Google の Gemini の重さはどれくらいですか? OpenAI の GPT モデルと比較するとどうですか?この CMU 論文には明確な測定結果があります
少し前に、Google は OpenAI GPT モデルの競合製品である Gemini をリリースしました。この大型モデルには、Ultra (最も高性能)、Pro、Nano の 3 つのバージョンがあります。研究チームが発表したテスト結果によると、Ultra バージョンは多くのタスクで GPT4 を上回り、Pro バージョンは GPT-3.5 と同等であることが示されています。 これらの比較結果は大規模な言語モデル研究にとって非常に重要ですが、正確な評価の詳細とモデルの予測はまだ公開されていないため、再現性やモデルの予測が制限されています。テスト結果の再現性が検出されても、その隠された詳細をさらに分析することは困難です。 Gemini の真の強みを理解するために、カーネギー メロン大学と BerriAI の研究者は、モデルの言語理解と生成機能の詳細な調査を実施しました。 彼らは、Gemini Pro、GPT 3.5 Turbo、GPT 4 Turbo、Mixtral のテキスト理解と生成機能を 10 個のデータ セットでテストしました。具体的には、MMLU で知識ベースの質問に答えるモデルの能力、BigBenchHard でモデルの推論能力、GSM8K などのデータセットの数学的質問に答えるモデルの能力、および次のようなデータセットの数学的質問に答えるモデルの能力をテストしました。 FLORES. モデルの翻訳能力、モデルのコード生成能力は HumanEval などのデータセットでテストされ、指示に従うエージェントとしてのモデルの能力は WebArena でテストされました。 以下の表 1 は、比較の主な結果を示しています。全体として、論文の公開日の時点で、Gemini Pro はすべてのタスクの精度において OpenAI GPT 3.5 Turbo に近いですが、それでもわずかに劣っています。さらに、Gemini と GPT のパフォーマンスが、オープンソースの競合モデル Mixtral よりも優れていることもわかりました。 この論文では、著者が各タスクの詳細な説明と分析を提供しています。すべての結果と再現可能なコードは次の場所にあります: https://github.com/neulab/gemini-benchmarkペーパーリンク: https://arxiv.org/ pdf /2312.11444.pdf##著者は Gemini Pro、GPT Four モデルを選択しました、3.5 Turbo、GPT 4 Turbo、Mixtral をテスト対象として使用しました。
以前の研究での評価時の実験設定の違いにより、公平なテストを保証するために、著者はまったく同じプロンプトの言葉と評価を使用して実験を再実行しました。プロトコル。ほとんどの評価では、標準リポジトリからのプロンプトワードとルーブリックが使用されました。これらのテスト リソースは、モデル リリースや評価ツール Eleuther などに付属するデータ セットから取得されます。その中で、プロンプトワードには通常、クエリ、入力、少数の例、思考連鎖推論などが含まれます。いくつかの特別な評価では、著者らは標準的な慣行に若干の調整が必要であることを発見しました。バイアスの調整は対応するコード リポジトリで行われています。元の論文を参照してください。
#この研究の目標は次のとおりです:
#1. 再現可能なコードと完全に透過的な結果を通じて、 OpenAI GPT モデルと Google Gemini モデルの機能のサードパーティによる客観的な比較を提供します。
2. 評価結果を詳しく調査し、2 つのモデルがどの分野でより顕著に機能するかを分析します。
#知識ベースの QA
著者は MMLU からデータを取得しました。 STEM、人文科学、社会科学などのさまざまなトピックをカバーする、知識ベースの多肢選択式の質問と回答の 57 問のタスク。 MMLU には合計 14,042 のテスト サンプルがあり、大規模な言語モデルの知識能力の全体的な評価を提供するために広く使用されています。
