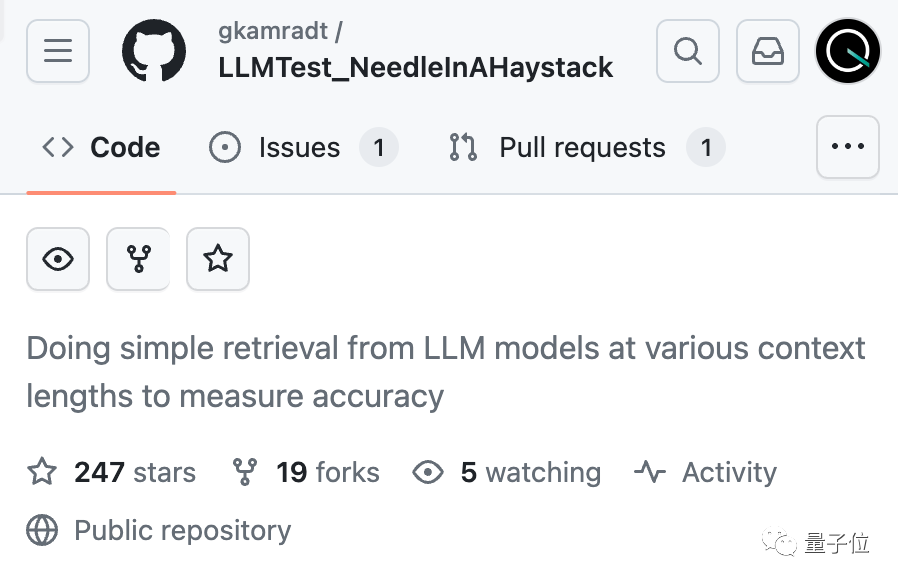
慎重な分析の結果、特に、その文が後から挿入され、記事全体とはほとんど関係のない場合、AI は文書内の 1 つの文に基づいて質問に答えることを嫌がるだけであることが判明しました。 つまり、この文章は記事の主題と関係がないとAIが判断した場合は、各文章を検索しないという方法がとられます
これが必要です AI を回避するにはいくつかのトリックを使用し、クロードに「文脈内で最も関連性の高い文は次のとおりです。」という文を回答の冒頭に追加するように依頼できます。 
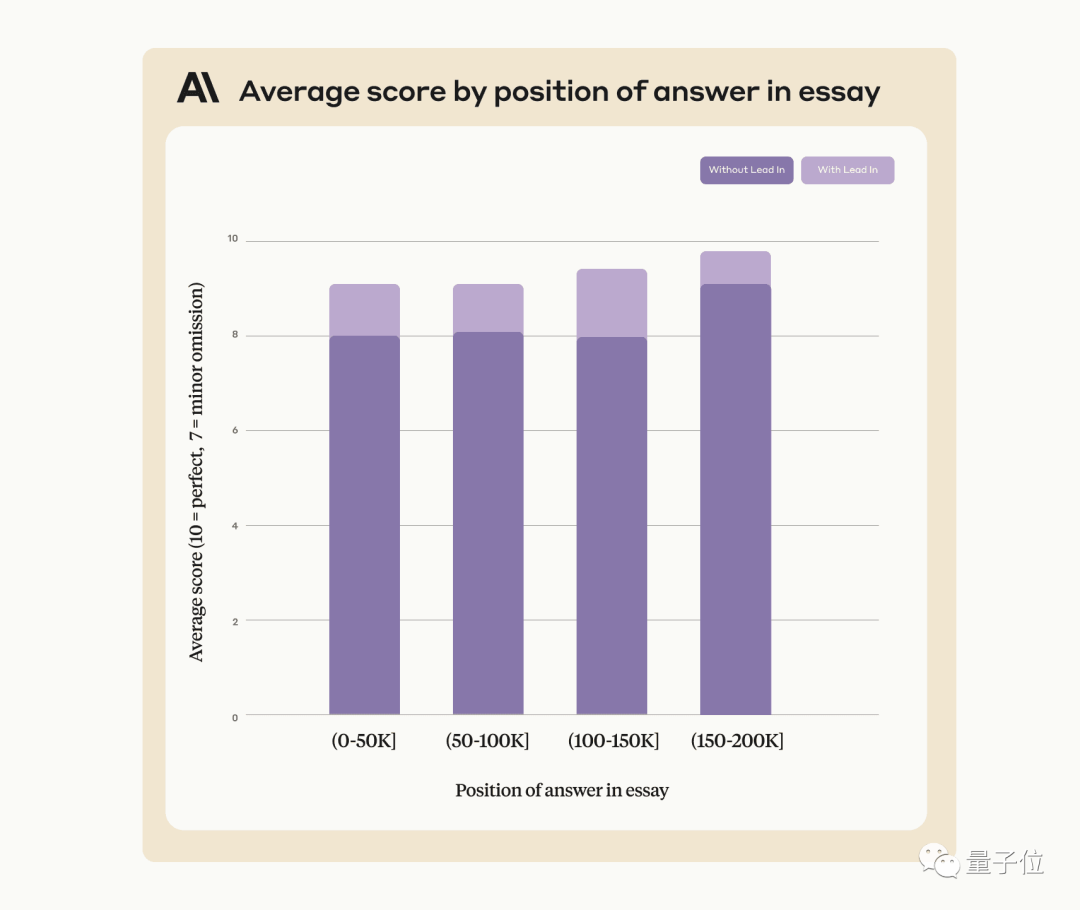 API を使用する場合、AI は特定の冒頭で答える必要がありますが、他の賢い使い方もできます
