

NVIDIA が AMD の顔を平手打ち: ソフトウェア サポートにより、H100 の AI パフォーマンスは MI300X よりも 47% 高速です。


12 月 14 日のニュースによると、AMD は今月初めに最も強力な AI チップ Instinct MI300X を発売し、同社の 8 GPU サーバーの AI パフォーマンスは Nvidia H100 8 GPU より 60% 向上しました。この点に関して、NVIDIA は最近、H100 と MI300X の間の一連の最新のパフォーマンス比較データをリリースしました。これは、H100 が適切なソフトウェアを使用して MI300X よりも高速な AI パフォーマンスを提供する方法を示しています。
AMD が以前にリリースしたデータによると、MI300X の FP8/FP16 パフォーマンスは NVIDIA H100 の 1.3 倍に達し、Llama 2 70B および FlashAttendant 2 モデルの実行速度は H100 より 20% 高速です。 8v8 サーバーでは、Llama 2 70B モデルを実行している場合、MI300X は H100 より 40% 高速であり、Bloom 176B モデルを実行している場合、MI300X は H100 より 60% 高速です。
ただし、MI300X と NVIDIA H100 を比較する場合、AMD は最新の ROCm 6.0 スイート (スパーシティなどを含む FP16、Bf16、FP8 などの最新のコンピューティング フォーマットをサポートできる) の最適化ライブラリを使用していることに注意してください。これらの数字を取得します。対照的に、NVIDIA H100 は、NVIDIA の TensorRT-LLM などの最適化ソフトウェアを使用せずにはテストされませんでした。
NVIDIA H100 テストに関する AMD の暗黙の声明は、vLLM v.02.2.2 推論ソフトウェアと NVIDIA DGX H100 システムを使用した Llama 2 70B クエリの入力シーケンス長が 2048、出力シーケンス長が 128 であることを示しています
NVIDIA が DGX H100 (8 個の NVIDIA H100 Tensor コア GPU、80 GB HBM3 を搭載) に対してリリースした最新のテスト結果は、パブリック NVIDIA TensorRT LLM ソフトウェアが使用されており、その v0.5.0 がバッチ 1 テストに使用されていることを示しています。 、レイテンシーしきい値測定用の v0.6.1。テスト ワークロードの詳細は、以前に実施された AMD テストと同じです
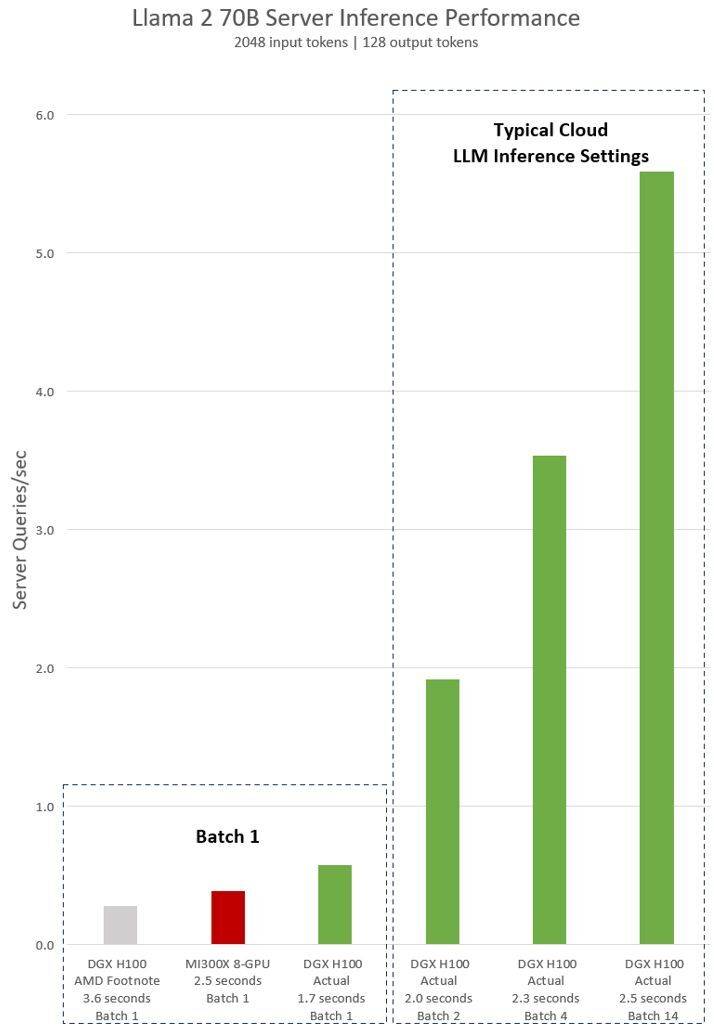
結果によると、最適化されたソフトウェアを使用した後、NVIDIA DGX H100 サーバーのパフォーマンスは 2 倍以上向上し、AMD が発表した MI300X 8-GPU サーバーよりも 47% 高速になりました。
DGX H100 は、1 つの推論タスクを 1.7 秒で処理できます。応答時間とデータセンターのスループットを最適化するために、クラウド サービスは特定のサービスに対して固定の応答時間を設定します。これにより、複数の推論リクエストをより大きな「バッチ」に結合できるため、サーバー上の 1 秒あたりの推論の総数が増加します。 MLPerf などの業界標準ベンチマークでも、この固定応答時間メトリクスを使用してパフォーマンスを測定します応答時間のわずかなトレードオフにより、サーバーがリアルタイムで処理できる推論リクエストの数に不確実性が生じる可能性があります。固定の 2.5 秒の応答時間バジェットを使用すると、NVIDIA DGX H100 サーバーは 1 秒あたり 5 件を超える Llama 2 70B 推論を処理できますが、Batch-1 は 1 秒あたり 1 件未満しか処理できません。
明らかに、Nvidia がこれらの新しいベンチマークを使用するのは比較的公平です。結局のところ、AMD も最適化されたソフトウェアを使用して GPU のパフォーマンスを評価しているため、Nvidia H100 をテストするときに同じことを行わないのはなぜでしょうか?