著者は、MMLU における 4 人の被験者の全体的なパフォーマンス (下図を参照)、サブタスクのパフォーマンス、および出力の長さの影響を比較および分析しました。パフォーマンスについて。 図 1: 5 つのサンプル プロンプトと思考チェーン プロンプトを使用した、MMLU 上の各モデルの全体的な精度。
図からわかるように、Gemini Pro の精度は GPT 3.5 Turbo よりも低く、GPT 4 Turbo よりもはるかに低くなります。思考連鎖プロンプトを使用する場合、各モデルのパフォーマンスにほとんど差はありません。著者らは、これは MMLU が主に知識ベースの質問と回答のタスクをキャプチャしており、より強力な推論指向のプロンプトからはあまり恩恵を受けない可能性があるためであると推測しています。 MMLU のすべての質問は、A ~ D の 4 つの回答が順番に並べられた多肢選択の質問であることに注意してください。以下のグラフは、各モデルが選択した各回答選択肢の割合を示しています。この図から、双子座の回答分布は最後の選択肢 D を選択する方向に非常に偏っていることがわかります。これは、GPT のバージョンによって得られるよりバランスの取れた結果とは対照的です。これは、ジェミニが多肢選択式の質問に関連する広範な指導調整を受けておらず、その結果、モデルの回答ランキングに偏りが生じていることを示している可能性があります。 図 2: テストされたモデルによって予測された多肢選択式質問に対する回答の割合。
次の図は、MMLU テスト セットのサブタスクにおけるテストされたモデルのパフォーマンスを示しています。 Gemini Pro は、GPT 3.5 と比較して、ほとんどのタスクのパフォーマンスが低くなります。思考連鎖プロンプトにより、サブタスク間の差異が軽減されます。 図 3: 各サブタスクにおけるテストされたモデルの精度。 著者は、Gemini Pro の長所と短所を深く掘り下げています。図 4 からわかるように、Gemini Pro は、ヒューマン ジェンダー (社会科学)、形式論理 (人文科学)、初等数学 (STEM)、および専門医学 (専門分野) のタスクにおいて GPT 3.5 よりも遅れています。 Gemini Pro が得意とする 2 つのタスクでも僅差です。 図 4: MMLU タスクにおける Gemini Pro と GPT 3.5 の利点。 Gemini Pro の特定のタスクにおけるパフォーマンスの低下には、2 つの理由が考えられます。まず、双子座が答えを返せない状況があります。ほとんどの MMLU サブタスクでは、API 応答率は 95% を超えていますが、道徳 (応答率 85%) と人間の性別 (応答率 28%) の 2 つのタスクでは、対応する応答率が大幅に低くなります。これは、一部のタスクにおける Gemini のパフォーマンスの低下が、入力コンテンツ フィルターによるものである可能性があることを示唆しています。第 2 に、Gemini Pro は、形式論理と基本的な数学タスクを解決するために必要な基本的な数学的推論のパフォーマンスが若干劣ります。 著者は、図 5 に示すように、思考連鎖プロンプトの出力の長さがモデルのパフォーマンスにどのように影響するかも分析しました。一般に、より強力なモデルはより複雑な推論を実行する傾向があるため、より長い答えが出力されます。 Gemini Pro には、その「対戦相手」に比べて注目に値する利点があります。つまり、その精度は出力長の影響をあまり受けません。 Gemini Pro は、出力長が 900 を超える場合でも GPT 3.5 を上回るパフォーマンスを発揮します。ただし、GPT 4 Turbo と比較して、Gemini Pro および GPT 3.5 Turbo は長い推論チェーンを出力することはほとんどありません。 図 5: MMLU でテストされたモデルの出力長分析。
In BIG-Bench Hard テスト セットを使用して、著者は被験者の一般的な推論能力を評価します。 BIG-Bench Hard には、算術推論、記号推論、多言語推論、事実知識の理解など、27 の異なる推論タスクが含まれています。ほとんどのタスクは 250 の質問と回答のペアで構成されますが、質問がわずかに少ないタスクもいくつかあります。