API を使用する場合、AI は特定の冒頭で答える必要がありますが、他の賢い使い方もできます
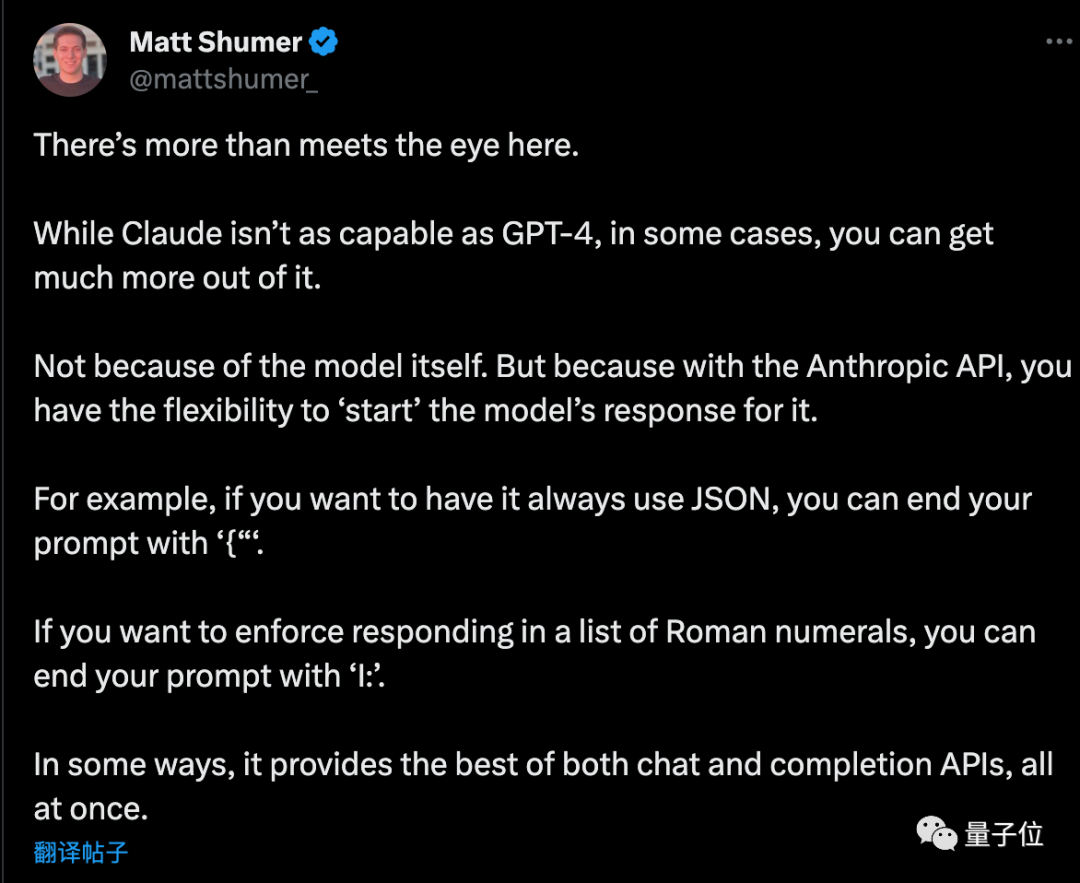
起業家のマット シューマー氏が計画を読んだ後、いくつか追加しましたチップ###
如果想让AI输出纯JSON格式,提示词的最后以“{”结尾。同理,如果想让AI列出罗马数字,提示词以“I:”结尾就行。
不过事情还没完……
国内的大型公司也开始注意到这项测试,并开始尝试他们自己的大型模型是否能够通过
同样拥有超长上下文的月之暗面Kimi大模型团队也测出了问题,但给出了不同的解决方案,也取得了很好的成绩。

在不改变原义的情况下,需要重写的内容是:这样做的好处是,修改用户提问提示比要求AI在回答中添加一句更容易实现,尤其是在不调用API而直接使用聊天机器人产品的情况下