NVIDIA のソフトウェア スタックは CUDA エコシステムを中心に展開しており、長年の努力と開発を経て、人工知能市場で非常に強力な地位を築いていますが、一方で AMD の ROCm 6.0 は新しく、まだテストされていないことを知っておく必要があります。現実世界のシナリオ。
AMD が以前に開示した情報によると、AMD は Microsoft や Meta などの大企業との契約の大部分に達しており、これらの企業は同社の MI300X GPU を Nvidia の H100 ソリューションの代替品と見なしています。
AMD の最新の Instinct MI300X は、2024 年上半期に大量に出荷される予定です。ただし、NVIDIA のより強力な H200 GPU もそれまでに出荷され、NVIDIA は新世代の Blackwell B100 も 2024 年上半期に発売される予定です。 2024年の半分。さらに、インテルは新世代 AI チップ Gaudi 3 も発売します。次に、人工知能分野での競争はさらに激化しそうだ。
編集者: Xinzhixun-Rurounijian
以上がNVIDIA が AMD の顔を平手打ち: ソフトウェア サポートにより、H100 の AI パフォーマンスは MI300X よりも 47% 高速です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 OneXGPU 2 の AMD Radeon RX 7800M は Nvidia RTX 4070 ラップトップ GPU を上回ります
Sep 09, 2024 am 06:35 AM
OneXGPU 2 の AMD Radeon RX 7800M は Nvidia RTX 4070 ラップトップ GPU を上回ります
Sep 09, 2024 am 06:35 AM
OneXGPU 2 は、AMD ですらまだ発表していない GPU である Radeon RX 7800M を搭載した最初の eGPU です。外部グラフィックス カード ソリューションのメーカーである One-Netbook によって明らかにされたように、新しい AMD GPU は RDNA 3 アーキテクチャに基づいており、Navi
 ASUS、AMD Ryzen 9 8945H と興味深いお香ディスペンサーを搭載した Adol Book 14 Air を発表
Aug 01, 2024 am 11:12 AM
ASUS、AMD Ryzen 9 8945H と興味深いお香ディスペンサーを搭載した Adol Book 14 Air を発表
Aug 01, 2024 am 11:12 AM
ASUSはすでに、Zenbook 14 OLED(Amazonで現在1,079.99ドル)を含むさまざまな14インチラップトップを提供しています。このたび、表面的には典型的な 14 インチのラップトップのように見える Adol Book 14 Air を導入することが決定しました。ただし、目立たないメタ
 Ryzen AI ソフトウェアが新しい Strix Halo および Kraken Point AMD Ryzen プロセッサをサポート
Aug 01, 2024 am 06:39 AM
Ryzen AI ソフトウェアが新しい Strix Halo および Kraken Point AMD Ryzen プロセッサをサポート
Aug 01, 2024 am 06:39 AM
AMD Strix Point ラップトップは市場に登場したばかりで、次世代の Strix Halo プロセッサは来年中にリリースされる予定です。ただし、同社はすでに Strix Halo および Krackan Point APU のサポートを Ryzen AI ソフトウェアに追加しています。
 ハンドヘルドコンソール用AMD Z2 Extremeチップが2025年初頭の発売に向けて発表
Sep 07, 2024 am 06:38 AM