図 6 は、テストされたモデルの全体的な精度を示しています。 Gemini Pro の精度は GPT 3.5 Turbo よりわずかに低く、GPT 4 Turbo よりもはるかに低いことがわかります。それに比べて、Mixtral モデルの精度ははるかに低くなります。
図 6: BIG-Bench-Hard でテストされたモデルの全体的な精度。
著者は、ジェミニの一般推論が全体的にパフォーマンスが悪い理由についてさらに詳しく説明します。まず、質問の長さによる精度を調べました。図 7 に示すように、Gemini Pro は、より長く複雑な問題ではパフォーマンスが低下します。また、GPT モデル、特に GPT 4 Turbo では、非常に長い問題であっても、GPT 4 Turbo の回帰は非常に小さいです。これは、それが堅牢であり、より長く複雑な質問やクエリを理解できることを示しています。 GPT 3.5 Turbo の堅牢性は平均的です。 Mixtral は質問の長さの点では安定したパフォーマンスを示しましたが、全体的な精度は低かったです。
図 7: BIG-Bench-Hard でテストされたモデルの質問の長さ別の精度。
著者は、特定の BIG-Bench-Hard タスクでテストされたモデルの精度に違いがあるかどうかを分析しました。図 8 は、GPT 3.5 Turbo が Gemini Pro よりも優れているタスクを示しています。 「変換されたオブジェクトの位置を追跡する」タスクでは、Gemini Pro のパフォーマンスは特に悪かった。これらのタスクには、人々がアイテムを交換したり、誰が何かを所有しているかを追跡したりすることが含まれますが、Gemini Pro は順序を正しく保つのに苦労することがよくありました。 図 8: GPT 3.5 Turbo は、Gemini Pro の BIG-Bench-Hard サブタスクを上回ります。 Gemini Pro は、複数のステップで解決する必要がある算術問題や翻訳の間違いの発見などのタスクにおいて、Mixtral よりも劣ります。 Gemini Pro が GPT 3.5 Turbo よりも優れているタスクもあります。図 9 は、Gemini Pro が GPT 3.5 Turbo を最もリードしている 6 つのタスクを示しています。タスクは異種混合であり、世界の知識 (sports_ Understanding)、シンボル スタックの操作 (dyck_langages)、単語のアルファベット順の並べ替え (word_sorting)、およびテーブルの解析 (penguins_in_a_table) を必要とするタスクが含まれます。 図 9: Gemini Pro は、BIG-Bench-Hard サブタスクで GPT 3.5 を上回ります。 著者は、図 10 に示すように、さまざまな回答タイプでテストされたモデルの堅牢性をさらに分析しました。 Gemini Pro は、formal_fallacies タスクに属する「有効/無効」回答タイプで最も悪いパフォーマンスを示しました。興味深いことに、このタスクの質問の 68.4% には回答がありませんでした。ただし、他の回答タイプ (word_sorting タスクと dyck_ language タスクで構成される) では、Gemini Pro はすべての GPT モデルおよび Mixtral よりも優れたパフォーマンスを示します。つまり、Gemini Pro は、単語を並べ替えたり、正しい順序で記号を生成したりすることに特に優れています。さらに、MCQ の回答では、質問の 4.39% が Gemini Pro によって回答がブロックされました。 GPT モデルはこの分野で優れており、Gemini Pro はそれらと競合するのに苦労しています。 図 10: BIG-Bench-Hard での回答タイプ別のテストされたモデルの精度。
要するに、特定のタスクで先頭に立っているモデルはないようです。したがって、汎用推論タスクを実行する場合は、どちらのモデルを使用するかを決定する前に、Gemini モデルと GPT モデルの両方を試してみる価値があります。 テスト対象モデルの数学的推論能力を評価するため、著者は次の 4 つの算数問題ベンチマークを作成しました:
(1) GSM8K: 小学校算数ベンチマーク;