我使用了一种新方法来帮助测试GPT-4和Claude2.1的月球背面,结果显示GPT-4取得了显著的改善,而Claude2.1只有轻微的改善
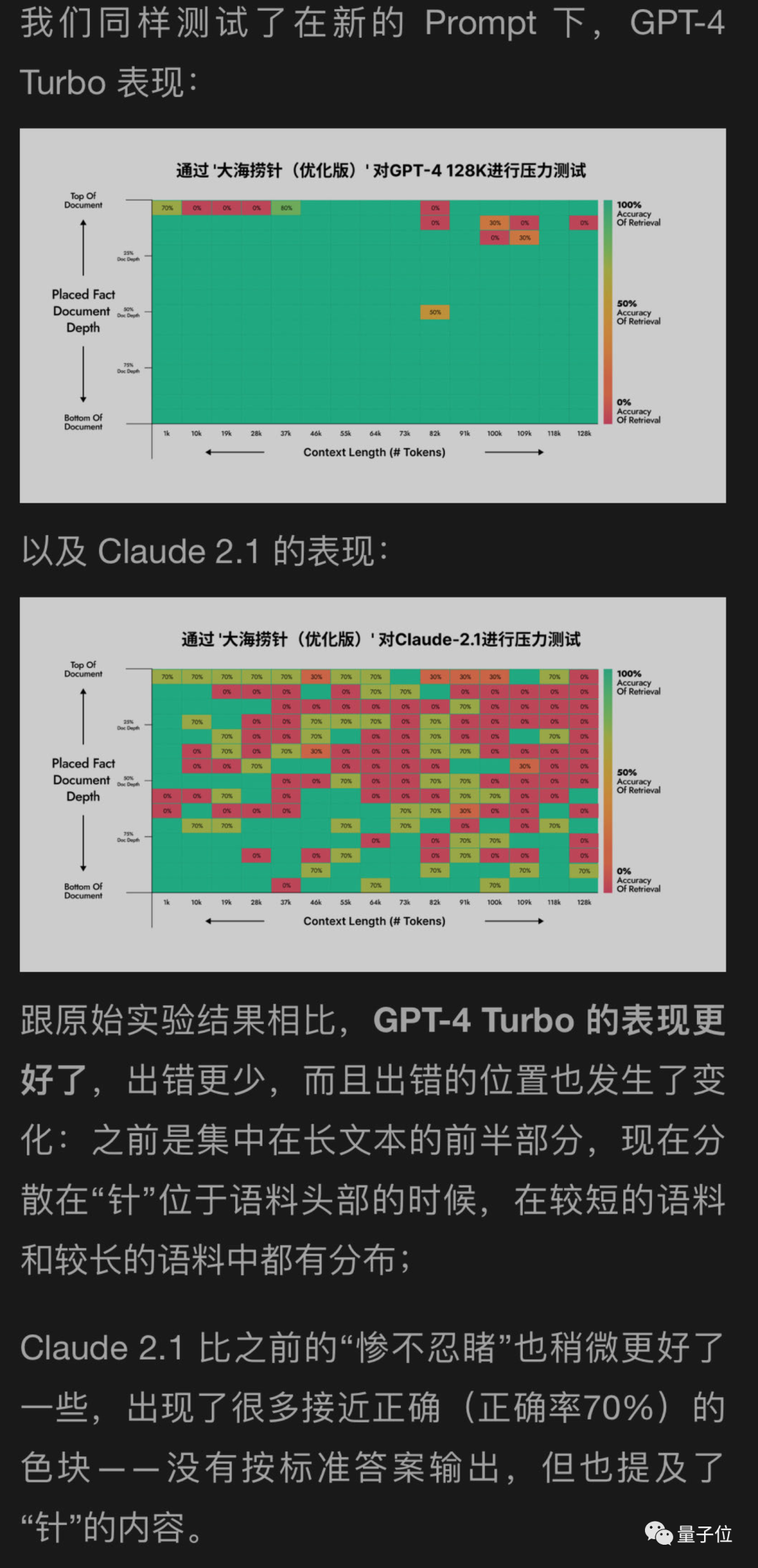
看来这个实验本身有一定局限性,Claude也是有自己的特殊性,可能与他们自己的对齐方式Constituional AI有关,需要用Anthropic自己提供的办法更好。
后来,月球背面的工程师继续进行了更多轮的实验,其中一个实验居然是……

糟糕,我变成测试数据了
以上がGPT-4 と Claude2.1 のロックを解除: 一文で、100,000 以上のコンテキスト大規模モデルの真の力を実感でき、スコアが 27 から 98 に増加します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