ハンドヘルドコンソール用AMD Z2 Extremeチップが2025年初頭の発売に向けて発表
Sep 07, 2024 am 06:38 AM
AMDはRyzen Z1 Extreme(およびその非Extremeバージョン)をハンドヘルドゲーム機向けにカスタマイズしたにもかかわらず、このチップが主流のハンドヘルド機に搭載されたのはAsus ROG Ally(Amazonで現在569ドル)とLenovo Legion Go(3つ)の2つだけでした。 Rを数えると
 AMD、数百万台のRyzenおよびEPYCプロセッサに影響する「Sinkclose」の重大度の高い脆弱性を発表
Aug 10, 2024 pm 10:31 PM
AMD、数百万台のRyzenおよびEPYCプロセッサに影響する「Sinkclose」の重大度の高い脆弱性を発表
Aug 10, 2024 pm 10:31 PM
8月10日の当サイトのニュースによると、AMDは一部のEPYCおよびRyzenプロセッサにコード「CVE-2023-31315」の「Sinkclose」と呼ばれる新たな脆弱性が存在し、世界中の数百万のAMDユーザーが関与する可能性があることを正式に確認したとのこと。では、シンククローズとは何でしょうか? 『WIRED』の報道によると、この脆弱性により侵入者は「システム管理モード(SMM)」で悪意のあるコードを実行することが可能になるという。伝えられるところによると、侵入者はブートキットと呼ばれるマルウェアの一種を使用して相手のシステムを制御する可能性があり、このマルウェアはウイルス対策ソフトウェアでは検出できません。このサイトからの注: システム管理モード (SMM) は、高度な電源管理とオペレーティング システムに依存しない機能を実現するために設計された特別な CPU 動作モードです。
 Ryzen AI 9 HX 370 を搭載した初の Minisforum ミニ PC、高額で発売されると噂
Sep 29, 2024 am 06:05 AM
Ryzen AI 9 HX 370 を搭載した初の Minisforum ミニ PC、高額で発売されると噂
Sep 29, 2024 am 06:05 AM
Aoostar は Strix Point mini PC を最初に発表した企業の 1 つであり、その後、Beelink が 999 ドルという高騰する開始価格で SER9 を発売しました。 Minisforum は、EliteMini AI370 をからかうことでパーティーに参加しました。その名前が示すように、これは会社の
 Beelink SER9: Radeon 890M iGPU を搭載したコンパクト AMD Zen 5 ミニ PC が発表されましたが、eGPU オプションは限られていました
Sep 12, 2024 pm 12:16 PM
Beelink SER9: Radeon 890M iGPU を搭載したコンパクト AMD Zen 5 ミニ PC が発表されましたが、eGPU オプションは限られていました
Sep 12, 2024 pm 12:16 PM
Beelink は、新しいミニ PC と付属のアクセサリを猛烈な勢いで発表し続けています。要約すると、EQi12、EQR6、EX eGPU ドックをリリースしてから 1 か月強が経過しました。現在、同社は AMD の新しい Strix に注目しています。
 取引 | 120Hz OLED、64GB RAM、AMD Ryzen 7 Pro を搭載した Lenovo ThinkPad P14s Gen 5 が現在 60% オフです
Sep 07, 2024 am 06:31 AM
取引 | 120Hz OLED、64GB RAM、AMD Ryzen 7 Pro を搭載した Lenovo ThinkPad P14s Gen 5 が現在 60% オフです
Sep 07, 2024 am 06:31 AM
最近、多くの学生が学校に戻り、古いラップトップがもう役に立たないことに気づいている人もいるかもしれません。大学生の中には、ゴージャスな OLED スクリーンを備えたハイエンドのビジネス ノートブックを市場に出す人もいるかもしれません。