(2) SVAMP: 変更して生成堅牢な推論スキルをチェックするための語順問題;
(3) ASDIV: さまざまな言語モードと質問タイプ;
(4) MAWPS: 算術および代数の文章問題が含まれています。
著者は、4 つの数学的問題テスト セットで Gemini Pro、GPT 3.5 Turbo、GPT 4 Turbo、Mixtral の精度を比較し、それらの全体的なパフォーマンスと違い、問題の複雑さにおけるパフォーマンスの違いを調べました。さまざまな深さの思考連鎖の下でのパフォーマンス。
図 11 は全体的な結果を示しています。異なる言語モードを使用した GSM8K、SVAMP、および ASDIV を含むタスクでは、Gemini Pro の精度は GPT 3.5 Turbo の精度よりわずかに低く、 GPT 4 Turboでははるかに低くなります。 MAWPS のタスクに関しては、テストされたすべてのモデルが 90% 以上の精度を達成していますが、Gemini Pro は依然として GPT モデルよりわずかに劣っています。このタスクでは、GPT 3.5 Turbo が GPT 4 Turbo をわずかに上回っています。比較すると、Mixtral モデルの精度は他のモデルよりもはるかに低くなります。
図 11: 4 つの数的推論テスト セット タスクにおけるテストされたモデルの全体的な精度。
#問題の長さに対する各モデルのロバスト性を図 12 に示します。 BIG-Bench Hard の推論タスクと同様に、テスト対象のモデルは、長い質問に答えるときに精度の低下を示しました。GPT 3.5 Turbo は、短い質問では Gemini Pro よりも優れたパフォーマンスを示しますが、リグレッションが速く、Gemini Pro は長い質問の精度では GPT 3.5 Turbo に似ていますが、それでもわずかに遅れています。 # 図 12: 4 つの数的推論テスト セット タスクにおける、さまざまな質問の長さに対する答えを生成する際のテストされたモデルの精度。 さらに、著者らは、答えを得るまでに長い思考連鎖が必要な場合、テストしたモデルの精度に違いがあることを観察しました。図 13 に示すように、GPT 4 Turbo は長い推論チェーンを使用する場合でも非常に堅牢ですが、GPT 3.5 Turbo、Gemini Pro、および Mixtral では COT 長が増加すると制限が生じます。著者らは分析を通じて、COT 長が 100 を超える複雑なサンプルでは Gemini Pro が GPT 3.5 Turbo よりも優れたパフォーマンスを発揮したが、より短いサンプルではパフォーマンスが低下したことも発見しました。 図 13: 異なる思考チェーン長における GSM8K の各モデルの精度。 # 図 14 は、さまざまな桁数に対する答えを生成する際のテストされたモデルの精度を示しています。著者らは、回答に 1 桁、2 桁、または 3 桁以上の数字が含まれるかどうかに基づいて 3 つの「バケット」を作成しました (MAWPS タスクを除き、2 桁を超える回答はありませんでした)。図に示されているように、GPT 3.5 Turbo は複数桁の数学の問題に対してより堅牢であるように見えますが、Gemini Pro はより大きな数値の問題に対して性能が低下します。
# 図 14: 回答の桁数が異なる場合の 4 つの数学的推論テスト セット タスクにおける各モデルの精度。 このセクションでは、著者モデルのコーディング機能を調べるために、2 つのコード生成データセット (HumanEval と ODEX) が使用されました。前者は、Python 標準ライブラリの限られた関数セットに対するモデルの基本的なコードの理解をテストし、後者は、Python エコシステム全体でより広範なライブラリのセットを使用するモデルの能力をテストします。どちらの問題でも、入力は英語で書かれたタスク指示です (通常はテスト ケースが含まれます)。これらの質問は、モデルの言語理解、アルゴリズム理解、初歩的な数学能力を評価するために使用されます。合計で、HumanEval には 164 のテスト サンプルがあり、ODEX には 439 のテスト サンプルがあります。
まず、図 15 に示す全体的な結果から、両方のタスクにおける Gemini Pro の Pass@1 スコアは GPT 3.5 Turbo よりも低く、さらに大幅に低いことがわかります。 GPT 4 ターボよりも低い。これらの結果は、Gemini のコード生成機能には改善の余地があることを示しています。
図 15: コード生成タスクにおける各モデルの全体的な精度。
次に、著者は、図 16 (a) の金溶液の長さとモデルのパフォーマンスの関係を分析します。ソリューションの長さは、対応するコード生成タスクの難易度をある程度示すことができます。著者らは、ソリューションの長さが 100 未満の場合 (より簡単な場合など)、Gemini Pro は GPT 3.5 に匹敵する Pass@1 スコアを達成しますが、ソリューションの長さが長くなると大幅に遅れることを発見しました。これは、Gemini Pro が英語のタスクでのより長い入力と出力に対して概して堅牢であることを著者が発見した、前のセクションの結果とは興味深い対照的です。
著者らは、図 16(b) で、各ソリューションに必要なライブラリがモデルのパフォーマンスに与える影響も分析しました。モック、パンダ、numpy、datetime などのほとんどのライブラリの使用例では、Gemini Pro のパフォーマンスは GPT 3.5 よりも悪くなります。ただし、matplotlib の使用例では、GPT 3.5 および GPT 4 よりも優れたパフォーマンスを示し、コードを通じてプロットの視覚化を実行する能力が優れていることを示しています。  最後に、著者はコード生成の点で Gemini Pro のパフォーマンスが GPT 3.5 よりも悪かったいくつかの具体的な失敗例を示しています。まず、彼らは、Gemini が Python API で関数とパラメーターを正しく選択する点でわずかに劣っていることに気づきました。たとえば、次のプロンプトが表示された場合:
最後に、著者はコード生成の点で Gemini Pro のパフォーマンスが GPT 3.5 よりも悪かったいくつかの具体的な失敗例を示しています。まず、彼らは、Gemini が Python API で関数とパラメーターを正しく選択する点でわずかに劣っていることに気づきました。たとえば、次のプロンプトが表示された場合: ##Gemini Pro は次のコードを生成し、型不一致エラーが発生しました:
対照的に、GPT 3.5 Turbo は次のコードを使用しており、これにより目的の効果が得られます:
さらに、Gemini Pro のエラー率が高くなります。この場合、コードは次のとおりです。実行されたは構文的には正しいですが、より複雑なインテントと正しく一致しません。たとえば、次のヒントに関して:
Gemini Pro は、複数回出現する数値を削除せずに、一意の数値のみを抽出する実装を作成しました。
この一連の実験は、FLORES-200 マシンを使用して評価されました。翻訳ベンチマーク: モデルの多言語機能、特にさまざまな言語ペア間で翻訳する機能。著者らは、Robinson et al. (2023) の分析で使用された 20 言語の異なるサブセットに焦点を当てており、リソースの入手可能性と翻訳の難易度のさまざまなレベルをカバーしています。著者らは、選択したすべての言語ペアのテスト セット内の 1012 文を評価しました。
表 4 と 5 では、著者は Gemini Pro、GPT 3.5 Turbo、GPT 4 Turbo と Google 翻訳などの成熟したシステムとの比較分析を行っています。さらに、幅広い言語をカバーすることで知られる主要なオープンソース機械翻訳モデルである NLLB-MoE のベンチマークも行いました。結果は、Google 翻訳が全体的に他のモデルよりも優れており、9 言語で良好なパフォーマンスを示し、次に NLLB が 0/5 ショット設定で 6/8 言語で良好なパフォーマンスを示していることを示しています。汎用言語モデルは競争力のあるパフォーマンスを示していますが、英語以外の言語への翻訳ではまだ専用の機械翻訳システムを超えていません。
#表 4: 0 ショット ヒントを使用したすべての言語にわたる機械翻訳の各モデルのパフォーマンス (chRF (%) スコア)。最高のスコアは太字で表示され、次に最高のスコアには下線が付けられます。
#表 5: 5 ショット プロンプトを使用したすべての言語の機械翻訳における各モデルのパフォーマンス(chRF (%) フラクション)。最高のスコアは太字で表示され、次に最高のスコアには下線が付けられます。
# 図 17 は、さまざまな言語ペアにわたる一般的な言語モデルのパフォーマンスの比較を示しています。 GPT 4 Turbo は、GPT 3.5 Turbo および Gemini Pro と比較して、NLLB で一貫したパフォーマンス バイアスを示します。 GPT 4 Turbo では、低リソース言語では大幅な改善が見られますが、高リソース言語では、両方の LLM のパフォーマンスは同等です。比較すると、Gemini Pro は 20 言語中 8 言語で GPT 3.5 Turbo および GPT 4 Turbo を上回り、4 言語で最高のパフォーマンスを達成しました。ただし、Gemini Pro は、約 10 の言語ペアで応答をブロックする強い傾向を示しました。
図 17: 言語ペアごとの機械翻訳のパフォーマンス (chRF (%) スコア)。 図 18 は、Gemini Pro は、信頼性の低いシナリオのブロック応答で実行される傾向があるため、これらの言語ではパフォーマンスが低いことを示しています。 Gemini Pro が 0 ショットまたは 5 ショット構成で「ブロックされた応答」エラーを生成した場合、応答は「ブロックされた」とみなされます。
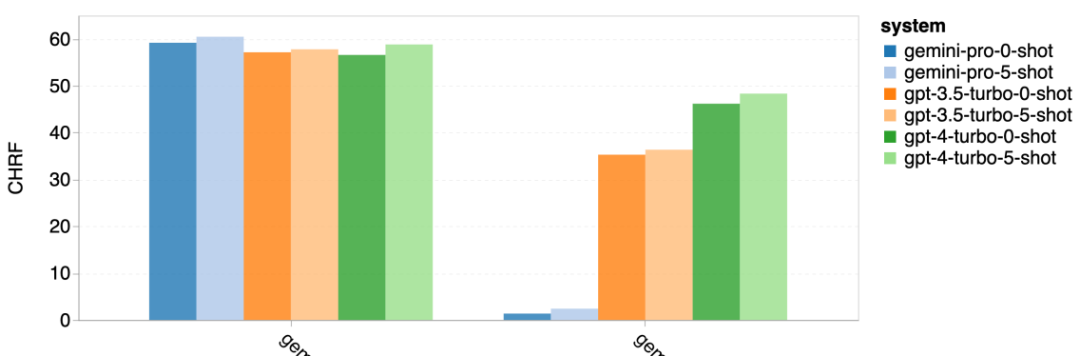
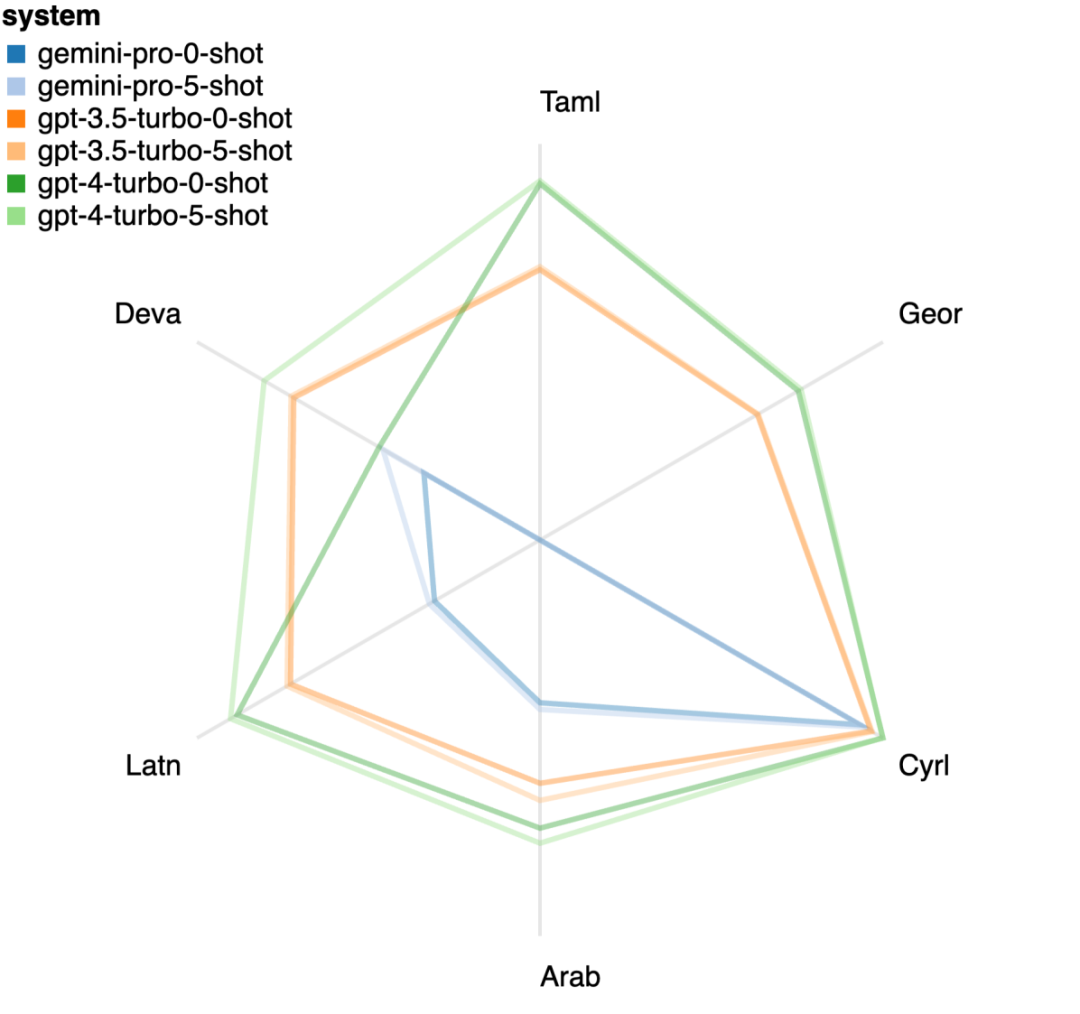
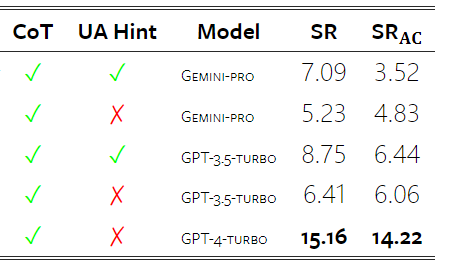
#図 18: Gemini Pro によってブロックされたサンプルの数。 #図 19 をよく見ると、シールドなしでは Gemini Pro が GPT 3.5 Turbo および GPT 4 Turbo よりわずかに優れていることがわかります。より信頼性の高いサンプルです。具体的には、5 ショット設定および 0 ショット設定でそれぞれ GPT 4 Turbo を 1.6 chrf および 2.6 chrf 上回り、GPT 3.5 Turbo を 2.7 chrf および 2 chrf 上回ります。ただし、これらのサンプルに対する GPT 4 Turbo および GPT 3.5 Turbo のパフォーマンスに関する著者らの予備分析では、これらのサンプルの変換は一般的により困難であることが示されています。 Gemini Pro は、これらの特定のサンプルではパフォーマンスが低下します。特に、Gemini Pro 0 ショットは応答をマスクしますが、5 ショットはマスクしません。またその逆も同様です。 図 19: マスクされたサンプルとマスクされていないサンプルの chrf パフォーマンス (%)。 モデルの分析を通じて、著者は、数ショット ヒントが一般に平均パフォーマンスを適度に向上させ、その分散パターンが増分であることを観察しました。 GPT 4 ターボ #図 20 は、言語族または文字ごとの明確な傾向を示しています。重要な観察は、Gemini Pro はキリル文字では他のモデルと競合するパフォーマンスを示しますが、他の文字ではそれほど優れていないということです。 GPT-4 はさまざまなスクリプトで優れたパフォーマンスを発揮し、他のモデルを上回ります。その中でも少数ショットのヒントは特に効果的です。この効果は、サンスクリット語を使用する言語で特に顕著です。 図 20: さまざまなスクリプトでの各モデルのパフォーマンス (chrf (%))。 最後に、著者は各モデルがネットワークをナビゲートするエージェントとして機能する機能。これには長期的な計画と複雑なデータの理解が必要なタスクです。彼らは、実行結果によって成功が測定されるシミュレーション環境 WebArena を使用しました。エージェントに割り当てられるタスクには、情報検索、Web サイトのナビゲーション、コンテンツと構成の操作が含まれます。タスクは、電子商取引プラットフォーム、ソーシャル フォーラム、共同ソフトウェア開発プラットフォーム (gitlab など)、コンテンツ管理システム、オンライン マップなど、さまざまな Web サイトにまたがります。 著者らは、Gemini-Pro の全体的な成功率、さまざまなタスクの成功率、応答の長さ、軌道のステップ、およびタスクの失敗を予測する傾向をテストしました。表 6 に全体的なパフォーマンスを示します。 Gemini-Pro のパフォーマンスは GPT-3.5-Turbo に近いですが、わずかに劣ります。 GPT-3.5-Turbo と同様に、Gemini-Pro は、タスクが完了しない可能性があることがヒントに示されている場合 (UA ヒント)、パフォーマンスが向上します。 UA ヒントを使用すると、Gemini-Pro の全体的な成功率は 7.09% になります。 #表 6: WebArena での各モデルのパフォーマンス。
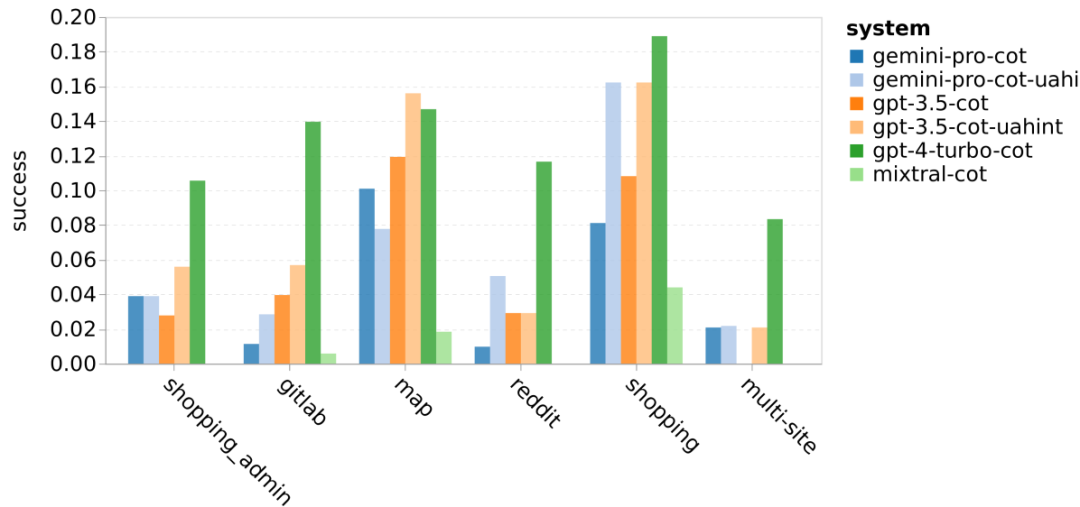
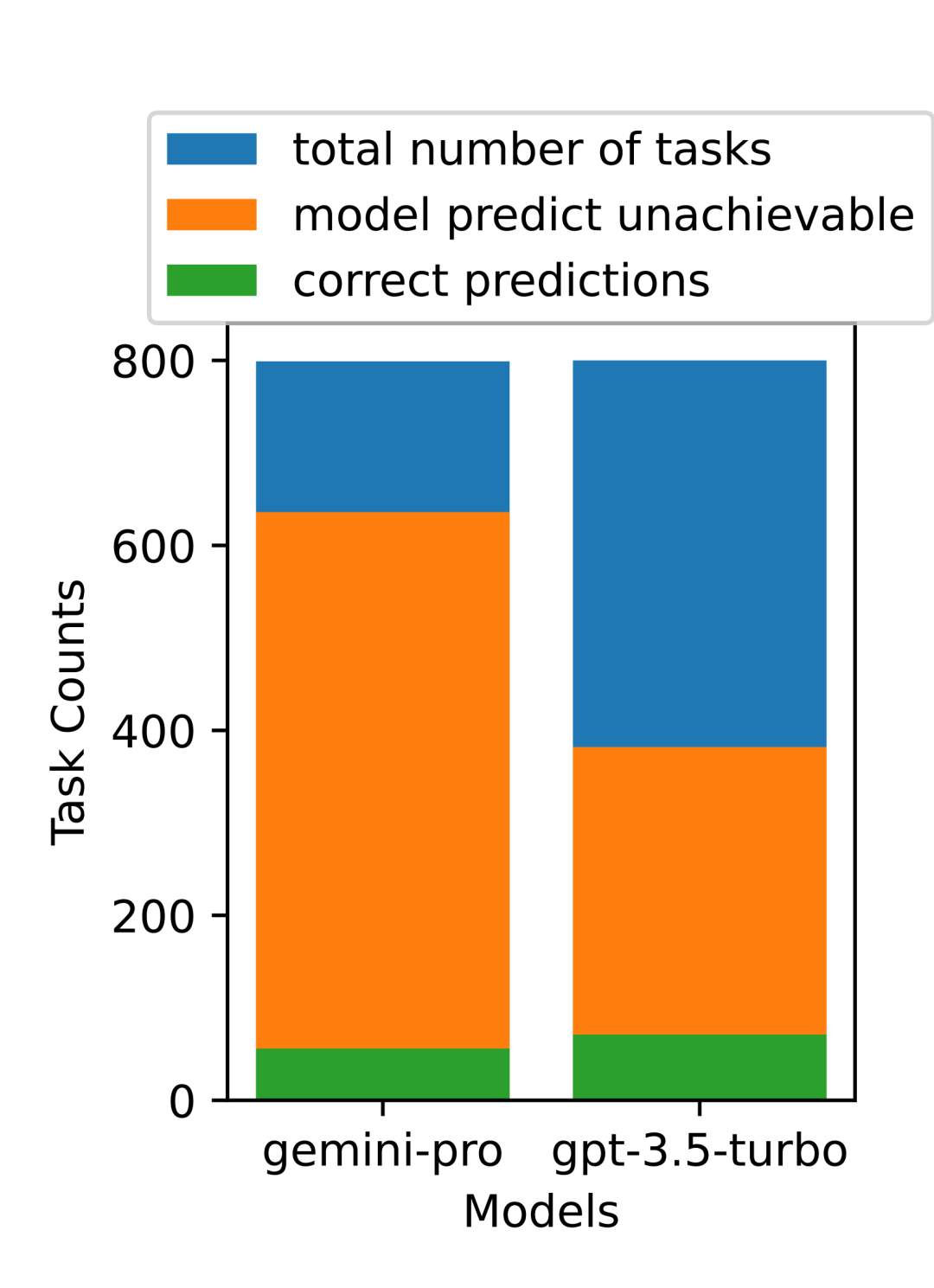
図 21 に示すように、Web サイトの種類ごとに分類すると、Gemini-Pro は gitlab 上で GPT よりもパフォーマンスが悪いことがわかります。マップ -3.5-Turbo は、ショッピング管理、reddit、ショッピング Web サイトでのパフォーマンスは GPT-3.5-Turbo に近いです。 Gemini-Pro は、マルチサイト タスクで GPT-3.5-Turbo よりも優れたパフォーマンスを示します。これは、さまざまなベンチマークにわたって、より複雑なサブタスクでは Gemini がわずかに優れたパフォーマンスを示す以前の結果と一致しています。 #図 21: さまざまな種類の Web サイトにおけるモデルの Web エージェントの成功率。 図 22 に示すように、一般に、Gemini-Pro は、特に UA の場合に、より多くのタスクを完了不可能と予測します。ヒント。 Gemini-Pro は、UA ヒントが与えられた場合、タスクの 80.6% 以上を完了できないと予測しましたが、GPT-3.5-Turbo は 47.7% のみを予測しました。データセット内の実際に達成不可能なタスクは 4.4% のみであることに注意することが重要です。そのため、どちらも実際の達成不可能なタスクの数を大幅に過大評価しています。
#図 22: UA の予測数量。 同時に、著者らは、Gemini Pro は短いフレーズで応答する可能性が高く、結論に達するまでの手順が少ないことも観察しました。 。図 23(a) に示すように、Gemini Pro の軌道の半分以上は 10 ステップ未満ですが、GPT 3.5 Turbo および GPT 4 Turbo のほとんどの軌道は 10 ~ 30 ステップの間です。同様に、Gemini の返信のほとんどは 100 文字未満ですが、GPT 3.5 Turbo、GPT 4 Turbo、Mixtral の返信のほとんどは 300 文字を超えています (図 23(b))。ジェミニは行動を直接予測する傾向がありますが、他のモデルは最初に推論してから行動を予測します。 以上がGemini の完全レビュー: CMU から GPT 3.5 Turbo まで、Gemini Pro は敗北の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



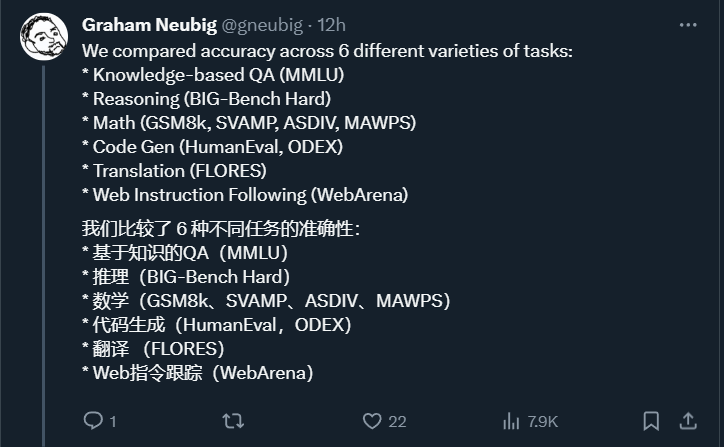
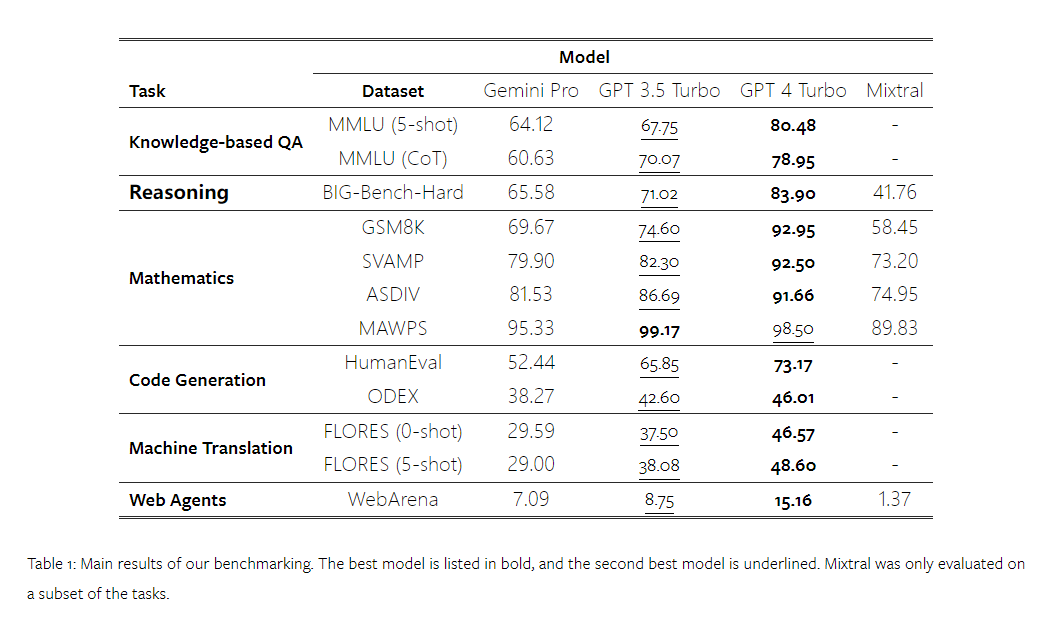

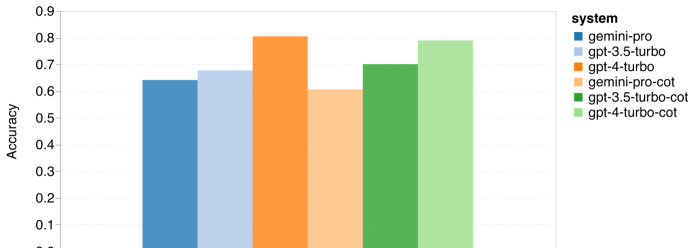
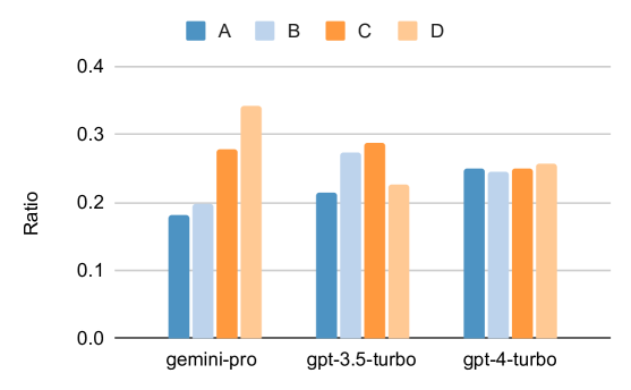
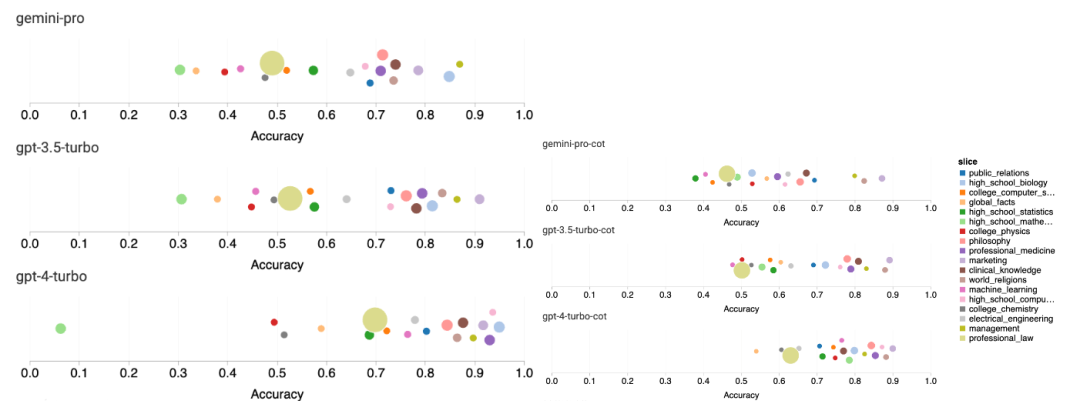
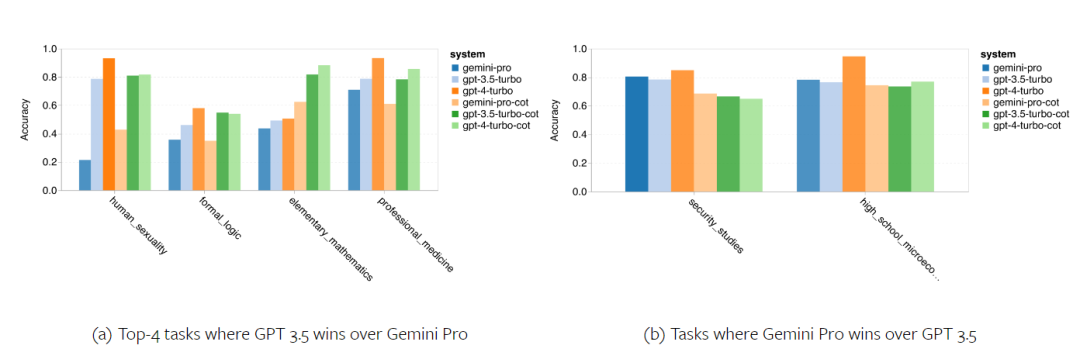
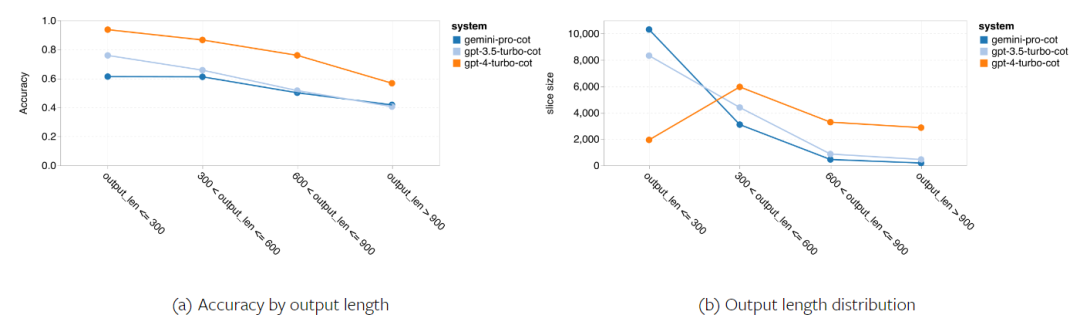
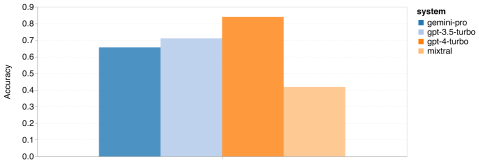
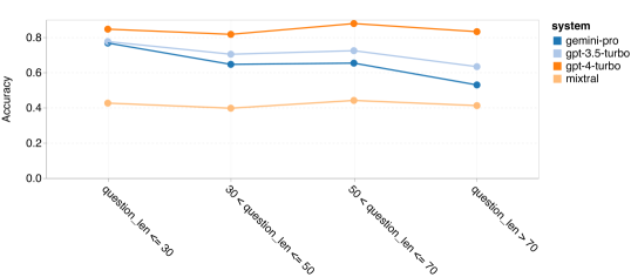
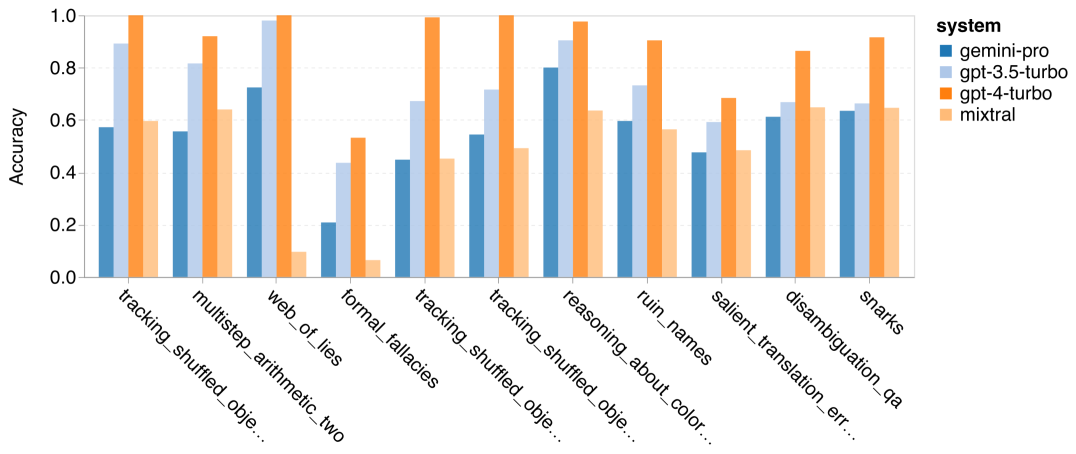
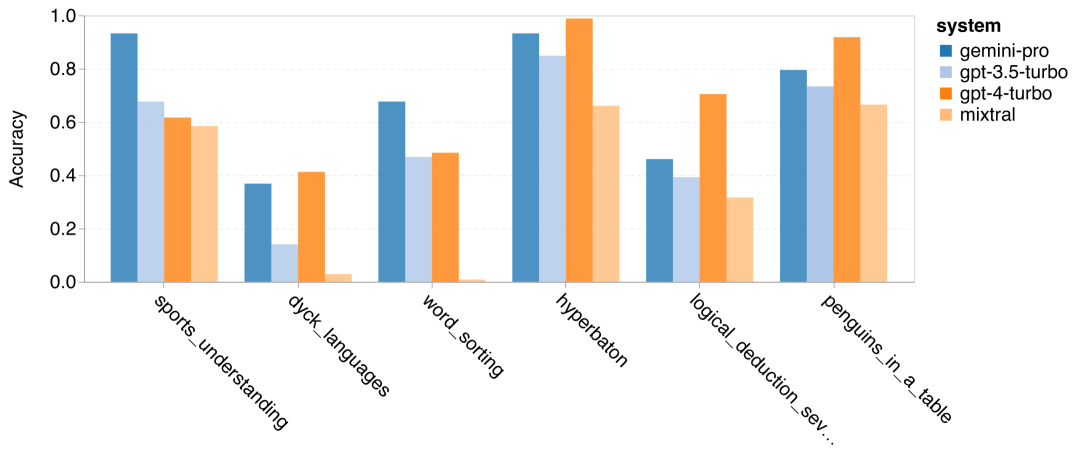
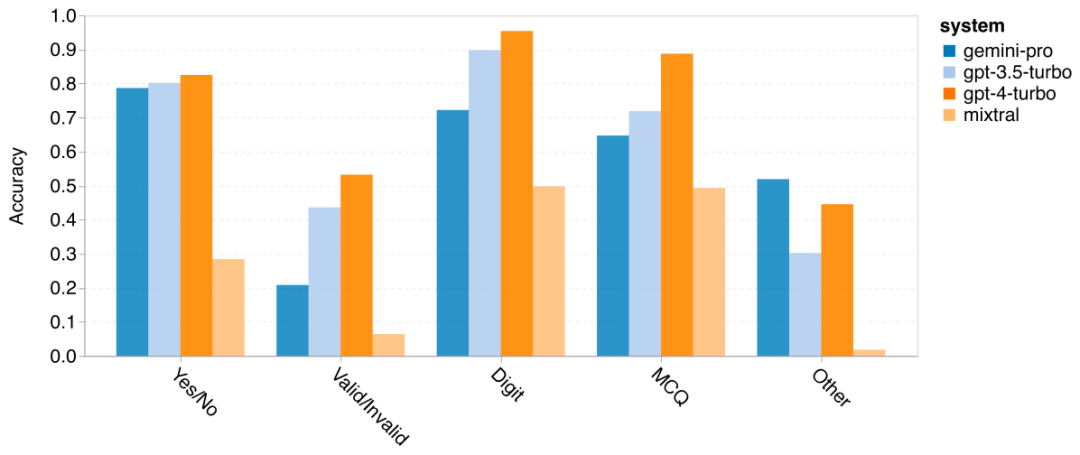
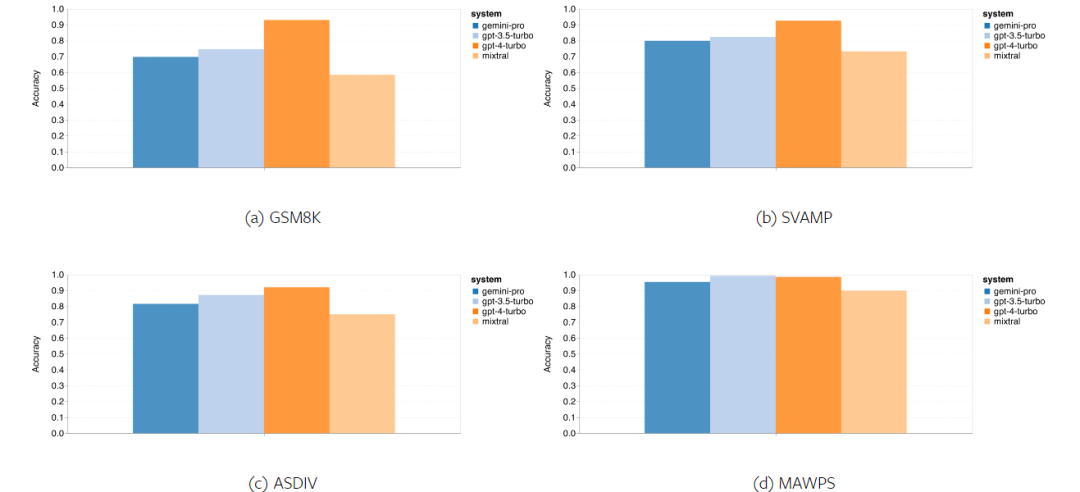
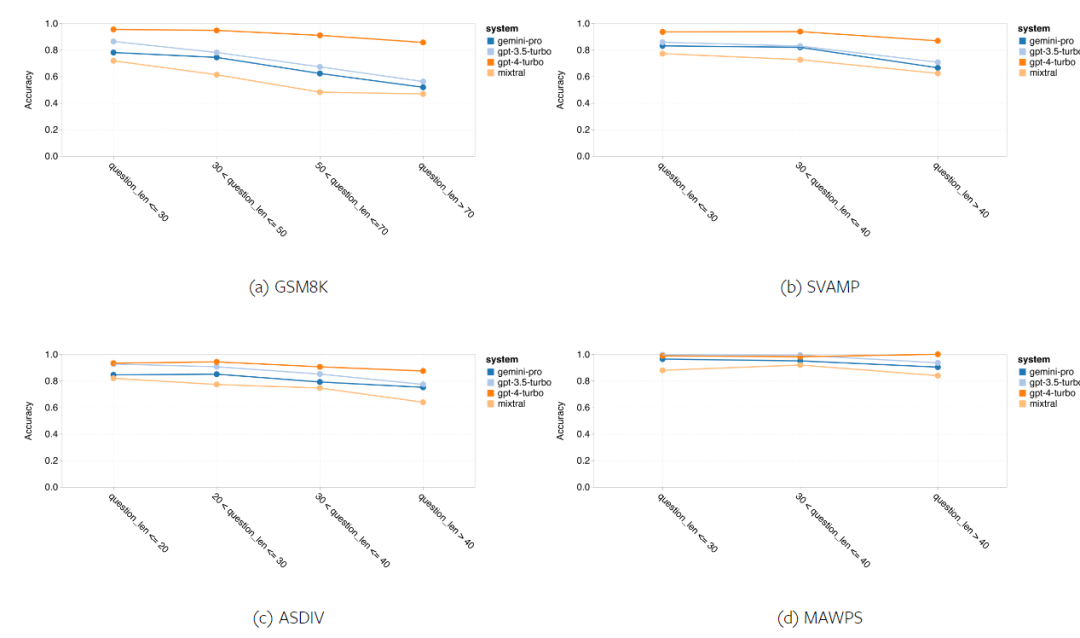
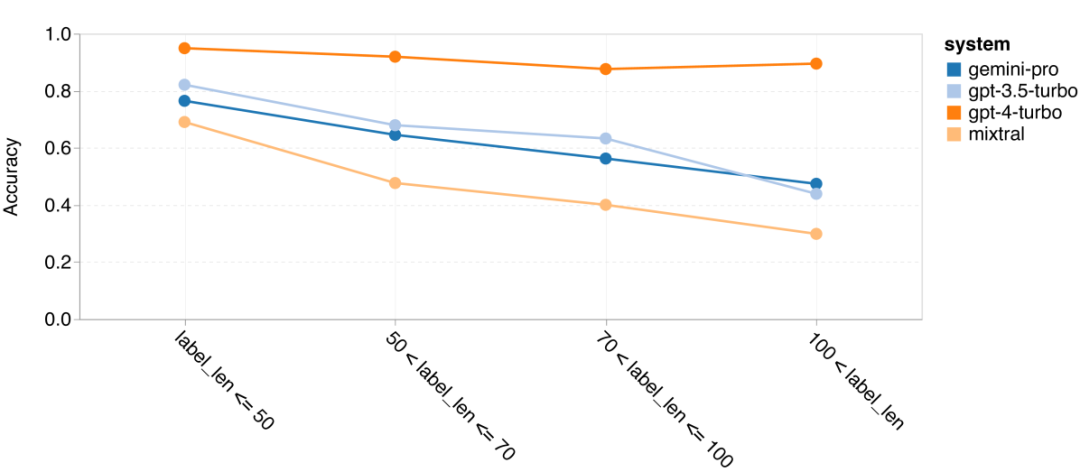
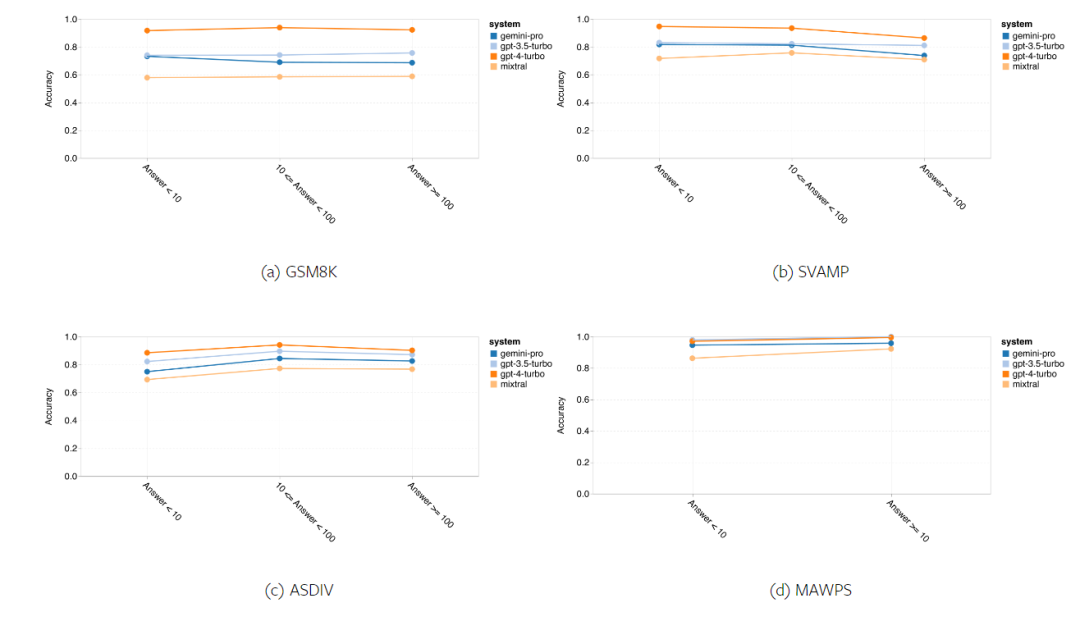
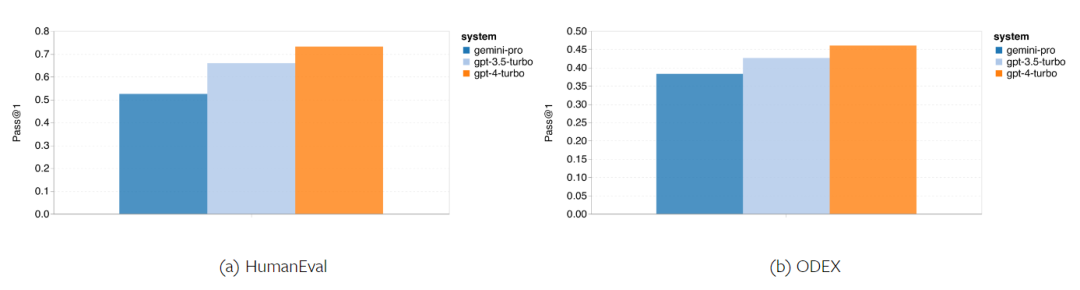
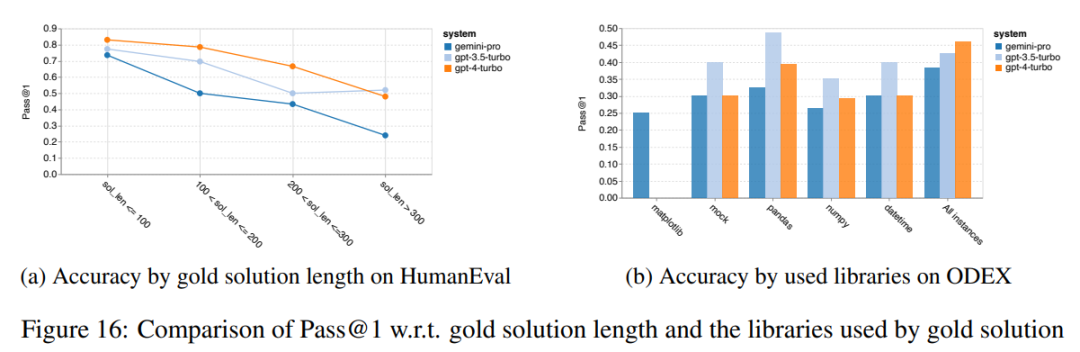
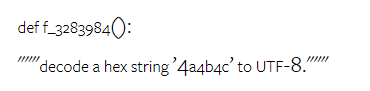
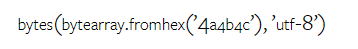
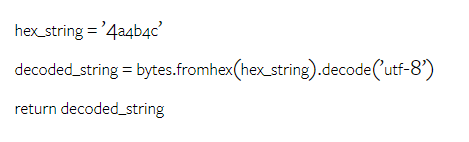


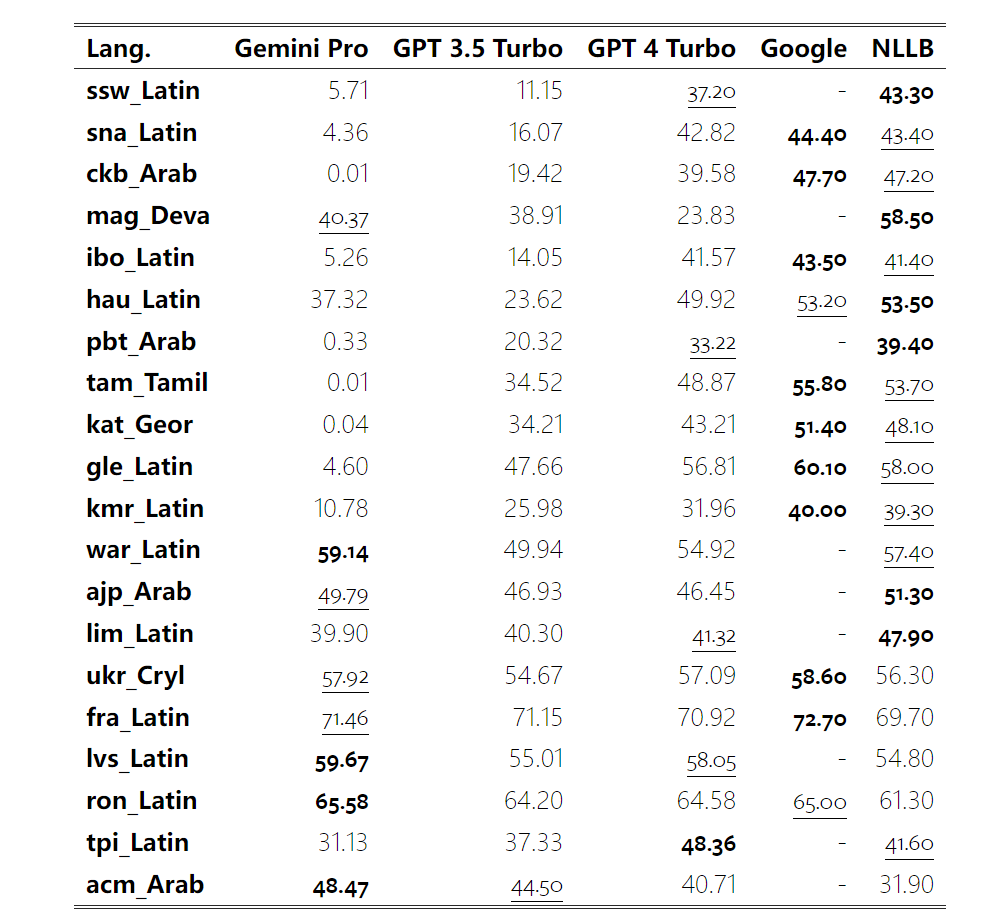
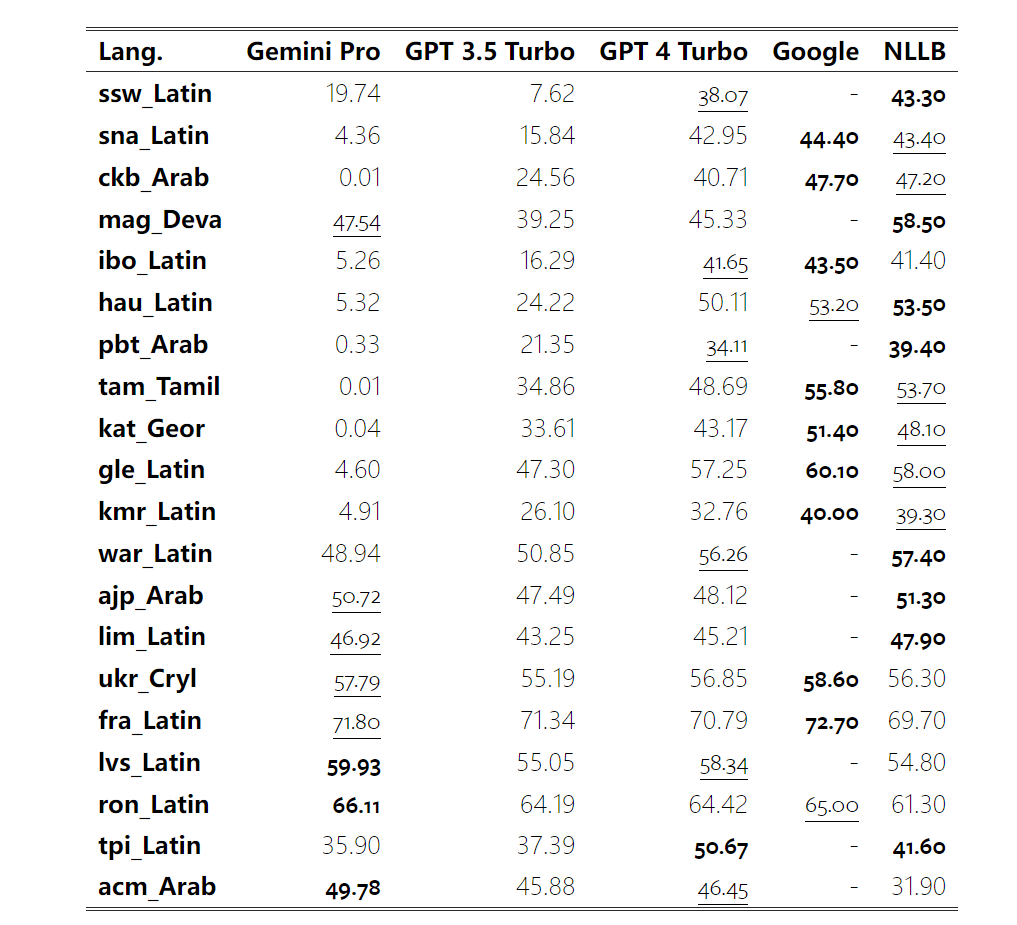
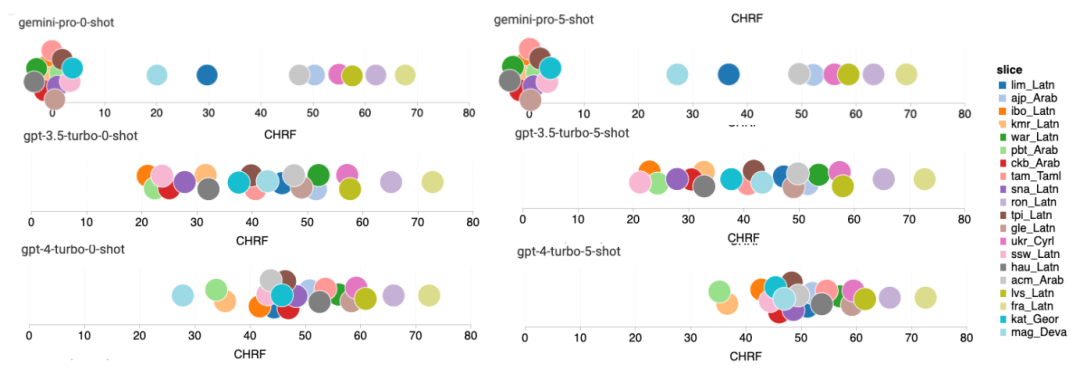 図 17: 言語ペアごとの機械翻訳のパフォーマンス (chRF (%) スコア)。
図 17: 言語ペアごとの機械翻訳のパフォーマンス (chRF (%) スコア)。 
 #図 22: UA の予測数量。
#図 22: UA の予測数量。 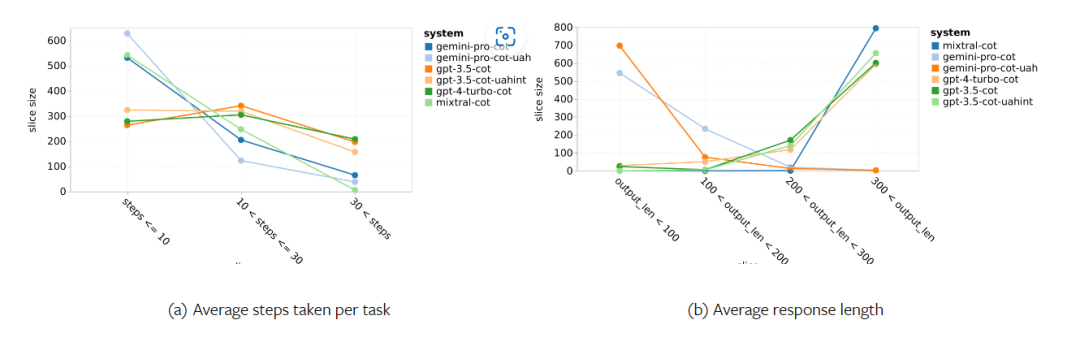












 7467
7467
 15
15

 どの2025通貨交換プラットフォームが優れていますか?トップ10の人気通貨取引アプリの最新の推奨事項
Mar 25, 2025 pm 06:18 PM
どの2025通貨交換プラットフォームが優れていますか?トップ10の人気通貨取引アプリの最新の推奨事項
Mar 25, 2025 pm 06:18 PM
 2025年の安全で使いやすい仮想通貨取引プラットフォームの概要
Mar 25, 2025 pm 06:15 PM
2025年の安全で使いやすい仮想通貨取引プラットフォームの概要
Mar 25, 2025 pm 06:15 PM
 2025年にはどのデジタル通貨交換アプリが優れていますか?上位10の仮想通貨アプリ交換のランキング
Mar 25, 2025 pm 06:06 PM
2025年にはどのデジタル通貨交換アプリが優れていますか?上位10の仮想通貨アプリ交換のランキング
Mar 25, 2025 pm 06:06 PM
 Ethereum Formal Trading Platform 2025の最新の要約
Mar 26, 2025 pm 04:45 PM
Ethereum Formal Trading Platform 2025の最新の要約
Mar 26, 2025 pm 04:45 PM
 トップ10グローバルセキュリティと使いやすい仮想通貨交換ランキング2025
Mar 21, 2025 pm 03:09 PM
トップ10グローバルセキュリティと使いやすい仮想通貨交換ランキング2025
Mar 21, 2025 pm 03:09 PM
 2025年の世界のトップ10の暗号通貨取引所の最新のランキング
Mar 26, 2025 pm 05:09 PM
2025年の世界のトップ10の暗号通貨取引所の最新のランキング
Mar 26, 2025 pm 05:09 PM
 2025 Cryptoデジタル通貨取引アプリソフトウェアの最新のランキングリスト
Mar 21, 2025 pm 02:51 PM
2025 Cryptoデジタル通貨取引アプリソフトウェアの最新のランキングリスト
Mar 21, 2025 pm 02:51 PM
 2025年のトップ10の安全で信頼性の高いデジタル通貨取引プラットフォーム
Mar 21, 2025 pm 03:21 PM
2025年のトップ10の安全で信頼性の高いデジタル通貨取引プラットフォーム
Mar 21, 2025 pm 03:21 PM
